Efficient Data Management With Offset and Cursor-Based Pagination in Modern Applications
Explore offset and cursor-based pagination, integrated with Jakarta Data, Quarkus, and MongoDB, highlighting their benefits and practical use in REST APIs.
Join the DZone community and get the full member experience.
Join For FreeManaging large datasets efficiently is essential in software development. Retrieval strategies play a crucial role in improving performance and scalability, especially when response times are critical. Pagination is a core technique used to manage data effectively. It is essential for optimizing performance and resource management. In this article, we will explore two pagination strategies, offset and cursor-based pagination, that are suited to different scenarios and requirements. These strategies will help you understand the importance of pagination and how they can benefit your system.
Leveraging Jakarta Data, this exploration integrates these pagination techniques into a REST API developed with Quarkus and MongoDB. This combination demonstrates practical implementation and highlights the synergy between modern technologies and advanced data handling methods.
This discussion aims to comprehensively understand each pagination method’s mechanics, benefits, and trade-offs, empowering developers to make informed decisions suited to complex and high-demand applications.
Pagination: From Ancient Scrolls to Modern Databases
Pagination, a critical concept in data organization, transcends its modern digital application, tracing its roots back to the earliest forms of written records. In contemporary usage, pagination divides content into discrete pages, whether in print or digital. This technique is pivotal for improving the user experience by making information access manageable and intuitive and enhancing the performance of data retrieval systems by limiting the volume of data loaded or rendered at any one time.
The necessity for effective data organization is a complex dilemma. Ancient civilizations like Rome, developed early methods to manage extensive written information. Although the Romans did not use pagination in the way we understand it today — dividing texts into pages — they implemented organizational methods that foreshadowed modern pagination systems.
Long texts in Rome were typically inscribed on scrolls made of papyrus or vellum. These scrolls, cumbersome in length, were navigated with indices and markers. Such markers functioned similarly to a modern table of contents, guiding readers to different text sections. While rudimentary by today's standards, this method represented an early form of pagination, as it organized information into segments that could be accessed independently.
Additionally, the Romans used wax tablets for shorter documents. These tablets could be bound together, forming a structure akin to today's books — a codex. The advent of the codex was a significant evolution in text organization, allowing for faster and more efficient information access. Users could flip through pages, a clear predecessor to our current pagination systems, which significantly enhanced the speed and ease of reviewing information.
In the digital age, pagination is essential for handling large datasets effectively. Digital pagination helps manage server loads and improve response times by delivering content in segments rather than requiring the entire dataset to be loaded simultaneously. It conserves resources and improves user interactions with applications by providing a seamless navigational experience.
The parallels between ancient Roman text organization methods and modern digital pagination highlight a continuous need throughout history: efficiently managing large quantities of information. Whether through physical markers in scrolls, the development of the codex, or sophisticated digital pagination algorithms, the core challenge remains the same—making information accessible and manageable.
Pagination in Modern Applications: Necessity and Strategies
Pagination is an essential feature in modern software applications that helps to structure data into manageable pieces. This approach enhances user experience by preventing information overload and optimizes application performance by reducing the load on backend systems. When data is paginated, systems can query and render only the necessary subset of data at a time, thereby reducing memory usage and improving response times. It is especially critical in large datasets or high-user concurrency applications, where efficient data handling can significantly improve scalability and user satisfaction.
Pagination can be very useful, but it also poses some challenges. Developers need to balance user experience and server performance carefully. Implementing pagination requires additional logic on both the client and server sides, which can complicate development. While pagination can reduce initial load time by fetching only a part of the data, it may increase the total waiting time for users as they navigate through multiple pages. Maintaining context between pages, such as sorting and filters, also requires careful state management and adds to the complexity.
In modern web development, two popular pagination strategies are popular: offset pagination and cursor-based pagination. Each strategy has advantages and drawbacks, making it more suitable for different scenarios.
Offset Pagination
Offset pagination is a traditional method of dividing data into manageable chunks. Data is accessed by skipping a specified number of records before returning a set amount. This technique is often used in web and database applications to facilitate direct navigation to particular pages using a simple numeric offset.
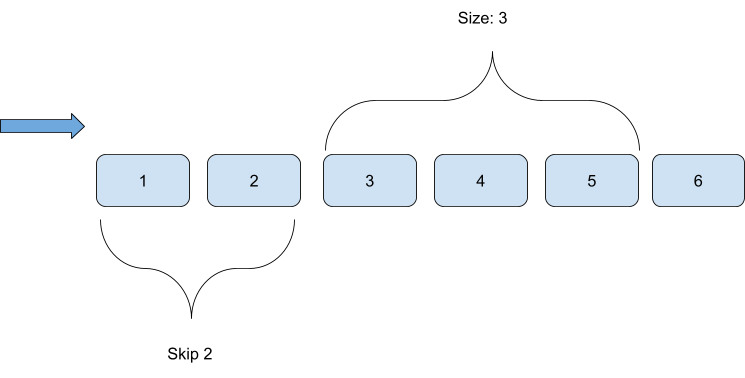
Figure 1: An offset pagination illustration
The implementation of offset pagination generally involves two critical parameters in database queries:
LIMIT: This parameter specifies the maximum number of records to return in a single page. It defines the size of each chunk of data, aligning with the concept of a “page” in pagination.OFFSET: This parameter indicates the number of records to skip from the beginning of the dataset. The value of theOFFSETis typically calculated as(page number - 1) * page size, allowing users to jump directly to the start of any page.
Offset pagination is highly favored for its simplicity and straightforward implementation. It is particularly effective in applications where users benefit from being able to jump directly to a specific page and where the total number of records is known and relatively stable. It makes it ideal for situations where user-friendly navigation and simplicity are paramount.
The main limitation of offset pagination is its scalability with large datasets. As the dataset grows and users request pages with higher numbers, the cost of skipping many records increases. This results in slower query performance because each subsequent page requires counting and skipping more records to reach the starting point of the desired page.
If the underlying data is subject to insertion, deletion, or modification, users may experience “phantom reads” or skipped records as they navigate between pages. It happens because the offset does not account for changes in the dataset’s size or order after the initial page load.
Offset pagination remains a popular choice for many applications due to its user-friendly approach and ease of implementation. However, understanding its limitations and properly planning its use is crucial to ensure that the system remains responsive and provides a good user experience as data scales.
Cursor-Based Pagination
Cursor-based pagination is an efficient method for managing data retrieval in large or dynamically updated datasets. It employs a cursor, which is a reference to a specific point in the dataset, to fetch data sequentially starting from the cursor’s position.
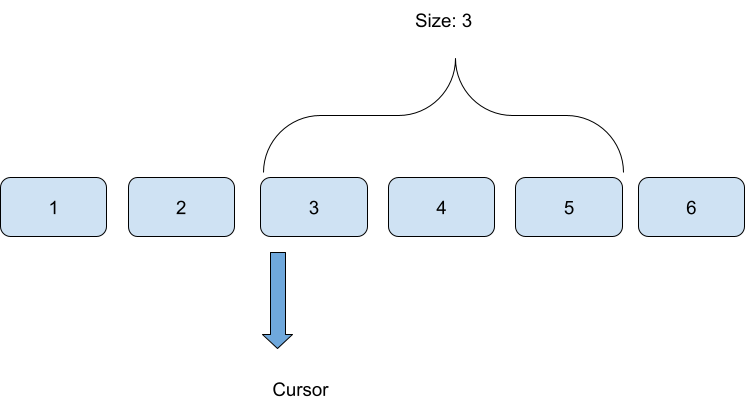
Cursor-based pagination relies on a cursor to guide data fetching. The cursor can comprise multiple fields to ensure precise data retrieval and maintain sort order. Here’s how it can be structured:
Cursor Fields
One or more fields uniquely identify each record’s position within the dataset. These fields should be stable (i.e., not change once set) and unique to prevent duplicates and ensure data integrity. Commonly used fields include timestamps, unique IDs, or combinations of multiple fields to support complex sorting requirements.
Query Direction
This specifies whether the data retrieval should move forward or backward relative to the cursor’s position. It is beneficial in applications like social media feeds or log monitoring systems where newer or older entries might be of interest.
Usage of Multiple Fields
When sorting by multiple criteria (e.g., sorting blog posts by both creation_date and title), a cursor can include these fields to ensure that pagination maintains the specified sort order across queries. It is essential for consistency, especially in cases where the dataset is large or frequently updated.
Using a cursor in pagination is particularly advantageous for large or frequently updated datasets, as it avoids the performance overhead of skipping over records and ensures consistent access to data.
While cursor-based pagination provides significant performance benefits and enhances data consistency, its implementation can be complex. It requires the setup of a stable and unique cursor, which can be challenging, especially in datasets without obvious unique identifiers. Additionally, it restricts users to sequential navigation, which can be a limitation in use cases requiring random access to data. Adjusting the user interface to work smoothly with cursor-based pagination, especially when using multiple fields in a cursor, can also add to the development complexity.
Developers often have to choose between offset and cursor-based pagination when implementing pagination in their applications. Each method presents different advantages and challenges. To make an informed decision, it is vital to understand how these methods compare across various dimensions, such as ease of implementation, performance, data consistency, and user navigation. To help identify the most suitable pagination strategy for different scenarios in software development, the following table provides a comprehensive comparison of offset and cursor-based pagination, highlighting key features and typical use cases. Additionally, the table also considers scalability.
| Feature | Offset Pagination | Cursor-based Pagination |
|---|---|---|
|
Description |
Paginates data using a numeric offset to skip several records before returning the next set |
Uses a cursor, often a unique identifier, to fetch data sequentially from the specified position |
|
Implementation Ease |
Implementing basic SQL or NoSQL queries with |
More complex to implement, requiring a stable and unique field as the cursor |
|
Best Use Cases |
Well-suited for small to medium datasets and applications where total data count and direct access to any page are beneficial |
Ideal for large or dynamically changing datasets where performance and data consistency are critical |
|
Performance |
Performance degrades as the dataset size increases, especially when accessing higher page numbers due to increased load in skipping records. |
Consistently high performance as it avoids the overhead of skipping records and directly accessing data starting from the cursor’s position |
|
Data Consistency |
Susceptible to issues like phantom reads or data duplication during pagination if underlying data changes |
Offers better consistency as each page load depends on the cursor’s position, which can adapt to changes in the data |
|
User Navigation |
Allows users to jump to any specific page directly, facilitating random access |
Generally restricts users to sequential navigation, which might not be suitable for all applications |
|
Complexity of Queries |
Simple queries, straightforward pagination logic |
Queries can be complex, especially when multiple fields are used as cursors to maintain order and uniqueness |
|
Scalability |
Less scalable with larger datasets due to increased query load for higher offsets |
Highly scalable, particularly effective in handling huge datasets efficiently |
When dealing with large datasets, it is essential to understand the efficiency and limitations of pagination strategies. One major challenge with offset-based pagination is that it becomes more difficult to access the data as the offset increases, particularly in large datasets. For example, if a dataset has 1 million records and is divided into pages of 100, accessing the final page (page 10,000) would require the database to process and discard the initial 999,900 records before delivering the last 100. It can result in longer load times as the dataset grows, making offset pagination less practical for handling large amounts of data.
Cursor-based pagination is a more efficient solution for managing extensive datasets than offset pagination. With offset pagination, high offsets can cause performance issues, but cursor-based pagination avoids these pitfalls by using a pointer to track the last record fetched. This method enables subsequent queries to start from where the last one ended, resulting in faster data retrieval. To illustrate this point, the graph accompanying this text compares the performance of offset pagination versus cursor-based pagination in handling a dataset of 7.3 million records, showing the significant speed advantage of using cursors.
This visual representation underscores the strategic importance of choosing the appropriate pagination method, considering factors such as the dataset size and access patterns. This ensures optimal performance and user experience, a crucial consideration in large-scale data handling.
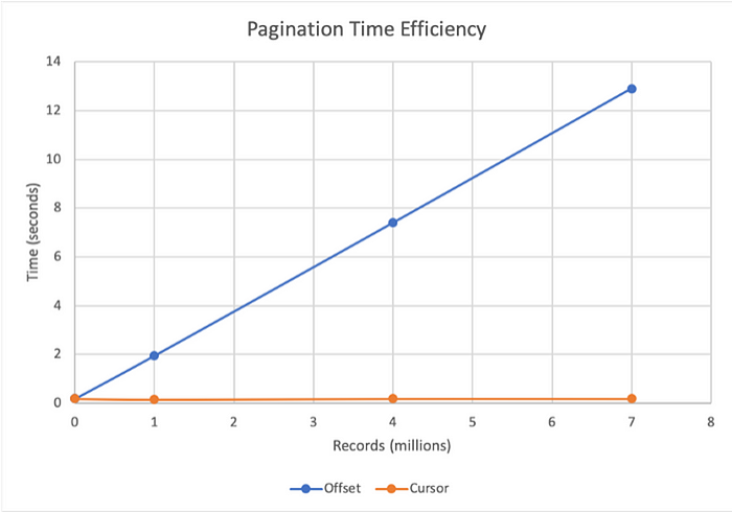
Figure 3: Offset pagination vs Cursor pagination for 7.3 million records in MySQL (Source)
Choosing between offset and cursor-based pagination depends on an application's specific needs. Offset works well for smaller datasets or when direct page access is necessary, while cursor-based pagination is better for large or dynamic datasets. Next, we'll demonstrate both methods in a sample app to show the real-world implications of each.
Introduction To Practical Pagination
In this section, we transition from theoretical discussions about pagination to a practical demonstration, focusing on the distinct methods of implementing offset and cursor-based pagination. We’ll explore these concepts hands-on, utilizing Jakarta Data within a Quarkus application paired with MongoDB. This setup will enable us to directly compare the two pagination techniques by manipulating a manageable dataset of fruits.
Our goal is to provide a clear illustration of how both pagination strategies can be seamlessly integrated and managed using Jakarta Data, a powerful toolset for data handling in Java applications. While this demonstration focuses on a simple scenario involving just ten elements, it’s important to note that the principles and methods discussed are not limited to small datasets. They are scalable and applicable to much larger datasets, giving you the confidence to apply these strategies in real-world scenarios.
Moreover, the broader context of developing a comprehensive REST API, including using query parameters and implementing HATEOAS (Hypermedia as the Engine of Application State) for pagination, merits a detailed discussion that could quickly fill its dedicated article. The complexities involved in designing such APIs and the strategies for incorporating pagination efficiently are substantial topics that we will not delve into deeply here. Instead, this demonstration aims to introduce the core concepts of pagination with Jakarta Data, focusing on the technical implementation of the pagination mechanisms rather than the intricacies of the REST API design. We will provide references at the conclusion for those interested in exploring the broader context and details of REST API construction in further depth.
This article specifically discusses the pagination features available in Jakarta Data. However, it’s important to note that Jakarta Data provides a wide range of functionalities that aim to make persistence integration for Jakarta EE applications simpler.
Jakarta Data facilitates pagination through its API, enabling efficient data handling and retrieval in applications that manage large datasets or require sophisticated query capabilities. Two primary components underpin the pagination functionality:
1. PageRequest Creation
Jakarta Data provides the PageRequest class to encapsulate pagination requests. Here’s how you can specify different types of pagination:
Offset-Based Pagination
This is used when you want to specify a particular page and size for the data retrieval. It’s straightforward and suitable for many standard use cases where the total number of items is known.
PageRequest offSet = PageRequest.ofPage(1).size(10);
Cursor-Based Pagination
This method is used when dealing with continuous data streams or when the dataset is large and frequently updated. It allows fetching data continuously from a certain point without re-querying the previously fetched records.
PageRequest cursor = PageRequest.ofSize(10).afterCursor(PageRequest.Cursor.forKey("key"));
Both methods are designed to optimize data fetching processes by limiting the number of records retrieved per query, thus enhancing performance and resource utilization.
2. Special Parameters
Jakarta Data also allows the use of special parameters that enhance the capabilities of repository interfaces. These parameters can be used to further refine the pagination strategy, including limits, sorting, and more intricate pagination mechanisms.
The standard return structure for pagination queries is the Page interface, which provides a simple way to handle paginated data. Jakarta Data offers a specialized version called CursoredPage for cursor-based pagination. This structure is beneficial for scenarios where traditional page-based navigation is insufficient or impractical.
Practical Example
Based on our previous conversation about Jakarta Data’s pagination features, we would like to showcase how these capabilities can be implemented in a real-world application through a practical example. The example we are presenting utilizes Jakarta Data with Eclipse JNoSQL, Quarkus, and MongoDB to demonstrate the flexibility and power of Jakarta Data, especially in terms of how it interfaces with both NoSQL and relational databases through Jakarta Persistence.
For those interested in exploring the complete code and diving deeper into its functionalities, you can find the sample project here: Quarkus Pagination with JNoSQL and MongoDB.
The FruitRepository in our example extends BasicRepository, leveraging Jakarta Data’s capabilities to interact with the database in a streamlined manner. This repository illustrates three primary methods by which Jakarta Data can fetch and manage data:
- Using the
@Findannotation: Simplifies the query process by allowing direct annotation-based querying - Using Jakarta Query Language: Enables more complex queries similar to SQL, suitable for advanced data manipulation
- Using method by query convention: Facilitates queries based on method naming conventions, making code easier to read and maintain
Within the FruitRepository, we’ve implemented two specific methods to handle pagination:
@Repository
public interface FruitRepository extends BasicRepository<Fruit, String> {
@Find
CursoredPage<Fruit> cursor(PageRequest pageRequest, Sort<Fruit> order);
@Find
@OrderBy("name")
Page<Fruit> offSet(PageRequest pageRequest);
long countBy();
}
- Cursor pagination: This utilizes a
CursoredPage<Fruit>to manage large datasets efficiently. This method is particularly useful in applications where data is continuously updated, as it provides a stable and performant way to handle sequential data retrieval. - Offset pagination: This employs a
simple Page<Fruit>to access data in a more traditional page-by-page manner. This approach is straightforward and familiar to many developers, making it ideal for applications with stable and predictable datasets.
These examples illustrate the versatility of Jakarta Data in handling different pagination strategies, offering developers robust options based on their specific application needs. This approach not only highlights the practical application of Jakarta Data but also emphasizes its adaptability across different types of databases and data management strategies.
Expanding upon our practical implementation with Jakarta Data, the FruitResource class in our Quarkus application provides REST endpoints for offset and cursor-based pagination methods. This setup effectively demonstrates the nuances between the two strategies and how they can be applied to serve data RESTful.
In the FruitResource class, we define two distinct REST endpoints tailored to the different pagination strategies.
This endpoint demonstrates offset pagination where clients can specify the page and size as query parameters. It is straightforward, allowing users to jump to a specific page directly. This method is particularly effective for datasets where the total size is known and predictable navigation between pages is required.
@Path("/offset")
@GET
@Produces(MediaType.APPLICATION_JSON)
public Iterable<Fruit> hello(@QueryParam("page") @DefaultValue("1") long page,
@QueryParam("size") @DefaultValue("2") int size) {
var pageRequest = PageRequest.ofPage(page).size(size);
return fruitRepository.offSet(pageRequest).content();
}
This endpoint caters to cursor-based pagination, which is essential for handling large or frequently updated datasets. The cursor acts as a pointer that facilitates fetching records continuously without skipping over previous data. This method ensures efficiency and consistency, particularly when dealing with real-time data streams. Clients can provide either an after or before cursor, depending on the direction of navigation they require.
Both endpoints utilize Sort<Fruit> defined as ASC or DESC to determine the order in which records are fetched. This sort order enhances the usability of the pagination by ensuring that data is presented in a logical sequence.
@Path("/cursor")
@GET
@Produces(MediaType.APPLICATION_JSON)
public Iterable<Fruit> cursor(@QueryParam("after") @DefaultValue("") String after,
@QueryParam("before") @DefaultValue("") String before,
@QueryParam("size") @DefaultValue("2") int size) {
if (!after.isBlank()) {
var pageRequest = PageRequest.ofSize(size).afterCursor(PageRequest.Cursor.forKey(after));
return fruitRepository.cursor(pageRequest, ASC).content();
} else if (!before.isBlank()) {
var pageRequest = PageRequest.ofSize(size).beforeCursor(PageRequest.Cursor.forKey(before));
return fruitRepository.cursor(pageRequest, DESC).stream().toList();
}
var pageRequest = PageRequest.ofSize(size).size(size);
return fruitRepository.cursor(pageRequest, ASC).content();
}
The FruitResource class design is an excellent example of how different pagination approaches can be customized to fit specific application requirements. By comparing these two methods in a single application, developers can gain practical insights into selecting and implementing the most suitable pagination strategy based on their data characteristics and user needs. This approach not only showcases Jakarta Data’s capabilities in a microservices architecture using Quarkus and MongoDB but also enhances understanding of RESTful service design and data management.
Conclusion
As we have worked through the complexities of applying offset and cursor-based pagination using Jakarta Data in a Quarkus and MongoDB environment, we have realized Jakarta Data's adaptability and effectiveness in managing data retrieval processes. This exploration has provided practical use cases and emphasized the strategic benefits of each pagination method, enabling developers to make informed decisions according to their application requirements.
This conversation provides a foundation for further exploration into Jakarta Data's capabilities and its integration with modern application frameworks like Quarkus. By understanding these pagination techniques, developers will be better equipped to construct scalable and efficient applications that can easily handle large datasets. In the future, choosing and implementing the most appropriate pagination strategy will be critical in optimizing application performance and enhancing user experience.
References
Opinions expressed by DZone contributors are their own.
Comments