Developing With Dragonfly: Cache-Aside
Dive into efficient cache-aside development strategies. Learn to optimize performance for robust applications in this comprehensive guide.
Join the DZone community and get the full member experience.
Join For FreeIn the realm of web application development (or any other applications involving backend servers), the quest for optimal performance often intersects with the challenge of managing data retrieval efficiently. Imagine a scenario where a web application is tasked with fetching a large amount of data from its main database: user profiles, blog posts, product details, transaction history, and more. These queries to the primary database will inevitably introduce significant latency, resulting in a poor user experience and potentially pushing the database to its limits.
A common solution is to add a cache that can relieve the primary database of much of the load. This cache mechanism operates as a strategic intermediary, positioned between the intricate network of services constituting your application and the primary database itself. Its fundamental purpose is to store a duplicate copy of the most frequently requested data or data anticipated to be accessed imminently.
Where to Cache?
While caching within individual services might appear to be a convenient solution, it introduces challenges. This approach leads to stateful services, potentially resulting in data inconsistencies across multiple instances of the same service application.
Redis has traditionally occupied the role of a centralized cache service, offering seamless data storage and retrieval. However, since Redis is often limited by its single-threaded data manipulation and complex cluster management, the emergence of Dragonfly takes the spotlight. Dragonfly can serve as a drop-in replacement for Redis, retaining compatibility while leveraging novel algorithms and data structures on top of a multi-threaded, shared-nothing architecture to elevate your application's cache management to unprecedented levels of speed and scalability.
In this blog post, we will see code examples implementing the caching layer in your service as well as discuss different cache eviction strategies.
A Basic Cache-Aside Implementation
The service code example will be implemented in Go using the Fiber web framework instead of the standard library. Fiber is inspired by Express, and it is an easier option to demonstrate the caching layer in this blog post. However, the general ideas and techniques can be applied to other programming languages and frameworks as well. If you want to follow along, the sample application code can be found in this GitHub repo.
1. The Cache-Aside Pattern
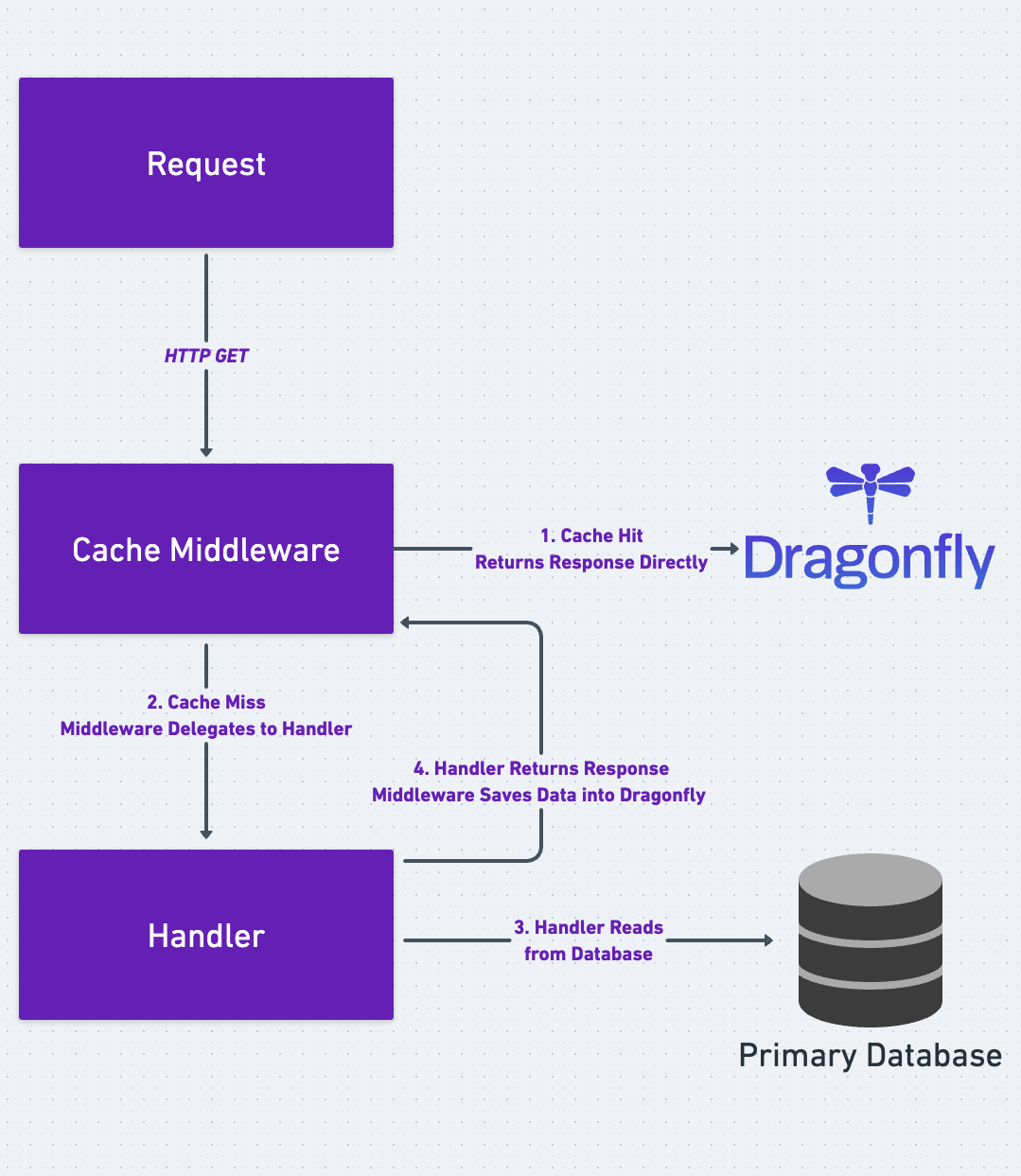
The code example presented in this blog post brings to life the Cache-Aside pattern depicted below. Cache-aside (or Lazy-Loading) is the most common caching pattern available. The fundamental data retrieval logic can be summarized as follows:
- When a service within your application needs specific data, it queries the cache first.
- Ideally, the required data is readily available in the cache; this is often referred to as a cache hit. With a cache hit, the service can respond to the query directly. This fast-track journey sidesteps the need to engage the database, thus substantially reducing the response time.
- If the required data is absent from the cache, aptly termed a cache miss, the service redirects the query to the primary database instead.
- After data retrieval from the database, the cache is also lazily populated, and the service can eventually respond to the query.
As we delve into the intricacies of the code and concepts, it's valuable to maintain the visualization of the Cache-Aside pattern. In times of uncertainty or confusion, this illustration serves as a steadfast point of reference.
2. Connect to Dragonfly
Firstly, let's create a client that talks to Dragonfly:
import (
"context"
"log"
"time"
"github.com/gofiber/fiber/v2"
"github.com/redis/go-redis/v9"
)
// Use local Dragonfly instance address & credentials.
func createDragonflyClient() *redis.Client {
client := redis.NewClient(&redis.Options{Addr: "localhost:6379"})
err := client.Ping(context.Background()).Err()
if err != nil {
log.Fatal("failed to connect with dragonfly", err)
}
return clientIn the provided code snippet, what's noteworthy is the usage of the go-redis library. It's important to highlight that due to Dragonfly's impressive compatibility with the RESP wire protocol, the very same code can seamlessly connect to Dragonfly as long as the correct network address and credentials are provided. This inherent adaptability minimizes friction when considering the switch to Dragonfly, showcasing its role as an effortless upgrade path for optimizing cache management in your web application.
3. Create a Cache Middleware
Next, let's create a cache middleware:
import (
"context"
"log"
"time"
"github.com/gofiber/fiber/v2"
"github.com/gofiber/fiber/v2/middleware/cache"
"github.com/redis/go-redis/v9"
)
func createServiceApp() *fiber.App {
client := createDragonflyClient()
// Create cache middleware connecting to the local Dragonfly instance.
cacheMiddleware := cache.New(cache.Config{
Storage: &CacheStorage{client: client},
Expiration: time.Second * 30,
Methods: []string{fiber.MethodGet},
MaxBytes: 0, // 0 means no limit
StoreResponseHeaders: false,
})
// ...
}In the Fiber framework, a middleware function behaves as a link in the chain of actions during an HTTP request cycle. It gains access to the context, encapsulating the request's scope, to enact a specific task. In the context of this tutorial, the middleware is constructed using a ready-to-use cache middleware template. It's crucial to observe the configuration parameters applied to the cache middleware:
Storagedesignates the cache's data repository. Here, a wrapper layerCacheStorageover the memory-storeclient, which connects and issues commands to Dragonfly, is employed.Expirationdictates the time-to-live for each cached entry.Methodsgoverns which HTTP methods undergo caching. In the code snippet above, emphasis rests on caching only theGETendpoints.MaxBytesdefines the upper limit for stored response body bytes. Setting it to0means no limit, relinquishing control to Dragonfly'smaxmemoryandcache_modeflags for server-side cache eviction management. More on this follows shortly.
4. The Storage Interface
In the code snippet above, we passed in a struct pointer wrapping the Dragonfly client.
Storage: &CacheStorage{client: client}The rationale behind this choice stems from the fact that the creators of Fiber anticipated diverse scenarios during the middleware design. Consequently, directly passing the Dragonfly client, which is equipped with uniquely typed methods for various commands, wasn't viable. Instead, the ingenious solution involves the introduction of the CacheStorage wrapper. This wrapper adheres to a common interface defined in Fiber, namely Storage, effectively representing a fixed collection of method signatures that denote specific behaviors.
The subsequent code snippet delves into the mechanics of CacheStorage:
// CacheStorage implements the fiber.Storage interface.
type CacheStorage struct {
client *redis.Client
}
func (m *CacheStorage) Get(key string) ([]byte, error) {
// Use the actual GET command of Dragonfly.
return m.client.Get(context.Background(), key).Bytes()
}
func (m *CacheStorage) Set(key string, val []byte, exp time.Duration) error {
// Use the actual SET command of Dragonfly.
return m.client.Set(context.Background(), key, val, exp).Err()
}
func (m *CacheStorage) Delete(key string) error {
// Use the actual DEL command of Dragonfly.
return m.client.Del(context.Background(), key).Err()
}
func (m *CacheStorage) Close() error {
return m.client.Close()
}
func (m *CacheStorage) Reset() error {
return nil
}
// In https://github.com/gofiber/fiber/blob/master/app.go
// Below is the 'Storage' interface defined by the Fiber framework.
// The 'CacheStorage' type needs to conform all the methods defined in this interface.
type Storage interface {
Get(key string) ([]byte, error)
Set(key string, val []byte, exp time.Duration) error
Delete(key string) error
Reset() error
Close() error
}
Within this construct, CacheStorage meticulously aligns itself with the requirements of the Fiber framework. This alignment is facilitated by method implementations such as Get, Set, and Delete, designed to interact with byte data at specified keys. While the implementation above leverages the GET, SET, and DEL commands intrinsic to Dragonfly, the underlying principle here is the realization of these methods as prescribed by the Fiber interface.
5. Register Middleware and Handlers
With the cache middleware now in place, utilizing Dragonfly as the underlying in-memory store, the next step is to register the cache middleware and handlers for reading user and blog information. It's important to underline that the implementation's elegance shines through the app.Use(cacheMiddleware) instruction, an act that propagates the effects of the cache middleware globally for all routes. However, we configured the cache middleware to only cache responses on routes that use the HTTP GET method (i.e., Methods: []string{fiber.MethodGet}). Routes with any other HTTP methods (such as HEAD, POST, PUT, etc.) remain exempt from caching. Note that, for simplicity, there are only GET routes in the service application.
func createServiceApp() *fiber.App {
client := createDragonflyClient()
// Create cache middleware connecting to the local Dragonfly instance.
cacheMiddleware := cache.New(cache.Config{
Storage: &CacheStorage{client: client},
Expiration: time.Second * 30,
Methods: []string{fiber.MethodGet},
MaxBytes: 0, // 0 means no limit
StoreResponseHeaders: false,
})
// Create Fiber application.
app := fiber.New()
// Register the cache middleware globally.
// However, the cache middleware itself will only cache GET requests.
app.Use(cacheMiddleware)
// Register handlers.
app.Get("/users/:id", getUserHandler)
app.Get("/blogs/:id", getBlogHandler)
return app
}6. Start Dragonfly and Service Application
The concluding segment of the Go code entails the creation of a service application instance, a construct meticulously established in prior sections. Subsequently, this instance is harnessed within a main function, as depicted below:
func main() {
app := createServiceApp()
if err := app.Listen(":8080"); err != nil {
log.Fatal("failed to start service application", err)
}
}However, before running the main function, let's not forget another important step: starting a Dragonfly instance locally. There are several options available to get Dragonfly up and running quickly. For this tutorial, using the docker-compose.yml file below along with the docker compose up command, we will have a Dragonfly instance running locally.
version: '3'
services:
dragonfly:
container_name: "dragonfly"
image: 'docker.dragonflydb.io/dragonflydb/dragonfly'
ulimits:
memlock: -1
ports:
- "6379:6379"
command:
- "--maxmemory=2GB"
- "--cache_mode=true"As previously noted, the specification of maxmemory and cache_mode flag arguments during the Dragonfly instance initialization assumes paramount significance. Finally, we can run the main function, initializing a service application using Dragonfly as a caching layer.
7. Interact With the Service
With the service application now running, the next step is to initiate an HTTP GET request to the service, thus engendering interaction with the caching mechanism:
curl --request GET \
--url http://localhost:8080/blogs/1000
There should be a successful response from the HTTP call. In the meantime, the response body should be saved in Dragonfly automatically by our cache middleware:
dragonfly$> GET /blogs/1000_GET_body
"{\"id\":\"1000\",\"content\":\"This is a micro-blog limited to 140 characters.\"}"
8. Recap: Cache Read and Write Paths
Now, let's trace back to the Cache-Aside pattern illustration, with a focus on the read-path:
- An HTTP GET request is initiated.
- The adept cache middleware intervenes, positioning itself before the handler's execution, and tries to read from Dragonfly.
- A cache miss occurs, as this is the first time of data retrieval.
- The cache middleware delegates to the handler, and the handler, in turn, reads from the primary database.
- Once the cache middleware gets the response from the handler, it saves the response in Dragonfly before returning.
- Future requests for the same data can be readily answered by the cache, steering clear of the primary database.
In terms of the write path, the service application in the example refrains from incorporating HTTP POST/PUT routes for simplicity. Consequently, cache invalidation or replacement strategies remain uncharted domains for this blog post. The service application relies on the expiration configuration imbued within the cache middleware. This arrangement orchestrates the eviction of certain cached items as they gradually outlive their relevance.
However, despite the presence of automated expirations, it's important to acknowledge that the Dragonfly instance can still find itself nudging against its defined maxmemory, which is 2GB in the example configuration above. To visualize this potential scenario, consider our service application diligently answering user and blog requests, spanning across a diverse spectrum of tens of millions of IDs. Under these circumstances, the likelihood of nearing maxmemory is obvious.
Fortunately, the cache_mode=true argument was also specified. By doing so, Dragonfly will evict items least likely to be requested again in the future when it is nearing the maxmemory limit. We will discuss further about the power of the cache_mode=true argument below.
Dragonfly Advantages as a Cache Store
In this blog post, we created a service application with a caching layer backed by Dragonfly. As we have seen, the Fiber authors designed a generic storage interface for the middleware. This means many in-memory data stores can be adapted and used as backing storage. This revelation prompts a natural question: with a variety of options available, why is Dragonfly such a good choice for modern caching?
Memory Efficiency and Ultra-High Throughput
While classic hash-tables are built upon a dynamic array of linked-lists, Dragonfly's Dashtable is a dynamic array of flat hash-tables of constant size. This design allows for much better memory efficiency, resulting in steady-state memory usage that's up to 30% less, as detailed in the Redis vs. Dragonfly Scalability and Performance blog post.
Meanwhile, thanks to Dragonfly's advanced architecture, a lone AWS EC2 c6gn.16xlarge instance can surge to a staggering 4 million ops/sec throughput.
High Hit Ratio With the LFRU Eviction Policy
When cache_mode=true is passed during initialization, Dragonfly utilizes a universal Least-Frequently-Recently-Used (LFRU) cache policy to evict items when approaching the maxmemory limit. Compared to Redis' LRU cache policy, LFRU is resistant to fluctuations in traffic, does not require random sampling, has zero memory overhead per item, and has a very small run-time overhead. Comprehensively described in the Dragonfly Cache Design blog post, the algorithm behind LFRU, namely 2Q, takes both frequency and time sensitivity into consideration:
2Q improves LRU by acknowledging that just because a new item was added to the cache - does not mean it's useful. 2Q requires an item to have been accessed at least once before to be considered as a high quality item.
By employing the 2Q algorithm, Dragonfly's LFRU eviction policy leads to a higher cache hit ratio. With a higher hit ratio, fewer requests would propagate through the caching layer and reach the primary database, which in turn leads to more steady latency and better quality of service.
Taking full advantage of Dragonfly's strengths: memory efficiency, high throughput, and high hit ratio, it becomes a compelling choice for a cache store within modern cloud-driven environments.
Conclusion
In this blog post, we demonstrated how to craft a caching layer using the Fiber web framework middleware. Our exploration delved primarily into the Cache-Aside pattern with a fixed cache expiration period. Also, we discussed how Dragonfly's universal LFRU eviction policy provides a higher cache hit ratio and can be highly beneficial by reducing the load on the primary database.
Published at DZone with permission of Joe Zhou. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments