Design Insights From Unit Testing
When tests are hard to write, it's because they're telling you how the production design can be improved. Unit Testing offers priceless feedback if only you'd listen.
Join the DZone community and get the full member experience.
Join For FreeProbably the biggest breakthrough while Unit Testing is to realize that writing tests offer priceless feedback about the design of your production code. This feedback goes from suggesting immediate obvious improvements, up to hints about some of the most advanced design principles in software engineering. This article briefly enumerates these hints, pointing to questions to ask about your design.
Disclaimer: Don't follow blindly these hints, but make sure you understand all of them so that you can decide in your real problem what would improve the design, and what wouldn't.
Warning: this article might bring more questions than answers. Which is good.
Since Java is my native language, the pseudocode in the article smells like Java, and the mocking framework referenced is Mockito. However, the design ideas are completely language agnostic.
Some Terms
- Stubbing = Teaching what a method should return, eg
when(..f()).thenReturn(..) - Verifying = Checking a method got called by tested code, eg
verify(..).f() - Cyclomatic Complexity = Number of independent execution paths; a good measure of the number of tests required to fully cover that code. You can measure it, for example with this IntelliJ plugin.
- Value Object = Tiny immutable class
Specific Signatures
A method receiving only the parameters strictly required by its behavior is both easier to test (fewer objects to create in test) and easier to understand at the call site.
f(customer); f(customer.getCoupons()); // easier to test and more explicitConvenient APIs
When you call a production method 10 times from your tests, you get to think more carefully about its signature, like the function name and parameters. This way, you often get ideas on how to make that API more expressive and more flexible, thus improving the quality of the production code.
Pitfall ⚠: when making the production code more convenient for testing, the API change should also make sense when calling that function from production. Such a bad example would be to add an extra parameter to the method under test just to enable easier testing of it, even though no caller really needs that parameter in the production code.
Immutable Objects
Consider a function changing some attribute of the argument it receives.
void f(arg) { // complexity arg.setTotal(..); }Testing this function is straightforward, but what happens if you want to test separately the function calling f():
void fCaller() { arg = new Arg(); // complexity f(arg); // more complexity using arg.getTotal() }If you want to stub the behavior of f() when testing the code of fCaller(), that would require stubbing with callback:
when(..).thenAnswer(x -> ((Arg)x.getArguments()[0]).setTotal(..));This technique leads to some of the ugliest test codes you could ever see. So the design hint is clear:
Favor using immutable objects in complex logic.
In our case, it would mean that f() would return total instead of changing an argument.
Command Query Separation (CQS) Principle
When writing a test, you conclude that you have to both stub and verify the same function.
@Test void aTest() { when(mock.fun(..)).thenReturn(..); // stubbing // stuff verify(mock).fun(..); }This could happen because fun() is a peripheral function that calls an external system (eg sending a REST call outside). In such a case, you might want to make sure that the network call is performed exactly once because it's expensive, either in delay or an associated fee.
But if fun() is part of your core internal logic, then having to both stub and verify it means that fun() is both a query (returns results) and a command (produces side effects that you want to check). This means it violates the Command Query Separation (CQS) Principle that states that a function should either return data or change data. In other words, "functions returning data should be pure" (pure functions are defined in the next section).
You shouldn't need to verify stubbed methods.
https://martinfowler.com/articles/mocksArentStubs.html
If a function doesn't perform any side effects, calling it or not should not matter. Instead, the test should probably check other outcomes of the tested code that is based on the data returned by the stub. Here's a simple example to demonstrate this point:
@Test void aTest() { when(mock.fun()).thenReturn("John Doe"); String actual = prod.testedCode(); assertThat(actual).isEqualTo("John DOE"); }Applying CQS Principle in every method is almost impossible in a real system. Nevertheless, when CQS is followed, the code is more obvious, easier to read, and reason about.
Functional Core / Imperative Shell Segregation
Imagine testing a complex function with many ifs and loops. You need many tests to fully cover code with high cyclomatic complexity. To write more tests you need to shrink them, so limiting the use of mocks in these tests becomes a key concern. The design idea is to extract complex logic into functions that use fewer dependencies (ideally: zero), by leaving 'at the surface' the interaction with dependencies.
Let's look at a typical example of a use case:
public void someUsecase(..) { a = someRepo.find(..); // read DB b = someClient.fetch(..); // REST API call // complex logic requiring 10 tests someRepo.save(..); // write DB }Writing many tests on this method will be painful because of the stubbing, verifying, and argument captors involved. We could simplify both our tests and our production code if we extract the complex part into a separate method:
public void someUsecase(..) { // part of the Imperative Shell a = someRepo.find(..); b = someClient.fetch(..); X x = complexPure(a, b); someRepo.save(x); } X complexPure(a, b) { // member of the Functional Core // complex logic requiring 10 tests }Testing the complexPure() function becomes much easier as I only have to pass parameters and assert results. The production design also improved, as I separated the high-level orchestration policy from low-level details (in our case, deep complexity). Calling complexPure() also makes it very clear what data goes in and out.
In an ideal world, complexPure() would be implemented as a Pure Function:
Pure Function:
1) doesn't change any state when invoked, and
2) returns the same results when given the same parameters
Think for a moment. (1) stops you from calling a POST, sending an INSERT, and even changing a field, while (2) also disables you from doing a GET or SELECT to an external system: calling them again might bring different data from the other system.
In practice, it's quite hard to implement your complex logic as pure functions: one dependency sometimes persists in there, but the design goal is to strip the complexity of heavy dependencies. Such a loosely coupled design will be easier to test and reason about.
So here's the design principle to consider:
Separate deep (cyclomatic) complexity from heavy dependencies.
But what if complexPure() function needs to return multiple results back to the caller in Imperative Shell? Imagine a list of used coupons and the final price, that both need to be persisted after the pure function returns. In that case, ask: (a) can I break my function into two smaller parts to compute the two results independently (SRP principle)? If not, (b) consider returning from complexPure() a new type, a Value Object wrapping the two results, like PriceResult {double totalPrice; List<Coupon> usedCoupons;}
Introducing new Value Objects to carry data between different stages of the processing is sometimes called "Split Phase" refactoring, and makes code easier to read and to test, enabling you to test those stages in isolation.
Now it's time to ask: did you notice that complexPure() is not private? In Java, it could be package protected (please, not public!), to allow testing it directly. Am I breaking encapsulation for testing? OMG, Yes! By the way, if you can't sleep after reading this, consider using @VisibleForTesting - it will stop any other production class from calling the method; it can be enforced both via static tools like Sonar, but also inside your IDE (in IntelliJ, search for '@VisibleForTesting' in Settings>Editor>Inspections).
But I agree: this design is suspect, and it's only acceptable as long as the public method in the 'Imperative Shell' remains simple. The moment both the high-level function and the low-level one grow complex, another design principle will kick in:
Separation by Layers of Abstraction
Imagine you have a public method p() calling a private one v(). If p() and v() both grow complex and require many tests (imagine 7+), you will want to test them separately. You could break the encapsulation of v() like I did in the previous section (eg make it package protected) and then test it. Job done! Bravo!
public void p(a) { // complexity v(a); // complexity } void v(a) { // complexity a.getProfile().f(); // NPE? }But later, testing p() becomes more cumbersome because it internally calls v() - and that forces you to enlarge the fixture when testing p(). For example, in the code above, the argument passed to p(a) has to have a non-null profile inside, otherwise, an exception will occur at line // NPE. This might be annoying because after all, we wrote dedicated tests for v() - so why am I still calling v() when testing p() - you might think.
You can fix this issue in several ways:
- Use the ObjectMother pattern (e.g.,
TestData.aValidCustomer()) to generate reasonable test data - in our case an object A that has a non-nullprofile. - Use partial mocks (
@Spy) to block the local calls tov()when testingp(). But used on a regular basis this approach leads to confusing tests, and to the desperate thought "What am I testing over here?!!". - Extract the low-level
v()into a separate class, applying the Separation by Layers of Abstraction principle. Then, you link the new class into the old one like any regular dependency.
Separation by Layers of Abstraction
Code in a class should be at the same level of abstraction.
If it's the first time you hear this, you are probably confused: "Level of abstraction"?! A more human interpretation of this principle would be: if you can separate complex logic in 'high-level layer' and 'low-level concerns', then break the code accordingly into separate classes.
So whenever you think of using a partial mock (@Spy), the tests are trying to point out that there are multiple levels of abstraction in the same class.
Fixture Creep
Two terms are used below:
- Test Fixture - the context in which a test executes: data present in the database, stubbed methods in dependencies, WireMock stubs, or any other pre-initialization.
- Before-init - code that runs before every
@Testin a test class: all the@BeforeEach(JUnit5) or@Before(JUnit4) methods, plus similar initialization methods inherited from any test superclasses.
To write more test cases, it is a fundamental goal in testing to shrink the test code while still keeping it expressive. Therefore, the shared part of the test fixture will be pulled in the before-init. The problem is that different sets of tests in that test class will require slightly different initialization.
For example, some tests need to clear some preexisting state while others want some other initial data to be persisted in the database in the before-init. Even if it starts innocent, at some point later a test will fail and you won't be able to tell which of those INSERTS are really used by the failed test?
Another common example is to pull in the before-init all the stubbing ( when(...).thenReturn(...)) ever needed by any of the @Tests in that test class. That will wreak havoc when trying to fix a failing test failure later - you won't be able to tell which part of the shared before-init is really used by the failing test. Fortunately, Mockito addressed this bad habit in more recent versions by failing the test if a stubbed method is never invoked by the code under test, that is having STRICT stubbing.
This led to the famous UnnecessaryStubbingException that caused a lot of panic in developer teams around the world when they upgraded their Mockito version. So resist the temptation to place @MockitoSettings(LENIENT) on your test class. One last word for Mockito: as a 'gray middle ground' consider selectively making a few particular stubbing lenient, via Mockito.lenient().when(..)...
Fixture Creep happens when you accumulate in before-init (eg
@BeforeEach) shared initialization for many tests, but not entirely applicable to each of them.
@BeforeEach void init() { // fixture creep when(..).thenReturn(..); xRepo.save(X1); yRepo.save(Y1); wireMock.stub... when(..).thenReturn(..); // etc, you got the point }Instead of accumulating a massive before-init, consider breaking the test class to keep your before-init specific to all @Test s in the test class. Yes, I mean 1 production class could be tested by multiple test classes - naming is key here: make sure you include the name of the tested class in the test class name, to ease later navigation.
And perhaps later, think: would it make sense to break the production class the same way you broke the tests? It could be a good idea to break complex logic into smaller pieces.
Break the test class to keep the before-init (eg
@BeforeEach) specific to all@Tests.
But what if we have to write 5 tests on a fixture, then 5 more on a fixture that builds on top of the previous one, and so on? This is sometimes referred to as 'hierarchical fixture', and typically occurs when unit-testing longer flows. JUnit offers 3 technical means of approaching this, in chronological order:
- Test classes extending from an abstract base inheriting @Before (JUnit 4 + 5)
- JUnit5 @Nested tests
- JUnit5 extensions (to init data via composition)
Mock Roles, Not Objects
Mocking blindly all dependencies of a component is one of the worst testing practices in mainstream use today. Most developers I met think Unit Testing means picking a class and @Mock ing everything around it. And then years later, they complain that Mocks are Evil because their tests are so fragile.
The real reason? They mocked unclear contracts, that eventually changed and made them suffer.
Before replacing a real object with a fake one (eg. a mock), you should first review the responsibilities of that dependency - does it have a well-defined role? Or is it just a 'random bag of functions'?
The pioneers of Mocking, the creators of jMock, wrote a paper called Mock Roles, not Objects back in the days that mocks were just entering our mainstream practice. And they said: before mocking a dependency look very careful at the contract exposed by that dependency. Is it well-encapsulated? It is sound? Does it feel right?
Carefully review an API before mocking it and make sure it has a clear, sharp responsibility.
The practice raises two problems though:
Evolving Code
Most of the time, we just have to adjust some existing behavior or build a small feature on top of a large existing codebase. When we do that, many developers are overwhelmed by the effort required if they decide to rearrange responsibilities in existing code - too many existing tests and mocks will break... Tough problem. So they drop the redesign thought from the very start.
Designing New Code
If there's a larger evolution to implement, how would you know the roles of the objects in the final design? At the start, there are no objects! There are two approaches to this problem: Outside-in and Inside-Out (aka London vs Chicago TDD schools). For a comparison between the two, check out this article.
To summarize, the decision is: do I want to mock an object before I implement it? I could if I can nail a pretty good contract from start. Otherwise, it might be safer to first explore the problem and deeply understand it. Should I start mocking earlier (London) or later (Chicago)? This is a fascinating topic, but a bit too complex to tackle here.
In any case, you won't escape refactoring methods that are both unit-tested here and mocked over there. This refactoring is very challenging even for experienced developers. But as with anything complex, deliberate practice is the fastest way to overcome this barrier. Try to work out some test refactoring katas - but unfortunately, you won't find many such exercises online.
Onion- Architecture, AKA Clean-, Hexagonal-
"Domain should not depend on the outside world".
The idea is very old, but it was rebranded several times in history under different names: Ports-and-Adapters, Hexagonal Architecture, Onion Architecture, Clean Architecture. It is so fundamental to design, that it was recently named The Universal Architecture.
Preserving an Agnostic Domain stops us from polluting our core logic with external influences (DTOs), or with the inherent complexity of interacting with the outside world. This way, we can keep our focus more on what's specific to our application, on the problem we have to solve.
Testing adds another dimension to this philosophy, by asking: do you want to write your tests in terms of external objects (DTOs)? No! They are ugly, rigid, foreign, and just... DTOs. The same would apply to aggressive libraries that impose their complex APIs deep in our code.
So we decouple Domain from Application/Infrastructure and we pull as much complexity we can inside the safety of our Domain, and then we cover this logic with tests that only speak in the terms of our own Domain Model. So here's the rule.
To keep your tests clean and expressive, prefer using Domain Model objects as:
- Parameters and return values of tested production code
- Data used in stubbing or verifying mocks
We automatically follow this guideline when testing deep in our domain logic, but it may cause debates when testing close to connection points to the outside world.
In the diagram below, our Facades (ApplicationServices) work with DTOs of our API (at least in my opinionated Pragmatic Clean Architecture), and Adapters work with DTOs of 3rd party APIs.
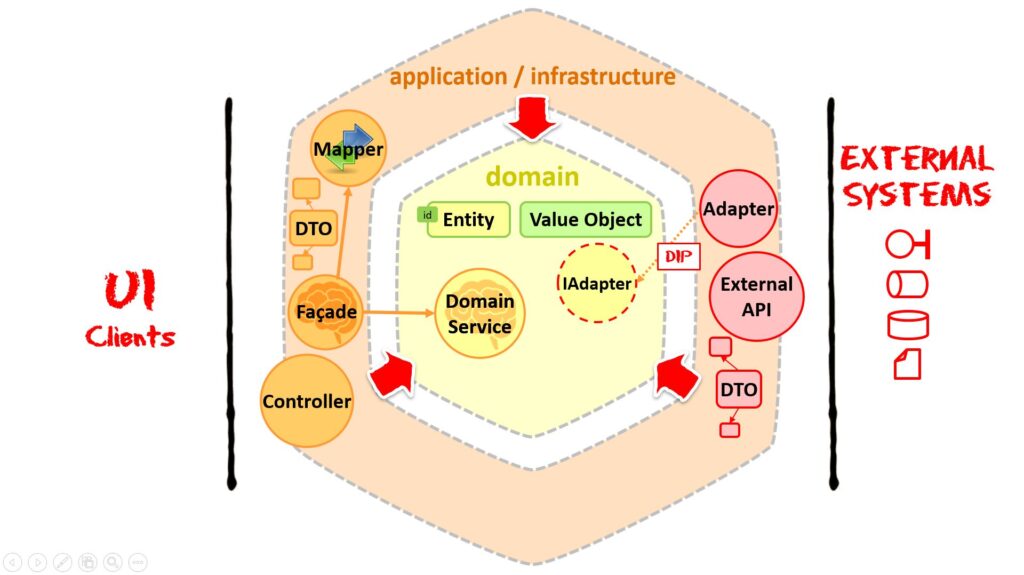
It is both a unit-testing and an architectural goal to write as much logic we can on our own domain model, minimizing the logic left "outside", in Facades and Adapters. And that is a healthy force, as more logic will be pushed into the friendly environment of our domain.
Always prefer using your Domain Model in your tests.
However, the code left outside can still host bugs, so how to test it?
Adapters
Calling other systems is classically done firing tests on the Adapter after setting up a WireMock stub. But the trend moves towards Contract Testing (e.g., Consumer-Driven Contract Tests - Pact, or Spring Cloud Contract) that keeps your 'expectations about the contract' in sync with the 'reality of the provider', even across systems.
Controllers + Facades
Calling our own endpoints is best done with end-to-end-ish tests, either with MockMvc or directly calling the controller method underlying the REST API.
Conclusion
A tough article, huh? And you used to write tests because 'you had to'.
I hope this article makes you listen more carefully to what tests are trying to tell you. And once you understand them, you will cherish your tests to their true value, as the best design feedback source you ever get.
If I missed some feedback hint or a nuance, please help me by leaving a comment.
Note: what triggered me to write this article was running my Unit Testing workshop with an excellent group of developers having decades of cumulated experience writing thorough unit tests. Thank you!
Published at DZone with permission of Victor Rentea. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments