Enhancing Web Scraping With Large Language Models: A Modern Approach
Explore the integration of Large Language Models (LLMs) with web scraping and the use of LLMs to efficiently transform complex HTML into structured JSON.
Join the DZone community and get the full member experience.
Join For FreeDuring my early days as a Data Engineer (which dates back to 2016), I had the responsibility of scraping data from different websites. Web scraping is all about making use of tools that are automated to get vast amounts of data from the websites, usually from their HTML.
I remember building around the application, digging into the HTML code, and trying to figure out the best solutions for scraping all the data. One of my main challenges was dealing with frequent changes to the websites: for example, the Amazon pages I was scraping changed every one to two weeks.
One thought that occurred to me when I started reading about Large Language Models (LLMs) was, "Can I avoid all those pitfalls I faced using LLMs to structure data from webpages?"
Let's see if I can.
Web Scraping Tools and Techniques
At the time, the main tools I was using were Requests, BeautifulSoup, and Selenium. Each service has a different purpose and is targeted at different types of web environments.
- Requests is a Python library that can be used to easily make HTTP requests. This library performs GET and POST operations against URLs provided in the requests. It is frequently used to fetch HTML content that can be parsed by BeautifulSoup.
- BeautifulSoup is a Python library for parsing HTML and XML documents, it constructs a parse tree from page source that allows you to access the various elements on the page easily. Usually, it is paired with other libraries like Requests or Selenium that provide the HTML source code.
- Selenium is primarily employed for websites that have a lot of JavaScript involved. Unlike BeautifulSoup, Selenium does not simply analyze HTML code: it interacts with websites by emulating user actions such as clicks and scrolling. This facilitates the data extraction from websites that create content dynamically.
These tools were indispensable when I was trying to extract data from websites. However, they also posed some challenges: code, tags, and structural elements had to be regularly updated to accommodate changes in the website's layout, complicating long-term maintenance.
What Are Large Language Models (LLMs)?
Large Language Models (LLMs) are next-generation computer programs that can learn through reading and analyzing vast amounts of text data. At this age, they are gifted with the amazing capability to write in a human-like narrative making them efficient agents to process language and comprehend the human language. The outstanding ability shone through in that kind of situation, where the text context was really important.
Integrating LLMs Into Web Scraping
The web scraping process can be optimized in a great measure when implementing LLMs into it. We need to take the HTML code from a webpage and feed it into the LLM, which will pull out the objects it refers to. Therefore, this tactic helps in making maintenance easy, as the markup structure can evolve, but the content itself does not usually change.

Here’s how the architecture of such an integrated system would look:
- Getting HTML: Use tools like Selenium or Requests to fetch the HTML content of a webpage. Selenium can handle dynamic content loaded with JavaScript, while Requests is suited for static pages.
- Parsing HTML: Using BeautifulSoup, we can parse out this HTML as text, thus removing the noise from the HTML (footer, header, etc.).
- Creating Pydantic models: Type the Pydantic model in which we are going to scrape. This makes sure that the data typed and structured conforms to the pre-defined schemas.
- Generating prompts for LLMs: Design a prompt that will inform the LLM what information has to be extracted.
- Processing by LLM: The model reads the HTML, understands it, and employs the instructions for data processing and structuring.
- Output of structured data: The LLM will provide the output in the form of structured objects which are defined by the Pydantic model.
This workflow helps to transform HTML (unstructured data) into structured data using LLMs, solving problems such as non-standard design or dynamic modification of the web source HTML.
Integration of LangChain With BeautifulSoup and Pydantic
This is the static webpage selected for the example. The idea is to scrape all the activities listed there and present them in a structured way.
This method will extract the raw HTML from the static webpage and clean it before the LLM processes it.
from bs4 import BeautifulSoup
import requests
def extract_html_from_url(url):
try:
# Fetch HTML content from the URL using requests
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad responses (4xx and 5xx)
# Parse HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
excluded_tagNames = ["footer", "nav"]
# Exclude elements with tag names 'footer' and 'nav'
for tag_name in excluded_tagNames:
for unwanted_tag in soup.find_all(tag_name):
unwanted_tag.extract()
# Process the soup to maintain hrefs in anchor tags
for a_tag in soup.find_all("a"):
href = a_tag.get("href")
if href:
a_tag.string = f"{a_tag.get_text()} ({href})"
return ' '.join(soup.stripped_strings) # Return text content with preserved hrefs
except requests.exceptions.RequestException as e:
print(f"Error fetching data from {url}: {e}")
return NoneThe next step is to define the Pydantic objects that we are going to scrape from the webpage. Two objects need to be created:
Activity: This is a Pydantic object that represents all the metadata related to the activity, with its attributes and data types specified. We have marked some fields asOptionalin case they are not available for all activities. Providing a description, examples, and any metadata will help the LLM to have a better definition of the attribute.ActivityScraper: This is the Pydantic wrapper around theActivity. The objective of this object is to ensure that the LLM understands that it is needed to scrape several activities.
from pydantic import BaseModel, Field
from typing import Optional
class Activity(BaseModel):
title: str = Field(description="The title of the activity.")
rating: float = Field(description="The average user rating out of 10.")
reviews_count: int = Field(description="The total number of reviews received.")
travelers_count: Optional[int] = Field(description="The number of travelers who have participated.")
cancellation_policy: Optional[str] = Field(description="The cancellation policy for the activity.")
description: str = Field(description="A detailed description of what the activity entails.")
duration: str = Field(description="The duration of the activity, usually given in hours or days.")
language: Optional[str] = Field(description="The primary language in which the activity is conducted.")
category: str = Field(description="The category of the activity, such as 'Boat Trip', 'City Tours', etc.")
price: float = Field(description="The price of the activity.")
currency: str = Field(description="The currency in which the price is denominated, such as USD, EUR, GBP, etc.")
class ActivityScrapper(BaseModel):
Activities: list[Activity] = Field("List of all the activities listed in the text")Finally, we have the configuration of the LLM. We will use the LangChain library, which provides an excellent toolkit to get started.
A key component here is the PydanticOutputParser. Essentially, this will translate our object into instructions, as illustrated in the Prompt, and also parse the output of the LLM to retrieve the corresponding list of objects.
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(temperature=0)
output_parser = PydanticOutputParser(pydantic_object = ActivityScrapper)
prompt_template = """
You are an expert making web scrapping and analyzing HTML raw code.
If there is no explicit information don't make any assumption.
Extract all objects that matched the instructions from the following html
{html_text}
Provide them in a list, also if there is a next page link remember to add it to the object.
Please, follow carefulling the following instructions
{format_instructions}
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["html_text"],
partial_variables={"format_instructions": output_parser.get_format_instructions}
)
chain = prompt | llm | output_parserThe final step is to invoke the chain and retrieve the results.
url = "https://www.civitatis.com/es/budapest/"
html_text_parsed = extract_html_from_url(url)
activites = chain.invoke(input={
"html_text": html_text_parsed
})
activites.ActivitiesHere is what the data looks like. It takes 46 seconds to scrape the entire webpage.
[Activity(title='Paseo en barco al anochecer', rating=8.4, reviews_count=9439, travelers_count=118389, cancellation_policy='Cancelación gratuita', description='En este crucero disfrutaréis de las mejores vistas de Budapest cuando se viste de gala, al anochecer. El barco es panorámico y tiene partes descubiertas.', duration='1 hora', language='Español', category='Paseos en barco', price=21.0, currency='€'),
Activity(title='Visita guiada por el Parlamento de Budapest', rating=8.8, reviews_count=2647, travelers_count=34872, cancellation_policy='Cancelación gratuita', description='El Parlamento de Budapest es uno de los edificios más bonitos de la capital húngara. Comprobadlo vosotros mismos en este tour en español que incluye la entrada.', duration='2 horas', language='Español', category='Visitas guiadas y free tours', price=27.0, currency='€')
...
]Demo and Full Repository
I have created a quick demo using Streamlit available here.
In the first part, you are introduced to the model. You can add as many rows as you need and specify the name, type, and description of each attribute. This will automatically generate a Pydantic model to be used in the web scraping component.
The next part allows you to enter a URL and scrape all the data by clicking the button on the webpage. A download button will appear when the scraping has finished, allowing you to download the data in JSON format.
Feel free to play with it!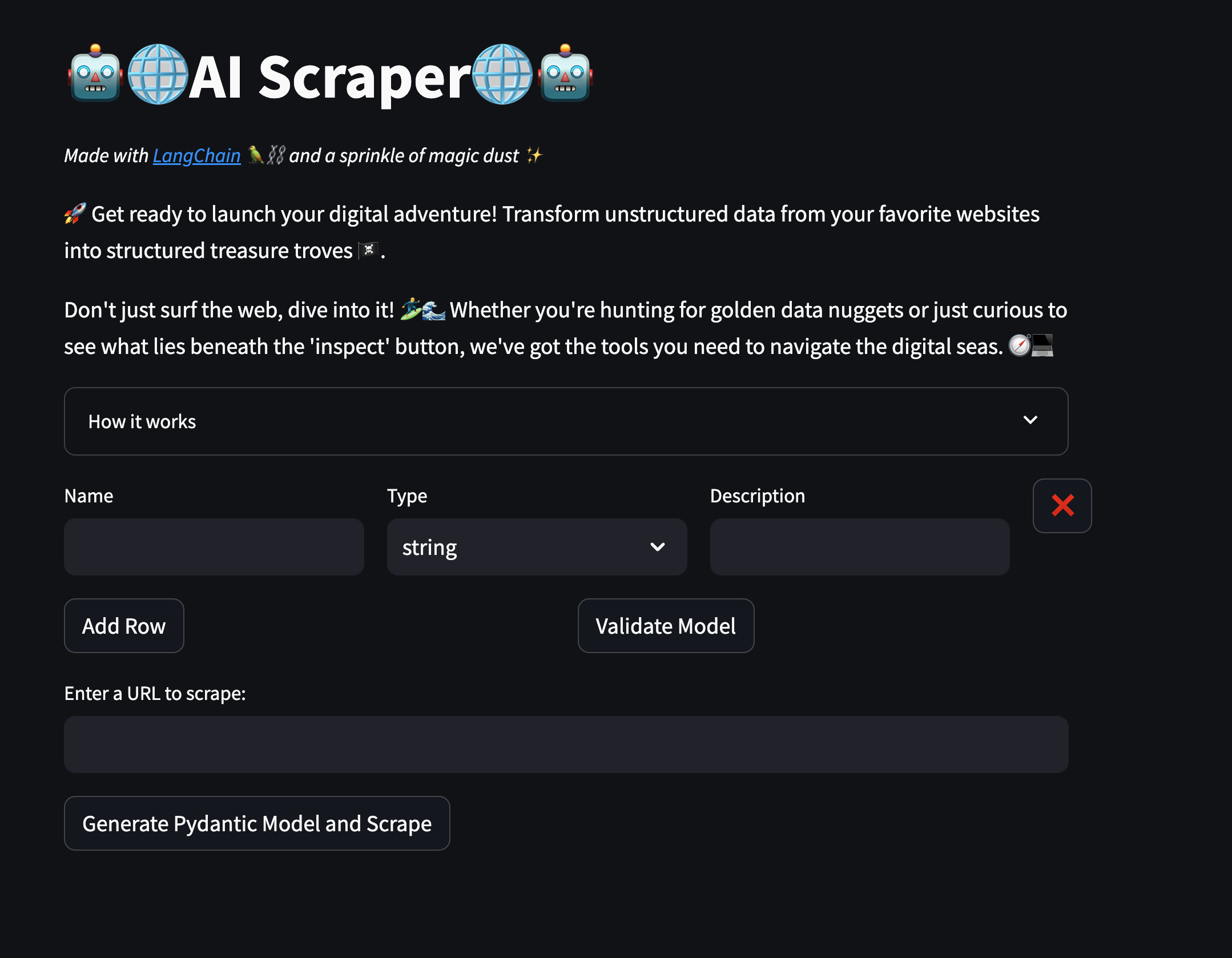
Conclusion
LLM provides new possibilities for efficiently extracting data from non-structured data such as websites, PDFs, etc. The automatization of web scraping by LLM not only will save time but also ensure the quality of the data retrieved.
However, sending raw HTML to the LLM could increase the token cost and make it inefficient. Since HTML often includes various tags, attributes, and content, the cost can quickly rise.
Therefore, it is crucial to preprocess and clean the HTML, removing all the unnecessary metadata and non-used information. This approach will help use LLM as a data extractor for webs while maintaining a decent cost.
The right tool for the right job!
Opinions expressed by DZone contributors are their own.
Comments