Couchbase: Improving Performance When Querying Multiple Arrays With FTS and N1QL
In this article, see how to improve performance when querying multiple arrays with FTS and N1QL.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Couchbase Full Text Search (FTS) is a great fit for indexing multiple arrays and executing queries with multiple filter predicates in arrays. In this article, I’ll demonstrate the advantages of using FTS over GSI (Global Secondary Index) for array indexing while working through an example use case that requires querying multiple arrays. We’ll be creating an FTS multi-array index and querying the index with N1QL using the new SEARCH() function introduced in Couchbase Server 6.5.
Travel Sample Bucket
In this article, we’ll be referencing the Travel Sample dataset available to install in any Couchbase Server instance. The travel-sample bucket has several distinct document types: airline, route, airport, landmark, and hotel. The document model for each kind of document contains:
A key that acts as a primary key
An id field that identifies the document
A type field that identifies the kind of document
The examples in this article will be using the hotel documents. The sample document below gives you an idea of the structure of a hotel document:

Figure 1 - Sample Hotel Document
The Problem
Our example is a use case where a user can search for hotels that have been reviewed or liked by a person with a particular name. This requires querying hotel documents on both public likes and reviews, which are arrays within the hotel document model:

Figure 2 - The “public_likes” and “reviews” arrays in the sample hotel document
First let’s look at implementing this use case with N1QL and GSI (Global Secondary Index). To find hotels that anyone named Ozella has either liked or reviewed, the query could look like this:
xxxxxxxxxx
SELECT name, address, city, country,
phone, public_likes, reviews
FROM `travel-sample`
WHERE type="hotel"
AND (ANY l IN public_likes SATISFIES l LIKE "%Ozella%" END
OR ANY r IN reviews SATISFIES r.author LIKE "%Ozella%" END);
We need to create an appropriate index for this query. Maybe something like this that indexes both arrays of interest for hotel documents:
xxxxxxxxxx
CREATE INDEX idx_hotel_public_likes_review_author ON `travel-sample`
(DISTINCT ARRAY `l` FOR l IN `public_likes` END,
DISTINCT ARRAY `r`.`author` FOR r IN `reviews` END)
WHERE `type` = 'hotel';
This doesn’t work, and we get the error shown in Figure 3:
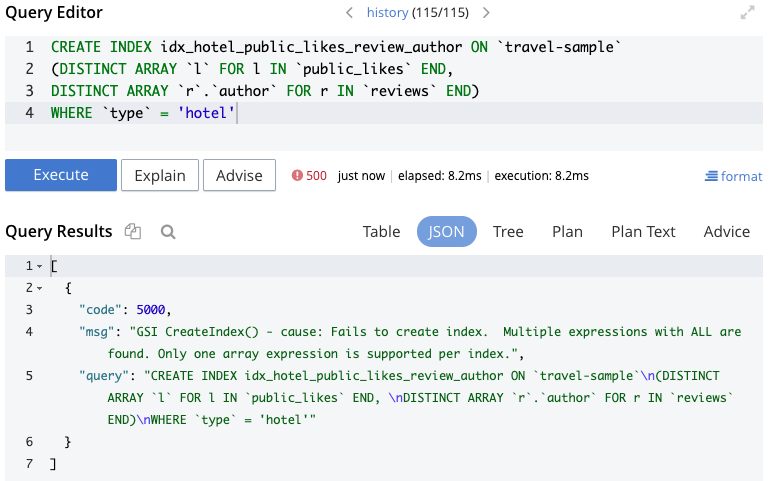
Figure 3 - Error creating index with multiple arrays
As Keshav Murthy wrote in his blog post Search and Rescue: 7 Reasons for N1QL (SQL) developers to use Search (problem #6), with N1QL in Couchbase, “to get the best performance while searching inside arrays, you need to create indexes with array keys. The array index comes with a limitation: each array index can only have one array key per index. So, when you have a customer object with multiple array fields, you can’t search all of them using a single index...causing expensive queries.” As Keshav notes in that article, this is a limitation with b-tree indexes in databases generally.
