Engineering Metrics Benchmarks: What Makes Elite Teams?
LinearB has analyzed 1,971 teams to enable developers to see how they compare to other big teams in the industry. Find out what they've learned
Join the DZone community and get the full member experience.
Join For FreeDORA Metrics and Beyond
In 2014 the DevOps Research and Assessment (DORA) team published their first State of DevOps report, identifying four metrics that can be used to measure engineering team performance.
Six months ago the Data Science Team at LinearB decided to continue where DORA left off, digging deeper into the data than ever before. For the first time in history, engineering teams are able to benchmark their performance against data-backed industry standards.
Our study analyzed:
- 1,971 Engineering Teams
- 847K Branches
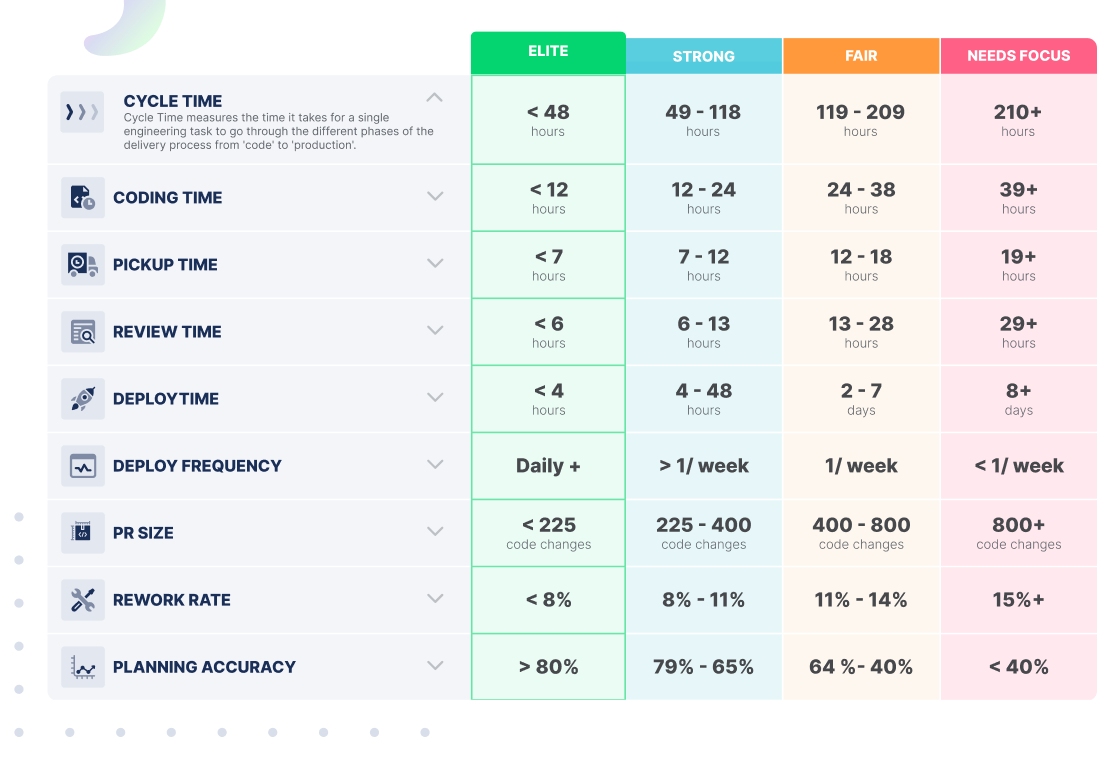
Benchmarking your organization’s performance against these metrics is a great way to understand the efficiency and effectiveness of your engineering operation. The best way to begin your journey is by gathering data.
To help you generate these nine metrics for your team, LinearB provides free accounts for dev teams. Our platform correlates data from your GitHub, GitLab or Bitbucket repos with data from your project management tool, like Jira, to provide the most accurate picture of your team’s performance possible.
Throughout the rest of this document, we will be providing details into how we calculated each metric, why we made the choices we did, and how each metric can be used to improve your engineering organization.
Calculating Engineering Metric Benchmarks
While the DORA Metrics and Accelerate book are based on interviews and assessments, the Engineering Metrics Benchmarks are based solely on data from working dev teams. The data itself comes from the many thousands of free and paid users of the LinearB platform. Our data is trusted because it comes from a global population of engineers who are improving their engineering metrics in a variety of ways. Since the LinearB platform is flexible enough to allow users to track their work through Git, project management, API or all three, our overall data sets are more diverse and therefore a better representation of how engineering teams work in real life.
When we began our study, we had to decide on what data was best suited to provide us with trusted results. So we started by making a list:
- We will not take out outliers
- We will only measure Merged PRs
- Will only include organizations with at least 400 branches
- We will only include organizations that had 270 days worth of data
- We would exclude draft PRs and excluded branches from our calculation
With these rules applied, we started by taking the average metric value during a 270 day period and began plotting them on a graph. Once this was done, we were able to take the percentiles that would turn into our rankings.
- Top 10% – Elite
- 11 – 30 % – Strong
- 31 – 60% – Fair
- Last 40% – Needs Focus
Why did we use these percentiles? It was a question we struggled with during the study. Why not make Elite the top 20% and make everyone feel a bit better about their performance? Should we make Fair and Strong a little bit larger so more organizations land in the middle of the chart?
At the end of the day, we wanted to represent what we felt was most true to the spirit of the data. In this regard, that meant Elite should be truly special. And any metric that falls into the last forty percent should be focused on by the organizations to understand how it can be improved.
Engineering Metrics
The nine metrics shown in the chart are all indicators of an engineering organization’s level of quality and efficiency. Teams who use these metrics to identify areas for focus, set goals and take steps to improve significantly increase their business value delivery.
Cycle Time:
Measures the amount of time from first commit to production release. It is a metric borrowed from lean manufacturing, and it is one of the most important metrics for software development teams.
Short Cycle Time demonstrates that an organization is delivering value to customers at a faster rate. Short Cycle Time correlates to small PR sizes, a healthy review process, and high deployment frequency. Overall, teams with an elite Cycle Time are able to deliver more features predictably and at a higher quality.
Long Cycle Time is caused by multiple reasons, the most common being bottlenecks within the PR review process. Longer Cycle Times reduce team efficiency as well as the ability to deliver features predictably.

Coding Time:
measures the time it takes from the first commit until a pull request is issued.
Short Coding Time correlates to low WIP, small PR size and clear requirements. Combined, these benefits mean a reduction in developer context switching costs (i.e. time spent re-focusing on a task).
Long Coding Time correlates to larger PR sizes, longer PR Review Times and a reduction in code quality. When requirements are unclear or work isn’t broken down into small chunks, code becomes more complex and more challenging to review thoroughly before production.
Pickup Time:
Measures the time a pull request waits for someone to start reviewing it.
Low Pickup Time represents strong teamwork and a healthy review process. When a PR is picked up and reviewed within 24 hours, the code is still fresh in the mind of the developer. This reduction of cognitive load saves a significant amount of refocus time.
Long Pickup Time is an indication of a common workflow bottleneck. Either the team isn’t aware a PR is ready for review or there aren’t enough developers taking on reviews. In both instances, a longer transition time between handoffs correlates to higher cognitive load (re-focus time) and reduced efficiency.
Review Time:
Measures the time it takes to complete a code review and get a pull request merged.
Low Review Time correlates to small PR sizes, reduced code complexity and short Cycle Time. The caveat here is to make sure your Review Depth (the number of comments per review) is consistent between two and four.
Long Review Time indicates large PR sizes, a lack of focus time and/or quality issues. Regular interruptions during a large PR review increase Review Time due to the developer needing to “get back into” the task. In a similar light, the longer a PR review takes, the less fresh the code will be in the mind of the owning developer. High rework rates also correlate to long review times.
Deploy Time:
Measures the time from when a branch is merged to when the code is released.
Low Deploy Time correlates to high deployment frequency and a more stable production environment. Modern development practices like CI/CD and automated testing improve the time to production and the feedback loop from users.
High Deploy Time correlates to manual efforts and low code quality. Build failures can be reduced by standardizing small PR sizes and a thorough PR review process.
Rework Rate:
Measures the amount of changes made to code that is less than 21 days old.
Low Rework Rates are an indication of higher overall code quality and a strong PR review process.
High Rework Rates signal code churn and is a leading indicator of quality issues.
Planning Accuracy:
Measures the ratio of planned work vs. what is actually delivered during a sprint or iteration.
High Planning Accuracy indicates a high level of predictability. Predictability within a sprint or larger project allows teams to deliver what they promised to deliver, on time.
Low Planning Accuracy is an indication of unplanned work, shadow work and high code churn. Missed delivery deadlines and high carryover are the most common result of low planning accuracy.

Deployment Frequency:
Measures how often code is released.
High Deployment Frequency represents a stable and healthy continuous delivery pipeline. Elite development teams are deploying small chunks of code to production multiple times a day to improve the user experience and shorten the feedback loop.
Low Deployment Frequency is an indicator of large deployment events that increase the likelihood of production instability.
PR Size:
Measures the number of code lines modified in a pull request.
Small PR Sizes are easier to review, safer to merge, and correlate to a lower Cycle Time.
Large PR Sizes directly correlate to higher Cycle Time and code complexity. High PR sizes are the most common cause of a high Cycle Time.
Understanding your team’s current performance is the first step to creating a culture of continuous improvement. If you’re ready to discover how your team performs against industry standards today, use this link to book a free engineering metrics benchmarks consultation.
Published at DZone with permission of Necco Ceresani, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments