Using Machine Learning to Retrieve Relevant CVs Based on Job Description
If you've ever tried to hire anyone, you know how difficult it can be to pour through hundreds of resumes and find the right one. AI can take the pain out of the process!
Join the DZone community and get the full member experience.
Join For FreeWe use the average word embeddings (AWE) model for retrieving relevant CVs based on a job description. We present a step-by-step guide in order to combine domain-trained word embeddings with pre-trained embeddings for Spanish documents (CVs). We also use Principal Component Analysis (PCA) as a reduction technique used to put similar dimensions to word embeddings results.
Architecture Description
Information retrieval (IR) models are composed of an indexed corpus and a scoring or ranking function. The main goal of an IR system is to retrieve relevant documents or web pages based on a user request. During the retrieval, the scoring function is used to sort the retrieved documents according to their relevance to the user query. The classic IR models such as BM25 and language models are based on the bag-of-words (BOW) indexing scheme. BOW models have two major weaknesses: they lose the context where a word appears and they also ignore its semantics. Latent semantic indexing (LSI) is a technique used to handle this problem but when the number of documents increases, the process of indexing becomes computationally expensive. The standard technique used to overcome this is to train word or paragraph embeddings over a corpus or use pre-trained embeddings.
Word embeddings (WE) are distributed representations of terms obtained from a neural network model. These continuous representations have been used recently in different natural language processing tasks. The average word embeddings (AWE) is a popular technique to represent long sequences of text, not just a term.
In our case, a set of CVs is available, but job descriptions are priorly unknown and we need to provide a solution based on an unsupervised learning approach. Thus, word embeddings seem to be a good starting point for our experiments.
Architecture is defined in the next figure.
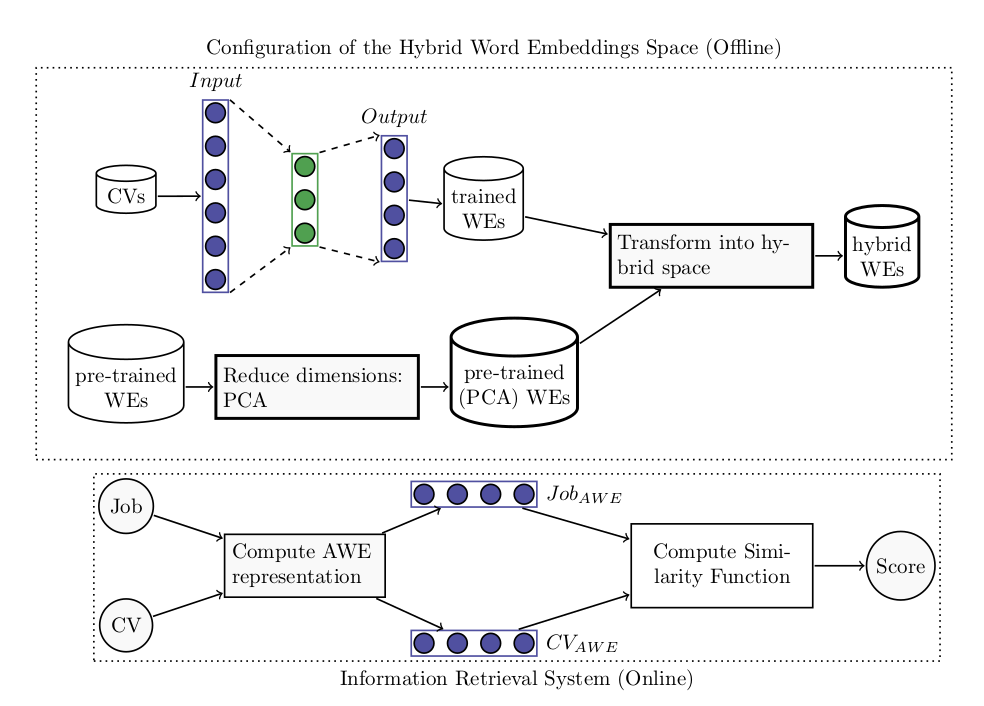
Step 1: Train Domain Word Embeddings (Trained WEs)
As a first step, we build a balanced corpus of CVs from four known job profiles: Java, Tester, SAP HCM, and SAP SD. As CVs are written in several formats and with different styles and vocabulary, we decide to use only nouns and verbs in order to obtain just the important and relevant information from the CV. Once the corpus is built, we pass it through Word2vec with the configuration parameters as follows: window size is 5, minimum word count is 3, and dimensions are 200. CBOW is the default Word2vec model used.
We use Python 3.6.1 with Anaconda 64 bit for Linux Ubuntu 16.04 LTS. To install several libraries, the pip install command must be run as follows:
pip install gensim
pip install pattern3
pip install textract
pip install numpy
pip install scipy
pip install sklearn
pip install pickleAfter all needed packages are installed, we create a function to retrieve all CVs from a specific folder, read them (using textract), lemmatize them (using pattern3), and finally create the word embeddings (using gensim). The python function responsible for extracting the text from CVs (PDF, TXT, DOC, DOCX) is defined as follows:
from gensim.models import Word2Vec, KeyedVectors
from pattern3 import es
import textract
from os import listdir
from os.path import isfile, join
import numpy as np
from scipy import spatial
from sklearn import decomposition
import matplotlib.pyplot as plt
import pickle
def read_All_CV(filename):
text = textract.process(filename)
return text.decode('utf-8')
#Next, we define a function to parse the documents (CVs) and save the word embeddings as follows:
def preprocess_training_data1(dir_cvs, dir_model_name):
dircvs = [join(dir_cvs, f) for f in listdir(dir_cvs) if isfile(join(dir_cvs, f))]
alltext = ' '
for cv in dircvs:
yd = read_All_CV(cv)
alltext += yd + " "
alltext = alltext.lower()
vector = []
for sentence in es.parsetree(alltext, tokenize=True, lemmata=True, tags=True):
temp = []
for chunk in sentence.chunks:
for word in chunk.words:
if word.tag == 'NN' or word.tag == 'VB':
temp.append(word.lemma)
vector.append(temp)
global model
model = Word2Vec(vector, size=200, window=5, min_count=3, workers=4)
model.save(dir_model_name) Once all the embeddings are saved into dir_model_name and we have set the word embeddings to the global variable model, we can use PCA technique to reduce dimensions of the pretrained word embeddings.
Step 2: Download and Reduce Pretrained Word Embeddings (Pretrained PCA WEs)
After we download the Spanish pre-trained word embeddings, we observe that these vectors have 300 dimensions and our proposed domain trained embeddings have 200 dimensions. We decide to reduce 300-dimensional vectors into 200 dimensions and then we build our hybrid space with both word embeddings spaces. The following function is responsible for reducing dimensions of the pre-trained word embeddings:
def reduce_dimensions_WE(dir_we_SWE, dir_pca_we_SWE):
m1 = KeyedVectors.load_word2vec_format(dir_we_SWE ,binary=True)
model1 = {}
# normalize vectors
for string in m1.wv.vocab:
model1[string]=m1.wv[string] / np.linalg.norm(m1.wv[string])
# reduce dimensionality
pca = decomposition.PCA(n_components=200)
pca.fit(np.array(list(model1.values())))
model1=pca.transform(np.array(list(model1.values())))
i = 0
for key, value in model1.items():
model1[key] = model1[i] / np.linalg.norm(model1[i])
i = i + 1
with open(dir_pca_we_SWE, 'wb') as handle:
pickle.dump(model1, handle, protocol=pickle.HIGHEST_PROTOCOL)
return model1Once the reduced vectors are obtained, we can perform the retrieval task using hybrid word embeddings and AWE to compute the mean vector of the document (CV) and query (job Description).
Step 3: Build the Hybrid Word Embeddings Space and Retrieve Relevant Documents (CVs)
We show a service developed in the lab where we essentially load both embeddings spaces and finally select, when a request comes, the embedding space that must be used. For instance, if the user puts the title of the job "Java," we will load the trained embedding space. When another unknown profile is typed, i.e. "Cobol Analyst," then pre-trained word embeddings are used. Besides, for each CV and job request, a mean word embedding vector is computed. Finally, we just retrieve the top three CVs that match with the job description requirement. The following Python function is responsible for this processing block:
model1 = Word2Vec.load(join(APP_STATIC, "word2vec/ourModel"))
with open(join(APP_STATIC, 'word2vec/reduced_pca.pickle'), 'rb') as f:
model2 = pickle.load(f)
@app.route('/find/', methods=['GET'])
def find():
data = request.args.get('value')
w2v = []
aux = data.lower().split(" ")[0:5]
sel = len(set(['java','sap','tester','prueba','hcm','sd','pruebas','testing']).intersection(aux))
val = False
if sel > 0:
model = model1
val = True
else:
model = model2
if val:
data = data.lower()
for sentence in es.parsetree(data, tokenize=True, lemmata=True, tags=True):
for chunk in sentence.chunks:
for word in chunk.words:
if val:
if word.lemma in model.wv.vocab:
w2v.append(model.wv[word.lemma])
else:
if word.lemma.lower() in model.wv.vocab:
w2v.append(model.wv[word.lemma.lower()])
else:
if word.string in model.keys():
w2v.append(model[word.string])
else:
if word.string.lower() in model.keys():
w2v.append(model[word.string.lower()])
Q_w2v = np.mean(w2v, axis=0)
# Example of document represented by average of each document term vectors.
dircvs = APP_STATIC + "/cvs_dir"
dircvsd = [join(dircvs, f) for f in listdir(dircvs) if isfile(join(dircvs, f))]
D_w2v = []
for cv in dircvsd:
yd = textract.process(cv).decode('utf-8')
w2v = []
for sentence in es.parsetree(yd.lower(), tokenize=True, lemmata=True, tags=True):
for chunk in sentence.chunks:
for word in chunk.words:
if val:
if word.lemma in model.wv.vocab:
w2v.append(model.wv[word.lemma])
else:
if word.lemma.lower() in model.wv.vocab:
w2v.append(model.wv[word.lemma.lower()])
else:
if word.string in model.keys():
w2v.append(model[word.string])
else:
if word.string.lower() in model.keys():
w2v.append(model[word.string.lower()])
D_w2v.append((np.mean(w2v, axis=0),cv))
# Make the retrieval using cosine similarity between query and document vectors.
retrieval = []
for i in range(len(D_w2v)):
retrieval.append((1 - spatial.distance.cosine(Q_w2v, D_w2v[i][0]),D_w2v[i][1]))
retrieval.sort(reverse=True)
ret_data = {"cv1":url_for('static', filename="test/"+retrieval[0][1][retrieval[0][1].rfind('/')+1:]), "score1": str(round(retrieval[0][0], 4)), "cv2":url_for('static', filename="test/"+retrieval[1][1][retrieval[1][1].rfind('/')+1:]), "score2": str(round(retrieval[1][0], 4)),"cv3":url_for('static', filename="test/"+retrieval[2][1][retrieval[2][1].rfind('/')+1:]), "score3": str(round(retrieval[2][0], 4)) }
return jsonify(ret_data)And that's it!
Opinions expressed by DZone contributors are their own.
Comments