Decoding eBPF Observability: How eBPF Transforms Observability as We Know It
Let’s look at eBPF. What is the technology, how is it impacting observability, and how does it compare with existing observability practices?
Join the DZone community and get the full member experience.
Join For FreeThere has been a lot of chatter about eBPF in cloud-native communities over the last 2 years. eBPF was a mainstay at KubeCon, eBPF days and eBPF summits are rapidly growing in popularity, companies like Google and Netflix have been using eBPF for years, and new use cases are emerging all the time. Especially in observability, eBPF is expected to be a game changer.
So let’s look at eBPF — what is the technology, how is it impacting observability, how does it compare with existing observability practices, and what might the future hold?
What Is eBPF Really?
eBPF is a programming framework that allows us to safely run sandboxed programs in the Linux kernel without changing kernel code.
It was originally developed for Linux (and it is still where the technology is most mature today), but Microsoft is rapidly evolving the eBPF implementation for Windows.
eBPF programs are, by design, highly efficient and secure — they are verified by the kernel to ensure they don’t risk the operating system’s stability or security.
So Why Is eBPF a Big Deal?
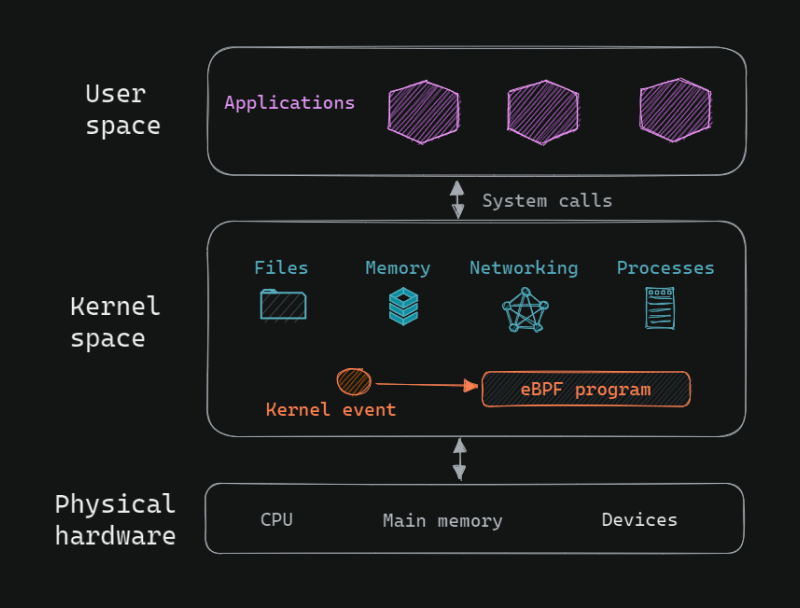
To understand this, we need to understand user space and kernel space.
User space is where all applications run. Kernel space sits between user space and the physical hardware. Applications in user space can’t access hardware directly. Instead, they make system calls to the kernel, which then accesses the hardware.
All memory access, file read/writes, and network traffic go through the kernel. The kernel also manages concurrent processes.
Basically, everything goes through the kernel (see the figure below).
And eBPF provides a safe, secure way to extend kernel functionality.
Historically, for obvious reasons, changing anything in the kernel source code or operating systems layer has been super hard.
The Linux kernel has 30M lines of code, and it takes several years for any change to go from an idea to being available widely. First, the Linux community has to agree to it. Then, it has to become part of the official Linux release. Then, after a few months, it is picked up by distributions like Red Hat and Ubuntu, which take it to a wider audience.
Technically, one could load kernel modules to one’s kernel and make changes directly, but this is very high risk and involves complex kernel-level programming, so is almost universally avoided.
eBPF comes along and solves this — and gives a secure and efficient mechanism to attach and run programs in the kernel.
Let’s look at how eBPF ensures both security and performance.
Highly Secure
- Stringent verification — Before any eBPF program can be loaded into a kernel, it is verified by the eBPF verifier, which ensures the code is absolutely safe — e.g., no hard loops, invalid memory access, unsafe operations.
- Sandboxed — eBPF programs are run in a memory-isolated sandbox within the kernel, separate from other kernel components. This prevents unauthorized access to kernel memory, data structures, and kernel source code.
- Limited operations — eBPF programs typically have to be written in a small subset of the C language — a restricted instruction set. This limits the operations that eBPF programs can perform, reducing the risk of security vulnerabilities.
High-Performance/Lightweight
- Run as native machine code — eBPF programs are run as native machine instructions on the CPU. This leads to faster execution and better performance.
- No context switches — A regular application regularly context-switches between user-space and kernel-space, which is resource intensive. eBPF programs, as they run in the kernel layer, can directly access kernel data structures and resources.
- Event-driven — eBPF programs typically run only in response to specific kernel events vs being always-on. This minimizes overhead.
- Optimized for hardware — eBPF programs are compiled into machine code by the kernel’s JIT (Just-In-Time) compiler just before execution, so the code is optimized for the specific hardware it runs on.
So eBPF provides a safe and efficient hook into the kernel for programming. And given everything goes through the kernel, this opens up several new possibilities that weren’t possible until now.
Why Is This a Big Deal Only Now?
The technology around eBPF has evolved over a long time and has been ~30 years in the making.
In the last 7–8 years, eBPF has been used at scale by several large companies and now we’re entering an era where the use of eBPF is becoming mainstream. See this video by Alexei Starovoitov, the co-creator of Linux and co-maintainer of eBPF, on the evolution of eBPF.
eBPF — A Brief History
- 1993- A paper from Lawrence Berkeley National Lab explores using a kernel agent for packet filtering. This is where the name BPF (“Berkeley Packet Filter”) comes from.
- 1997 — BPF is officially introduced as part of the Linux kernel (version 2.1.75).
- 1997–2014 — Several features are added to improve, stabilize and expand BPF capabilities.
- 2014 — A significant update is introduced, called “extended Berkeley packet Filter” (eBPF). This version makes big changes to BPF technology & makes it more widely usable — hence the word “extended”
Why this release was big, was that this made extending kernel functionality easy.
A programmer could code more or less like they would a regular application — and the surrounding eBPF infrastructure takes care of the low-level verification, security, and efficiency.
An entire supporting ecosystem and scaffolding around eBPF makes this possible (see figure below).
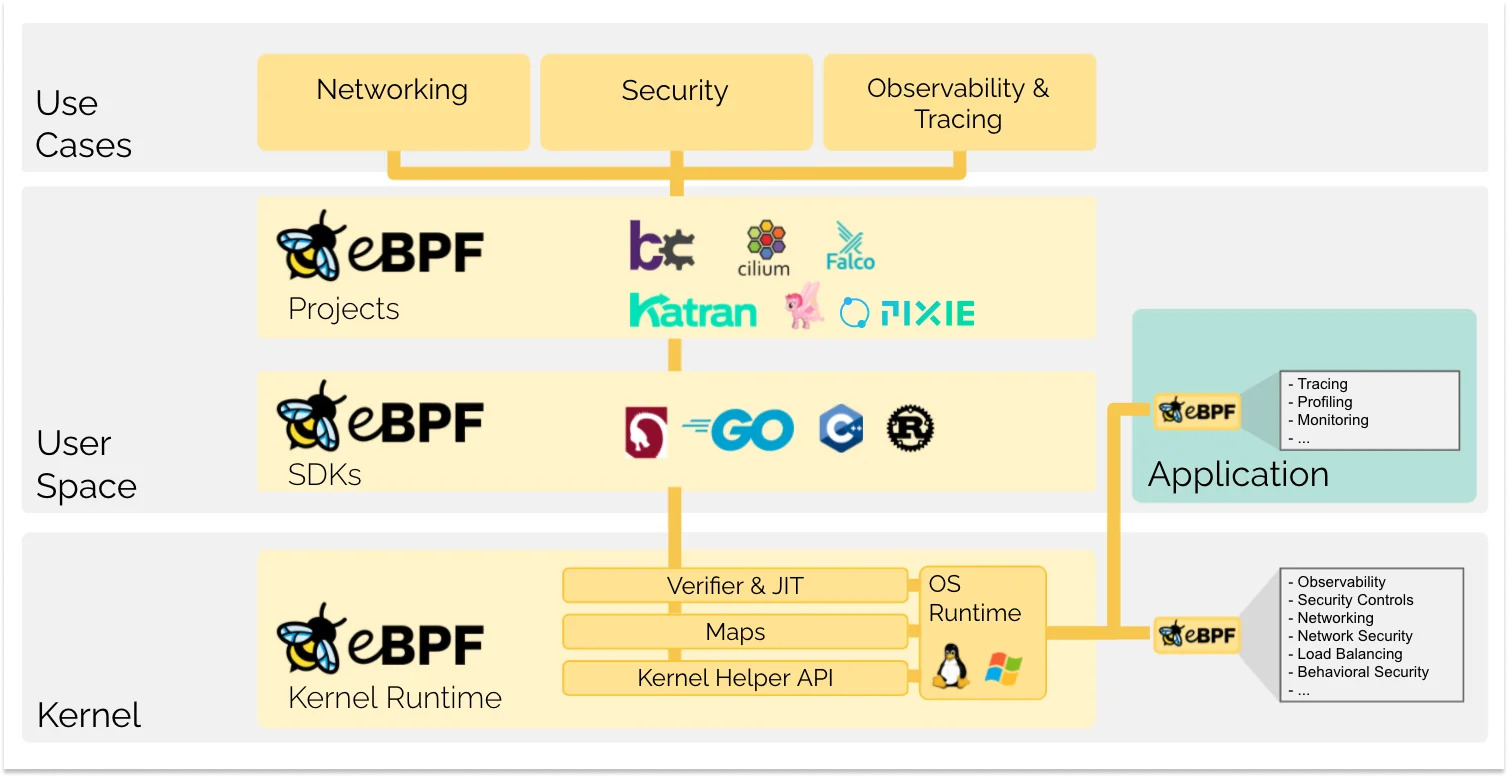
Even better, eBPF programs could be loaded and unloaded from the kernel without any restarts.
All this suddenly allowed for widespread adoption and application.
Widespread Adoption in Production Systems
eBPF’s popularity has exploded in the last 7–8 years, with several large companies using it in scale production systems.
- By 2016, Netflix was using eBPF widely for tracing. Brendan Gregg, who implemented it, became widely known in infrastructure & operations circles as an authority on eBPF.
- 2017 — Facebook open-sourced Katran, their eBPF-based load balancer. Every single packet to Facebook.com since 2017 has passed through eBPF.
- 2020- Google made eBPF part of its Kubernetes offering. eBPF now powers the networking, security, and observability layer of GKE. By now there’s also broad enterprise adoption in companies like Capital One and Adobe.
- 2021 — Facebook, Google, Netflix, Microsoft & Isovalent came together to announce the eBPF foundation to manage the growth of eBPF technology.
Now there are thousands of companies using eBPF and hundreds of eBPF projects coming up each year exploring different use cases.
eBPF is now a separate subsystem within the Linux kernel with a wide community to support it. The technology itself has expanded considerably with several new additions.
So What Can We Do With eBPF?
The most common use cases for eBPF are in 3 areas:
- Networking
- Security
- Observability
Security and networking have seen wider adoption and application, fueled by projects like Cilum. In comparison, eBPF-based observability offerings are earlier in their evolution and just getting started.
Let’s look at the use cases in security and networking first.
Security
Security is a highly popular use case for eBPF. Using eBPF, programs can observe everything happening at the kernel level, process events at a high speed to check for unexpected behavior, and raise alerts much more rapidly than otherwise.
For example:
Several third-party security offerings now use eBPF for data gathering and monitoring.
Networking
Networking is another widely applied use case. Being at the eBPF layer allows for comprehensive network observability, like visibility into the full network path including all hops, along with source and destination IP. With eBPF programs, one can process high-volume network events and manipulate network packets directly within the kernel with very low overhead.
This allows for various networking use cases like load balancing, DDoS prevention, Traffic shaping, and Quality of Service (QoS).
- Cloudflare uses eBPF to detect and prevent DDoS attacks, processing 10M packets per second without impacting network performance.
- Meta’s eBPF-based Katran does load-balancing for all of Facebook
Observability
By now it must be straightforward how eBPF can be useful in observability.
Everything passes through the kernel. And eBPF provides a highly performant and secure way to observe everything from the kernel.
Let us dive deeper into observability and look at the implications of this technology.
How Exactly Does eBPF Impact Observability?
To explore this, let’s step out of the eBPF universe and into the observability universe and look at what makes up our standard observability solution.
Any observability solution has 4 major components:
- Data collection — Getting telemetry data from applications and infrastructure
- Data processing — Filtering, indexing, and performing computations on the collected data
- Data storage — Short-term and long-term storage of data
- User experience layer — Determining how data is consumed by the user
Of this, what eBPF impacts (as of today), is really just the data collection layer — the easy gathering of telemetry data directly from the kernel using eBPF.
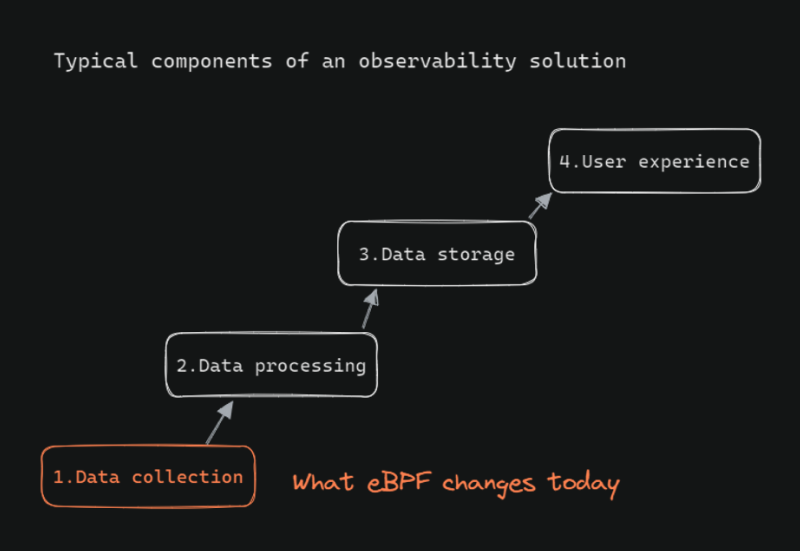
So what we mean when we say “eBPF observability” today, is using eBPF as the instrumentation mechanism to gather telemetry data, instead of using other methods of instrumenting. Other components of an observability solution remain unaffected.
How eBPF Observability Works
To fully understand the underlying mechanisms behind eBPF observability, we need to understand the concept of hooks.
As we saw earlier, eBPF programs are primarily event-driven — i.e., they are triggered any time a specific event occurs. For example, every time a function call is made, an eBPF program can be called to capture some data for observability purposes.
First, these hooks can be in kernel space or user space. So eBPF can be used to monitor both user space applications as well as kernel-level events.
Second, these hooks can either be pre-determined/static or inserted dynamically into a running system (without restarts!).
Four distinct eBPF mechanisms allow for each of these (see figure below):

Static and dynamic eBPF hooks into user space and kernel space
- Kernel tracepoints — used to hook into events pre-defined by kernel developers (with TRACE_EVENT macros)
- USDT — used to hook into predefined tracepoints set by developers in application code
- Kprobes (Kernel Probes) — used to dynamically hook into any part of the kernel code at runtime
- Uprobes (User Probes) — used to dynamically hook into any part of a user-space application at runtime
There are several pre-defined hooks in the kernel space that one can easily attach an eBPF program to (e.g., system calls, function entry/exit, network events, kernel tracepoints). Similarly in the user space, many language runtimes, database systems, and software stacks expose predefined hooks for Linux BCC tools that eBPF programs can hook into.
But what’s more interesting is kprobes and uprobes. What if something is breaking in production and I do not have sufficient information and I want to dynamically add instrumentation at runtime? That is where kprobes and uprobes allow for powerful observability.
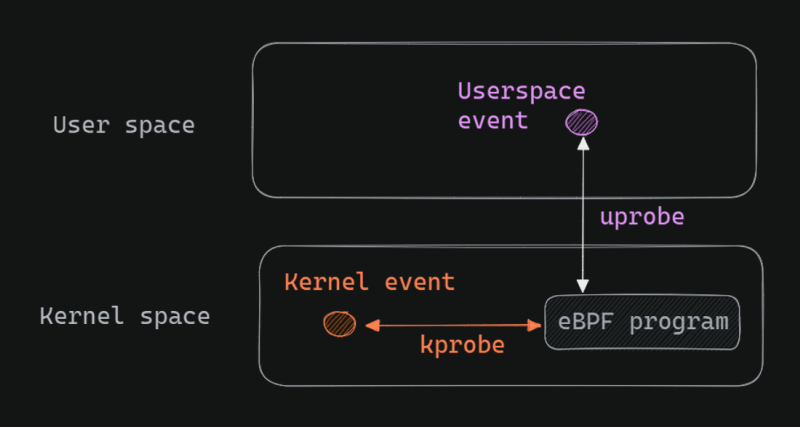
For example, using uprobes, one can hook into a specific function within an application without modifying the application’s code, at runtime. Whenever the function is executed, an eBPF program can be triggered to capture required data. This allows for exciting possibilities like live debugging.
Now that we know how observability with eBPF works, let’s look at use cases.
eBPF Observability Use Cases
eBPF can be used for almost all common existing observability use-cases, and in addition opens up new possibilities.
- System and Infrastructure Monitoring: eBPF allows for deep monitoring of system-level events such as CPU usage, memory allocation, disk I/O, and network traffic. For example, LinkedIn uses eBPF for all their infra monitoring.
- Container and Kubernetes Monitoring: Visibility into Kubernetes-specific metrics, resource usage, and health of individual containers and pods.
- Application Performance Monitoring (APM): Fine-grained observability into user-space applications and visibility into application throughput, error rates, latency, and traces.
- Custom Observability: Visibility into custom metrics specific to applications or infra that may not be easily available without writing custom code.
- Advanced Observability: eBPF can be used for advanced observability use cases such as live debugging, low-overhead application profiling, and system call tracing.
There are new applications of eBPF in observability emerging every day.
What does this mean for how observability is done today? Is eBPF likely to replace existing forms of instrumentation? Let’s compare with existing options.
eBPF vs. Existing Instrumentation Methods
Today, there are two main ways to instrument applications and infrastructure for observability, apart from eBPF.
- Agent-based instrumentation: Independent software SDKs/libraries integrated into application code or infrastructure nodes to collect telemetry data.
- Sidecar proxy-based instrumentation: Sidecars are lightweight, independent processes that run alongside an application or service. They are popular in microservices and container-based architectures such as Kubernetes.
For a detailed comparison of how eBPF-based instrumentation compares against agents and sidecars, see here. Below is a summary view:
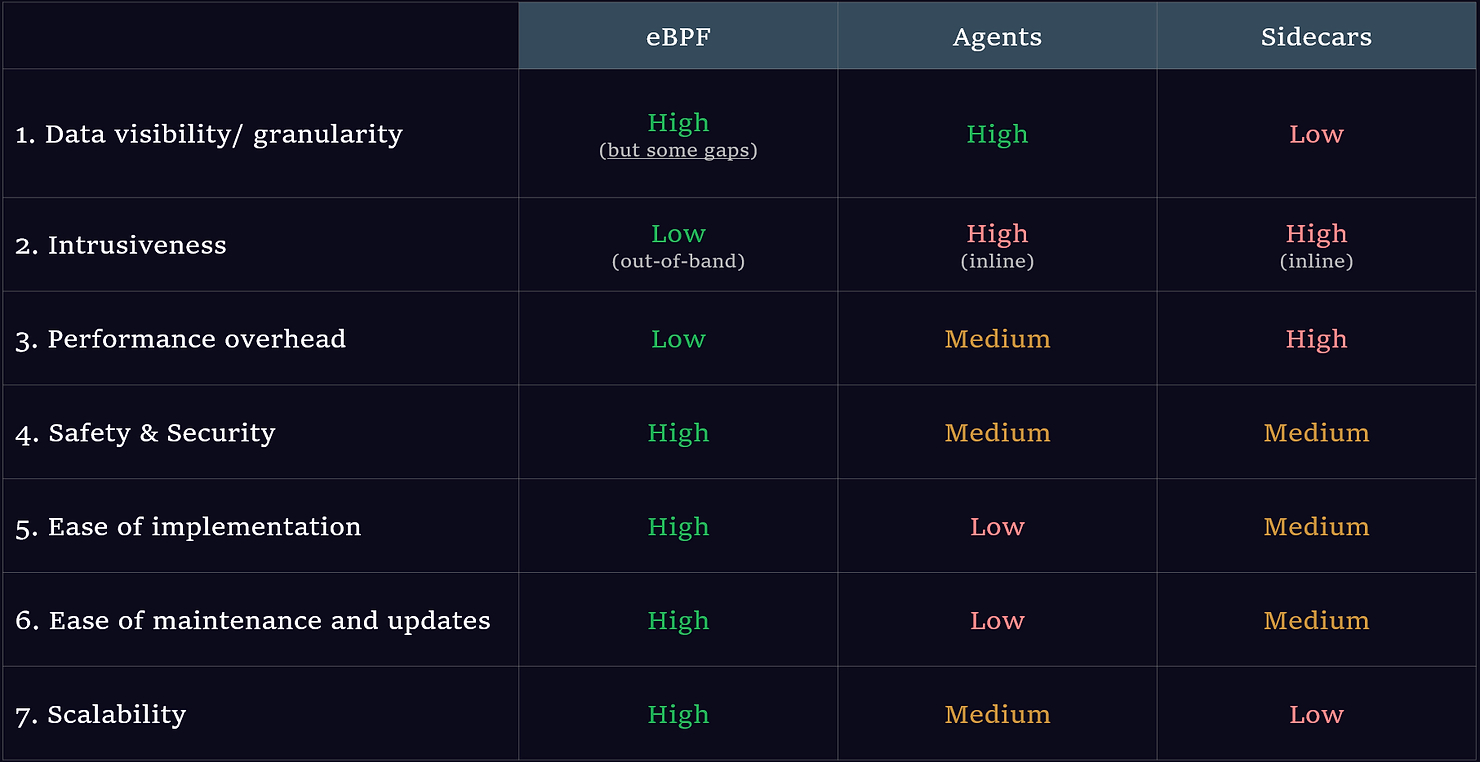 eBPF vs. agents vs. sidecars: Comparison
eBPF vs. agents vs. sidecars: Comparison
As we can see, eBPF outperforms existing instrumentation methods across nearly all parameters. There are several benefits:
- Can cover everything in one go (infrastructure, applications)
- Less intrusive — eBPF is not inline of running workloads like code agents, which run every time the workload runs. Data collection is out-of-band and sandboxed, so there is no impact on a running system.
- Low performance overhead — eBPF runs as native machine code and there is no context switching.
- More secure — due to in-built security measures like verification.
- Easy to install — can be dropped in without any code change or restarts.
- Easy to maintain and update — again no code change & restarts.
- More scalable — driven by easy implementation & maintenance, and low performance overhead
In terms of cons, the primary gap with eBPF observability today is in distributed tracing (feasible, but the use case is still in early stages).
In balance, given the significant advantages eBPF offers over existing instrumentation methods, we can reasonably expect that eBPF will emerge as the default next-generation instrumentation platform.
Implications for Observability
What does this mean for the observability industry? What changes?
Imagine an observability solution:
- that you can drop into the kernel in 5 minutes
- no code change or restarts
- covers everything in one go — infrastructure, applications, everything
- has near-zero overhead
- is highly secure
That is what eBPF makes possible. And that is the reason why there is so much excitement around the technology.
We can expect the next generation of observability solutions to all be instrumented with eBPF instead of code agents.
Traditional players like Datadog and NewRelic are already investing in building eBPF-based instrumentation to augment their code-based agent portfolio. Meanwhile there are several next-generation vendors built on eBPF, solving both niche use cases and for complex observability.
While traditional players had to build individual code agents language by language and for each infrastructure component over several years, the new players can get to the same degree of coverage in a few months with eBPF. This allows them to also focus on innovating higher up the value chain like data processing, user experience, and even AI. In addition, their data processing and user experience layers are also built ground-up to support the new use cases, volumes and frequency.
All this should drive a large amount of innovation in this space and make observability more seamless, secure and easy to implement over the coming years.
Who Should Use eBPF Observability?
First, if you’re in a modern cloud-native environment (Kubernetes, microservices), then the differences between eBPF-based and agent-based approaches are most visible (performance overhead, security, ease of installation etc).
Second, if you are operating at a large scale, then eBPF-based lightweight agents will drive dramatic improvements over the status quo. This is likely one of the reasons why eBPF adoption has been highest in technology companies with massive footprints like LinkedIn, Netflix, and Meta.
Third, if you’re short on tech capacity and are looking for an observability solution that requires almost no effort to install and maintain, then go straight for an eBPF-based solution.
Summary
In summary, by offering a significantly better instrumentation mechanism, eBPF has the potential to fundamentally reshape our approach to observability in the years ahead.
While in this article we primarily explored eBPF’s application in data collection/instrumentation, future applications could see eBPF used in data processing or even data storage layers. The possibilities are broad and as yet unexplored.
Published at DZone with permission of Samyukktha T. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments