Data Mesh — Graduating Your Data to Next Level
Data Mesh has the potential to completely change the way we handle and look at our data. This will impact all areas where data is the critical element.
Join the DZone community and get the full member experience.
Join For FreeData Mesh is fast emerging as a serious architecture pattern to look for in the field of data. I will stop after saying 'field of data' rather than extending the 'data' to data science, data engineering, data warehouse, and all such kinds of buzz words. We in IT have the habit of creating buzzwords and then following them. I just want to focus on something other than just the buzzword. The reason for this is Data Mesh has the potential to completely change the way we handle and look at our data. This will have an impact on all areas where data is the critical element.
Report Card For Current Level of Data
Before we graduate our data to the next level, here is a quick summary of progress or a report card of the current level of data. The diagram below shows how data is normally handled in today's IT systems.
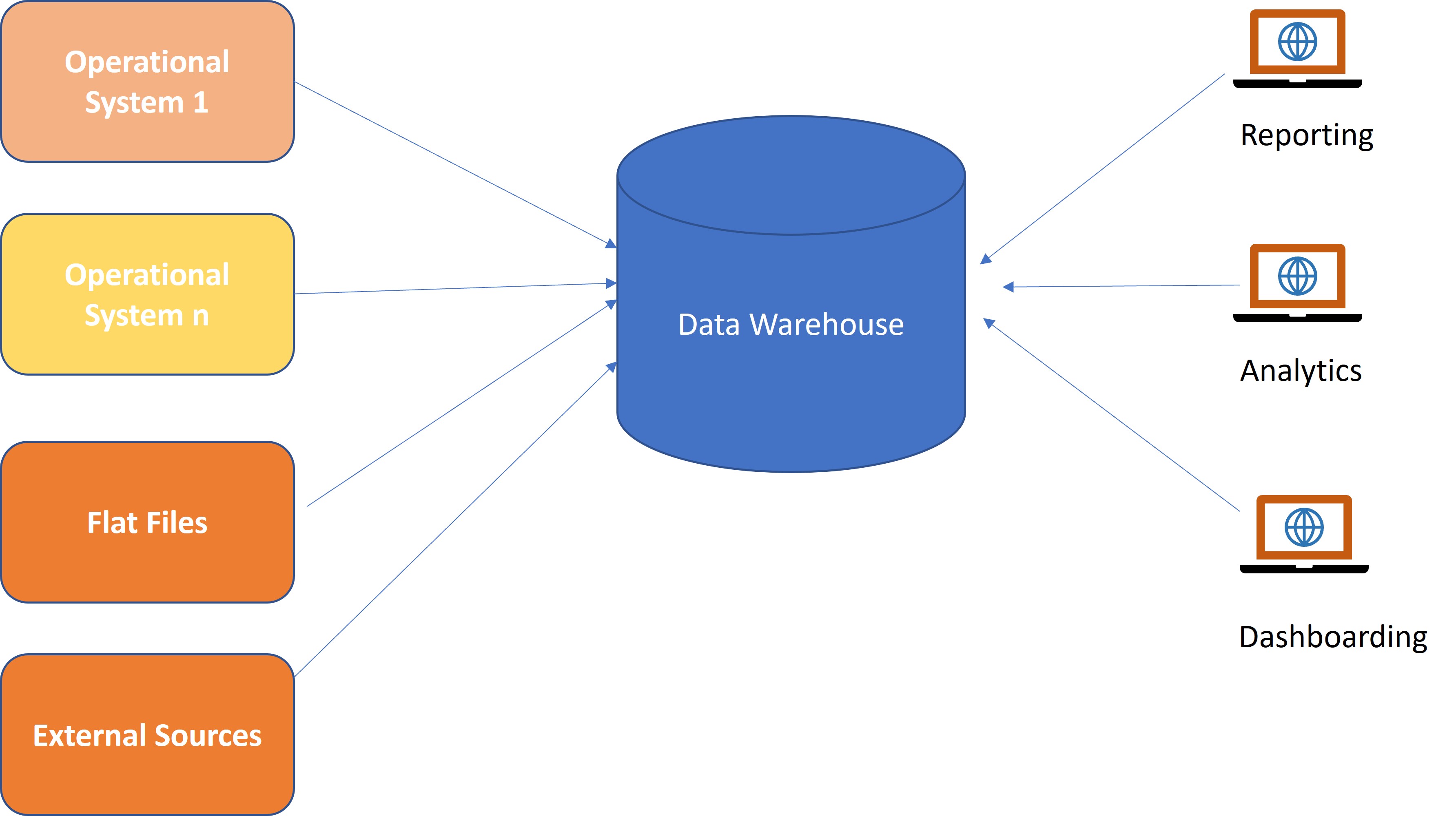
As shown above, data from various transactional/operational and external systems would flow into the Data warehouse via a web of ETL jobs. Lots of activities like cleansing, transformation, etc., would be done before this data can be aggregated/summarized and used by end consumers.
This approach has served us well for more than a few decades. But in today's world of ubiquitous data, this approach is hitting the ceiling. The same can be said about modern data lakes. In fact, in most cases, the data lake situation is even worse.
With the advent of Big Data/ IoT and streams of data, most organizations didn't know what to do with the data. Although they knew data is the new oil but didn't know how to refine and use this oil. They even didn't have many ideas about the analytical use cases they wanted to handle using this data. Maybe the buzzword of data lakes did them in. As everyone else was doing data-lake, so more and more people started doing this.
A few lines back, I said that with a data lake, the situation is even worse. And the primary reason is that with data warehouses, there is still some kind of governance and strategy in place for most organizations. But for data lakes, majority of instances, all kind of data ( structured/logs /streaming data, etc.) is simply being dumped into some cheap storage, with the idea that sometime in the future, they will have use cases to get the benefit from the new oil field they are creating. But wishes don't always come true.
Some Improvement Areas From the Report Card
- As data is centralized and with ubiquitous data, the volume and velocity of data are becoming so huge for a centralized system to handle
- Data engineers/data warehousing teams don't know much about the operation data, its domain, and intricacies
- No much agility about. how changes can be handled in such a system
How Application Layer Graduated to Next Level
Over the last few years, Domain-Driven design and microservices have really changed the way the application tier is handled. A big monolith is converted to domain-specific capabilities or microservices. This allows domain teams to focus on their own domain-specific capabilities. They own the domain, and they know the domain inside out. Not to mention the agility we have seen in these kinds of environments (of course, with great tooling and processes like CI/CD, DevOps, Containers, etc.).
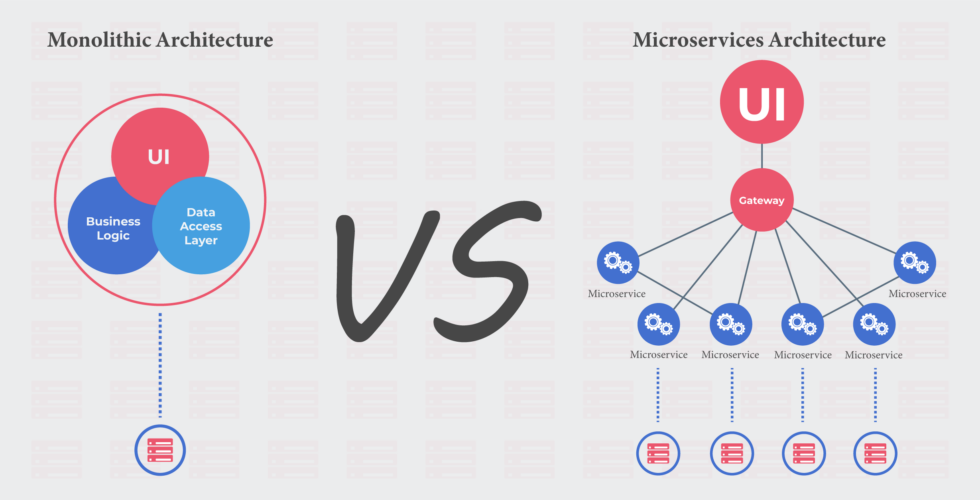
Converting a Monolith Application to Microservices Using
Domain-Driven Design
If you just look at both the diagrams above, you can see that we are taking exactly opposite approaches at the application layer and data layer. While at the application layer, we are simply breaking the monolith into multiple smaller units, in the database layer, we are bringing data from individual domains and putting it into one big monolith unit.
And that's where Data Mesh comes in. Enough of suspense-building. Let us have a quick look at what exactly this data mesh is.
The data mesh architecture empowers business domains with autonomy to define, create, govern, and share data products. So basically, each business domain will own its data. They can share it with consumers using APIs etc., but they manage all the life cycle of data.
1) As there is no one big centralized monolith, individual data products can scale better ( distributed scaling)
2) Each domain team owns and governs its data and products ( Federated Data Governance)
3) Each product team knows its data and domain better than any centralized team can know
4) Better agility
Bit of Advice
As mentioned in the opening lines, don't fall for a buzzword. Is Data Mesh a buzzword or a perfect fit for you, only you can assess and make a decision? I have seen people doing SOA wrong, I saw people doing P2P wrong, and I saw people doing REST and microservices wrong. And, of course, data lakes as well. Take an informed decision whether this is something for you or not.
Opinions expressed by DZone contributors are their own.
Comments