Custom Partitioner in Kafka: Let’s Take a Quick Tour!
Join the DZone community and get the full member experience.
Join For Free
In this blog, we are going to explore the Kafka partitioner. We will try to understand why the default partitioner is not enough and when you might need a custom partitioner. We will also look at a use case and create code for the custom partitioner. I assumed that you have sound knowledge of Kafka. Let’s understand the behavior of the default partitioner.
The default partitioner follows these rules:
- If a producer provides a partition number in the message record, use it.
- If a producer doesn’t provide a partition number, but it provides a key, choose a partition based on a hash value of the key.
- When no partition number or key is present, pick a partition in a round-robin fashion.
So, you can use the default partitioner in three scenarios:
- If you already know the partition number in which you want to send a message record, then use the first rule.
- When you want to distribute data based on the hash key, you will use the second rule of the default partitioner.
- If you don’t care about in which partition message record will be stored, then you will use the third rule of default partitioner.
You may also like: Kafka Producer and Consumer Examples Using Java.
There are two problems with the key:
- If the producer provides the same key for each message record, hashing will give you the same hash number, but it doesn’t ensure that if you provide two different keys, then it will never give you the same hash number.
- The default partitioner uses the hash value of the key and the total number of partitions on a topic to determine the partition number. If you increase a partition number, then the default partitioner will return different numbers evenly if you provide the same key.
Now, you might have questions as to how to solve this problem?
The answer to this question is very simple: you can implement your own algorithm based on your requirements and use it in the custom partitioner.
Kafka Custom Partitioner Example
Let’s create an example use-case and implement a custom partitioner. Try to understand the problem statement with the help of a diagram.
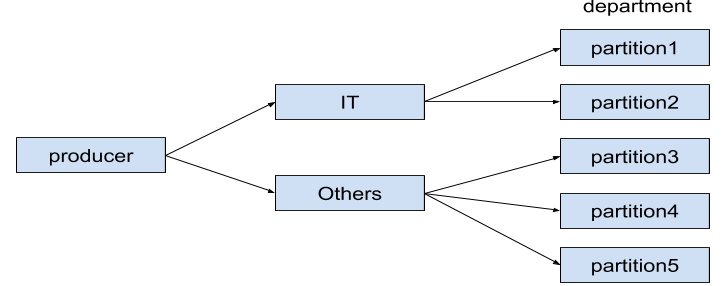
Assume we are collecting data from different departments. All the departments are sending data to a single topic named department. I planned five partitions for the topic. But, I want two partitions dedicated to a specific department named IT and the remaining three partitions for the rest of the departments. How would you achieve this?
You can solve this requirement, and any other type of partitioning needs by implementing a custom partitioner.
Kafka Producer
Let’s look at the producer code.
package com.knoldus
import java.util.Properties
import org.apache.kafka.clients.producer._
object KafkaProducer extends App {
val props = new Properties()
val topicName = "department"
props.put("bootstrap.servers", "localhost:9092,localhost:9093")
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer")
props.put("partitioner.class", "com.knoldus.CustomPartitioner")
val producer = new KafkaProducer[String, String](props)
try {
for (i <- 0 to 5) {
val record = new ProducerRecord[String, String](topicName,"IT" + i,"My Site is knoldus.com " + i)
producer.send(record)
}
for (i <- 0 to 5) {
val record = new ProducerRecord[String, String](topicName,"COMP" + i,"My Site is knoldus.com " + i)
producer.send(record)
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
producer.close()
}
}
The first step in writing messages to Kafka is to create a producer object with the properties you want to pass to the producer. A Kafka producer has three mandatory properties, as you can see in the above code:
- bootstrap.servers: Port pairs of the Kafka broker that the producer will use to establish a connection to the Kafka cluster. It is recommended that you should include at least two Kafka brokers because if one Kafka broker goes down, the producer will still be able to connect Kafka cluster.
- Key.serializer: Name of the class that will be used to serialize a key.
- value.serializer: Name of the class that will be used to serialize a value.
If you look at the rest of the code, there are only three steps:
- Create a
KafkaProducerobject. - Create a
ProducerRecordobject. - Send the record to the broker.
That is all that we do in a Kafka Producer.
Kafka Custom Partitioner
We need to create our class by implementing the Partitioner Interface. Your custom partitioner class must implement three methods from the interface.
Configure.Partition.Close.
Let’s look at the code.
xxxxxxxxxx
package com.knoldus
import java.util
import org.apache.kafka.common.record.InvalidRecordException
import org.apache.kafka.common.utils.Utils
import org.apache.kafka.clients.producer.Partitioner
import org.apache.kafka.common.Cluster
class CustomPartitioner extends Partitioner {
val departmentName = "IT"
override def configure(configs: util.Map[String, _]): Unit = {}
override def partition(topic: String,key: Any, keyBytes: Array[Byte], value: Any,valueBytes: Array[Byte],cluster: Cluster): Int = {
val partitions = cluster.partitionsForTopic(topic)
val numPartitions = partitions.size
val it = Math.abs(numPartitions * 0.4).asInstanceOf[Int]
if ((keyBytes == null) || (!key.isInstanceOf[String]))
throw new InvalidRecordException("All messages must have department name as key")
if (key.asInstanceOf[String].startsWith(departmentName)) {
val p = Utils.toPositive(Utils.murmur2(keyBytes)) % it
p
} else {
val p = Utils.toPositive(Utils.murmur2(keyBytes)) % (numPartitions - it) + it
p
}
}
override def close(): Unit = {}
}
configure and close are used for initialization and clean up. In our example, we don’t have anything to clean up and initialize.
The partition method is the place where all the action happens. The producer will call this method for each message record.input to this method is key, topic, cluster details. we need to do is to return an integer as a partition number. This is the place where we have to write our own algorithm.
Algorithm
Let’s try to understand the algorithm that I have implemented. I am applying my own algorithm in four simple steps.
- The first step is to determine the number of partitions and reserve 40% of them for the IT department. If I have five partitions for the topic, this logic will reserve two partitions for IT. The next question is, how do we get the number of partitions in the topic?
We have a cluster object as an input, and the methodpartitionsForTopicwill give us a list of all the partitions. Then, we take the size of the list. That’s the number of partitions in the Topic. Then, we set IT as 40% of the number of partitions. So, if I have five partitions, IT should be set to 2. - If we don’t get a message Key, we throw an exception. We need the Key because the Key tells us the department name. Without knowing the department name, we can’t decide that the message should go to one of the two reserved partitions or it should go to the other three partitions.
- The next step is to determine the partition number. If the Key = IT, then we hash the message value, divide it by 2, and take the mod as partition number. Using mod will make sure that we always get 0, or 1.
- If the Key != IT then we divide it by 3 and again take the mod. The mod will be somewhere between 0 and 2. So, I am adding 2 to shift it by 2
Kafka Consumer
Let’s look at the consumer code.
xxxxxxxxxx
package com.knoldus
import java.util
import java.util.Properties
import scala.jdk.CollectionConverters._
import org.apache.kafka.clients.consumer.KafkaConsumer
object KafkaConsumer extends App {
val props: Properties = new Properties()
val topicName = "department"
props.put("group.id", "test")
props.put("bootstrap.servers", "localhost:9092,localhost:9093")
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
val consumer = new KafkaConsumer(props)
try {
consumer.subscribe(util.Arrays.asList(topicName))
while (true) {
val records = consumer.poll(10)
for (record <- records.asScala) {
println("Topic: " + record.topic() + ", Offset: " + record.offset() +", Partition: " + record.partition())
}
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
consumer.close()
}
}
A Kafka consumer has three mandatory properties as you can see in the above code:
- bootstrap.servers: port pairs of Kafka broker that the consumer will use to establish a connection to the Kafka cluster.it is recommended that you should include at least two Kafka brokers because if one Kafka broker goes down then the consumer will still be able to connect Kafka cluster.
- key.deserializer: Name of the class that will be used to deserialize key.
- value.deserializer: Name of the class that will be used to deserialize a value.
If you look at the rest of the code, there are only two steps.
- Step 1 – Subscribe to the topic.
- Step 2 – Consume messages from the topic.
That is all that we do in a Kafka Consumer.
I hope you enjoy this blog and you are able to create custom partitioner in Kafka using scala. if you want source code please feel free to download source code.
Thanks for reading!
References:
1.https://kafka.apache.org/documentation/.
2.https://docs.confluent.io/..
Further Reading
Opinions expressed by DZone contributors are their own.
Comments