JIT Compilation of SQL in NoSQL
Go on a journey of JIT compilation for SQL queries.
Join the DZone community and get the full member experience.
Join For FreeHi everyone! My name is Georgy Lebedev, and I'm a part of Tarantool's kernel development team. In 2021, we participated in the Google Summer of Code (GSoC) for the first time: one of the proposed projects was migration of SQL from VDBE to a JIT platform — that's where my journey in Tarantool began.
Having a year of developing various toolchain components as educational projects under my belt and armed with the support of mentors (Nikita Pettik, Timur Safin, and Igor Munkin), I took on this project. While building a platform for JIT compilation of SQL queries in Tarantool virtually from scratch during just one summer, I have encountered some pitfalls and acquired, in my opinion, interesting knowledge and experience which I would like to share. This article will be of interest first and foremost to those who are interested in further maintaining this project, as well as to those who are considering implementing JIT compilation in their own SQL.
What I Had to Work With
To support the SQL language, Tarantool uses a virtual machine (VM) inherited from SQLite. It is also known as the Virtual Database Engine (VDBE). The schematic of this component:

One of the most popular ways to implement virtual machines is to operate with a bytecode stream of instructions; VDBE is based on that principle. In this article, we will be looking at bytecode as an intermediate representation for virtual machines and its interpretation. Further on, speaking about bytecode and SQL VM implementation in Tarantool, I will be referring to VDBE.
Bytecode interpretation is represented by a for loop over an array of opcodes (a bytecode program generated by a SQL query) and a switch by the opcode's type:
for(pOp = &aOp[p->pc]; 1; pOp++) {
switch (pOp->opcode) {
...
}
}Our Task
In terms of the application server, Tarantool already has a virtual machine, LuaJIT. Another handwritten VM (without using frameworks to build the execution environment) to support SQL just doesn't look very graceful from an architectural perspective, not to mention the performance issues that it introduces.
The project suggested exploring one of the following possible alternatives to the VDBE:
Expected results:
- Test the idea of migrating VDBE to the selected JIT platform
- Examine different scenarios for applying JIT compilation in the context of SQL
- Measure the performance of JIT compilation via different SQL benchmarks
Since it seemed impossible to solve this problem in the given timeframe of three summer months, and Tarantool already had the first approach to this task through a 3-year-old patch based on LLVM ORC, I decided to use this framework and continue to develop Nikita Pettik's idea. In addition, there was the successful example of Postgres, which already implemented such a platform based on this framework.
And now there is also another DBMS, ClickHouse, which also implements a JIT platform for SQL based on LLVM ORC.
JIT Compilation of SQL
JIT compilation is by no means a cure-all: this approach has its drawbacks and does not always provide results superior to bytecode interpretation, which is why JIT compilation has a rather limited set of applications.
Its main advantages are:
- Fewer jump instructions and localization of native code, which makes the best use of branch predictor
- Lower number of branches and less machine code due to specialization
- Higher performance for bytecode hot spots, which are bottlenecks in CPU processing
- Better use of CPU caches
- Generation of instructions for the target processor
- Room for optimization of the generated IR (intermediate representation)
In the context of SQL, we can distinguish the main scenario of using JIT compilation: heavy analytical DQL (data query language) queries that contain lots of logic and expressions.
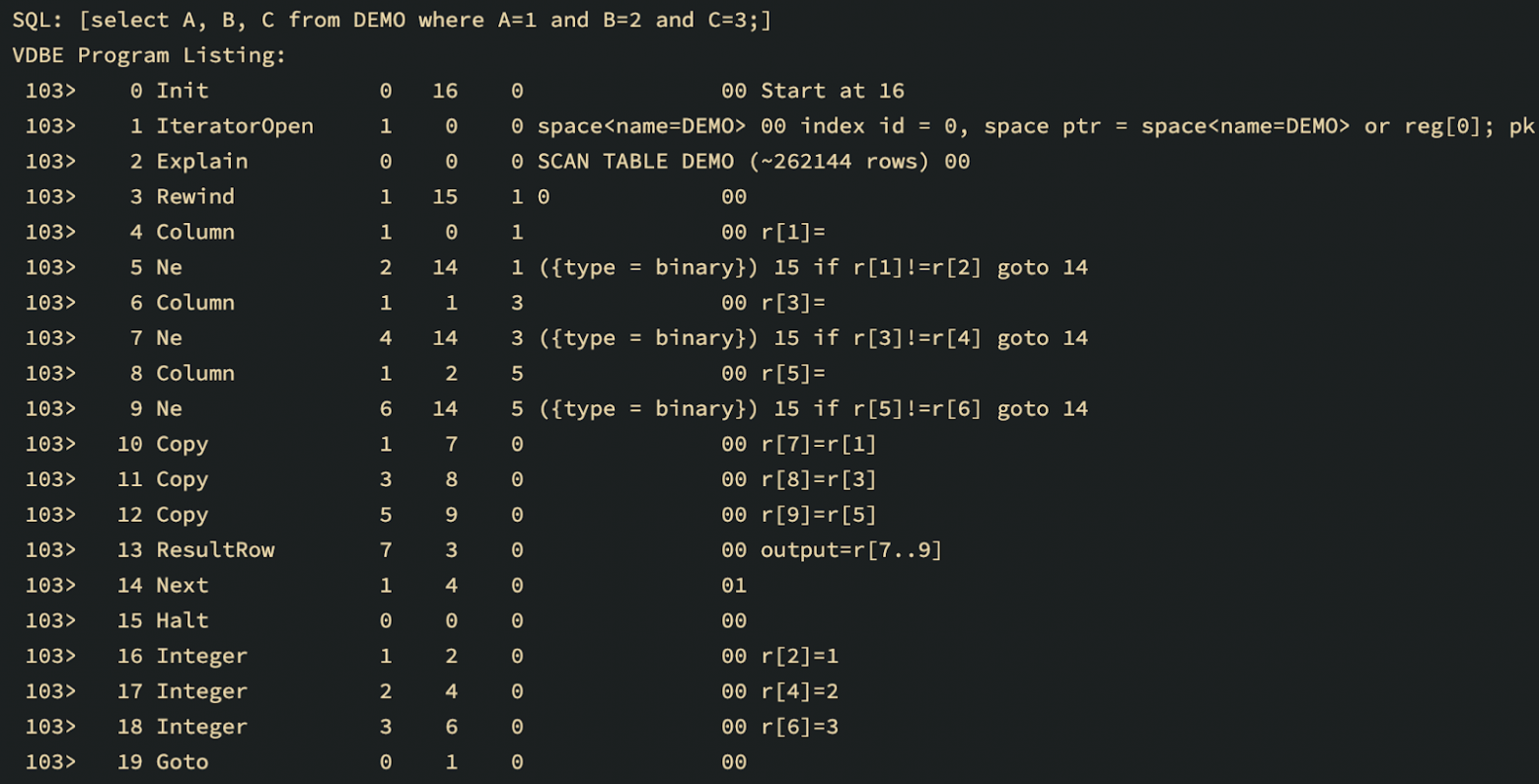
Such queries are merely bytecode sequences executed repeatedly in a loop. Such sequence can be merged into a single opcode, which would constitute a call to a native code function, making it an ideal case for applying JIT compilation.
We can highlight a handful of computational scenarios where this would be useful:
- Decoding tuples (Tarantool term for rows)
- Arithmetic and logical expressions of various kinds
- Aggregate functions
Here, aggregate functions are an especially interesting case as they are computed via separate loops — again, a very fitting condition for JIT compilation.
I highlighted some of the project's additional angles and challenges in my final report for GSoC.
The following is a summary of what I believe to be the most important conclusions I drew from my work on this project.
LLVM ORC
Using a third-party framework for JIT compilation, albeit with its own IR, allowed abstracting from the tasks of generating, optimizing, and storing native code. That helped to focus on generating LLVM IR and embedding the JIT compiler into the existing SQL infrastructure.
To Inline, or not to Inline, That is the Question
Embedding JIT compilation in SQL infrastructure raises the question of how to generate LLVM IR that is functionally equivalent to interpreting opcodes in C. There are two fundamentally different approaches:
- Completely manual generation of LLVM IR for each opcode (Postgres)
- Automatic generation via clang (Postgres)
In Postgres, the second approach is used only for built-in functions and operators.
In my opinion, the first approach is equivalent to writing assembler code: quite time-consuming and error-prone. Besides, it would be simply dull to do some mechanical work instead of an innovative summer project. I chose the following strategy: wrap the existing code blocks for SQL opcodes in callbacks called in the JIT-compiled code—this also allows getting rid of rather non-trivial code duplication in the first approach.
A reasonable question arises here: what about code specialization and other advantages of JIT compilation, which we seem to be deprived of by using such an approach? That's where the inlining features of LLVM were supposed to come to the rescue: as it turned out, the C API I was using, a small subset of the C++ API of LLVM, had no such features at all, and they were only introduced in version 13 of LLVM.

In addition, even to apply the C++ API, you need to build a whole infrastructure to:
- Store, index and load the bitcode generated by clang
- Search through bitcode modules (units of translation in LLVM) to find the necessary callbacks and pass their IR between modules
- Explicitly inline callbacks
A good example of how to implement such infrastructure is Postgres.
Patching the generated LLVM IR
There is an important detail in JIT compilation of SQL in Tarantool: some VBDE opcodes are patched when the bytecode is generated. For instance, this is useful for optimization—direct table reads can be replaced by reads from an index:
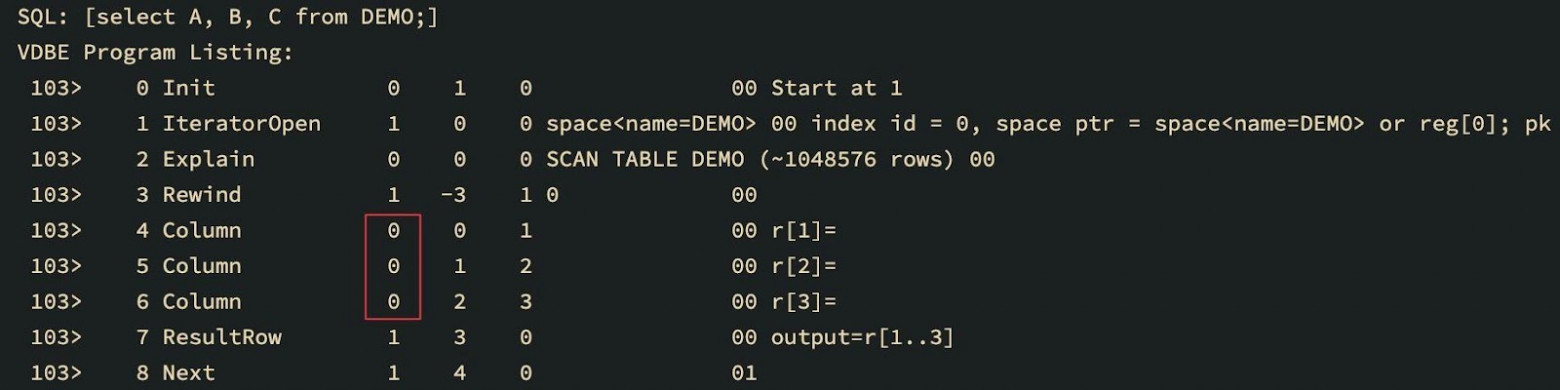
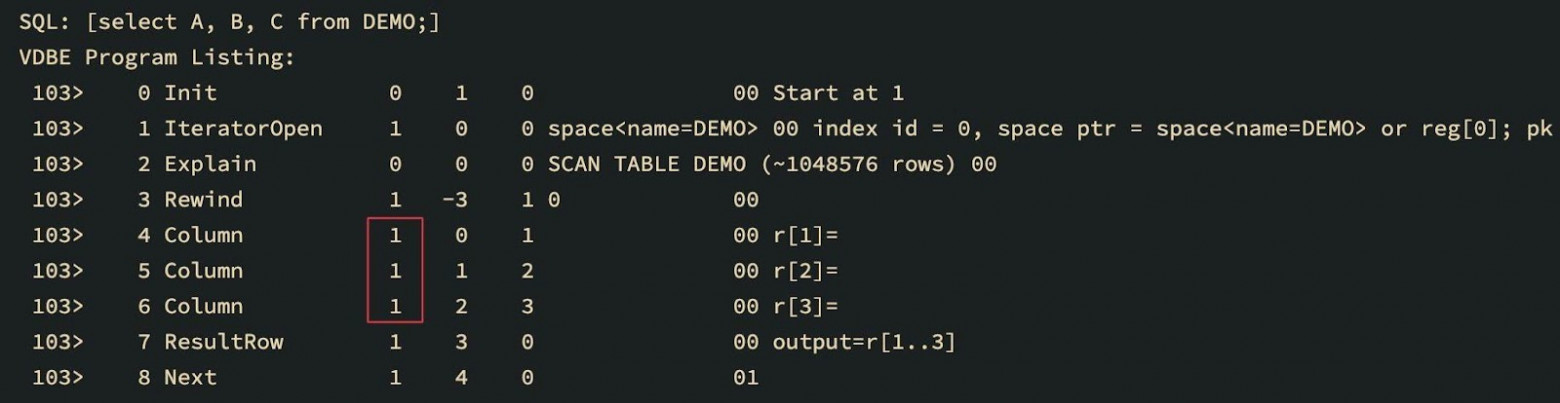
You can see that the first argument corresponding to the cursor number has changed for all Column opcodes.
Another reason to patch bytecode instructions might be coroutines used for subqueries. The bytecode that loads columns from the coroutine table must be changed to a bytecode that copies columns from the registers of the returned coroutine values:
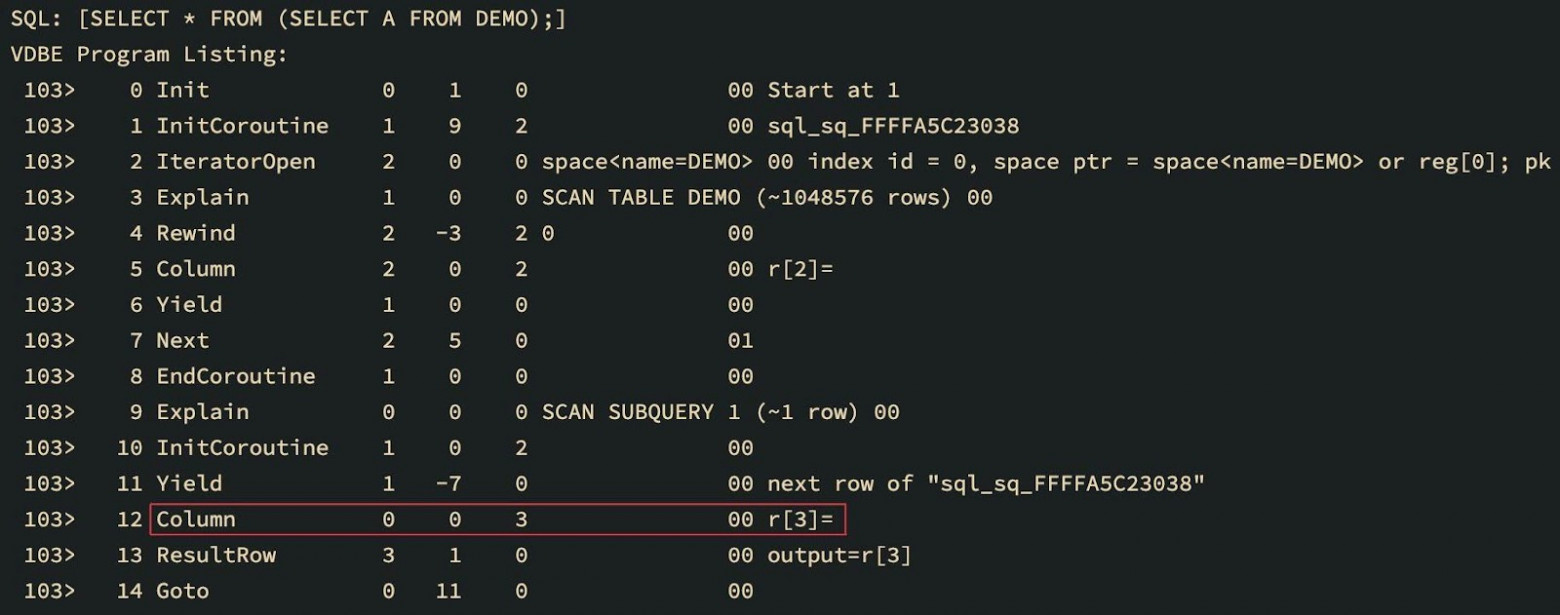
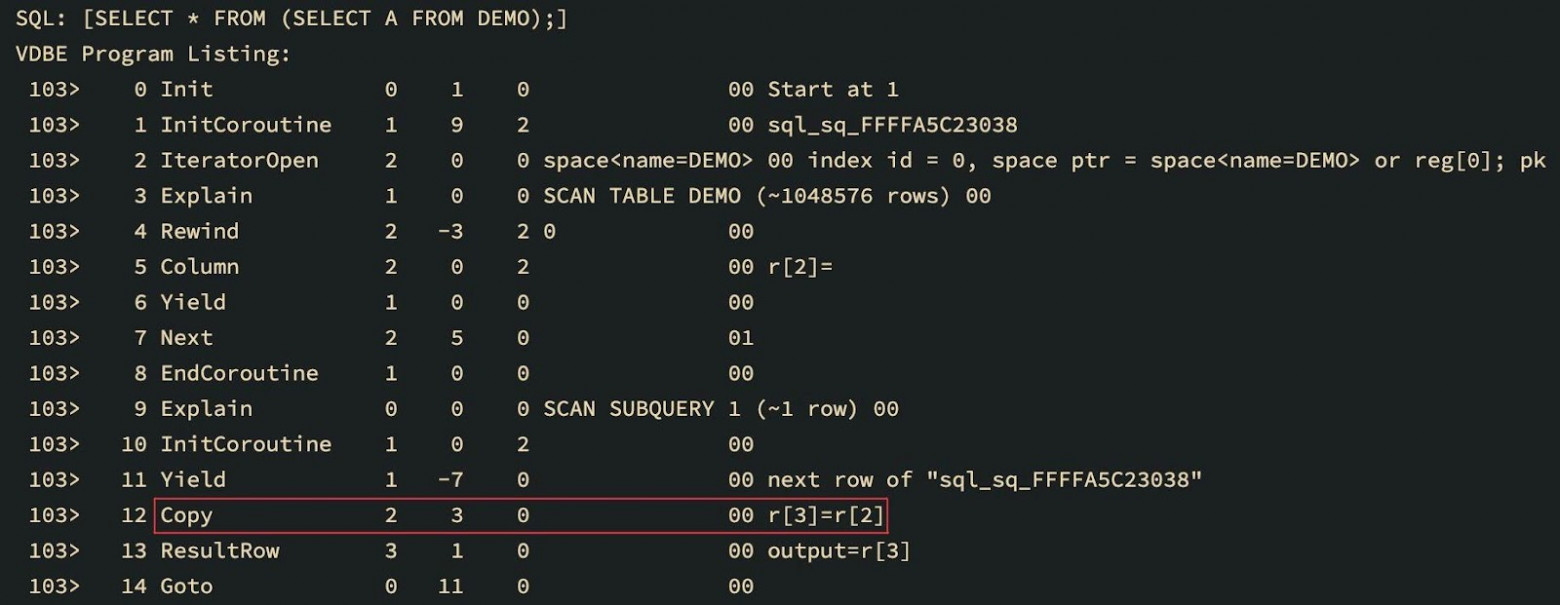
The same circumstances should be reflected in the generated LLVM IR. From the IR point of view, a solution to this problem is evident: use a separate base block for each opcode. This will make analysis, search, and patching of the required instructions much easier. It could even allow throwing entire blocks away and replacing them with other blocks. And all of it is non-linear!
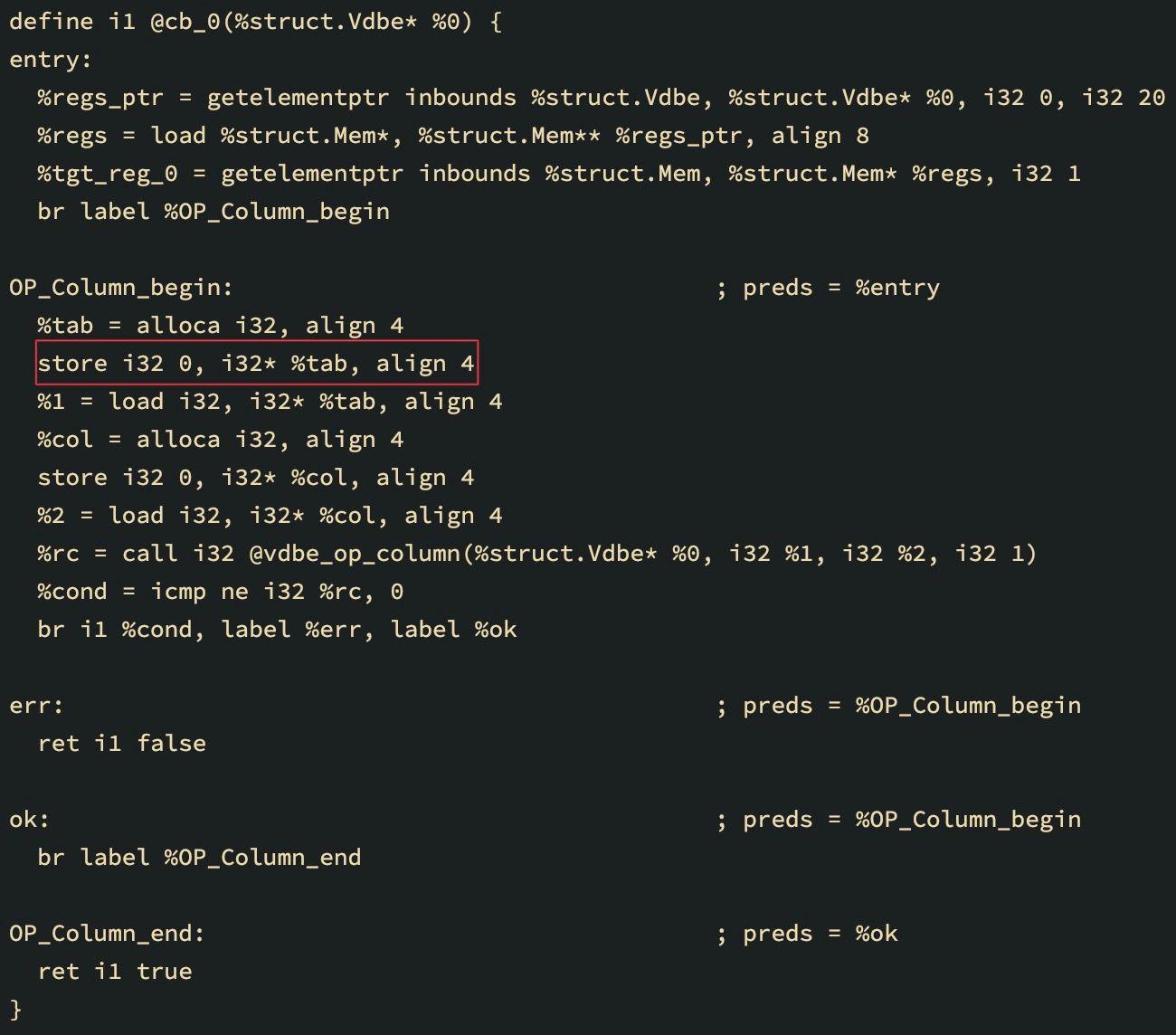
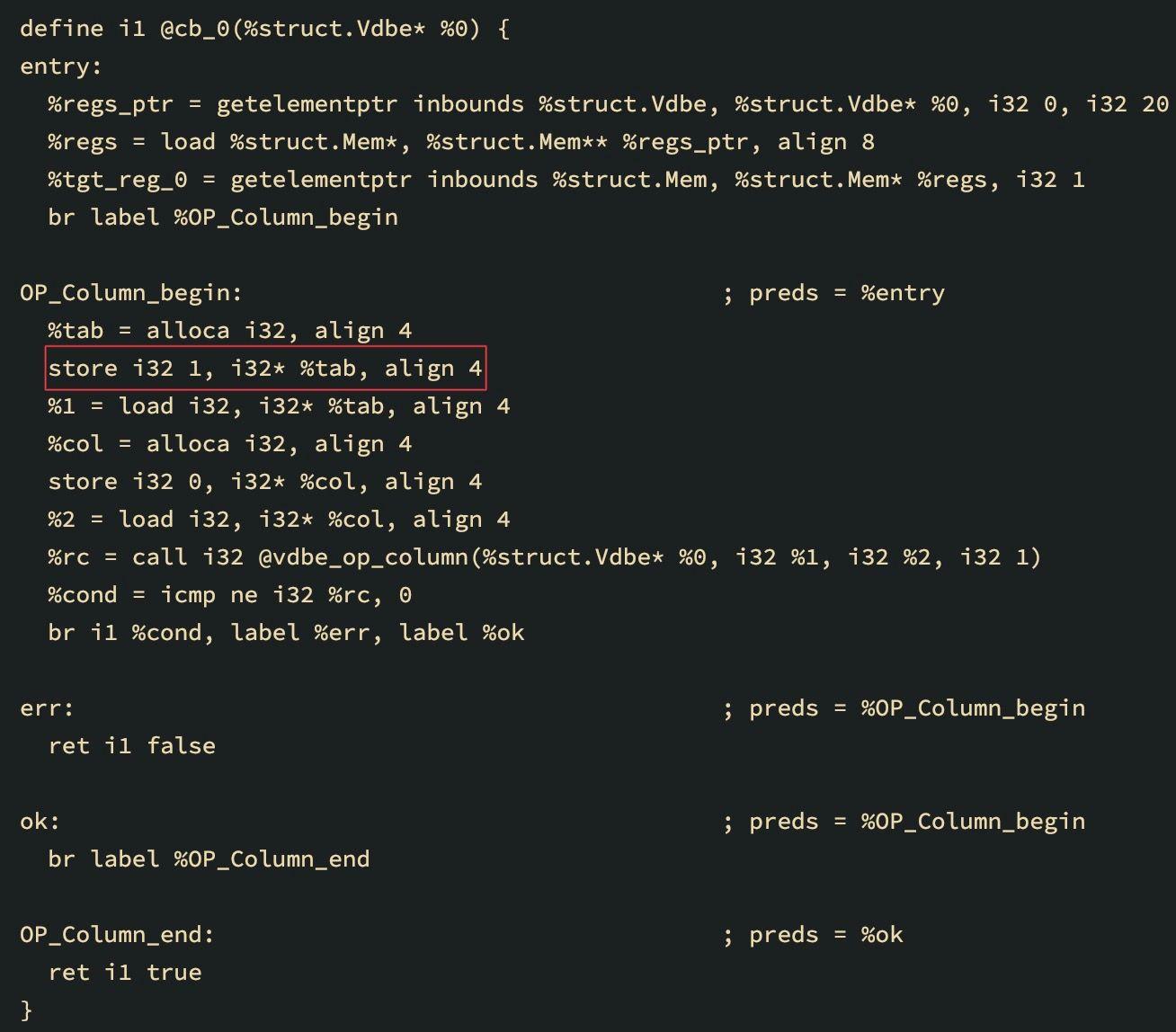
The LLVM IR above for the select A from DEMO query corresponds to loading a column into the register. You can see how the value of the store instruction argument in the base block OP_Column_begin has changed:
store i32 1, i32* %tab, align 4
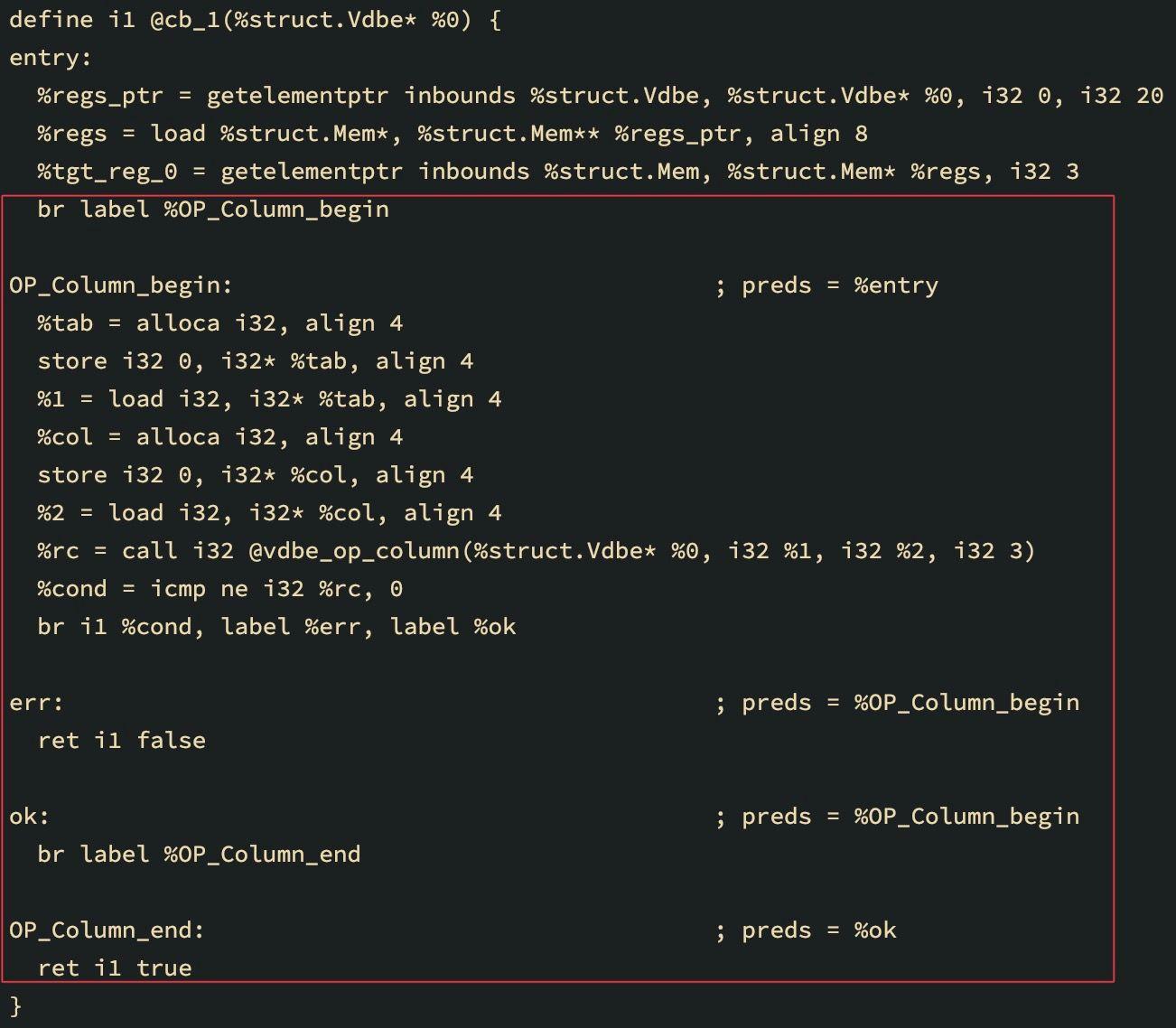
The LLVM IR below is generated for the select * from (select A from DEMO) query using a coroutine:
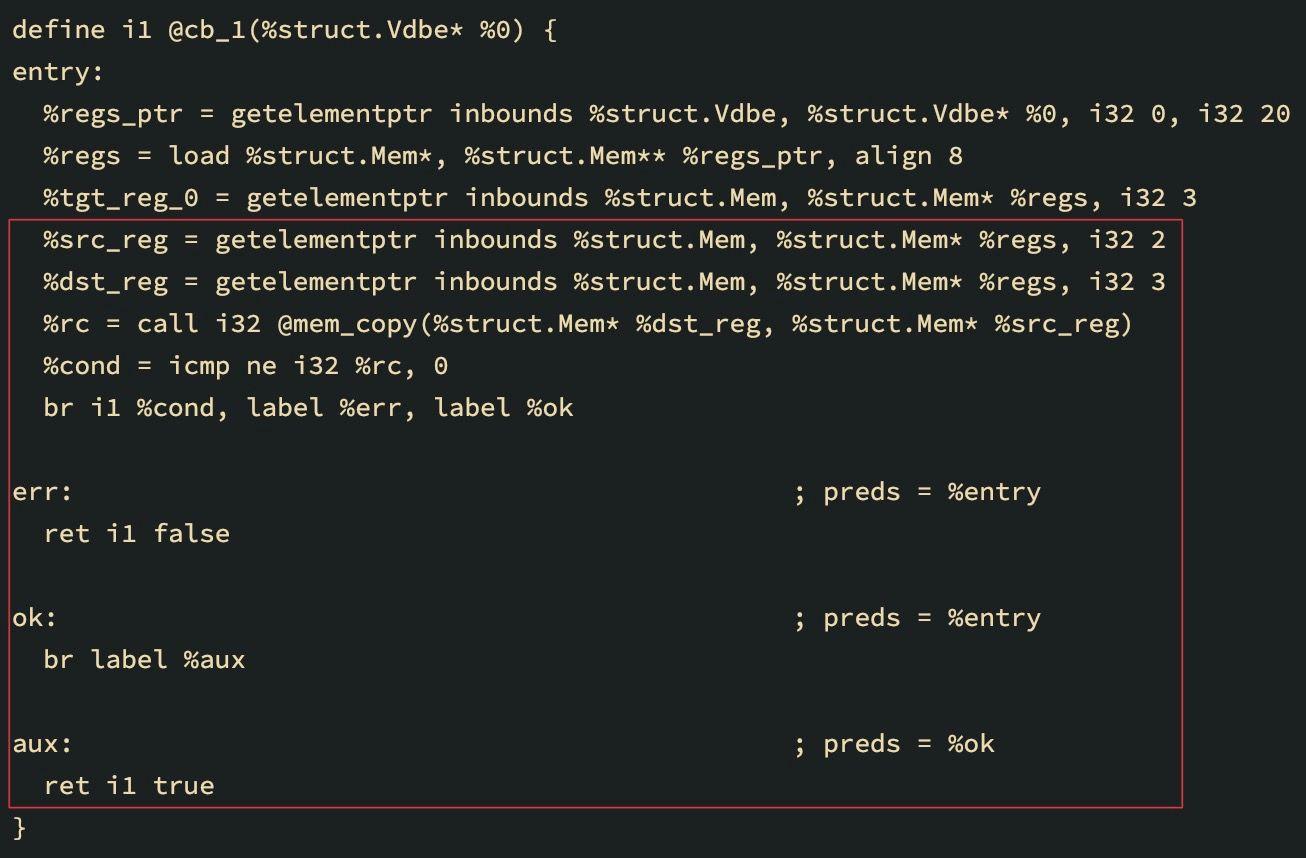
SQL Benchmarks
The final part of the project was measuring performance in standard SQL benchmarks. I took TPC-H as the most representative: it reflects the typical analytical SQL queries.
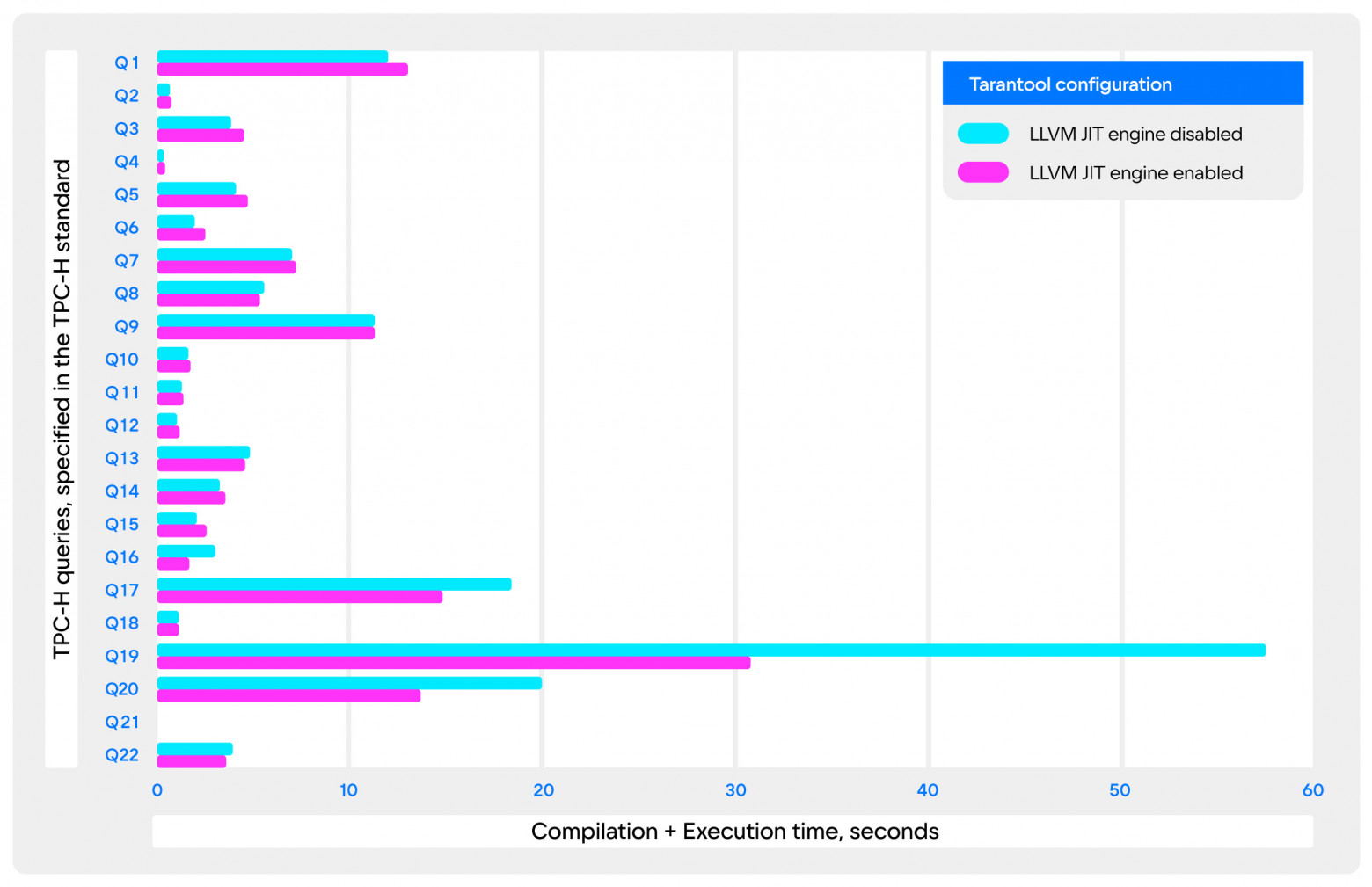
These measurements also took into account the analysis and compilation time of the queries, while normally JIT compilation is supposed to be used only for prepared queries. If we neglect these overheads, we can assume that there is no performance loss with JIT compilation.
Unfortunately, due to the fact that I did not have time to make a JIT compilation of arithmetic expressions, and most queries in TPC-H contain them in large numbers, there wasn't much to see in action. Only Q17, Q19, and Q20 queries were suitable. The most remarkable among them is Q19: it contains a huge number of column links and literals—the increase in performance was almost twofold!
Results
- Patchset with platform for JIT compilation of SQL based on version 12 of LLVM ORC.
- JIT compilation of different SELECT expressions: literals, column references and aggregate columns.
- JIT compilation of aggregate functions (e.g., SUM, COUNT, AVG) with some restrictions on query complexity.
- The TPC-H benchmark showed a significant increase in performance on some types of queries and no noticeable degradation in the rest.
Opinions expressed by DZone contributors are their own.
Comments