Execution Type Models in Node.js
Learn about execution-type models and their functionality in Node.js with practical examples in this comprehensive article.
Join the DZone community and get the full member experience.
Join For FreeThere are strong reasons why Node.js is so popular nowadays. Async programming model, cross-platform with a large community and open-source modules. It’s possible to write server-side on JavaScript, and it is fast and efficient. Node.js is designed to handle multiple asynchronous I/O operations efficiently. Node.js apply different execution types, and this article will explain how execution types work with practical usage in Node.js.
Types of Execution
V8 engine compiles JavaScript code into machine code that will be performed by the computer’s processor, which can have multiple cores. Node.js has only one main event loop thread, a mechanism used to handle async and non-blocking I/O operations. Non-blocking means an asynchronous programming paradigm that allows you to perform several operations at the same time without blocking the execution of the main program.
This approach allows Node.js to efficiently process a large number of concurrent requests without losing resources on blocking I/O operations. The event loop works differently depending on the type of execution. Executions are stacked up, but there are several different types of execution, and here we will go through all of the execution type models in Node.js.
There are three types of execution models in Node.js: Sequential, Concurrent, and Parallelism. The difference between those execution types is that each task takes some time to complete.
1. Sequential Execution
This type has multiple task execution, which happens one after another, and the current task execution must be completed before moving to the next task. This model is helpful for minor services with a small number of cheap functions where the order of execution is important.

Here is the simplest example of sequential execution. Each task is console.log and executed one after another in a sequence chain.
function executeAllTasks(): void {
console.log('Task Execution 1');
console.log('Task Execution 2');
console.log('Task Execution 3');
}
executeAllTasks();Or with a sequence of functions where each function will be in the chain and executed one after another.
function executionTask1() {
console.log('Execution Task 1');
}
function executionTask2() {
console.log('Execution Task 2');
}
function executionTask3() {
console.log('Execution Task 3');
}
function executeAllTasks() {
executionTask1();
executionTask2();
executionTask3();
}
executeAllTasks();The same idea with an async sequential execution.
function executionTask1(cb) {
setTimeout(() => {
console.log('Execution of Task 1');
cb();
}, 800);
}
function executionTask2(cb) {
setTimeout(() => {
console.log('Execution of Task 2');
cb();
}, 1500);
}
function executionTask3(cb) {
setTimeout(() => {
console.log('Execution of Task 3');
cb();
}, 300);
}
function main() {
executionTask1(() => {
executionTask2(() => {
executionTask3(() => {
console.log('All tasks executed');
});
});
});
}
main();This example shows how each task executes asynchronously using the setTimeout(). Each task will have a different time of execution. The callback will notify that the task was completed and the sequence is ready for the next task.
The next example is more realistic. Let’s say we need to read data from a database, then update and delete.
import { Client } from 'pg';
const client = new Client({
user: 'username',
host: 'hostname',
database: 'database-name',
password: 'password',
port: 5432,
});
async function runSequentially() {
const postId = 1;
const title = 'New Title';
try {
await client.connect();
const res1 = await client.query('SELECT * FROM posts WHERE id = $1', [postId]);
console.log(res1.rows[0]);
const res2 = await client.query('UPDATE posts SET title = $1 WHERE id = $2 RETURNING *', [title, postId]);
console.log(res2.rows[0]);
const res3 = await client.query('DELETE FROM posts WHERE id = $1', [2]);
console.log(res3.rowCount);
await client.end();
} catch (err) {
console.error(err);
}
}
runSequentially();From the chain of dependencies, we expect results that can be used in the following tasks.
2. Concurrent
This is an execution of tasks in overlapping time intervals. Tasks can start and run simultaneously, but completion can be at different times.
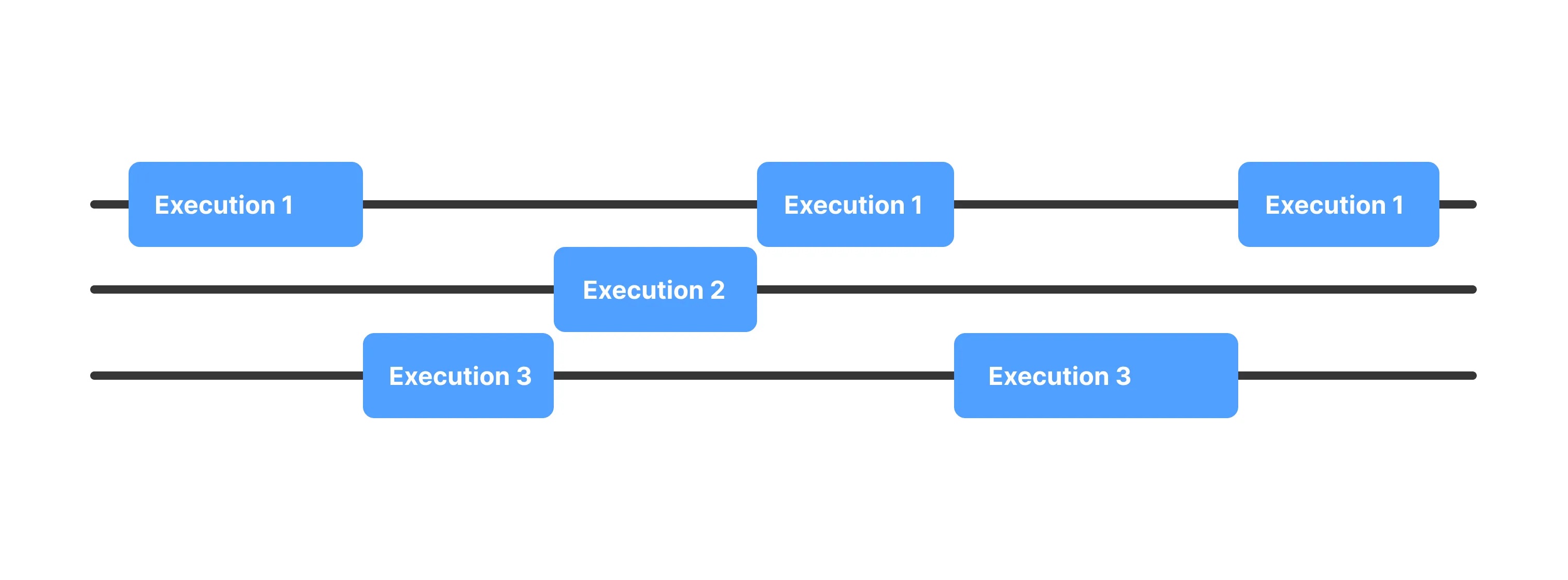
In a concurrent execution model, tasks can be executed independently of one another without waiting to complete the previous task. It can be helpful for applications that have several functions that can run independently.
const fs = require('fs');
fs.readFile('fileOne.txt', (error, data) => {
console.log(data.toString());
});
fs.readFile('fileTwo.txt', (error, data) => {
console.log(data.toString());
});
fs.readFile('fileThree.txt', (error, data) => {
console.log(data.toString());
});As you can see, all files are read concurrently, and the console logs will display the data of each file as soon as it’s read. Each task will start at the same time but could take different amounts of time to complete, and they may not complete at the same time.
To illustrate it with a more realistic example, let’s imagine that we have a function downloadFile but we have to deal with different files and download all of them.
const https = require('https');
const fs = require('fs');
interface FileProps {
url: string;
path: string;
}
async function downloadFile({ url, path }: FileProps): Promise<void> {
const file = fs.createWriteStream(path);
return new Promise<void>((resolve, reject) => {
https
.get(url, (response) => {
response.pipe(file);
file.on("finish", () => {
file.close();
resolve();
});
})
.on("error", (error) => {
fs.unlink(path);
reject(error);
});
});
}Now, let’s try to use downloadFile in concurrent example:
async function downloadFiles(): Promise<void> {
await Promise.all(
[
{ url: "https://example.com/file1.xml", path: "file1.xml" },
{ url: "https://example.com/file2.xml", path: "file2.xml" },
{ url: "https://example.com/file3.xml", path: "file3.xml" },
].map(downloadFile)
);
}
downloadFiles();Function downloadFiles downloads multiple files concurrently by creating an array of promises. By downloading files concurrently, the program can do that in a shorter way, making the program more efficient.
3. Parallelism
This type splits each task execution into smaller tasks and executes them simultaneously on different processors or cores. This type of execution allows completing all the tasks faster than executing them sequentially or concurrently.

This type of execution needs to care about the number of CPU cores, but parallel execution can significantly improve performance for applications that have CPU-bound tasks, like mathematical calculations, data processing, and image resizing or video encoding/decoding.
const workerThreads = require("worker_threads");
function runService(task) {
return new Promise((resolve, reject) => {
const worker = new workerThreads.Worker("./index.js", { workerData: task });
worker.on("message", resolve);
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
}
});
});
}
async function runParallel(tasks) {
return Promise.all(tasks.map(runService));
}
runParallel(["task1", "task2", "task3"]).catch(console.error);In this case, the function runService creates three workers that execute in parallel.
import sharp from "sharp";
import { Worker, isMainThread, parentPort, workerData } from "worker_threads";
interface ImageResizeTask {
id: number;
input: string;
output: string;
width: number;
height: number;
}
async function resizeImage(task: ImageResizeTask): Promise<void> {
await sharp(task.input).resize(task.width, task.height).toFile(task.output);
if (isMainThread) {
console.log(`Task completed: ${task.input} -> ${task.output}`);
} else {
parentPort!.postMessage({ id: task.id });
}
}
async function runParallel(tasks: ImageResizeTask[]): Promise<void> {
await Promise.all(
tasks.map((task, index) => {
return new Promise<void>((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: task,
});
worker.on("message", () => {
resolve();
});
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) {
reject(new Error(`Worker stopped with exit code ${code}`));
}
});
});
})
);
}
if (isMainThread) {
runParallel([
{
id: 1,
input: "input1.png",
output: "output1.png",
width: 300,
height: 200,
},
{
id: 2,
input: "input2.png",
output: "output2.png",
width: 800,
height: 600,
},
{
id: 3,
input: "input3.png",
output: "output3.png",
width: 1024,
height: 768,
},
]);
} else {
resizeImage(workerData);
}In this example, the resizeImage() function uses the sharp lib to resize the image and save it to the output file. It will output a message indicating that the task has been completed if the code is executed in the main thread. Running on a worker thread will send a message to the main thread indicating that the task has been completed.
Node.js supports parallelism through worker threads. It allows us to execute code in separate threads, and each has its own call stack and memory because it runs in different CPU cores.
Conclusion
Each type of execution has to have a specific use case and requirements of the program. Using those types in Node.js can improve performance, scalability, and efficiency depending on what you build. By choosing the right execution type, you can optimize the performance of your application.
Published at DZone with permission of Anton Kalik. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments