Key Considerations for Effective AI/ML Deployments in Kubernetes
Learn about managing AI/ML workloads in Kubernetes and follow a step-by-step tutorial for deploying a sample TensorFlow-based sentiment analysis model.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Kubernetes in the Enterprise: Once Decade-Defining, Now Forging a Future in the SDLC.
Kubernetes has become a cornerstone in modern infrastructure, particularly for deploying, scaling, and managing artificial intelligence and machine learning (AI/ML) workloads. As organizations increasingly rely on machine learning models for critical tasks like data processing, model training, and inference, Kubernetes offers the flexibility and scalability needed to manage these complex workloads efficiently. By leveraging Kubernetes' robust ecosystem, AI/ML workloads can be dynamically orchestrated, ensuring optimal resource utilization and high availability across cloud environments. This synergy between Kubernetes and AI/ML empowers organizations to deploy and scale their ML workloads with greater agility and reliability.
This article delves into the key aspects of managing AI/ML workloads within Kubernetes, focusing on strategies for resource allocation, scaling, and automation specific to this platform. By addressing the unique demands of AI/ML tasks in a Kubernetes environment, it provides practical insights to help organizations optimize their ML operations. Whether handling resource-intensive computations or automating deployments, this guide offers actionable advice for leveraging Kubernetes to enhance the performance, efficiency, and reliability of AI/ML workflows, making it an indispensable tool for modern enterprises.
Understanding Kubernetes and AI/ML Workloads
In order to effectively manage AI/ML workloads in Kubernetes, it is important to first understand the architecture and components of the platform.
Overview of Kubernetes Architecture
Kubernetes architecture is designed to manage containerized applications at scale. The architecture is built around two main components: the control plane (coordinator nodes) and the worker nodes.
Figure 1. Kubernetes architecture
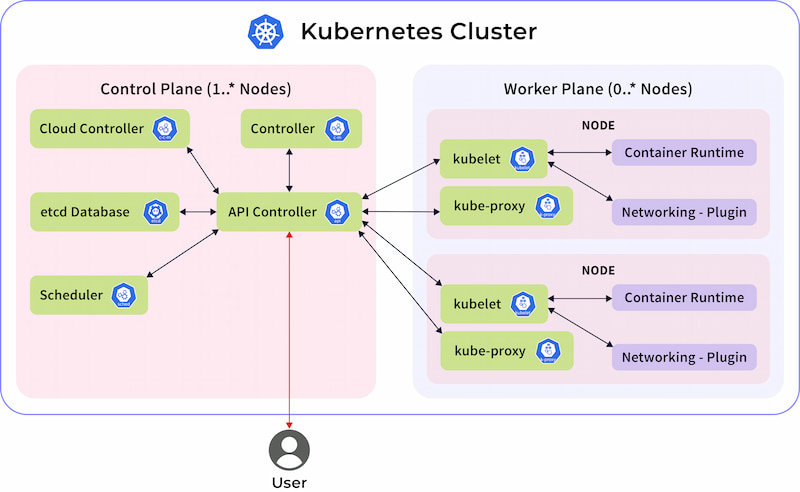
For more information, or to review the individual components of the architecture in Figure 1, check out the Kubernetes Documentation.
AI/ML Workloads: Model Training, Inference, and Data Processing
AI/ML workloads are computational tasks that involve training machine learning models, making predictions (inference) based on those models, and processing large datasets to derive insights. AI/ML workloads are essential for driving innovation and making data-driven decisions in modern enterprises:
- Model training enables systems to learn from vast datasets, uncovering patterns that power intelligent applications.
- Inference allows these models to generate real-time predictions, enhancing user experiences and automating decision-making processes.
- Efficient data processing is crucial for transforming raw data into actionable insights, fueling the entire AI/ML pipeline.
However, managing these computationally intensive tasks requires a robust infrastructure. This is where Kubernetes comes into play, providing the scalability, automation, and resource management needed to handle AI/ML workloads effectively, ensuring they run seamlessly in production environments.
Key Considerations for Managing AI/ML Workloads in Kubernetes
Successfully managing AI/ML workloads in Kubernetes requires careful attention to several critical factors. This section outlines the key considerations for ensuring that your AI/ML workloads are optimized for performance and reliability within a Kubernetes environment.
Resource Management
Effective resource management is crucial when deploying AI/ML workloads on Kubernetes. AI/ML tasks, particularly model training and inference, are resource intensive and often require specialized hardware such as GPUs or TPUs. Kubernetes allows for the efficient allocation of CPU, memory, and GPUs through resource requests and limits. These configurations ensure that containers have the necessary resources while preventing them from monopolizing node capacity.
Additionally, Kubernetes supports the use of node selectors and taints/tolerations to assign workloads to nodes with the required hardware (e.g., GPU nodes). Managing resources efficiently helps optimize cluster performance, ensuring that AI/ML tasks run smoothly without over-provisioning or under-utilizing the infrastructure. Handling resource-intensive tasks requires careful planning, particularly when managing distributed training jobs that need to run across multiple nodes. These workloads benefit from Kubernetes' ability to distribute resources while ensuring that high-priority tasks receive adequate computational power.
Scalability
Scalability is another critical factor in managing AI/ML workloads in Kubernetes. Horizontal scaling, where additional Pods are added to handle increased demand, is particularly useful for stateless workloads like inference tasks that can be easily distributed across multiple Pods. Vertical scaling, which involves increasing the resources available to a single Pod (e.g., more CPU or memory), can be beneficial for resource-intensive processes like model training that require more power to handle large datasets.
In addition to Pod autoscaling, Kubernetes clusters benefit from cluster autoscaling to dynamically adjust the number of worker nodes based on demand. Karpenter is particularly suited for AI/ML workloads due to its ability to quickly provision and scale nodes based on real-time resource needs. Karpenter optimizes node placement by selecting the most appropriate instance types and regions, taking into account workload requirements like GPU or memory needs. By leveraging Karpenter, Kubernetes clusters can efficiently scale up during resource-intensive AI/ML tasks, ensuring that workloads have sufficient capacity without over-provisioning resources during idle times. This leads to improved cost efficiency and resource utilization, especially for complex AI/ML operations that require on-demand scalability.
These autoscaling mechanisms enable Kubernetes to dynamically adjust to workload demands, optimizing both cost and performance.
Data Management
AI/ML workloads often require access to large datasets and persistent storage for model checkpoints and logs. Kubernetes offers several persistent storage options to accommodate these needs, including PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs). These options allow workloads to access durable storage across various cloud and on-premises environments. Additionally, Kubernetes integrates with cloud storage solutions like AWS EBS, Google Cloud Storage, and Azure Disk Storage, making it easier to manage storage in hybrid or multi-cloud setups.
Handling large volumes of training data requires efficient data pipelines that can stream or batch process data into models running within the cluster. This can involve integrating with external systems, such as distributed file systems or databases, and using tools like Apache Kafka for real-time data ingestion. Properly managing data is essential for maintaining high-performance AI/ML pipelines, ensuring that models have quick and reliable access to the data they need for both training and inference.
Deployment Automation
Automation is key to managing the complexity of AI/ML workflows, particularly when deploying models into production. CI/CD pipelines can automate the build, test, and deployment processes, ensuring that models are continuously integrated and deployed with minimal manual intervention. Kubernetes integrates well with CI/CD tools like Jenkins, GitLab CI/CD, and Argo CD, enabling seamless automation of model deployments. Tools and best practices for automating AI/ML deployments include using Helm for managing Kubernetes manifests, Kustomize for configuration management, and Kubeflow for orchestrating ML workflows. These tools help standardize the deployment process, reduce errors, and ensure consistency across environments. By automating deployment, organizations can rapidly iterate on AI/ML models, respond to new data, and scale their operations efficiently, all while maintaining the agility needed in fast-paced AI/ML projects.
Scheduling and Orchestration
Scheduling and orchestration for AI/ML workloads require more nuanced approaches compared to traditional applications. Kubernetes excels at managing these different scheduling needs through its flexible and powerful scheduling mechanisms. Batch scheduling is typically used for tasks like model training, where large datasets are processed in chunks. Kubernetes supports batch scheduling by allowing these jobs to be queued and executed when resources are available, making them ideal for non-critical workloads that are not time sensitive. Kubernetes Job and CronJob resources are particularly useful for automating the execution of batch jobs based on specific conditions or schedules.
On the other hand, real-time processing is used for tasks like model inference, where latency is critical. Kubernetes ensures low latency by providing mechanisms such as Pod priority and preemption, ensuring that real-time workloads have immediate access to the necessary resources. Additionally, Kubernetes' HorizontalPodAutoscaler can dynamically adjust the number of pods to meet demand, further supporting the needs of real-time processing tasks. By leveraging these Kubernetes features, organizations can ensure that both batch and real-time AI/ML workloads are executed efficiently and effectively.
Gang scheduling is another important concept for distributed training in AI/ML workloads. Distributed training involves breaking down model training tasks across multiple nodes to reduce training time, and gang scheduling ensures that all the required resources across nodes are scheduled simultaneously. This is crucial for distributed training, where all parts of the job must start together to function correctly. Without gang scheduling, some tasks might start while others are still waiting for resources, leading to inefficiencies and extended training times. Kubernetes supports gang scheduling through custom schedulers like Volcano, which is designed for high-performance computing and ML workloads.
Latency and Throughput
Performance considerations for AI/ML workloads go beyond just resource allocation; they also involve optimizing for latency and throughput.
Latency refers to the time it takes for a task to be processed, which is critical for real-time AI/ML workloads such as model inference. Ensuring low latency is essential for applications like online recommendations, fraud detection, or any use case where real-time decision making is required. Kubernetes can manage latency by prioritizing real-time workloads, using features like node affinity to ensure that inference tasks are placed on nodes with the least network hops or proximity to data sources.
Throughput, on the other hand, refers to the number of tasks that can be processed within a given time frame. For AI/ML workloads, especially in scenarios like batch processing or distributed training, high throughput is crucial. Optimizing throughput often involves scaling out workloads horizontally across multiple Pods and nodes. Kubernetes' autoscaling capabilities, combined with optimized scheduling, ensure that AI/ML workloads maintain high throughput — even as demand increases. Achieving the right balance between latency and throughput is vital for the efficiency of AI/ML pipelines, ensuring that models perform at their best while meeting real-world application demands.
A Step-by-Step Guide: Deploying TensorFlow Sentiment Analysis Model on AWS EKS
In this example, we demonstrate how to deploy a TensorFlow-based sentiment analysis model using AWS Elastic Kubernetes Service (EKS). This hands-on guide will walk you through setting up a Flask-based Python application, containerizing it with Docker, and deploying it on AWS EKS using Kubernetes. Although many tools are suitable, TensorFlow was chosen for this example due to its popularity and robustness in developing AI/ML models, while AWS EKS provides a scalable and managed Kubernetes environment that simplifies the deployment process.
By following this guide, readers will gain practical insights into deploying AI/ML models in a cloud-native environment, leveraging Kubernetes for efficient resource management and scalability.
Step 1: Create a Flask-based Python app setup
Create a Flask app (app.py) using the Hugging Face transformers pipeline for sentiment analysis:
from flask import Flask, request, jsonify
from transformers import pipeline
app = Flask(__name__)
sentiment_model = pipeline("sentiment-analysis")
@app.route('/analyze', methods=['POST'])
def analyze():
data = request.get_json()
result = sentiment_model(data['text'])
return jsonify(result)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)Step 2: Create requirements.txt
transformers==4.24.0
torch==1.12.1
flask
jinja2
markupsafe==2.0.1Step 3: Build Docker image
Create a Dockerfile to containerize the app:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["python", "app.py"]Build and push the Docker image:
docker build -t brainupgrade/aiml-sentiment:20240825 .
docker push brainupgrade/aiml-sentiment:20240825Step 4: Deploy to AWS EKS with Karpenter
Create a Kubernetes Deployment manifest (deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: sentiment-analysis
spec:
replicas: 1
selector:
matchLabels:
app: sentiment-analysis
template:
metadata:
labels:
app: sentiment-analysis
spec:
containers:
- name: sentiment-analysis
image: brainupgrade/aiml-sentiment:20240825
ports:
- containerPort: 5000
resources:
requests:
aws.amazon.com/neuron: 1
limits:
aws.amazon.com/neuron: 1
tolerations:
- key: "aiml"
operator: "Equal"
value: "true"
effect: "NoSchedule"Apply the Deployment to the EKS cluster:
kubectl apply -f deployment.yamlKarpenter will automatically scale the cluster and launch an inf1.xlarge EC2 instance based on the resource specification (aws.amazon.com/neuron: 1). Karpenter also installs appropriate device drivers for this special AWS EC2 instance of inf1.xlarge, which is optimized for deep learning inference, featuring four vCPUs, 16 GiB RAM, and one Inferentia chip.
Reference Karpenter spec as follows:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
limits:
resources:
cpu: "16"
provider:
instanceProfile: eksctl-KarpenterNodeInstanceProfile-<cluster-name>
securityGroupSelector:
karpenter.sh/discovery: <cluster-name>
subnetSelector:
karpenter.sh/discovery: <cluster-name>
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- key: node.kubernetes.io/instance-type
operator: In
values:
- inf1.xlarge
- key: kubernetes.io/os
operator: In
values:
- linux
- key: kubernetes.io/arch
operator: In
values:
- amd64
ttlSecondsAfterEmpty: 30Step 5: Test the application
Once deployed and exposed via an AWS Load Balancer or Ingress, test the app with the following cURL command:
curl -X POST -H "Content-Type: application/json" -d '{"text":"I love using this product!"}' https://<app-url>/analyzeThis command sends a sentiment analysis request to the deployed model endpoint: https://<app-url>/analyze.
Challenges and Solutions
Managing AI/ML workloads in Kubernetes comes with its own set of challenges, from handling ephemeral containers to ensuring security and maintaining observability. In this section, we will explore these challenges in detail and provide practical solutions to help you effectively manage AI/ML workloads in a Kubernetes environment.
Maintaining State in Ephemeral Containers
One of the main challenges in managing AI/ML workloads in Kubernetes is handling ephemeral containers while maintaining state. Containers are designed to be stateless, which can complicate AI/ML workflows that require persistent storage for datasets, model checkpoints, or intermediate outputs. For maintaining state in ephemeral containers, Kubernetes offers PVs and PVCs, which enable long-term storage for AI/ML workloads, even if the containers themselves are short-lived.
Ensuring Security and Compliance
Another significant challenge is ensuring security and compliance. AI/ML workloads often involve sensitive data, and maintaining security at multiple levels — network, access control, and data integrity — is crucial for meeting compliance standards. To address security challenges, Kubernetes provides role-based access control (RBAC) and NetworkPolicies. RBAC ensures that users and services have only the necessary permissions, minimizing security risks. NetworkPolicies allow for fine-grained control over network traffic, ensuring that sensitive data remains protected within the cluster.
Observability in Kubernetes Environments
Additionally, observability is a key challenge in Kubernetes environments. AI/ML workloads can be complex, with numerous microservices and components, making it difficult to monitor performance, track resource usage, and detect potential issues in real time. Monitoring and logging are essential for observability in Kubernetes. Tools like Prometheus and Grafana provide robust solutions for monitoring system health, resource usage, and performance metrics. Prometheus can collect real-time metrics from AI/ML workloads, while Grafana visualizes this data, offering actionable insights for administrators. Together, they enable proactive monitoring, allowing teams to identify and address potential issues before they impact operations.
Conclusion
In this article, we explored the key considerations for managing AI/ML workloads in Kubernetes, focusing on resource management, scalability, data handling, and deployment automation. We covered essential concepts like efficient CPU, GPU, and TPU allocation, scaling mechanisms, and the use of persistent storage to support AI/ML workflows. Additionally, we examined how Kubernetes uses features like RBAC and NetworkPolicies and tools like Prometheus and Grafana to ensure security, observability, and monitoring for AI/ML workloads.
Looking ahead, AI/ML workload management in Kubernetes is expected to evolve with advancements in hardware accelerators and more intelligent autoscaling solutions like Karpenter. Integration of AI-driven orchestration tools and the emergence of Kubernetes-native ML frameworks will further streamline and optimize AI/ML operations, making it easier to scale complex models and handle ever-growing data demands.
For practitioners, staying informed about the latest Kubernetes tools and best practices is crucial. Continuous learning and adaptation to new technologies will empower you to manage AI/ML workloads efficiently, ensuring robust, scalable, and high-performance applications in production environments.
This is an excerpt from DZone's 2024 Trend Report, Kubernetes in the Enterprise: Once Decade-Defining, Now Forging a Future in the SDLC.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments