Salesforce Bulk API 2.0: Streamlining Large-Scale Data Operations
Manage millions of data operations within Salesforce in a simple, reliable, and performative way using the Bulk API 2.0.
Join the DZone community and get the full member experience.
Join For FreeHave you ever faced the challenge of managing large data operations within Salesforce, such as updating, inserting, deleting, or querying records? These operations might arise from one-time data migration projects or ongoing data integration needs with external systems. In such scenarios, Salesforce Bulk API 2.0 is your solution. This robust API is designed to handle large-scale data operations efficiently, simplifying and streamlining the process.
Salesforce Bulk API 2.0 is a REST-based API, that runs the requested operation asynchronously. It is designed to simplify bulk operations within Salesforce as well as to improve the performance and reliability of bulk data processing. The following are key features of Bulk API 2.0.
1. Simplified Bulk Data Management
You only need to create one job for each data operation and Salesforce will handle breaking down the data set into multiple batches. This significantly reduces the time and effort needed for large data migrations or batch operations.
2. Reliability and Performance
Salesforce optimizes internal batch splits and execution for you. Salesforce also automatically executes retries when an error occurs and supports partial data processing. This means that even if some records fail, the successful ones are processed, and users receive clear feedback on the errors encountered.
3. Asynchronous Processing
Bulk API 2.0 processes the requests asynchronously, meaning the batches run in the background. This allows users to continue with other tasks without waiting for the operation to complete.
4. Supports JSON
The API supports JSON format for job creation and status checks.
How To Use Bulk API 2.0
To use Bulk API 2.0, you need to follow the following steps. Let us take an example of an update operation on the Opportunity table.
1. Create a Job
The first step is to create the job with operation = update, by sending a POST request with the following details.
endpoint: /services/data/vXX.X/jobs/ingest
payload: lineEnding request parameter is the line-ending format used in the CSV. The API supports two line-ending formats: linefeed (LF), and carriage-return plus linefeed (CRLF).
{
"object" : "Opportunity",
"contentType" : "CSV",
"operation" : "update",
"lineEnding" : "LF"
}response: You will get the response with the job ID. You will be using this Job ID in further steps. The status of the job is 'Open'.
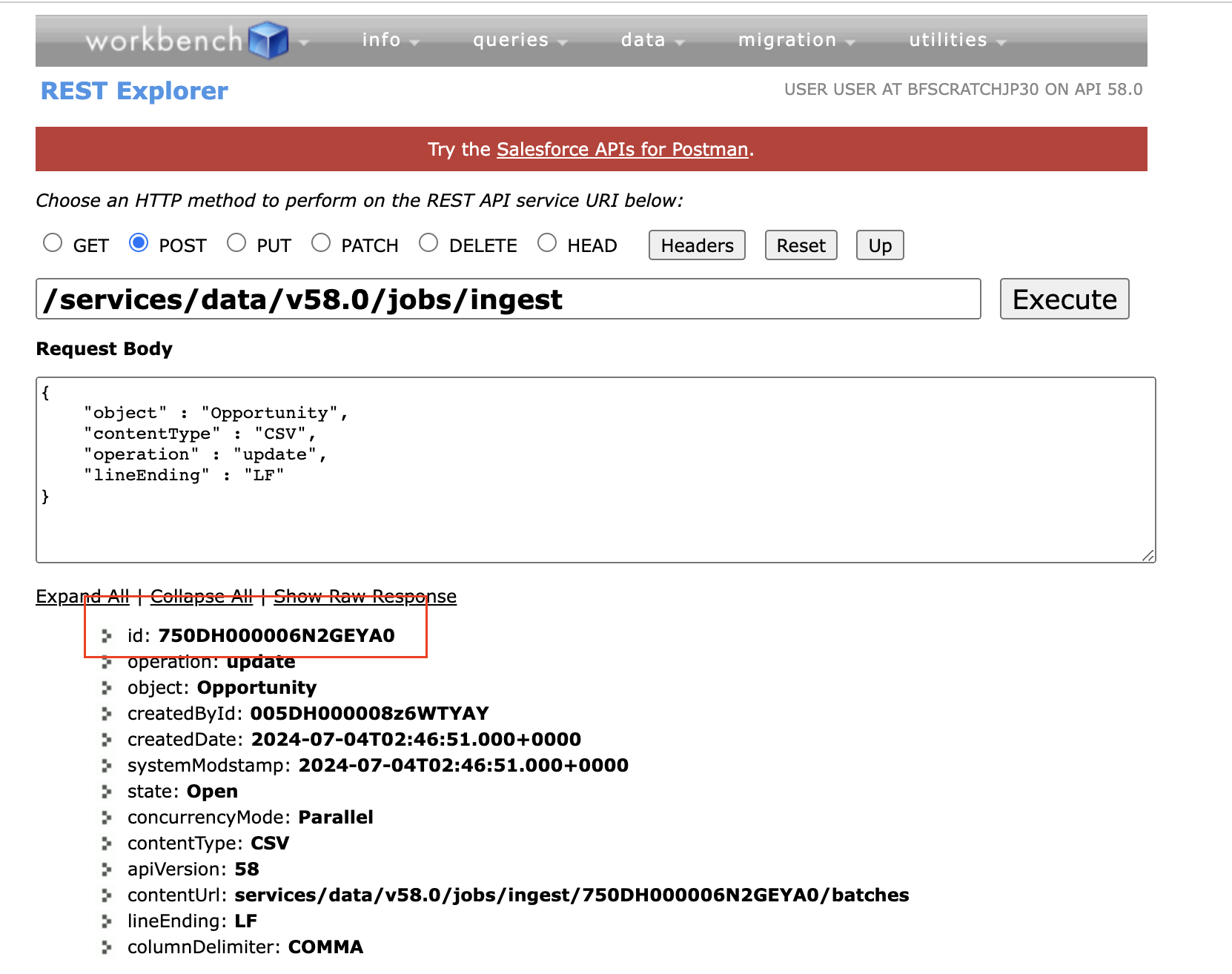
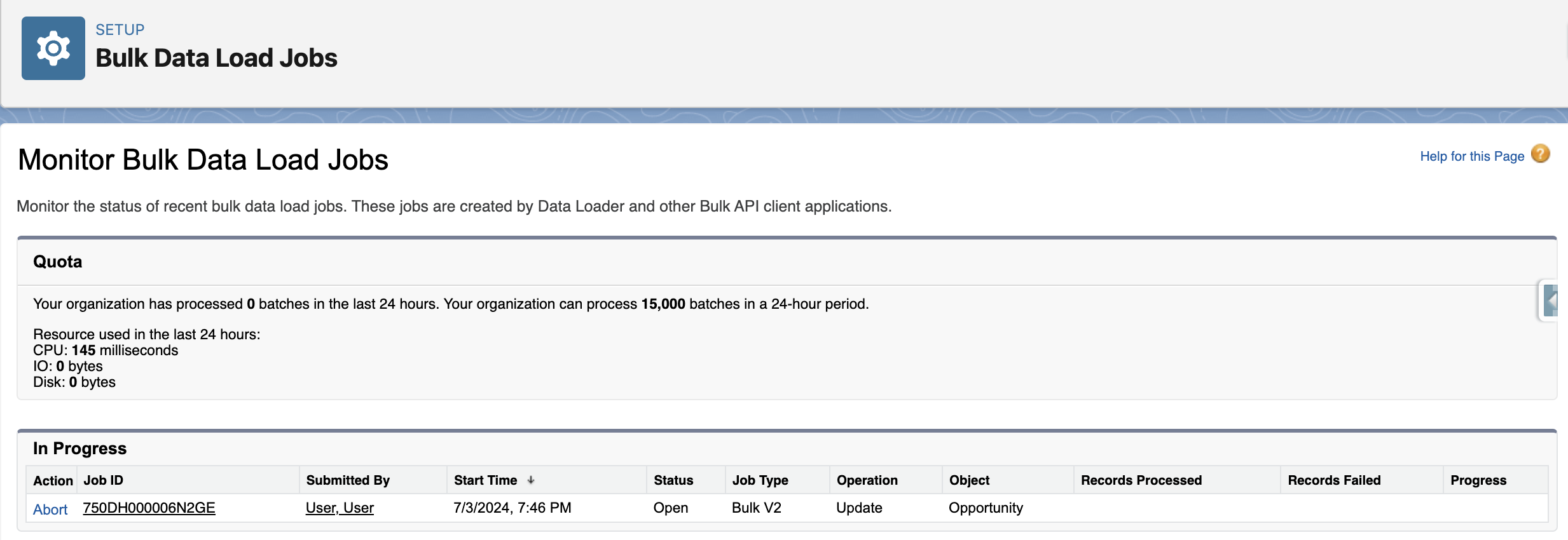
You can also go to Setup>Monitor Bulk Data Load Jobs to monitor the progress of the jobs.
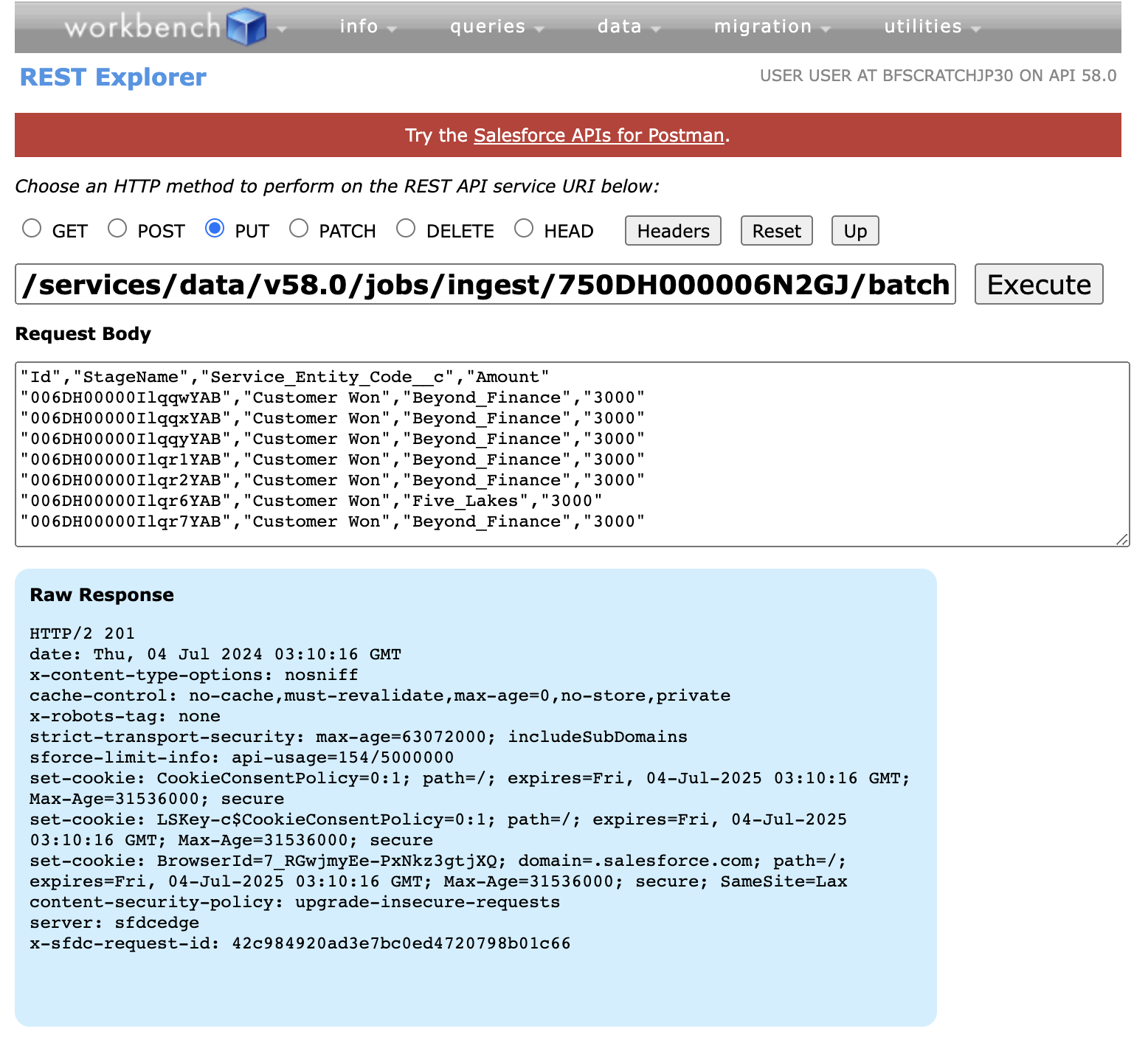
2. Upload Data
Once the job is created, the next step is to upload your data that needs an update. You need to send a PUT request to the following endpoint, with the data for the job in CSV format. You can upload up to 150 MB of data per job.
endpoint: /services/data/vXX.X/jobs/ingest/{jobId}/batches
3. Set Job State to Uploadcomplete
Once the upload is complete, notify Salesforce servers that it is time to process the data. To do this, send a PATCH request to the following endpoint.
endpoint: /services/data/vXX.X/jobs/ingest/{jobId}/
payload:
{ "state" : "UploadComplete" }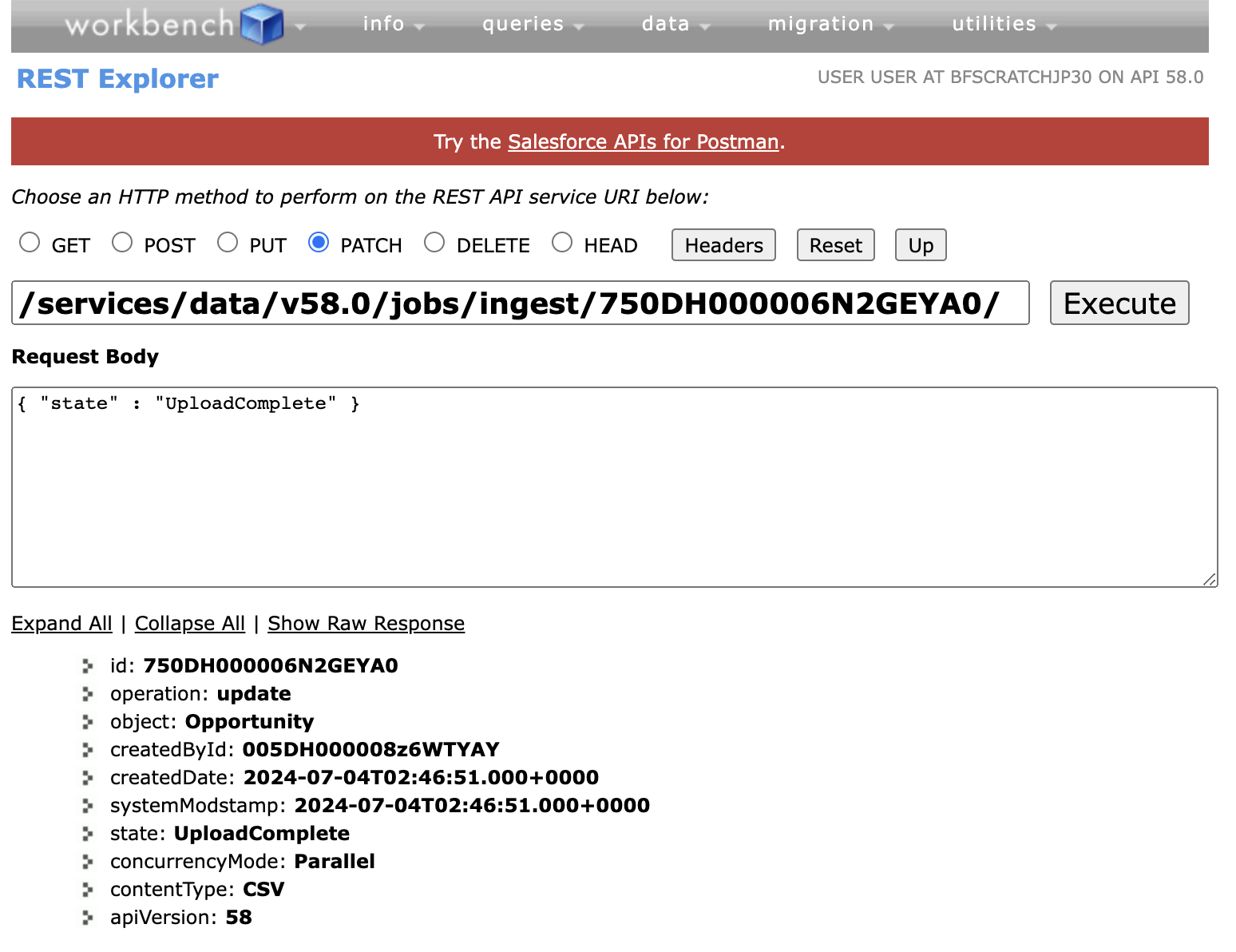
response: Job status is changed to UploadComplete.
4. Check the Status
If you want to check the status of the job and, the number of records processed, errored out, and unprocessed, you can send a GET request to the following endpoint.
endpoint: /services/data/vXX.X/jobs/ingest/{jobId}
response:
{ "id" : "7505fEXAMPLE4C2AAM",
"operation" : "update",
"object" : "Opportunity",
"createdById" : "0055fEXAMPLEtG4AAM",
"createdDate" : "2022-01-02T21:33:43.000+0000",
"systemModstamp" : "2022-01-02T21:38:31.000+0000",
"state" : "JobComplete",
"concurrencyMode" : "Parallel",
"contentType" : "CSV",
"apiVersion" : 61.0,
"jobType" : "V2Ingest",
"lineEnding" : "LF",
"columnDelimiter" : "COMMA",
"numberRecordsProcessed" : 7,
"numberRecordsFailed" : 0,
"retries" : 0,
"totalProcessingTime" : 886,
"apiActiveProcessingTime" : 813,
"apexProcessingTime" : 619 }You can also send a GET request to /services/data/vXX.X/jobs/ingest/{jobId}/failedResults endpoint to get the details of the failed records OR
to /services/data/v61.0/jobs/ingest/{jobId}/successfulResults/
endpoint to get details about which records were successfully processed.
Use Cases of Bulk API 2.0
Data Migration
Bulk API 2.0 is ideal for migrating large data sets from legacy systems to Salesforce. Its ability to process millions of data efficiently makes it the first option for large-scale operations.
Data Integration
When you have data integration requirements, integrating external systems to Salesforce, Bulk API 2.0 provides a robust solution. Its support for asynchronous processing makes large-scale data integration efficient, as it ensures that data can be integrated without disrupting ongoing operations.
Batch Processing
Routine batch processing jobs, such as nightly data cleanups, can be streamlined using Bulk API 2.0. Its error-handling capabilities make it ideal for routine data operations.
Conclusion
Salesforce Bulk API 2.0 is a critical tool for organizations to manage large-scale data operations efficiently. Its capability to process millions of data effectively, with robust error handling and support for asynchronous processing, makes this a go-to tool for any data migration, data integration, or batch processing projects.
Opinions expressed by DZone contributors are their own.
Comments