Data Ingestion for Batch/Near Real-Time Analytics
This article provides an overview of the data ingestion process, utilizing a real-world example from the crypto industry.
Join the DZone community and get the full member experience.
Join For FreeIn the midst of our ever-expanding digital landscape, data management undergoes a metamorphic role as the custodian of the digital realm, responsible for the ingestion, storage, and comprehension of the immense volumes of information generated daily. At a broad level, data management workflows encompass the following phases, which are integral to ensuring the reliability, completeness, accuracy, and legitimacy of the insights (data) derived for business decisions.
- Data identification: Identifying the required data elements to achieve the defined objective.
- Data ingestion: Ingest the data elements into a temporary or permanent storage for analysis.
- Data cleaning and validation: Clean the data and validate the values for accuracy.
- Data transformation and exploration: Transform, explore, and analyze the data to arrive at the aggregates or infer insights.
- Visualization: Apply business intelligence over the explored data to arrive at insights that complement the defined objective.
Within these stages, Data Ingestion acts as the guardian of the data realm, ensuring accurate and efficient entry of the right data into the system. It involves collecting targeted data, simplifying structures if they are complex, adapting to changes in the data structure, and scaling out to accommodate the increasing data volume, making the data interpretable for subsequent phases. This article will specifically concentrate on large-scale Data Ingestion tailored for both batch and near real-time analytics requirements.
To delve further into the intricacies of data ingestion processes, let's consider a practical scenario: analyzing the trends of trading crypto assets at a specific moment. To address this challenge, continuous ingestion of trading crypto asset data is imperative for ongoing analytics. By incorporating this data, the business team gains the ability to promptly identify and respond to any findings, both in batch and near real-time, during the analysis phase. For illustration purposes, we will utilize the Binance API to extract trade-pair details at a one-minute candle granularity and stream them for analysis.
Overall, the given scenario demands,
- A Data retrieval layer (container) on which Binance APIs will be invoked, parsed, and produced to the delivery layer.
- A unified streaming/delivery layer, where the data can be streamed and stored for analytics.
- An analytics layer to perform batch or near real-time analytics.
![data ingestion]()
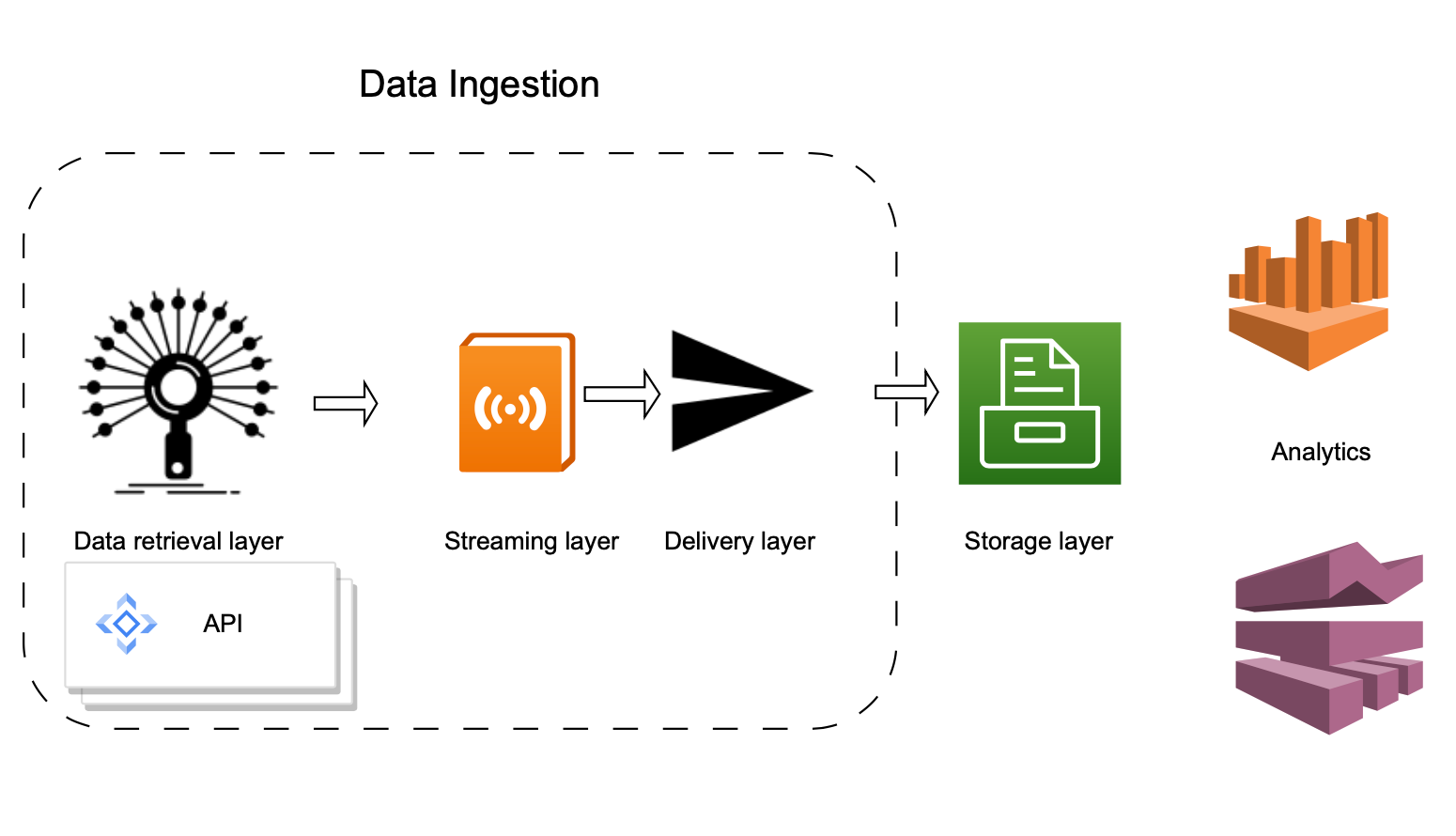
We will leverage AWS services to design an architecture/framework for this massive-scale data ingestion. These AWS components can, in turn, be glued/connected to an open-source distributed computing framework by importing and invoking corresponding libraries or other AWS services for analysis. The architecture referred to here has been implemented and tested in an AWS Account, and their screenshots are also made available.
![AWS]() Ingestion Layer (Lambda)
Ingestion Layer (Lambda)

We will use AWS Lambda as a serverless computing service. Below are some of the uses of AWS lambda functions,
- They are event-driven so that other APIs can keep interacting with them for future enhance-ability.
- AWS Lambda is an excellent candidate for both ad hoc and scheduled invocations.
- Lambda function in the architecture can be scheduled using cloud trail to run on a specific frequency, or we can have other APIS/Components call this service on demand or regular basis.
In our case, we are just invoking the function using a test event that looks as below,
{
"symbol": "BTCUSDT",
"start_time": "1610904690381",
"end_time": "1610991090381",
"interval": "1m"
}The Lambda function performs the below part,
- Execute GET Request against the intended API based on the function invocation.
- If HTTP 200 OK is received - then response data is transformed to JSON format if required and published to kinesis firehose.
- If the HTTP status code is different from 200, lambda gives a response as below,
{
"binance_api": "kline_candlestick",
"http_error_code":resp.status_code,
"response_error_message":extracted_response
}Sample Lambda Code for pulling events from API and publishing to kinesis firehose:
def lambda_handler_kline(event, context):
'''
lambda_handler code designed to invoke kline/candle_grain api
Converts the comma separated data to json format using utils function
Writes the response to Fireshose in json format
'''
try:
trade_pair, interval, start_time, end_time = event['symbol'], event['interval'], event['start_time'], event['end_time']
api_url = url_constructor(trade_pair,interval,start_time,end_time,base_url)
resp = api_caller(api_url,api_key)
extracted_response = resp.json()
if(resp.status_code==HttpErrorCodes.success.value):
if len(extracted_response) > 0:
data_extracted_response = list(map(lambda rec:{"Data":"{}\n".format(csv_to_json_converter(kline_candlestick_key_list,rec))},extracted_response))
full_lambda_response = firehose_client.put_record_batch(
DeliveryStreamName= kline_delivery_stream,
Records=data_extracted_response
)
lambda_response = full_lambda_response["ResponseMetadata"]
else:
lambda_response = { "binance_api": "kline_candlestick",
"http_error_code":resp.status_code,
"response_error_message":extracted_response
}
return lambda_responseGitHub Code
This repo has examples for a couple of Binance API invocations to get a taste of the variety of data that can be ingested and analyzed. Please refer to this link for the entire set of Binance APIs.
Streaming /Delivery and Storage Layer (Kinesis Firehose): Kinesis Firehose and S3
The candle grain events are extracted from API and produced to kinesis-firehose, where data is buffered(batched), compressed, and, if required, can also be encrypted. These data can, in turn, be transformed in Firehose into Apache Parquet or Apache ORC format and delivered to S3. Since Firehose loads new data within 60 seconds, they become one of the excellent candidates for near real-time ingestion into data lakes. Data stored in S3 can be designed to be the source for Data Lake. There can be multiple datasets like this, for example, order_history and transaction_history, to be made available in S3. Once data is ingested, then the data can be made available for analysis through Data Crawling and Data Cataloging.
Analytics Layer (Glue/Athena)
I have used Glue Crawler to crawl the ingested data lake, which generates the Glue Catalog. These crawlers can be scheduled on any frequency basis to recognize schema evolutions and update Glue Catalogs. This supports schema evolution. Glue Catalog can, in turn, be referred to by Redshift Spectrum or Amazon Athena for querying.
Batch Analytics
- A glue catalog helps with metadata inference and data querying through the redshift spectrum.
- If Redshift is not an option, load the aggregated data into a data warehouse, for example, Snowflake, using any data orchestration or scheduling tools below, and synchronize the data with certain frequency.
- Apache Airflow
- AWS data pipeline
- If we are expecting a high data volume in the order of billions, then having a Spark job (AWS Glue job) to read the data in s3 using glue catalog, run the queries, and store the aggregated result in s3 and copy it into Snowflake/Redshift.
Near Real-Time Analytics
- If a redshift cluster is made available and redshift spectrum access is enabled, querying the data through the redshift spectrum would enable fast, near-real-time analytics.
- Also, the near real-time analysis latency needs to be reduced. In that case, we can directly publish the data to kinesis streams from lambda and use kinesis analytics to query the data in near real-time with reduced latency. Store the results back in s3 through Firehose for further querying.
Scaling
We might need to adjust scaling parameters at different layers to meet the growing demands of data and frequency. Below are some critical parameters that can be used for scale-out in this design.
- Lambda concurrency: Number of requests that the lambda function handles at a given time. This concurrency parameter can be set based on the parallel crypto assets or region-specific requests. Please refer to aws_documentation for more information on concurrency.
- Kinesis firehose: Read throughput per partition; PutRecordBatch operations can be increased by requesting a quota increase. Please refer to firehose_documentation for more details.
- Kinesis stream: The number of shards can be increased based on the producer's incoming data volume or the consumer's outgoing data volume. Please refer to this link for shard calculations.
Data Quality
To guarantee the precision and entirety of the data, a system is required to consistently calculate data quality metrics (with each new dataset version), validate defined constraints, halt dataset publication in error scenarios, and alert producers for necessary actions. By executing these procedures automatically, data quality serves as the gateway to prevent the propagation of data issues into consumer data pipelines, thereby minimizing their potential impact.
Many libraries are available in different languages for DQ checks; PyDeequ is one of the widely used libraries that allows one to calculate data quality metrics on the dataset, define and verify data quality constraints, and be informed about changes in the data distribution. This can be leveraged to identify data quality issues.
Conclusion
This article provides an overview of the data ingestion process, utilizing a real-world example from the crypto industry. It demonstrates the process by accessing sample crypto trade data from the Binance API exchange through AWS services. In a practical implementation for an organization, the data ingestion process would involve handling data from various sources and APIs, utilizing multiple delivery streams for diverse datasets aimed at analysis. The article delves into the crucial aspects of scaling parameters, offering insights into tuning services to accommodate increasing data volumes. It also highlights orchestration tools that simplify and streamline the ingestion process.
In the ever-expanding data universe, innovations in ingestion processes are vital to capturing the growing wealth of data. The content of this article offers a scalable blueprint for executing the ingestion process through AWS services. I believe that this information will be beneficial in shaping the development of data ingestion processes tailored to your specific requirements, emphasizing robustness, resilience, and scalability.
Opinions expressed by DZone contributors are their own.
Comments