Distributed SQL: An Alternative to Database Sharding
Distributed SQL databases are designed from the ground up to scale almost linearly. In this article, learn the basics of distributed SQL and how to get started.
Join the DZone community and get the full member experience.
Join For FreeDatabase sharding is the process of dividing data into smaller pieces called "shards." Sharding is typically introduced when there’s a need to scale writes. During the lifespan of a successful application, the database server will hit the maximum number of writes it can perform either at the processing or capacity level. Slicing the data into multiple shards—each one on its own database server—reduces the stress on each individual node, effectively increasing the write capacity of the overall database. This is what database sharding is.
Distributed SQL is the new way to scale relational databases with a sharding-like strategy that's fully automated and transparent to applications. Distributed SQL databases are designed from the ground up to scale almost linearly. In this article, you'll learn the basics of distributed SQL and how to get started.
Disadvantages of Database Sharding
Sharding introduces a number of challenges:
- Data partitioning: Deciding how to partition data across multiple shards can be a challenge, as it requires finding a balance between data proximity and even distribution of data to avoid hotspots.
- Failure handling: If a key node fails and there are not enough shards to carry the load, how do you get the data on a new node without downtime?
- Query complexity: Application code is coupled to the data-sharding logic and queries that require data from multiple nodes need to be re-joined.
- Data consistency: Ensuring data consistency across multiple shards can be a challenge, as it requires coordinating updates to the data across shards. This can be particularly difficult when updates are made concurrently, as it may be necessary to resolve conflicts between different writes.
- Elastic scalability: As the volume of data or the number of queries increases, it may be necessary to add additional shards to the database. This can be a complex process with unavoidable downtime, requiring manual processes to relocate data evenly across all shards.
Some of these disadvantages can be alleviated by adopting polyglot persistence (using different databases for different workloads), database storage engines with native sharding capabilities, or database proxies. However, while helping with some of the challenges in database sharding, these tools have limitations and introduce complexity that requires constant management.
What Is Distributed SQL?
Distributed SQL refers to a new generation of relational databases. In simple terms, a distributed SQL database is a relational database with transparent sharding that looks like a single logical database to applications. Distributed SQL databases are implemented as a shared-nothing architecture and a storage engine that scales both reads and writes while maintaining true ACID compliance and high availability. Distributed SQL databases have the scalability features of NoSQL databases—which gained popularity in the 2000s—but don’t sacrifice consistency. They keep the benefits of relational databases and add cloud compatibility with multi-region resilience.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
How Does Distributed SQL Work?
To understand how Distributed SQL works, let’s take the case of MariaDB Xpand—a distributed SQL database compatible with the open-source MariaDB database. Xpand works by slicing the data and indexes among nodes and automatically performing tasks such as data rebalancing and distributed query execution. Queries are executed in parallel to minimize lag. Data is automatically replicated to make sure that there’s no single point of failure. When a node fails, Xpand rebalances the data among the surviving nodes. The same happens when a new node is added. A component called rebalancer ensures that there are no hotspots—a challenge with manual database sharding—which occurs when one node unevenly has to handle too many transactions compared to other nodes that may remain idle at times.
Let’s study an example. Suppose we have a database instance with some_table and a number of rows:
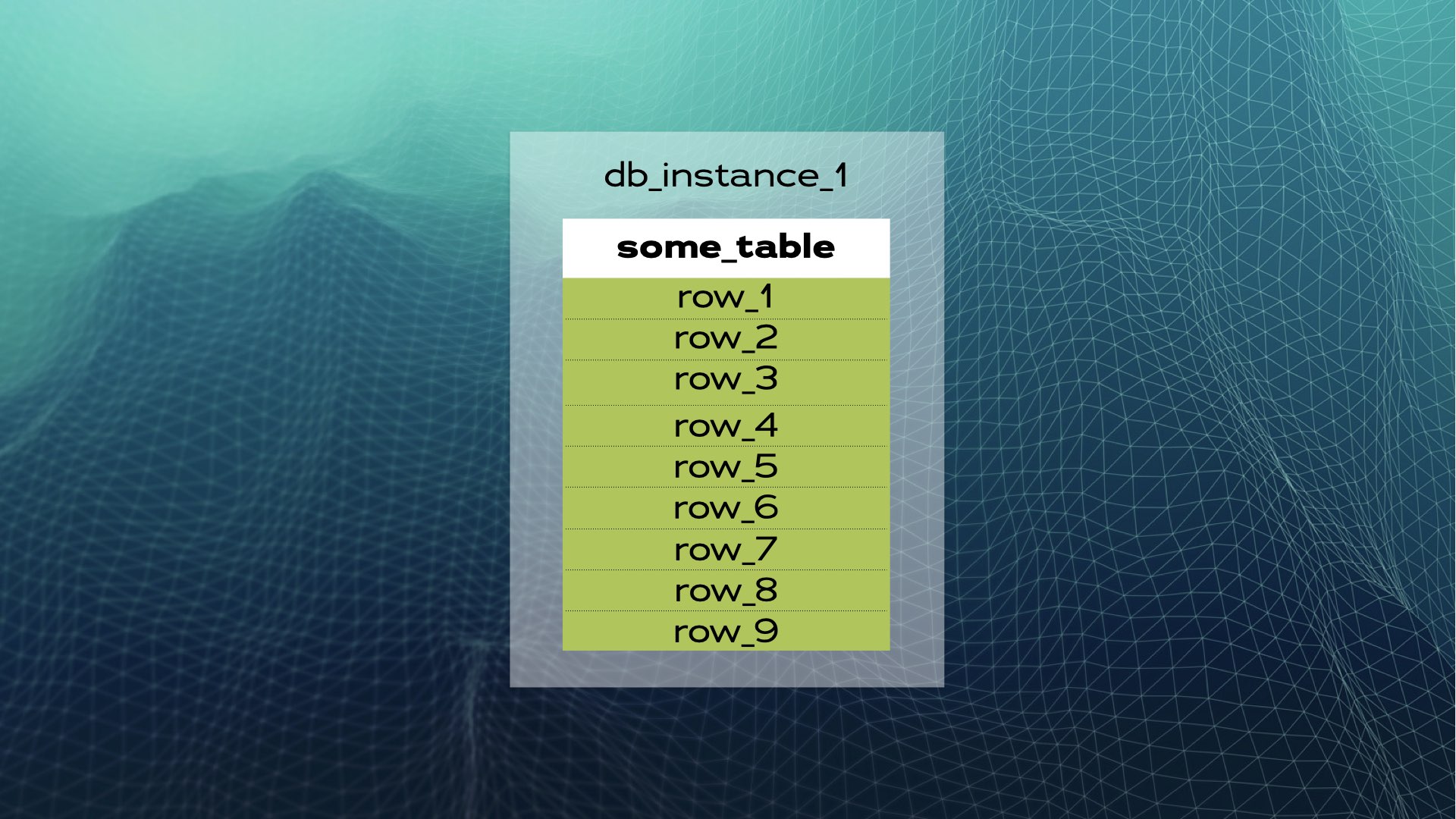
We can divide the data into three chunks (shards):

And then move each chunk of data into a separate database instance:
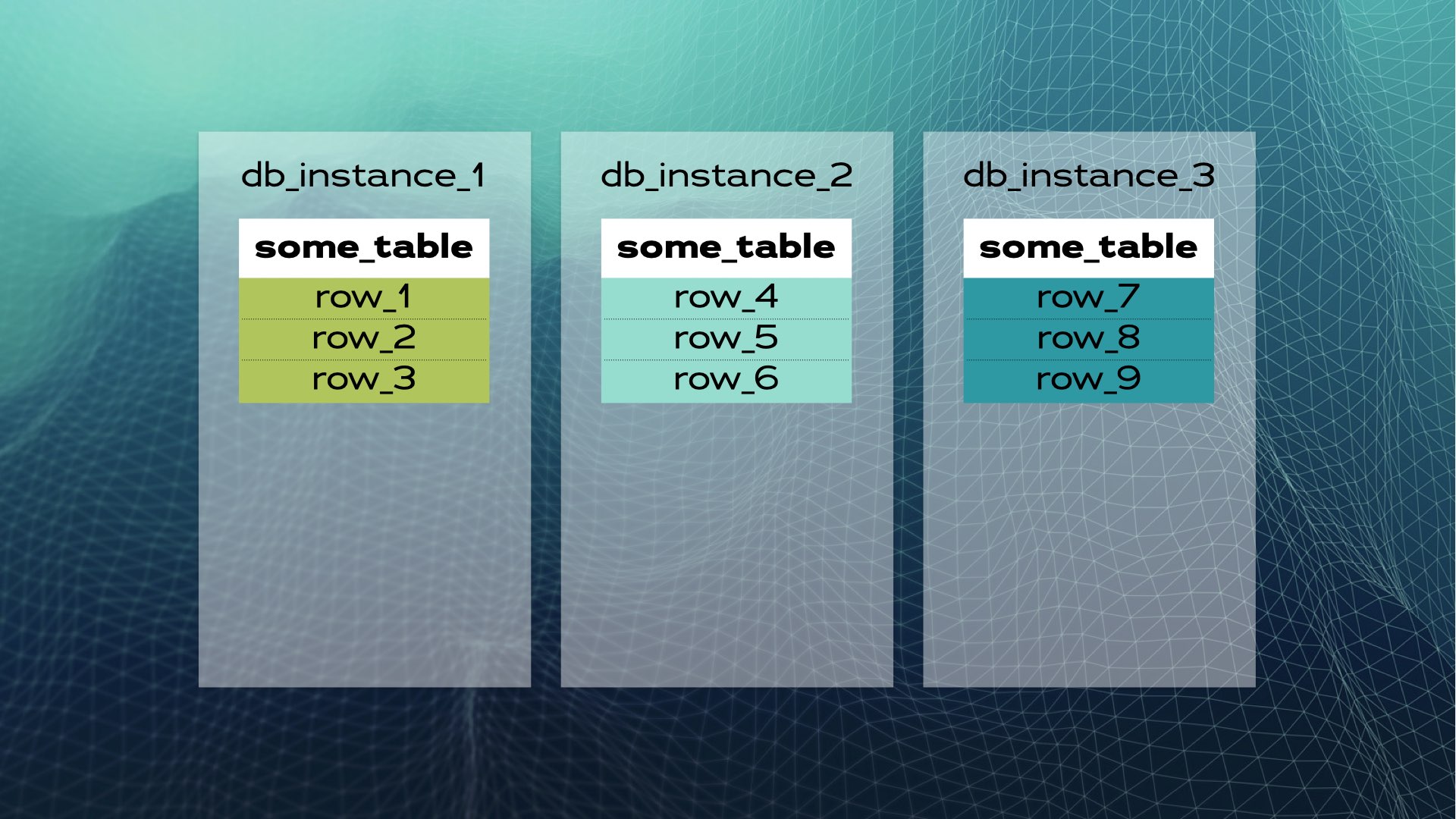
This is what manual database sharing looks like. Distributed SQL does this automatically for you. In the case of Xpand, each shard is called a slice. Rows are sliced using a hash of a subset of the table’s columns. Not only is data that is sliced, but indexes are also sliced and distributed among the nodes (database instances). Moreover, to maintain high availability, slices are replicated in other nodes (the number of replicas per node is configurable). This also happens automatically:
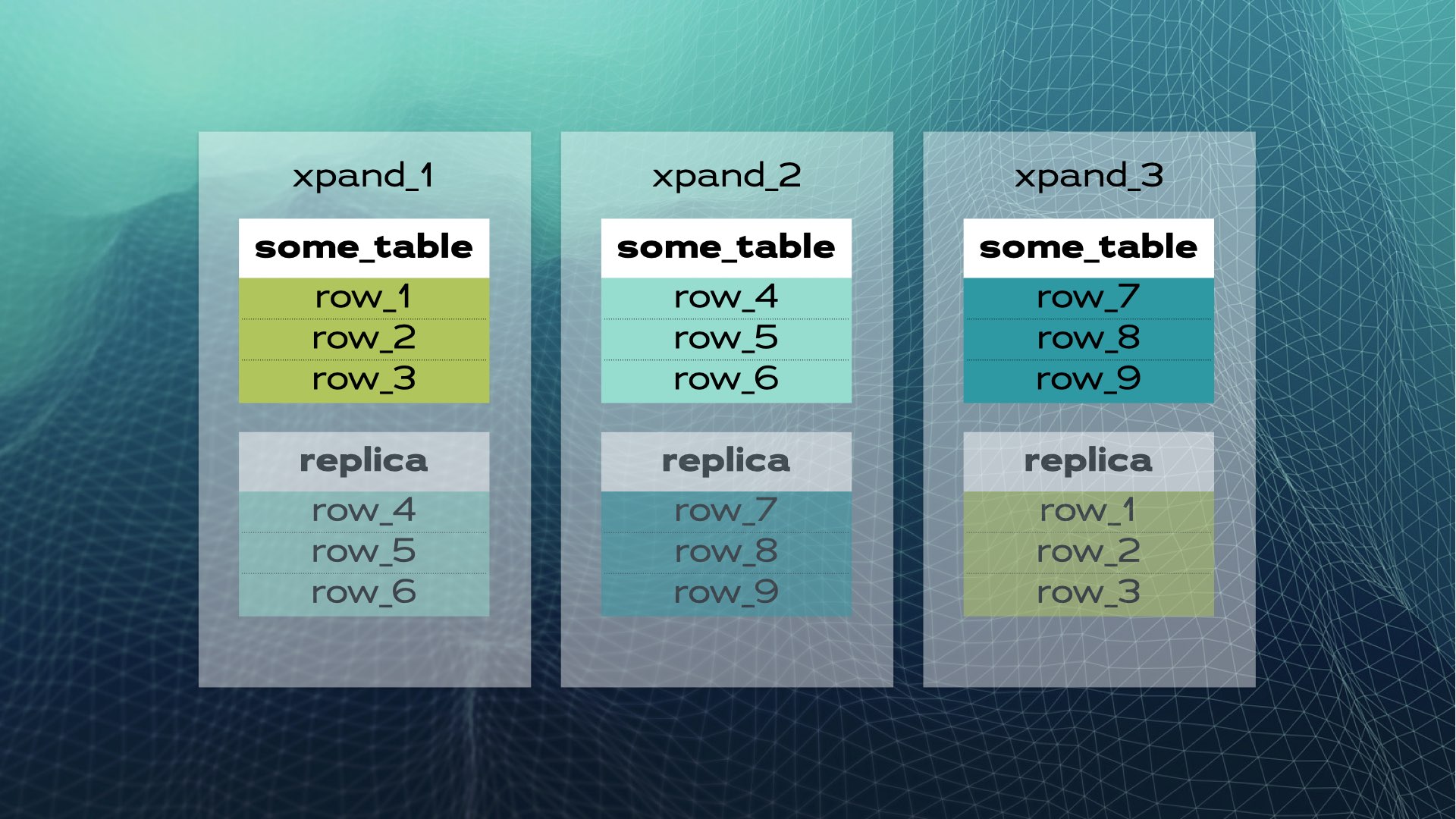
When a new node is added to the cluster or when one node fails, Xpand automatically rebalances the data without the need for manual intervention. Here’s what happens when a node is added to the previous cluster:

Some rows are moved to the new node to increase the overall system capacity. Keep in mind that, although not shown in the diagram, indexes as well as replicas are also relocated and updated accordingly. A slightly more complete view (with a slightly different relocation of data) of the previous cluster is shown in this diagram:
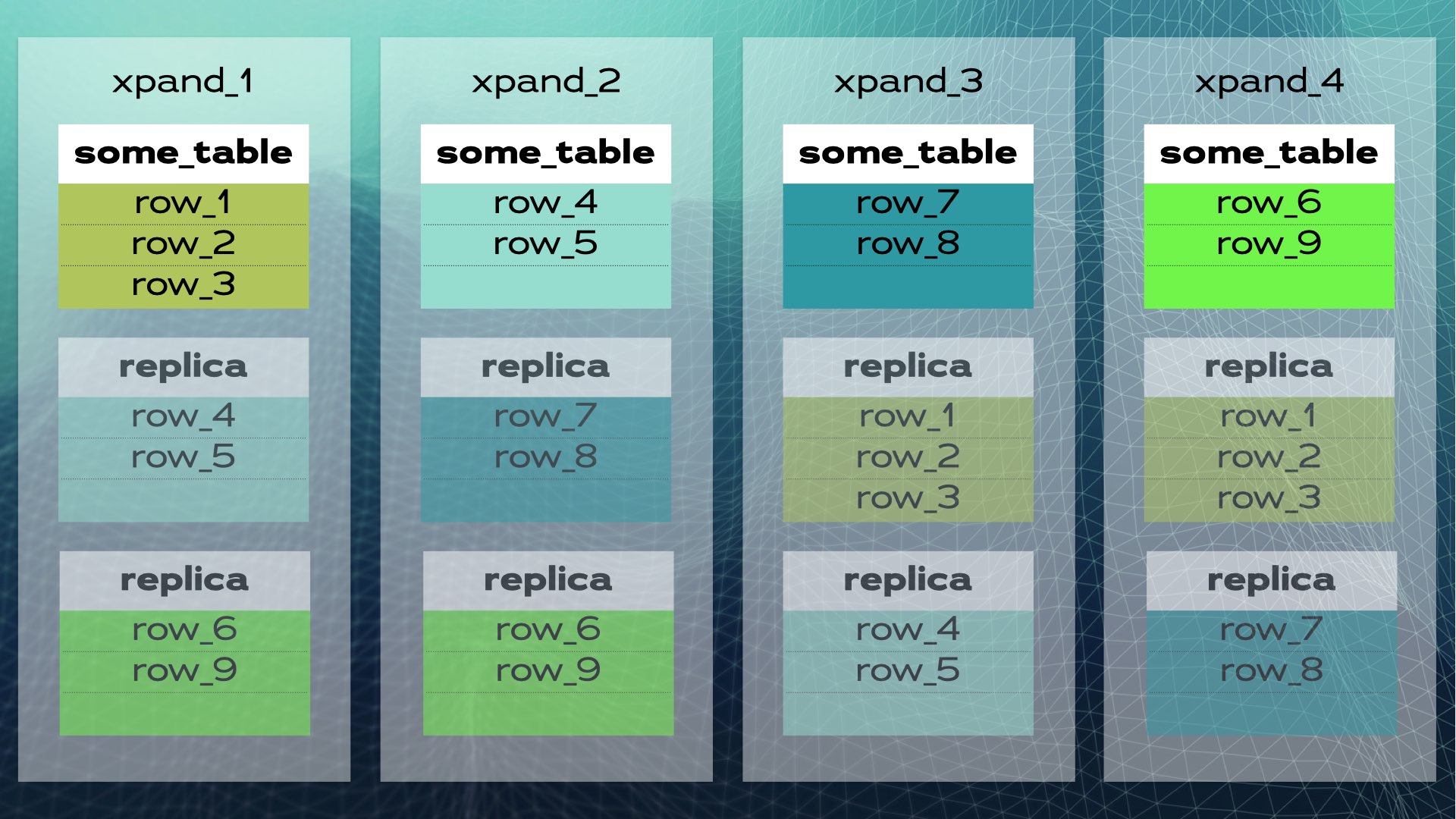
This architecture allows for nearly linear scalability. There’s no need for manual intervention at the application level. To the application, the cluster looks like a single logical database. The application simply connects to the database through a load balancer (MariaDB MaxScale):
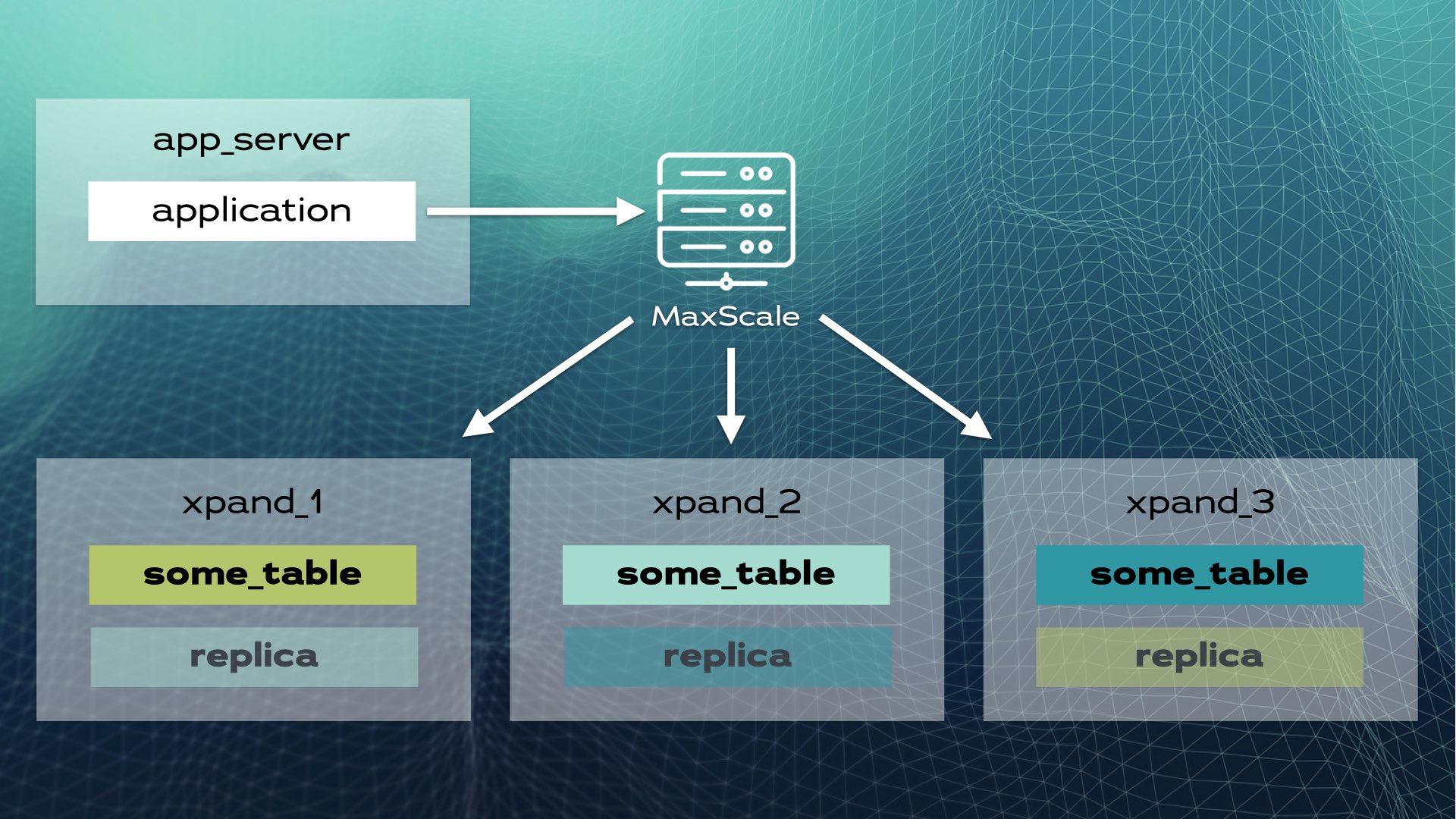
When the application sends a write operation (for example, INSERT or UPDATE), the hash is calculated and sent to correct the slice. Multiple writes are sent in parallel to multiple nodes.
When Not To Use Distributed SQL
Sharding a database improves performance but also introduces additional overhead at the communication level between nodes. This can lead to slower performance if the database is not configured correctly or if the query router is not optimized. Distributed SQL might not be the best alternative in applications with less than 10K queries per second or 5K transactions per second. Also, if your database consists of mostly many small tables, then a monolithic database might perform better.
Getting Started With Distributed SQL
Since a distributed SQL database looks to an application as if it was one logical database, getting started is straightforward. All you need is the following:
- An SQL client like DBeaver, DbGate, DataGrip, or any SQL client extension for your IDE
- A distributed SQL database
Docker makes the second part easy. For example, MariaDB publishes the mariadb/xpand-single Docker image that allows you to spin up a single-node Xpand database for evaluation, testing, and development.
To start an Xpand container, run the following command:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"See the Docker image documentation for details.
Note: At the time of writing this article, the mariadb/xpand-single Docker image is not available on ARM architectures. On these architectures (for example Apple machines with M1 processors), use UTM to create a virtual machine (VM) and install, for example, Debian. Assign a hostname and use SSH to connect to the VM to install Docker and create the MariaDB Xpand container.
Connecting to the Database
Connecting to an Xpand database is the same as connecting to a MariaDB Community or Enterprise server. If you have the mariadb CLI tool installed, simply execute the following:
mariadb -h 127.0.0.1 -u user -pYou can connect to the database using a GUI for SQL databases like DBeaver, DataGrip, or an SQL extension for your IDE (like this one for VS Code). We are going to use a free and open-source SQL client called DbGate. You can download DbGate and run it as a desktop application or since you are using Docker, you can deploy it as a web application that you can access from anywhere via a web browser (similar to the popular phpMyAdmin). Simply run the following command:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateOnce the container starts, point your browser to http://localhost:3000/. Fill in the connection details:
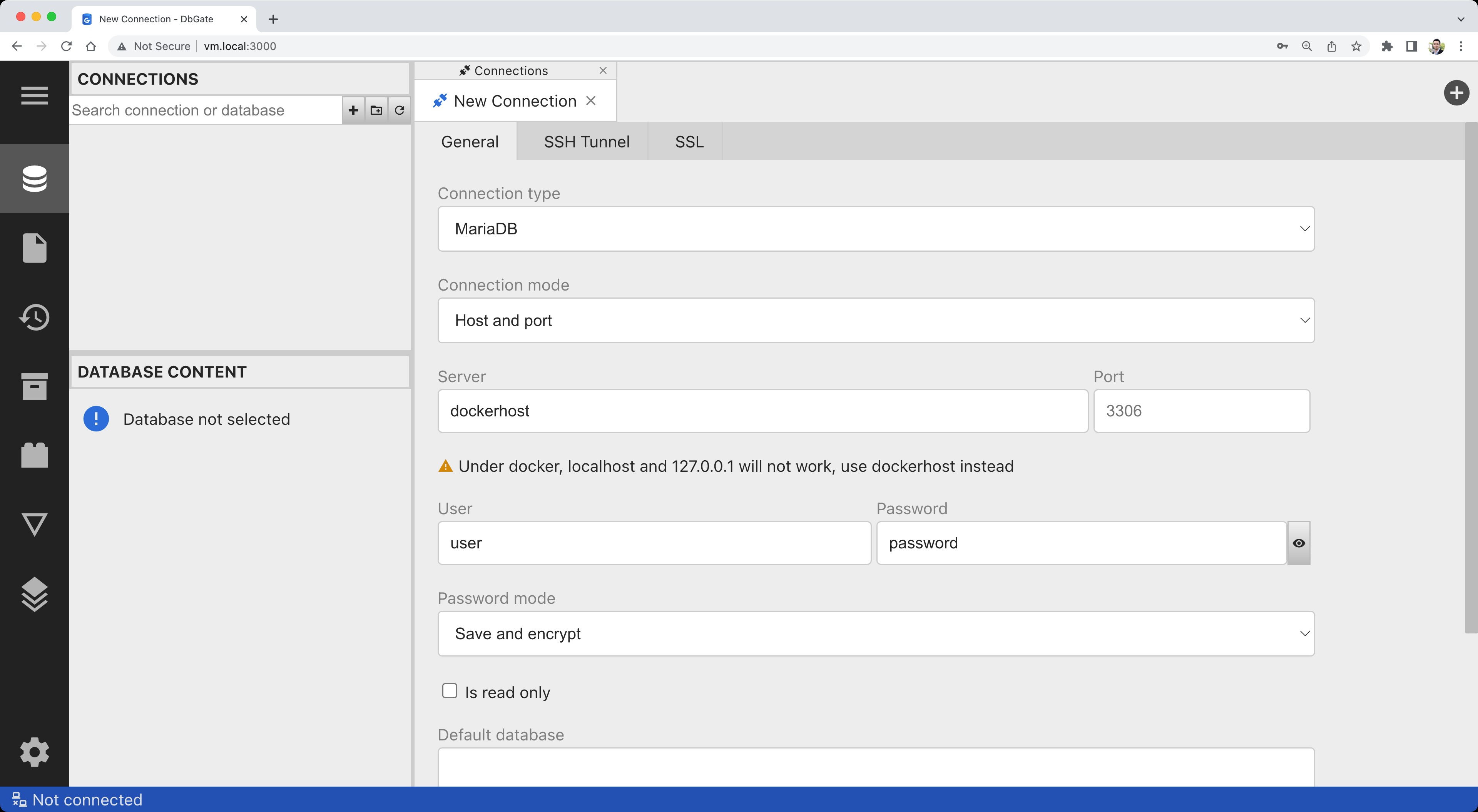
Click on Test and confirm that the connection is successful:

Click on Save and create a new database by right-clicking on the connection in the left panel and selecting Create database. Try creating tables or importing an SQL script. If you just want to try out something, the Nation or Sakila are good example databases.
Connecting From Java, JavaScript, Python, and C++
To connect to Xpand from applications you can use the MariaDB Connectors. There are many programming languages and persistence framework combinations possible. Covering this is outside of the scope of this article, but if you just want to get started and see something in action, take a look at this quick start page with code examples for Java, JavaScript, Python, and C++.
The True Power of Distributed SQL
In this article, we learned how to spin up a single-node Xpand for development and testing purposes as opposed to production workloads. However, the true power of a distributed SQL database is in its capability to scale not only reads (like in classic database sharding) but also writes by simply adding more nodes and letting the rebalancer optimally relocate the data. Although it is possible to deploy Xpand in a multi-node topology, the easiest way to use it in production is through SkySQL.
If you want to learn more about distributed SQL and MariaDB Xpand, here's a list of useful resources:
Opinions expressed by DZone contributors are their own.
Comments