So now let’s try two separate array indexes. The indexes to support this query could look like these, which were created using the Couchbase N1QL Index Advisor, a new (DP) feature in Couchbase 6.5:
xxxxxxxxxx
CREATE INDEX adv_DISTINCT_public_likes_type ON `travel-sample`(DISTINCT ARRAY `l` FOR l in `public_likes` END) WHERE `type` = 'hotel';
CREATE INDEX adv_DISTINCT_reviews_author_type ON `travel-sample`(DISTINCT ARRAY `r`.`author` FOR r in `reviews` END) WHERE `type` = 'hotel';
With those 2 indexes in place, our query runs successfully with 5 results (hotel_26020, hotel_10025, hotel_5081, hotel_20425, hotel_25327) and the following execution plan:

Figure 4 - Execution plan using multiple indexes (GSI)
Same plan in JSON:
xxxxxxxxxx
{
"#operator": "Sequence",
"#stats": {
"#phaseSwitches": 1,
"execTime": "1.321µs"
},
"~children": [
{
"#operator": "Authorize",
"#stats": {
"#phaseSwitches": 3,
"execTime": "3.034µs",
"servTime": "1.037859ms"
},
"privileges": {
"List": [
{
"Target": "default:travel-sample",
"Priv": 7
}
]
},
"~child": {
"#operator": "Sequence",
"#stats": {
"#phaseSwitches": 1,
"execTime": "2.235µs"
},
"~children": [
{
"#operator": "UnionScan",
"#stats": {
"#itemsIn": 1646,
"#itemsOut": 904,
"#phaseSwitches": 5107,
"execTime": "1.32474ms",
"kernTime": "113.495553ms"
},
"scans": [
{
"#operator": "DistinctScan",
"#stats": {
"#itemsIn": 4004,
"#itemsOut": 813,
"#phaseSwitches": 9641,
"execTime": "1.381997ms",
"kernTime": "69.065425ms"
},
"scan": {
"#operator": "IndexScan3",
"#stats": {
"#itemsOut": 4004,
"#phaseSwitches": 16021,
"execTime": "19.678094ms",
"kernTime": "30.973177ms",
"servTime": "17.461885ms"
},
"index": "adv_DISTINCT_public_likes_type",
"index_id": "288083a758973630",
"index_projection": {
"primary_key": true
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"range": [
{
"high": "[]",
"inclusion": 1,
"low": "\"\""
}
]
}
],
"using": "gsi",
"#time_normal": "00:00.037",
"#time_absolute": 0.037139979000000004
},
"#time_normal": "00:00.001",
"#time_absolute": 0.0013819969999999998
},
{
"#operator": "DistinctScan",
"#stats": {
"#itemsIn": 4104,
"#itemsOut": 833,
"#phaseSwitches": 9881,
"execTime": "2.475034ms",
"kernTime": "80.914158ms"
},
"scan": {
"#operator": "IndexScan3",
"#stats": {
"#itemsOut": 4104,
"#phaseSwitches": 16421,
"execTime": "8.610445ms",
"kernTime": "52.02497ms",
"servTime": "22.586149ms"
},
"index": "adv_DISTINCT_reviews_author_type",
"index_id": "cca7f912cab1a4c6",
"index_projection": {
"primary_key": true
},
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"range": [
{
"high": "[]",
"inclusion": 1,
"low": "\"\""
}
]
}
],
"using": "gsi",
"#time_normal": "00:00.031",
"#time_absolute": 0.031196594
},
"#time_normal": "00:00.002",
"#time_absolute": 0.002475034
}
],
"#time_normal": "00:00.001",
"#time_absolute": 0.00132474
},
{
"#operator": "Fetch",
"#stats": {
"#itemsIn": 904,
"#itemsOut": 904,
"#phaseSwitches": 3733,
"execTime": "2.887995ms",
"kernTime": "8.826606ms",
"servTime": "170.010321ms"
},
"keyspace": "travel-sample",
"namespace": "default",
"#time_normal": "00:00.172",
"#time_absolute": 0.172898316
},
{
"#operator": "Parallel",
"#stats": {
"#phaseSwitches": 1,
"execTime": "6.134µs"
},
"copies": 2,
"~child": {
"#operator": "Sequence",
"#stats": {
"#phaseSwitches": 2,
"execTime": "3.621µs"
},
"~children": [
{
"#operator": "Filter",
"#stats": {
"#itemsIn": 904,
"#itemsOut": 5,
"#phaseSwitches": 1824,
"execTime": "279.461548ms",
"kernTime": "85.245883ms"
},
"condition": "(((`travel-sample`.`type`) = \"hotel\") and (any `l` in (`travel-sample`.`public_likes`) satisfies (`l` like \"%Ozella%\") end or any `r` in (`travel-sample`.`reviews`) satisfies ((`r`.`author`) like \"%Ozella%\") end))",
"#time_normal": "00:00.279",
"#time_absolute": 0.279461548
},
{
"#operator": "InitialProject",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 25,
"execTime": "7.156613ms",
"kernTime": "357.453351ms"
},
"result_terms": [
{
"expr": "(`travel-sample`.`name`)"
},
{
"expr": "(`travel-sample`.`address`)"
},
{
"expr": "(`travel-sample`.`city`)"
},
{
"expr": "(`travel-sample`.`country`)"
},
{
"expr": "(`travel-sample`.`phone`)"
},
{
"expr": "(`travel-sample`.`public_likes`)"
},
{
"expr": "(`travel-sample`.`reviews`)"
}
],
"#time_normal": "00:00.007",
"#time_absolute": 0.007156613
},
{
"#operator": "FinalProject",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 17,
"execTime": "12.167µs",
"kernTime": "98.849µs"
},
"#time_normal": "00:00.000",
"#time_absolute": 0.000012167
}
],
"#time_normal": "00:00.000",
"#time_absolute": 0.000003621
},
"#time_normal": "00:00.000",
"#time_absolute": 0.000006134
}
],
"#time_normal": "00:00.000",
"#time_absolute": 0.0000022349999999999998
},
"#time_normal": "00:00.001",
"#time_absolute": 0.0010408930000000002
},
{
"#operator": "Stream",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 13,
"execTime": "939.145µs",
"kernTime": "182.523171ms"
},
"#time_normal": "00:00.000",
"#time_absolute": 0.000939145
}
],
"~versions": [
"2.0.0-N1QL",
"6.5.0-4960-enterprise"
],
"#time_normal": "00:00.000",
"#time_absolute": 0.000001321
}
In the single-node cluster being used for these examples, the query elapsed time is around 190-200 milliseconds to return the 5 resulting documents. As you can see in the plan, there are two IndexScan3 operators which use each of the two array indexes we created, followed by a DistinctScan for the results of each index scan, and then a UnionScan. The UnionScan shows an #itemsIn value of 1646 documents and an #itemsOut value of 904 documents, the Fetch operator also gets 904 documents, and finally, with the Filter operator we get an #ItemsOut value of 5. The fetch of 904 documents is a waste considering that we ended up with 5 documents returned by the query, and in fact, about 170 milliseconds of the overall elapsed time is spent fetching the 905 documents when only 5 are needed.
The Solution
By contrast, an FTS inverted index can easily be created for multiple arrays and is well-suited for cases where you need to search for fields in multiple arrays. We’ll create a FTS index on hotel documents for both the public_likes array and the author field within the reviews array.
Index creation steps:
On the Full Text Search UI, click “Add Index”.
Specify an index name, e.g. “hotel_mult_arrays”, and select the travel-sample bucket.
Since each document in the travel-sample bucket has a “type” field indicating the type of document, leave “JSON type field” set to “type”.
Under type mappings:
Click “+ Add Type Mapping”, and specify “hotel” as the type name, since the requirement is to search all hotel documents.
A list of available analyzers can be accessed by means of the pull-down menu to the right of the type name field. For this use case, leave “inherit” selected so that the type mapping inherits the default analyzer from the index.
Since the requirement is to search the hotel public likes and review author fields, check “only index specified fields”. With this checked, only user-specified fields from the document are included in the index for the hotel type mapping (the mapping will not be dynamic, meaning that all fields are considered available for indexing).
Click OK.
Mouse over the row with the hotel type mapping, click the + button, and then click “insert child field”. This will allow the public_likes array to be individually included in the index. Specify the following:
field: Enter the name of the field to be indexed, “public_likes”.
type: Leave this set to text for the public_likes array.
searchable as: Leave this the same as the field name for the current use case. It can be used to indicate an alternate field name.
analyzer: As was done for the type mapping, for this use case, leave “inherit” selected so that the type mapping inherits the default analyzer.
index checkbox: Leave this checked, so that the field is included in the index. Unchecking the box would explicitly remove the field from the index.
store checkbox: Check this setting to include the field content in the search results which permits highlighting of matched expressions in the results. This is useful for testing the index, but not recommended in Prod if highlighting isn’t required since it increases index size.
“include in _all field” checkbox: Leave this checked since the use case requirement is to search multiple fields.
“include term vectors” checkbox: Leave this checked, too, during development and testing of our index to allow highlighting of results.
docvalues checkbox: Uncheck this setting. This setting stores the field values in the index which provides support for Search Facets, and for the sorting of search results based on field values, neither of which we need in this use case.
Click OK.
Mouse over the row with the hotel type mapping, click the + button, and then click “insert child mapping”. This will allow the array of review sub-documents to be included in the index. Enter the property name “reviews”, leave “inherit” selected in the analyzer drop-down, check “only index specified fields”, and click OK.
Mouse over the row with the reviews child mapping, click the + button, and then click “insert child field”. This will allow the author field from the array of review sub-documents to be included in the index. Specify the following:
field: Enter the name of the field to be indexed, “author”.
type: Leave this set to text for the author field.
searchable as: Leave this the same as the field name for the current use case. It can be used to indicate an alternate field name.
analyzer: As was done for the type mapping, for this use case, leave “inherit” selected so that the type mapping inherits the default analyzer.
index checkbox: Leave this checked, so that the field is included in the index. Unchecking the box would explicitly remove the field from the index.
store checkbox: Check this setting to include the field content in the search results which permits highlighting of matched expressions in the results. This is useful for testing the index, but not recommended in Prod if highlighting isn’t required since it increases index size.
“include in _all field” checkbox: Leave this checked since the use case requirement is to search multiple fields.
“include term vectors” checkbox: Leave this checked, too, during development and testing of our index to allow highlighting of results.
docvalues checkbox: Uncheck this setting. This setting stores the field values in the index which provides support for Search Facets, and for the sorting of search results based on field values, neither of which we need in this use case.
Click OK.
Finally, uncheck the checkbox next to the “default” type mapping. If the default mapping is left enabled, all documents in the bucket are included in the index, regardless of whether the user actively specifies type mappings. Only the hotel documents are required, and they are included by the hotel type mapping added previously.
The default values suffice for the remaining collapsed panels (Analyzers, Custom Filters, Date/Time Parsers, and Advanced).
Index Replicas can be set to 1, 2 or 3, provided that the cluster is running the Search service on n+1 nodes. With a single node development environment, maintain the default value of 0.
For Index Type, the default value of “Version 6.0 (Scorch)” is appropriate for any newly created indexes. Scorch reduces the size of the index on disk, and provides enhanced performance for indexing and mutation-handling.
Index Partitions can be left to the default value of 6.
At this point, the create index page should look like the last frame captured in Figure 5. Click “Create Index” to complete the process.
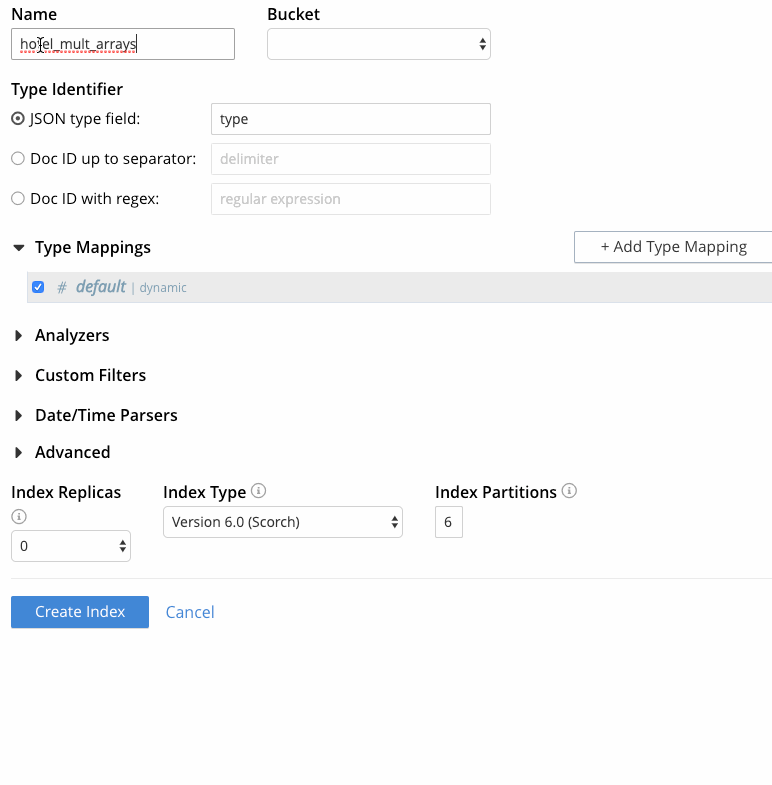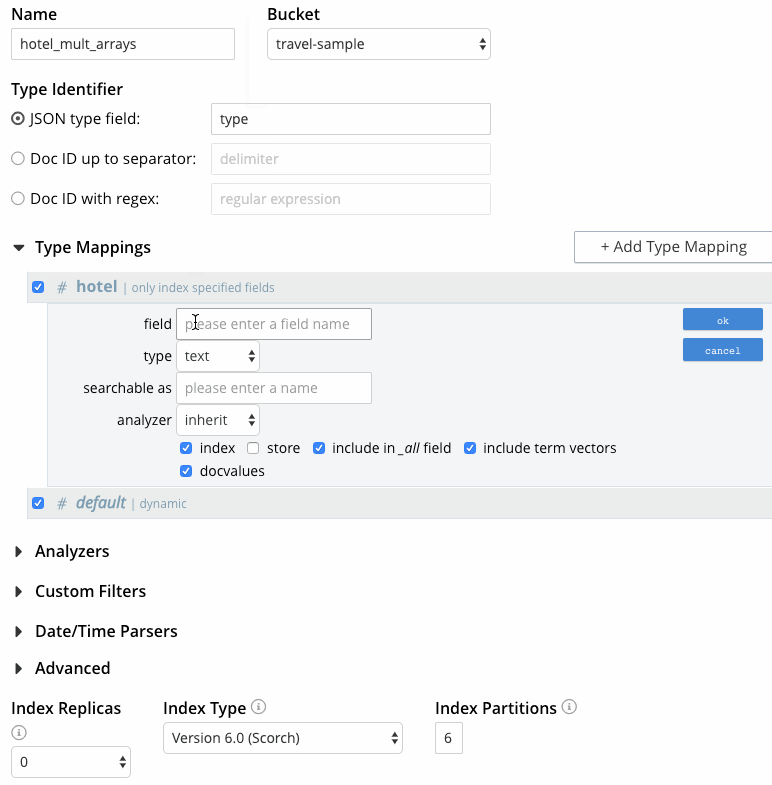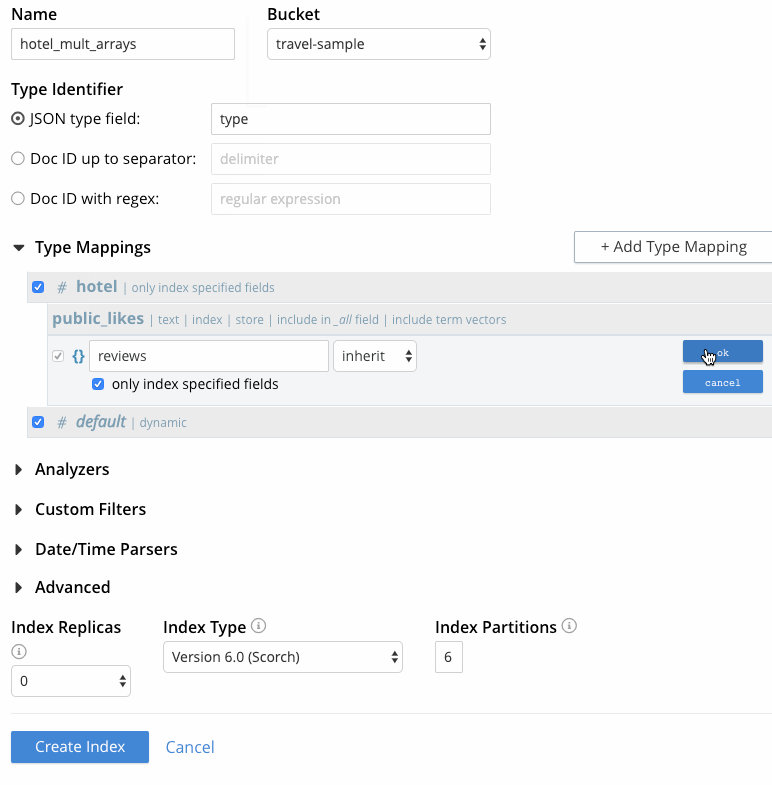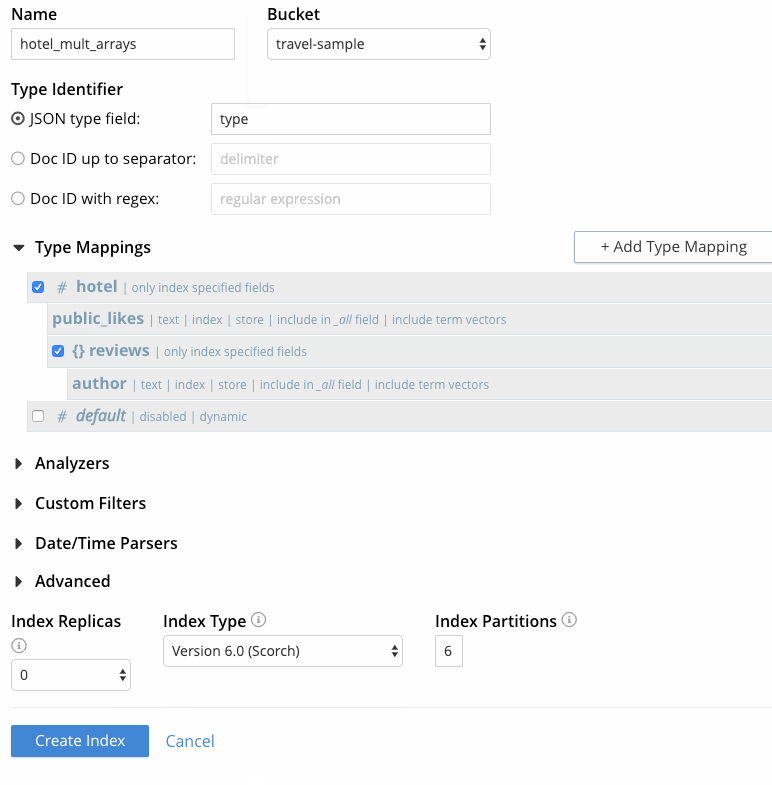
Figure 5 - Creating FTS index with multiple arrays
Note: See Appendix for the JSON payload used to create this index through the REST API.
Testing queries against the index:
On the Full Text Search UI, wait for indexing progress to show 100%, then click on the index name “hotel_mult_arrays”.
To search for any hotels with likes or reviews by someone named “Ozella”, in the “search this index…” text box, enter “Ozella” and click Search. Field-scoping of the search is not required because both indexed fields are included in the default field “_all”.
The results are shown (similar to Figure 6) with the key of each matching document and highlighted matching fields. The document IDs returned are the same as those from our earlier N1QL query.
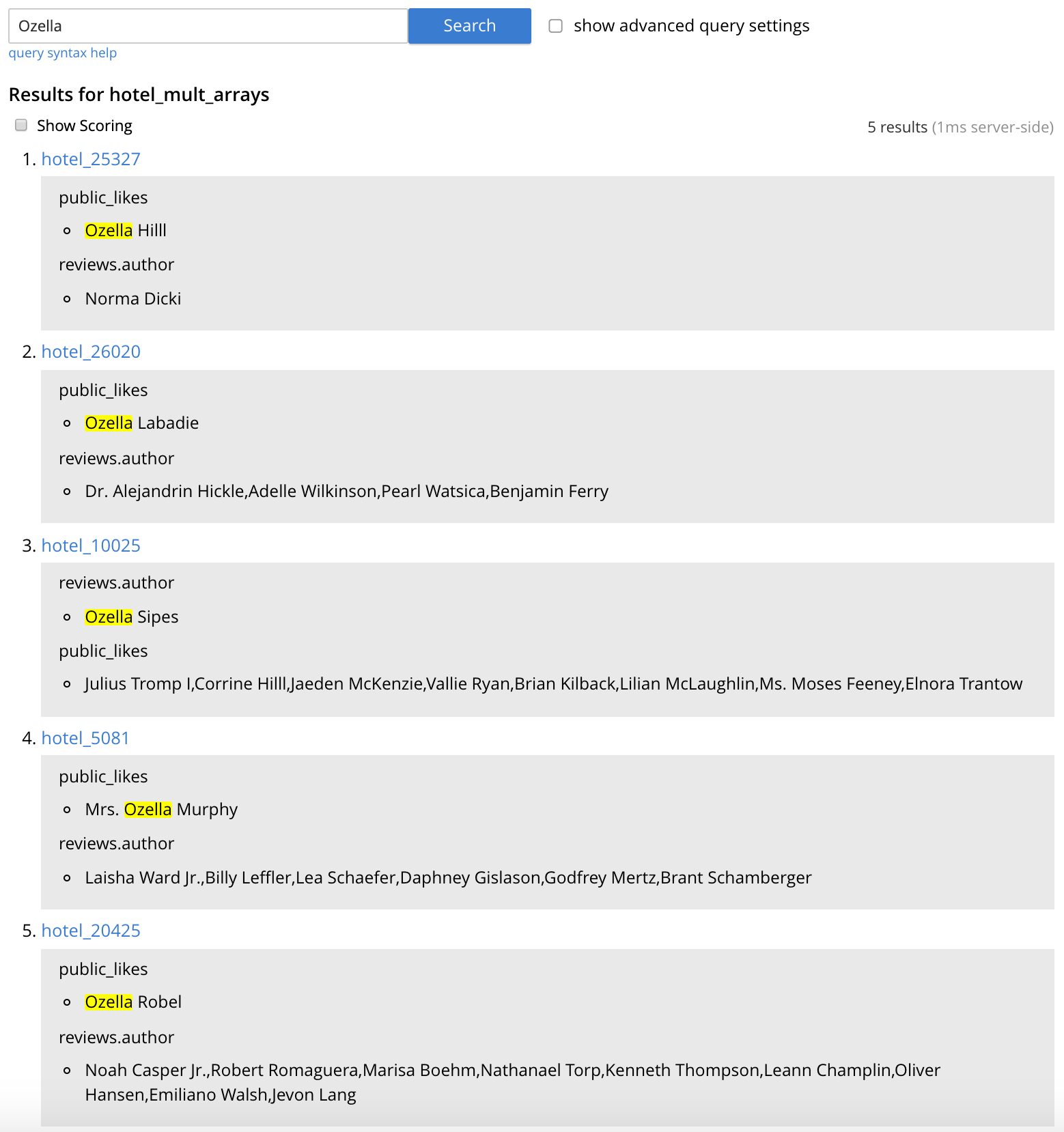
Figure 6 - Index “hotel_mult_arrays” search results for “Ozella”
This is a single index on 2 array keys, which, as mentioned earlier, is something you could never do in a b-tree based index. So now let’s take advantage of this FTS index in a N1QL query by using the SEARCH() function. Our query could look like this:
xxxxxxxxxx
SELECT name, address, city, country,
phone, public_likes, reviews
FROM `travel-sample` AS t USE INDEX(hotel_mult_arrays USING FTS)
WHERE t.type="hotel"
AND SEARCH(t, {"query": {"match":"Ozella"}}, {"index":"hotel_mult_arrays"});
A few things to note about the query:
The USE INDEX...USING FTS clause specifies that the FTS index should be used rather than a GSI index, so this query doesn’t use the index service. (Documentation)
Because our FTS index uses a custom type mapping, the query needs to have the matching type specified in the WHERE clause (t.type="hotel").
The FTS index name is specified in the “index” field in the SEARCH() function as a hint, but that is optional since the USE INDEX clause takes precedence over a hint provided in the “index” field. (Documentation)
Using the FTS index we created, our N1QL query runs successfully and returns 5 results (hotel_5081, hotel_26020, hotel_10025, hotel_20425, hotel_25327) and the following execution plan:

Figure 7 - Execution plan using multiple indexes (FTS)
Same plan in JSON:
xxxxxxxxxx
{
"#operator": "Sequence",
"#stats": {
"#phaseSwitches": 1,
"execTime": "18.8µs"
},
"~children": [
{
"#operator": "Authorize",
"#stats": {
"#phaseSwitches": 3,
"execTime": "32.1µs",
"servTime": "3.421ms"
},
"privileges": {
"List": [
{
"Target": "default:travel-sample",
"Priv": 7
}
]
},
"~child": {
"#operator": "Sequence",
"#stats": {
"#phaseSwitches": 1,
"execTime": "122.8µs"
},
"~children": [
{
"#operator": "IndexFtsSearch",
"#stats": {
"#itemsOut": 5,
"#phaseSwitches": 23,
"execTime": "239.3µs",
"kernTime": "84.5µs",
"servTime": "3.9146ms"
},
"as": "t",
"index": "hotel_mult_arrays",
"index_id": "7a28a8346fad6118",
"keyspace": "travel-sample",
"namespace": "default",
"search_info": {
"field": "\"\"",
"options": "{\"index\": \"hotel_mult_arrays\"}",
"outname": "out",
"query": "{\"query\": {\"match\": \"Ozella\"}}"
},
"using": "fts",
"#time_normal": "00:00.004",
"#time_absolute": 0.0041539
},
{
"#operator": "Fetch",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 25,
"execTime": "334.8µs",
"kernTime": "4.4328ms",
"servTime": "1.5272ms"
},
"as": "t",
"keyspace": "travel-sample",
"namespace": "default",
"#time_normal": "00:00.001",
"#time_absolute": 0.001862
},
{
"#operator": "Parallel",
"#stats": {
"#phaseSwitches": 1,
"execTime": "21.1µs"
},
"copies": 2,
"~child": {
"#operator": "Sequence",
"#stats": {
"#phaseSwitches": 2,
"execTime": "49.1µs"
},
"~children": [
{
"#operator": "Filter",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 26,
"execTime": "6.8953ms",
"kernTime": "14.8149ms"
},
"condition": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \"Ozella\"}}, {\"index\": \"hotel_mult_arrays\"}))",
"#time_normal": "00:00.006",
"#time_absolute": 0.0068953
},
{
"#operator": "InitialProject",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 25,
"execTime": "2.3597ms",
"kernTime": "20.7458ms"
},
"result_terms": [
{
"expr": "(`t`.`name`)"
},
{
"expr": "(`t`.`address`)"
},
{
"expr": "(`t`.`city`)"
},
{
"expr": "(`t`.`country`)"
},
{
"expr": "(`t`.`phone`)"
},
{
"expr": "(`t`.`public_likes`)"
},
{
"expr": "(`t`.`reviews`)"
}
],
"#time_normal": "00:00.002",
"#time_absolute": 0.0023597
},
{
"#operator": "FinalProject",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 17,
"execTime": "300µs",
"kernTime": "375.9µs"
},
"#time_normal": "00:00",
"#time_absolute": 0
}
],
"#time_normal": "00:00.000",
"#time_absolute": 0.0000491
},
"#time_normal": "00:00.000",
"#time_absolute": 0.0000211
}
],
"#time_normal": "00:00.000",
"#time_absolute": 0.0001228
},
"#time_normal": "00:00.003",
"#time_absolute": 0.0034531
},
{
"#operator": "Stream",
"#stats": {
"#itemsIn": 5,
"#itemsOut": 5,
"#phaseSwitches": 13,
"execTime": "1.3409ms",
"kernTime": "14.8586ms"
},
"#time_normal": "00:00.001",
"#time_absolute": 0.0013409
}
],
"~versions": [
"2.0.0-N1QL",
"6.5.0-4960-enterprise"
],
"#time_normal": "00:00.000",
"#time_absolute": 0.0000188
}
In the single-node cluster being used for these examples, the query elapsed time is around 20 milliseconds to return the same 5 documents. As you can see in the plan, there is an IndexFtsSearch operator but there are no IndexScan3, DistinctScan, UnionScan, or IntersectScan operators. The overall query is much more efficient without these expensive GSI operators. The IndexFtsSearch operator sends the 5 matching documents from the FTS index to the Fetch operator which gets only those 5 documents. The fetch is much more efficient here than in the previous query since it’s only fetching 5 vs 904 documents, and this can also be observed in the comparison of overall elapsed times (and the servTime for the fetch operators: 170ms in query 1 and 1.5ms in query 2) between the queries.
Conclusion
With GSI you can mix and match multiple array indexes in a single query, but with FTS you can mix and match multiple arrays in a single FTS index (and with FTS there is no leading key problem as in GSI regarding the order of the fields in the index). As we’ve shown in this simple example of querying 2 arrays in the hotel documents, utilizing the new SEARCH() function in N1QL can result in simpler and more performant array queries. The same concept could be applied to queries utilizing several arrays, which would have even more favorable results over N1QL queries utilizing multiple GSI array indexes. This approach uses fewer system resources and provides higher throughput, which results in an increase in overall system efficiency.
This is just one example of the benefits of the integration between N1QL and FTS, and other benefits are documented in the blog posts in the references section below.
References
Couchbase Search Resources: https://www.couchbase.com/products/full-text-search
Couchbase FTS Documentation: https://docs.couchbase.com/server/current/fts/full-text-intro.html
Couchbase N1QL Search Documentation: https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
Couchbase FTS Blog Posts: https://blog.couchbase.com/category/full-text-search/
Couchbase FTS Online Training: https://learn.couchbase.com/store/509465-cb121-intro-to-couchbase-full-text-search-fts
Appendix
Index Definition JSON: hotel_mult_arrays
xxxxxxxxxx
{
"type": "fulltext-index",
"name": "hotel_mult_arrays",
"uuid": "5fc5d43dfebc4a60",
"sourceType": "couchbase",
"sourceName": "travel-sample",
"sourceUUID": "a1dd9dbb6aa27a47fac317dabfe74f61",
"planParams": {
"maxPartitionsPerPIndex": 171,
"indexPartitions": 6
},
"params": {
"doc_config": {
"docid_prefix_delim": "",
"docid_regexp": "",
"mode": "type_field",
"type_field": "type"
},
"mapping": {
"analysis": {},
"default_analyzer": "standard",
"default_datetime_parser": "dateTimeOptional",
"default_field": "_all",
"default_mapping": {
"dynamic": true,
"enabled": false
},
"default_type": "_default",
"docvalues_dynamic": true,
"index_dynamic": true,
"store_dynamic": false,
"type_field": "_type",
"types": {
"hotel": {
"dynamic": false,
"enabled": true,
"properties": {
"public_likes": {
"dynamic": false,
"enabled": true,
"fields": [
{
"docvalues": true,
"include_in_all": true,
"include_term_vectors": true,
"index": true,
"name": "public_likes",
"store": true,
"type": "text"
}
]
},
"reviews": {
"dynamic": false,
"enabled": true,
"properties": {
"author": {
"dynamic": false,
"enabled": true,
"fields": [
{
"docvalues": true,
"include_in_all": true,
"include_term_vectors": true,
"index": true,
"name": "author",
"store": true,
"type": "text"
}
]
}
}
}
}
}
}
},
"store": {
"indexType": "scorch"
}
},
"sourceParams": {}
}
Opinions expressed by DZone contributors are their own.
Comments