Enhancing Churn Prediction With Ensemble Learning Techniques
Customer churn is a substantial threat to businesses, affecting revenue and strategic planning. Predictive analytics has transitioned to an indispensable element of business strategy.
Join the DZone community and get the full member experience.
Join For FreeCustomer churn extends beyond a mere indicator of revenue loss: across diverse industries, it poses a formidable challenge that can profoundly destabilize a business's foundation. It undermines long-term strategic planning, escalates operational costs, and frequently signals underlying deficiencies, such as product quality or customer service efficiency. Against this background, predictive analytics has transitioned from a desirable addition to an indispensable element of business strategy.
Historically, this domain has leaned on traditional statistical models, including logistic regression and decision trees. These methodologies sift through historical customer data to identify indicators predictive of future service discontinuation. Although these methods have demonstrated resilience over time, their adequacy is increasingly being questioned. In this regard, ensemble learning emerges as a sophisticated alternative, offering enhanced precision and reliability in identifying potential customer attrition.
Ensemble learning, in turn, distinguishes itself by simultaneously employing multiple predictive models to refine accuracy. This article, thus, aims to elucidate how ensemble learning can revolutionize the approach to churn prediction: we will explore various techniques such as Random Forest, Gradient Boosting, and Stacking, illustrating their efficacy in predicting customer churn through pragmatic examples.
Ensemble Learning: Introductory Insights
In essence, ensemble learning is a sophisticated machine learning approach that combines multiple models to predict customer churn rather than relying on a single model. This technique is akin to a collaborative effort where each model (weak learner) contributes its unique perspective, compensating for the limitations of individual models and enhancing overall prediction accuracy.
This method is particularly effective for churn prediction due to the complex nature of customer behavior. Different models, each with its specialty, work together to provide a more comprehensive understanding of why customers leave a service.
Traditional methods, which use only one model, miss out on this richness of perspective. By integrating these diverse models, Ensemble learning captures a fuller picture of customer churn and improves prediction accuracy by giving more weight to the more effective models.
Common Techniques
In churn prediction, ensemble methods typically encompass three primary techniques: Random Forest, Gradient Boosting, and Stacking. Each of these methodologies possesses distinct characteristics that render them particularly effective for specific aspects of churn prediction.
Random Forest
Random Forest operates as an aggregation of decision trees, each formulated on a subset of the dataset. The final prediction is derived from the mean of the outputs from these individual trees, ensuring a more balanced result. This method is notably advantageous for churn prediction as it manages numerical and categorical data types, such as customer age and product categories. Importantly, Random Forest also offers metrics indicating the relative importance of different features, essential in identifying key factors driving customer churn and thereby assisting in developing focused retention strategies.
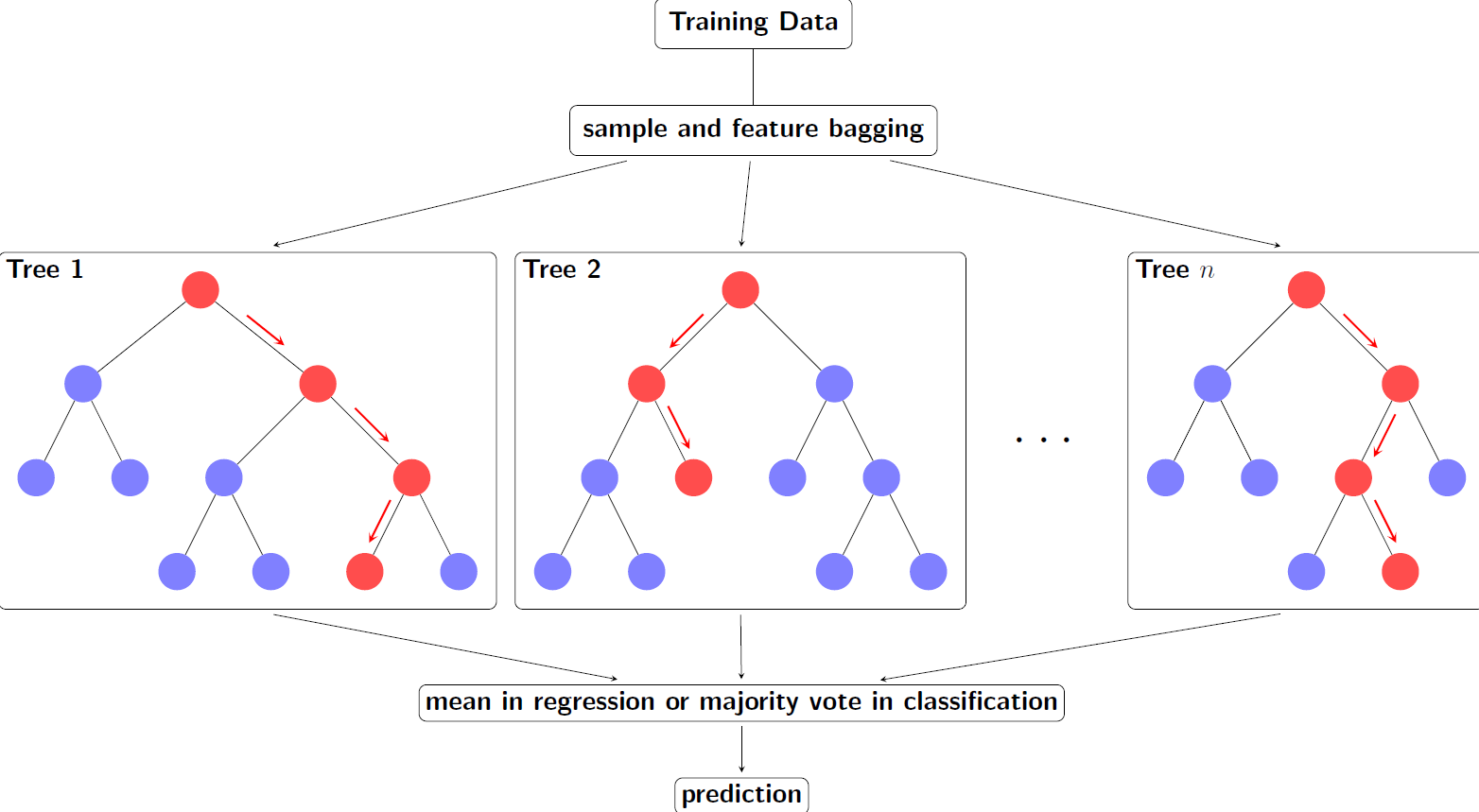
Gradient Boosting
Gradient Boosting employs a progressive strategy in model development. It begins with a basic model and incrementally enhances complexity by increasing weight of incorrectly predicted points on the current ensemble. This technique finely progressively refines its predictions by increasing number of trees. The final prediction is based on the weighted average of the individual trees.
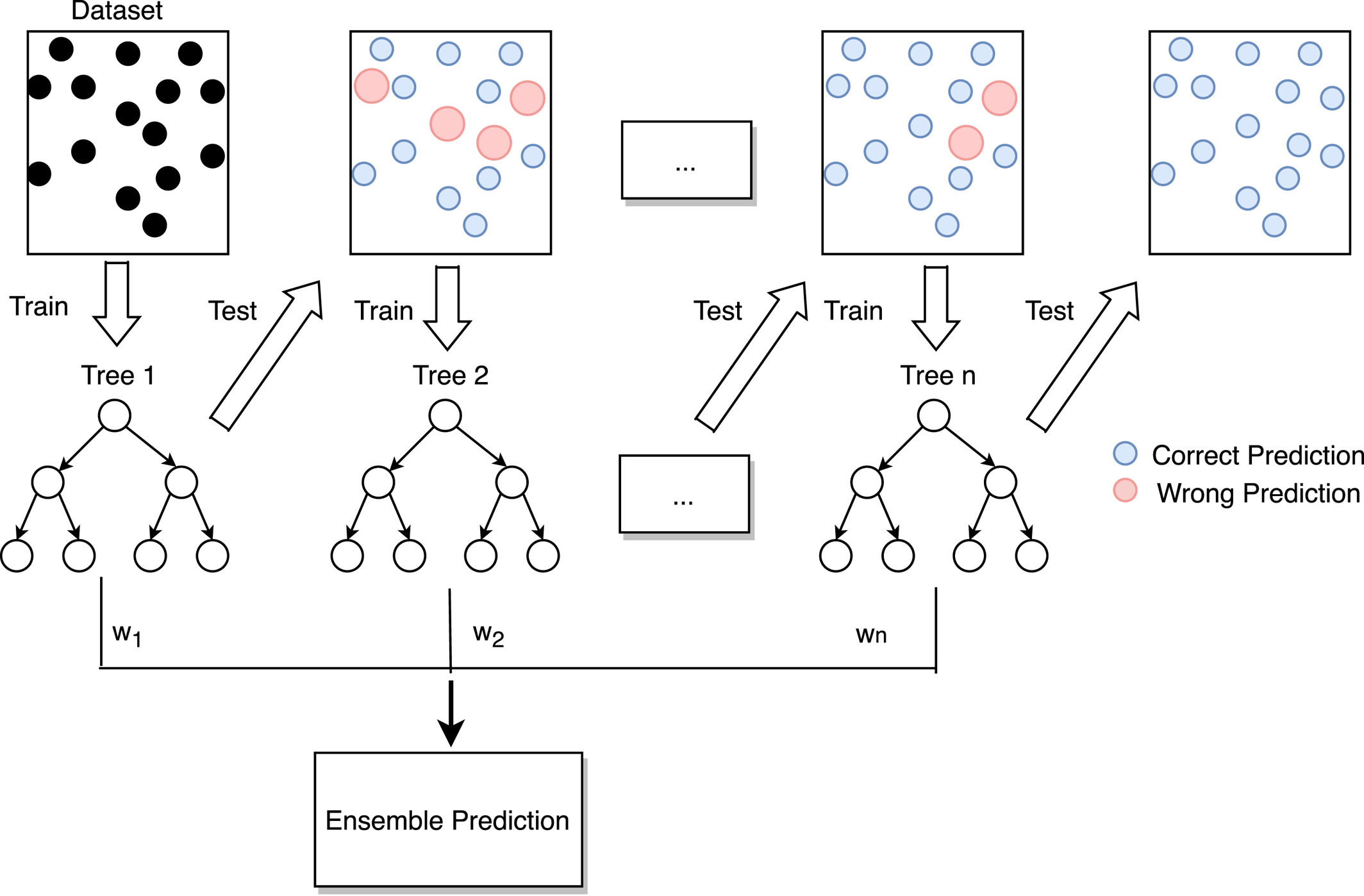
Gradient Boosting builds a strong classifier by sequentially training weak learners, with each new learner focusing on the mistakes made by the ensemble of the previous ones [2].
Stacking
Stacking acts as the mastermind among ensemble methods: it amalgamates predictions from various models and utilizes another model, termed the meta-model, to generate the ultimate prediction. This methodology's versatility allows the integration of the different model types into a single ensemble, resulting in a more precise prediction. In churn prediction, stacking can merge diverse models, such as logistic regression for demographic insights, decision trees for behavioral patterns, and neural networks for analyzing transaction sequences, to create a robust, multi-dimensional prediction framework.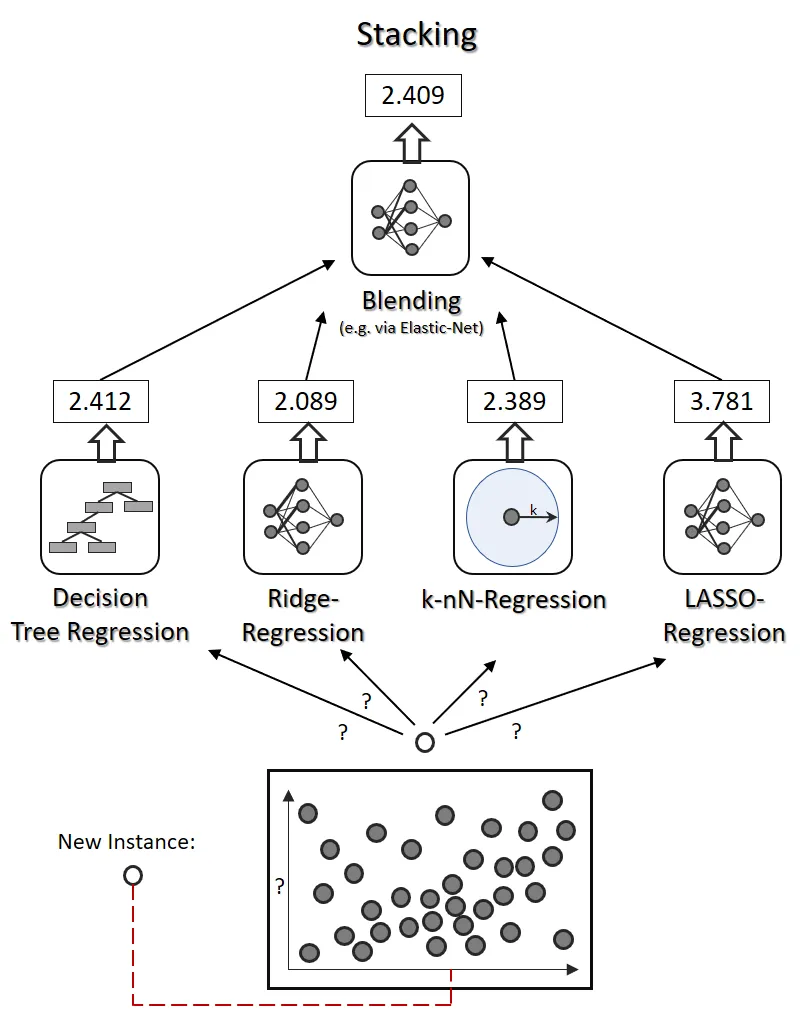
Stacking is a ensemble learning method that combine multiple machine learning algorithms via meta learning [3].
Refined Techniques: Specialized Enhancements for Improved Accuracy
Implementing ensemble methods for churn prediction requires more than simply deploying pre-existing algorithms. Enhancing these models' performance involves customizing them to address the specific challenges of churn modelling. The following are some tailored adjustments:
Random Forest: Class Balancing
Churn prediction models often deal with imbalanced classes, with a majority of loyal customers compared to churners. To address this, a Random Forest model can be calibrated to assign greater weight to the minority class, ensuring that churners are adequately represented and not overshadowed by the larger group of non-churners.
Gradient Boosting: Learning Rate Adjustment and Early Stopping
For Gradient Boosting, fine-tuning the learning rate is critical. A lower rate can enhance the model's resilience against data noise. Furthermore, implementing early stopping parameters allows the model to halt training when signs of overfitting appear, thereby maintaining its applicability to a broader range of scenarios.
Stacking: Strategic Model Selection
In stacking, the selection of both base models and the meta-model is pivotal. A strategic combination might include logistic regression and decision trees as base models, complemented by a neural network as the meta-model. This blend leverages the benefits of both conventional statistical methods and advanced machine learning techniques, offering a well-rounded approach to churn prediction.
Consistent Feature Engineering Across Models
Tailoring feature engineering to highlight churn-specific predictors can significantly enhance ensemble models. Incorporating specialized features can substantially enhance model performance.
Tech Solutions
When it comes to implementing ensemble learning techniques for churn prediction, the good news is that there's no need to start from scratch. Several technology options are available to make this task much more manageable.
Scikit-learn, a popular Python library, offers ready-made algorithms for Random Forest and Gradient Boosting, along with tools for fine-tuning models. This allows you to begin with existing models and adjust them to fit your needs. For those more comfortable with R, packages like randomForest and gbm provide similar pre-built ensemble algorithms and customization options tailored for various prediction scenarios, including churn.
Enterprise-level platforms like DataRobot and H2O.ai offer a convenient solution with their integrated ensemble methods and user-friendly dashboards, making it easier to convert data into actionable insights. Additionally, major cloud services such as AWS, Azure, and Google Cloud provide pre-configured ensemble models as part of their machine learning offerings, which is especially helpful for businesses looking to scale or handle large datasets.
Specialized analytics platforms, such as Adobe Analytics and IBM SPSS, are tailored for specific industries and integrate easily with existing business tools, offering domain-specific ensemble modelling options. Utilizing these technological solutions, both novices and experienced professionals can create a more efficient and quicker path to implementing ensemble learning techniques.
In conclusion, ensemble learning techniques mark a significant leap forward in the realm of churn prediction. Leveraging algorithms such as Random Forest, Gradient Boosting, and Stacking, these methods not only enhance the predictive accuracy of machine learning systems but also provide interpretability and explainability. This interpretative capability is crucial for identifying the underlying causes of customer churn, enabling businesses to take remedial actions and address the root of the problem.
Whether utilizing popular libraries like Scikit-learn in Python or enterprise-level platforms such as DataRobot and H2O.ai, businesses now have accessible and efficient solutions to implement ensemble learning. Moreover, major cloud services like AWS, Azure, and Google Cloud offer pre-configured ensemble models, facilitating scalability and handling large datasets. For industry-specific needs, specialized analytics platforms like Adobe Analytics and IBM SPSS seamlessly integrate with existing business tools, providing tailored ensemble modelling options. In essence, ensemble learning not only elevates predictive capabilities but also equips businesses with the tools to understand and mitigate customer churn effectively.
References
[1] https://tex.stackexchange.com/questions/503883/illustrating-the-random-forest-algorithm-in-tikz
[2] Zhang, T., Lin, W., Vogelmann, A.M., Zhang, M., Xie, S., Qin, Y. and Golaz, J.C., 2021. Improving convection trigger functions in deep convective parameterization schemes using machine learning. Journal of Advances in Modeling Earth Systems, 13(5), p.e2020MS002365.
Opinions expressed by DZone contributors are their own.
Comments