The problem that we are trying to solve here is programmatically finding the alignment between the car's orientation and the camera. The best way it can be represented is as a point-on-camera video streaming frame, where the car velocity is directed.
Typically, such a problem can be easily solved with the use of machine deep learning and neuron networks. However, I have insight that this problem could be solved with a non-trivial but very elegant solution; my knowledge in mathematics led me to use Least Square Optimization for Optical Flow representation of captured video stream without the need to train algorithms with real videos. This approach could automatically adapt to any environment as much as optical flow could provide accurate output.
Problem Statement
Let’s say you are developing a car autopilot and using some sort of dash camera for computer vision and navigation. Due to a lack of a standardized approach to installing that camera, each camera installation can have a different alignment between the camera and car orientation. The car dash camera calibration is an important step for car auto-piloting in general.
Before we jump into all the hassle of mathematical formulas and computer algorithms, in this YouTube playlist, you can see 10 video samples of algorithm execution results:
Solution Overview
To solve the problem, I mainly relied on Optical Flow with a combination of Least Square Optimization that will detect a point-on-video frame where the car is moving. Considering that typically the car moves straight forward, detecting car velocity direction from the camera video stream would represent car and camera alignment in the best way, and it will tell how the camera is oriented in relation to the car.
The challenge here is that the car is not always moving straight; also, due to rocking and shaking, the actual velocity could be chaotic and random around the actual searched values.
So, once we can get a stream of car velocity points over time by reading it from the car dash video stream, the next step is to filter out outliers and find some good percentile of data close to real positioning.
Optical Flow
So, first question: how could we capture car velocity from video? How can we find the point-on-video streaming where the car velocity is headed?
To solve that problem, there is a very handy representation of visual motion data called optical flow.
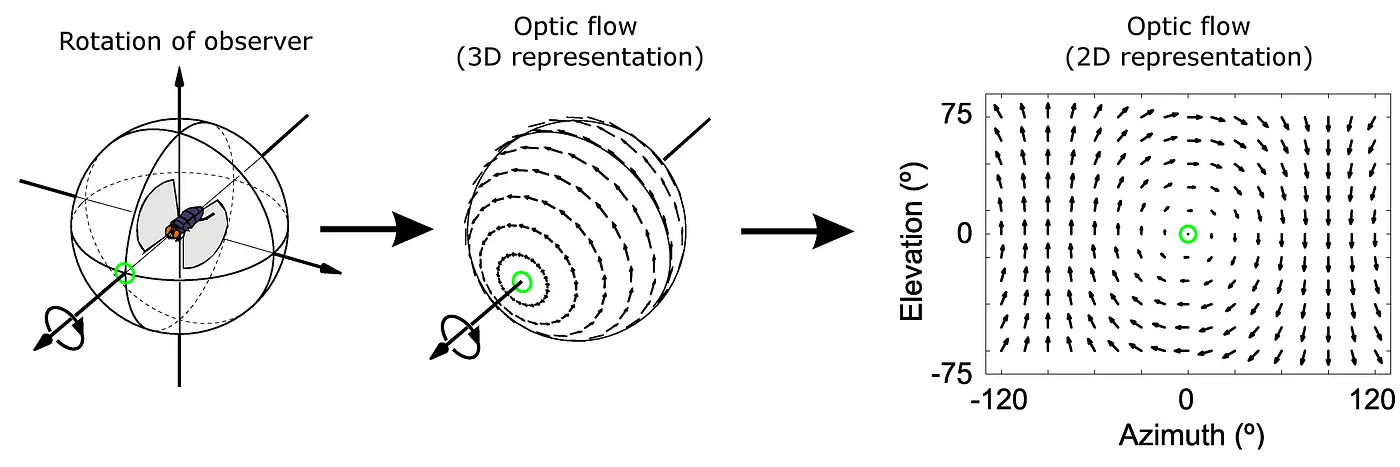
Wikipedia explains optical flow as: “Optical flow or optic flow is the pattern of apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer and a scene.”
I’ll try to rephrase it to make it more understandable. On video streaming, we typically capture how objects are animated in real life. So, with the use of a certain algorithm by processing two or more consecutive video frames, we are able to calculate a vector for every pixel of the video frame that represents how and where objects are moving behind that pixel on that video.
For example, let’s say we have a static camera that is recording a street, and there is a car moving from the left side of the video to the right side; by feeding two consecutively video frames, all the optical flow vector of every pixel of the car will be directed to the right, and the magnitude of that vectors will be the speed of car of real 3D world velocity projected onto 2D video frame image, as much as 2D-pixel processing algorithm can extract that motion.
What will happen if the camera is not static, but the camera is moving itself; for example, a car dash camera? Intuitively we can assume that all optical flow vectors will be headed from distant points, where our velocity is headed, and optical flow vectors will look backward to car motion, like in the Star Wars movie when the starship enters hyperspace.
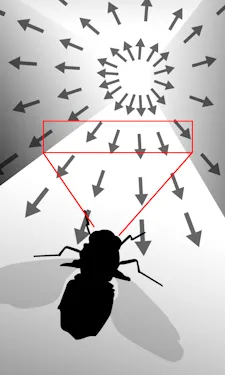
The reason why it happens is that when we drive straight to a very distant point far away, all objects are moving relatively backward to us following straight parallel lines, and according to perspective projection as real cameras do, all parallel lines of the real 3D world in 2D perspective projection will not be parallel anymore:
On one side all these parallel lines of 3D will be connected in a single point on 2D perspective projection, where this parallel line is directed far away in 3D space.
The other side of that 3D parallel line will go outside of the camera clipping 2D space.
Please see the illustration of perspective projection below, so you can see this 2D projection of the intersection of parallel lines in 3D space, very clearly:
So, optical flow just represents this relative parallel backward motion of objects we pass by, starting at the distant point where our car movement is directed.
In Python, it is handy to use the OpenCV library to capture video streaming and convert two consecutive frames into optical flow:
Python
import cv2
cap = cv2.VideoCapture(self.video_file)
prev_gray = None
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(self.frame, cv2.COLOR_BGR2GRAY)
flow = None
if prev_gray is not None:
flow = cv2.calcOpticalFlowFarneback(self.prev_gray, gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# flow is ready for further processing:
prev_gray = gray
cap.release()
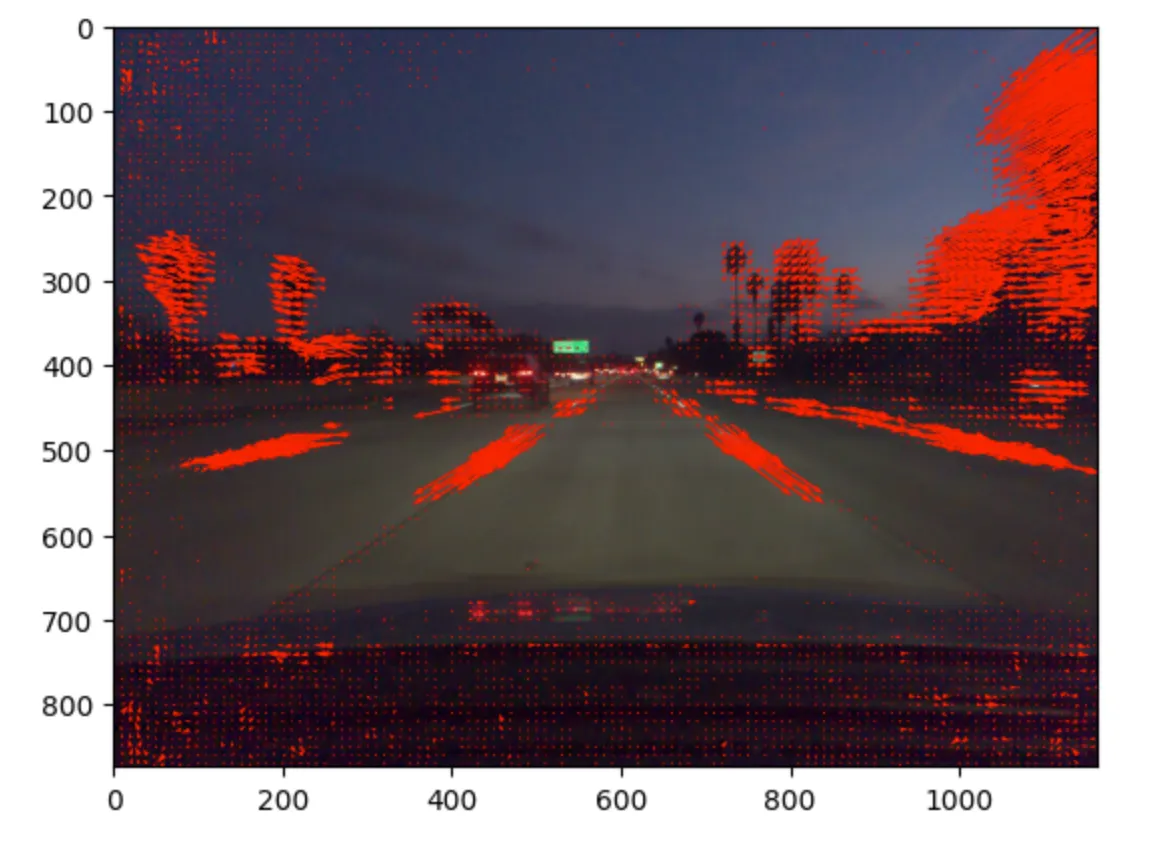
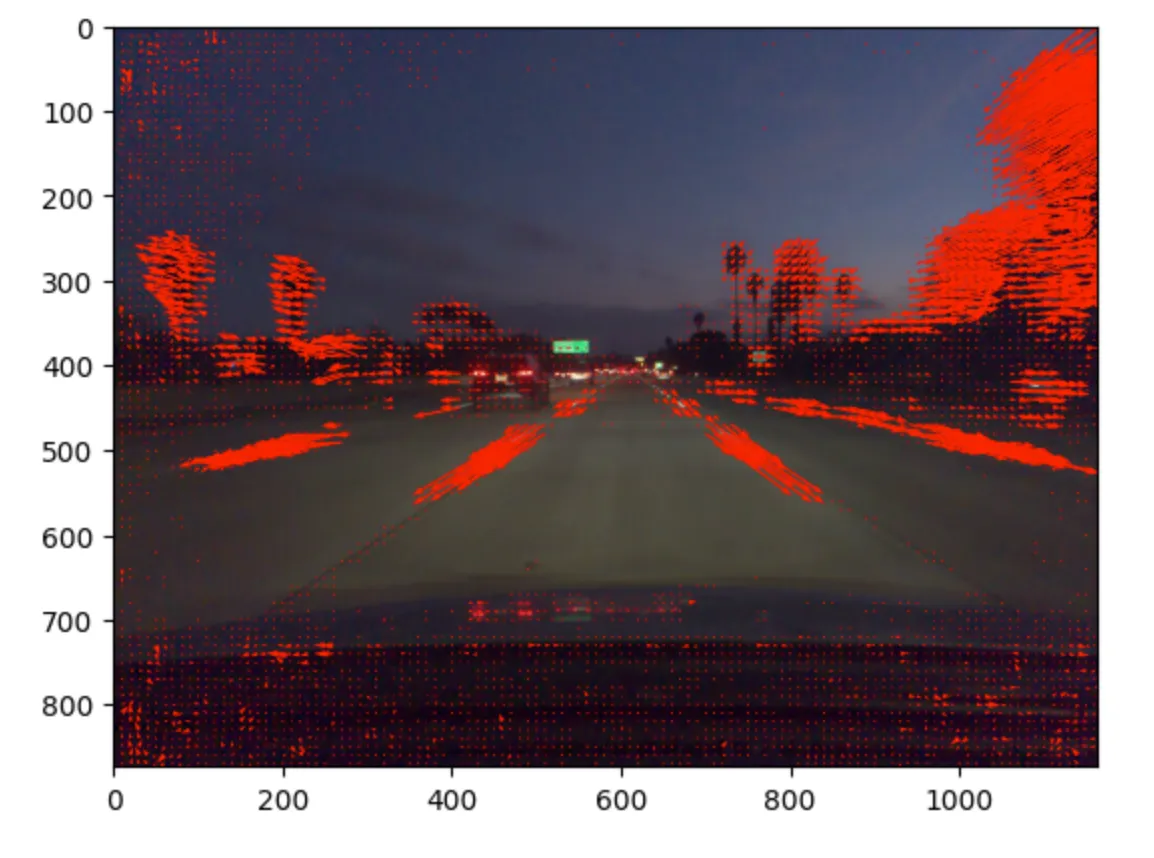
This picture is a visualization of an optical flow vector that has the largest magnitude from the video capturing that I’ve used to test an algorithm, and I think you should see enough optical flow vectors to calculate the point of car velocity.
You can see this tree on the right and on the left side, that it is directed to move outside of the camera view space as the car keeps moving forward.
Least Square Optimization
Now we learned what’s an optical flow, and to solve our problem, we need to find a point where all lines projected by the optical flow vector are intersected since it is a point where the car is headed.
In most simple cases, we have to find an intersection of two straight non-parallel lines projected by two non-colinear vectors — this is a very simple mathematical problem.
However, in our case, we have the entire picture of such vectors, where each pixel has its own optical flow vector and corresponding projected line, and the challenge is that due to noise and optical flow calculation accuracy — not every vector will look into the same point.
So, the problem that we trying to solve now, is to find the point that will be in most closest position to all straight lines projected by all optical flow vectors.
I’ve mentioned that we will use Least Square Optimization (LSO) for that, and for LSO we need to define the evaluation function. To find the closest point to all projected lines, as evaluation function will provide a distance between the searched point and projected lines, and we will try to minimize the value of that function with the use of LSO.
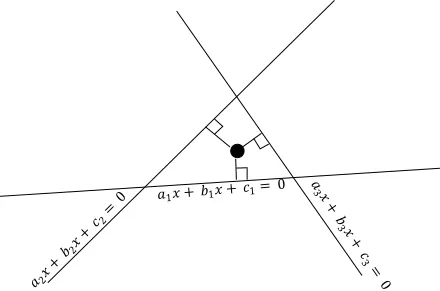
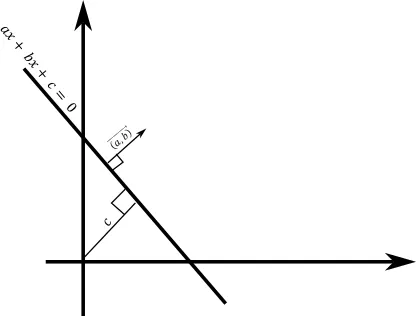
To define the distance between the point and the line, we will use the formula below:
ax + by + c = d
Where:
d: Is a distance between the point (x, y) to the line
(a,b): Is the unity vector perpendicular to the line
c: Is the distance from the center coordinate point (0,0) to the closest point on the line
And it should be obvious that any point that satisfies this equation: ax+bx+c=0 lies on that line.
In this article, I don’t have a purpose to go too much into details of linear algebra and geometry, however, if you want to learn more about finding distance between point and line, you can refer to the Wikipedia URL.
Let’s say we know the optical flow vector and its position, so we can find (a,b,c) in the following way.
For least squared optimization we need to define the function that we are trying to optimize, so we need to find a point where the distance to all lines projected by optical flow vectors would be minimal. For the optimization function, we will take a sum of squared distances between points and lines, with the following formula, and we want to find points (x, y) where LSO is minimal, where a, b, and c are known arguments calculated from optical flow vectors.
To find x, y where LSO will take the minimum value, it can be done by finding the roots of the derivative for that equation. Please refer to the wiki to learn more about what derivatives are.
As a result, we will have an easily solvable system of linear equations:
It can be described in the form of a matrix, and solved by means of Gaussian elimination or any other method:
And of course, Python has nice library functions to solve such equations.
As a result (x,y) - will be the point on the screen where the car is directed.
Precise Car Move Detection
For a more sophisticated scenario where a car is moving forward and spinning around one of its axes, we would need to solve a more sophisticated formula with a few extra variables (u,v) in addition to (x,y). Where (x,y) will represent the point where the car is directed, and (u,v) will represent the car's spinning motion.
However, in our case, to find camera alignment, we need only a few good frames where the car is moving forward. Any spinning or changing in driving direction will just create a noise for camera alignment calculation.
Below, I will describe a few tricks for how to filter out noise from the calculation in order to calibrate the camera.
LSO Code
Above, I have described how to capture the video stream and calculate optical flow with the use of the Open CV library.
Here is the code to calculate the intersection point of optical flow projected lines, which is also the car velocity point by using the formulas described above:
You may notice here, that I didn’t include normalization for optical flow vectors to make them unit vectors, the same way as I’ve described straight line function. I’ve mentioned that (a, b) — should be a unit vector, however, the reason why I didn’t include a normalized vector (a,b) — will be described in more detail in the next chapter about Noise Suppression.
Noise Suppression
The sample optical flow visualization that I’ve shared above, is actually representing only a few optical flow vectors, not all of them, however, the optical flow provides a vector for each pixel on the screen. To make this visualization representative to describe optical flow in the best way, I’ve drawn only the optical flow vectors whose magnitude was high enough above a certain threshold.
Obviously, the vectors with small magnitude, are not good to describe car velocity. For example, you can see these optical flow vectors at the bottom of the screen, which belong to the car dashboard. The car dashboard is static and doesn’t have any motion relative to the car camera, and its small, noisy vectors randomly look in different directions. The magnitude of this vector is small and barely breaks the threshold.
On the other side, we can see quite a high magnitude for road markings and trees on the side of the road, so the faster the car is moving the higher magnitude the object has, and these objects represent car motion in the best way.
If I draw optical flow and normalize their vector size, you will see a picture like this:
Obviously, optical flow vector magnitudes matter; however, it is not the only single parameter that we should take into account to filter the noise.
Let’s enumerate which attribute of optical flow we can use to measure the quality of each optical flow.
Quality of Model Evaluation List
First, we need to remember what parameters we have:
At this point, we are able to find a point (x,y) — where the car is moving to
We can keep a history of a series of points (x, y) calculated in the past
Each optical flow vector has a magnitude
Each optical flow vector has direction
Each optical flow vector is applied to a certain pixel position on the video frame
Using this argument above we can use certain calculations to evaluate the quality, which I’ve split into two categories:
We can evaluate the quality for each particular optical flow vector, drop the optical flow vectors from the calculation that seem to be outliers, and break the accuracy of our model
The series of calculated car direction points (x, y) is also a matter of study for quality evaluation.
Optical Flow Vector Magnitude
The first and obvious to take into consideration is to use magnitude.
I’ve tested a couple of approaches here:
One approach is to introduce some threshold to drop any optical vector whose magnitude is below the threshold.
Another approach is to quantify magnitude and use it as weight so a longer optical flow will impact more calculations than a smaller one.
Of course, I’ve started with the 1st approach as the most obvious one. I’ve started dropping vectors that didn’t pass a certain threshold. Dropping such vectors is actually very good for visualization, so my assumption was that if I could see it, I could calculate it; however, when I ran a few more tests, I didn’t see a lot of differences in whether I was performing magnitude cut-off or not.
However, if you remember this function, which can calculate the distance between any point on the screen and the optical flow projected line that is used in LSO:
ax + by + c = d
I found a very significant difference, when my argument (a,b, c) were normalized and when my argument (a,b,c) were proportional to optical flow vector magnitude. Normalization of (a,b,c) significantly reduced calculation accuracy compared to the proportional approach even with cut-off.
The rationale behind this is if you multiply all arguments by some coefficient “m”: it will be, like the following:
This will still represent the same straight line; however, distance evaluation used by LSO will be increased proportionally to argument “m”, so LSO in the first place will take into consideration larger (a, b, c), and only smaller.
If you remember that code sample above, when I calculated (a,b) — I didn’t make a normalization for that vector intentionally, and as a result, the vector (a,b) length is equal to the length of the optical flow vector length. So, the longer optical flow vector has more vote power in the LSO calculation.
Optical Flow Vector Magnitude Threshold
Regarding cutting off the optical flow vector based on magnitude, it might seem a good idea; however, during my tests in most cases, I didn’t find a significant difference. In one case I noticed a difference, when I had a lot of road traffic moving in opposite directions to me, and this traffic generated many optical flow vectors with high magnitude, so many smaller vectors with the right direction were not taken into account, even though it was majority of them. Since we are already using optical flow vector magnitude as vote power in the calculation, the cutoff threshold is already redundant.
Regarding that oppositely directed traffic, to suppress that noise, the best we can do is to utilize the law of large numbers, which states that the average of the results obtained from a larger number of independent and identical random samples converges to the true value if it exists. So, to increase accuracy instead of cutting off, I’ve decided to increase the number of optical flow vectors in calculation, and didn’t do any cutoff at all.
Initially, I tried to normalize all optical flow vectors, and the results were unsatisfying, almost on all videos, since the number of outliers is quite significant. Even though it was not the majority, it was still impacting the accuracy of the calculation.
When I used optical flow vector magnitude for calculation power, without any cutoff, the accuracy for calculation increased, and essentially for video samples with oppositely directed traffic.
Further, I’ve found a few more approaches, to how I can increase the accuracy of calculation, and it will be described in the next chapter below.
Law of Large Numbers and Gaussian Binomial Distribution
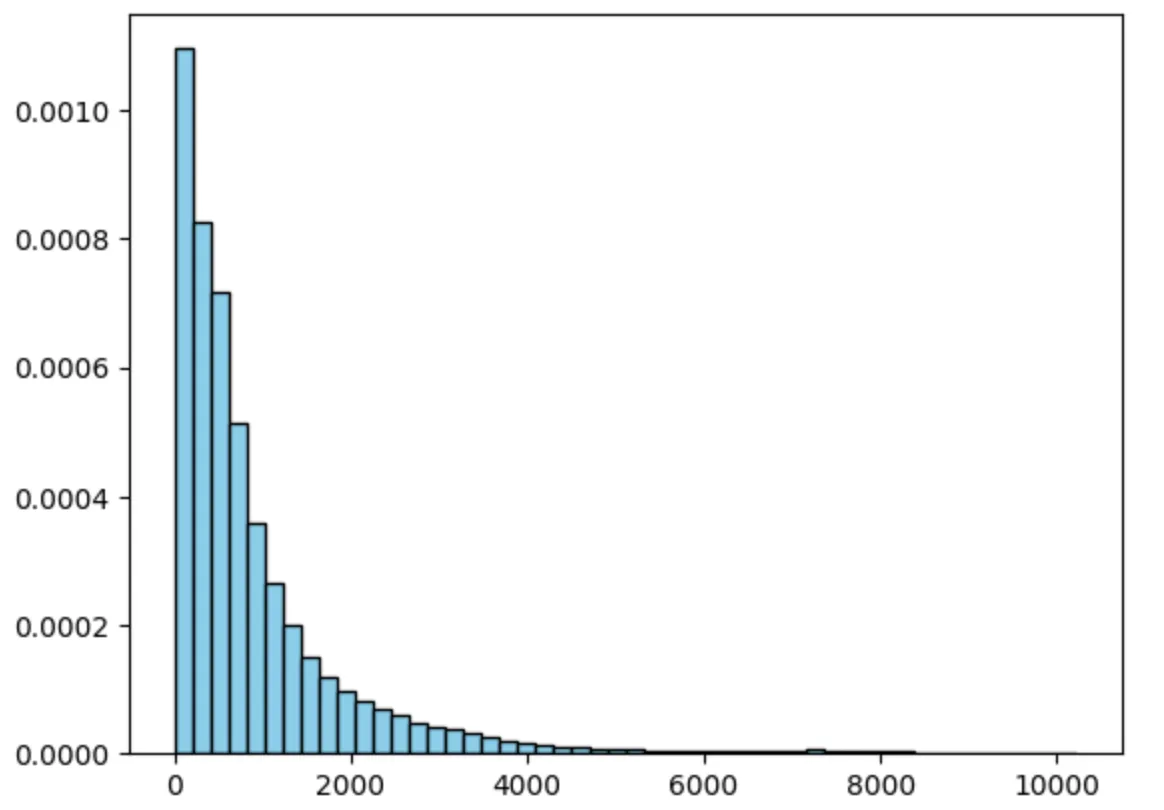
I’ve already touched on the topic of the law of large numbers, but now let me present the squared Gaussian binomial distribution from my calculations. The histogram below represents data from the first pass of Optical Flow LSO. To build buckets for the histogram, I’ve used a squared distance of the projected line by optical flow vector to the found point.
The axis of the chart is described below, and to calculate the x-bucket of values, I’ve used the “d” variable from the formula below.
ax + by + c = d
The x-axis is our deviation in squared pixels, it is like if we have an optical flow vector, it is the closed squared distance between lines projected by that optical flow vector to that point that we just found with the LSO method.
The y-axis is our percentage, like the frequency of how many such deviated optical flows we have.
As you can see from the chart below, the highest percentage of the data has a smaller deviation, and the amount of such data decreases with the higher deviation. That proves that the law of large numbers is applicable here. Typically Gaussian binomial distribution has a recognizable bell shape. In my LSO I am using a squared value, so we can observe only the positive half of that bell and it is squared.
Optical Flow Angle Deviation
Since we are looking for an intersection of many lines projected by an optical flow vector, one of the metrics to calculate if that optical flow vector is an outlier, is to calculate an angle between the optical flow vector and the vector directed from the correspondent pixel to point of projected lines intersection. If you remember optical flow are directed in the opposite direction to where the car is moving, so ideally the angle should be closer to 180 degrees.
The easiest way to get an angle is to use a dot vector product. Normalization for vectors is needed to get the angle accurately.
The code for filtering outliers by angle is below.
Meaning of variables:
(qvx[i], qvy[I]): Is i-th optical vector
(qx[i], qy[I]): Is the pixel coordinate of i-th optical vector
(c_x, c_y): The point of optical flow projected lines intersection
The calculation is briefly explained:
To calculate the angle accurately, I am normalizing my vectors first
As 1st vector: I am taking an optical flow vector
As 2nd vector: I am taking the vector from the optical flow pixel to the point of line intersection
As threshold: Instead of angle, the cos of angle is used, which is also the result of the dot product.
The function is parametrized with percentiles, instead of filtering to some hardcoded angle, it will filter out certain percentiles of deviated data for further calculation
The Cycle of Diversified Models for Outlier Reduction
I was always excited about the philosophical concept proposed by Hegel about thesis–antithesis–synthesis. The ancient wise Chinese philosophy noticed the same nature of metaphysics by expressing this in Yin and Yang concepts.
This concept is often used in engineering to create motion or to describe cycles of evolution, and in my case, I have also found an application for that to increase calculation accuracy by iterating through evaluation cycles with the use of different alternating models like Yin and Yang.
I’ve used two different mathematical models to describe the same mathematical problem, where both models could be used to describe deviation and mean in different way, and then I’ve used them by alternating one approach after another in a cycle, the precision is greatly increasing with each evaluation.
Initially, I was trying to use a single model by taking the mean and deviation only from that formula:
ax+bx+cx=d
However using the same formula for mean and deviation to sort out outliers, the mean almost never improves with such evaluation.
When I started using the second model, by using angle for deviation and outlier sorting-out, each time mean with the use of LSO and ax+bx+cx=d accuracy increased with every cycle of evaluation.
The way how to filter out outliers with angle deviation, as I’ve described before:
def filter_wrong_directed(q, c, percentile):
....
The code that handles evaluation cycles is provided below, and you can find a listing of the reused method above:
def find_move_direction_by_flow_tf_v2(
flow,
direction_percentile = 30,
stop_dot_value = 0.95
):
q = extract_flow_points_tf(flow)
l = list_of_lines_tf(q)
c = find_move_direction_by_lines_tf(l)
r = None
while True:
q = filter_wrong_directed(q, c, direction_percentile)
l = list_of_lines_tf(q)
c = find_move_direction_by_lines_tf(l)
r = {
"c": c,
"q": q
}
thr = q["thr"]
if thr > stop_dot_value:
break
return r
As you can notice here, instead of using angle threshold, I am using percentile here, so my angle threshold is dynamic, and with every new evaluation of a cycle by taking percentile, the angle threshold is decreased narrowing down calculation only to good optical flow vectors. With the use of a smaller percentile by running more numbers of iterations, I was able to increase calculation accuracy significantly.
Empirically, I’ve found that by filtering out only 10%, I was able to get the best accuracy, so no reason to go less than 10%. However, 30% required a smaller number of iterations, and 30% offered the best balance between performance and calculation accuracy. If something is not accurate with 30% compared to 10%, this noise will still be removed during the post-processing phase described below.
Here is a series of video frames, for each iteration of that cycle. This visualization presents which optical flow remains on each iteration.
1st iteration, we consider every optical flow for calculation.
2nd iteration —30% of optical flow vectors were dropped.
4th iteration — keep dropping a little bit more optical flow vectors.
Once we cleaned almost every optical flow vector noise keeping only the quality one, the 6th is the last iteration:
Camera Calibration
And now the last part for noise suppression.
Since we are processing the video, we can imagine that we will have a stream of point calibrations. The way that a good car direction point is calculated depends on many factors, like:
Car speed
Street brightness and video contrast
Amount of visible object that forms optical flow vectors
Accuracy of optical flow algorithm
An object that has its own velocity — like other cars
Car rocks and shakes
Change of car direction, road turns.
As part of camera calibration, while the camera is most of the time mounted statically, the stream of calculated points needs to be post-processed to get actual car camera alignment.
The logic for post-processing is quite straightforward:
All the time we keep a couple of seconds of the best data
To get the calibrated value, we take 30 percentile of best quality data and take the mean of that data
Once a new data point arrives, we replace the worst value with the new value.
In the result — history will keep only the best quality data and the mean of the 30 percentile will be used as the result for cutting off all outliers.
def sort_by_deviation(data, mean = None):
if mean is None:
mean = np.mean(data)
deviation = (data - mean)
deviation = deviation * deviation
indices = np.argsort(deviation)
sorted_data = data[indices]
return sorted_data
def smooth_calib(data):
result = np.copy(data)
prev_data = sort_by_deviation(data[:100])
result[:100] = np.mean(prev_data[:30])
for i in range(101, len(data)):
prev_data[-1] = data[i]
prev_data = sort_by_deviation(prev_data)
result[i] = np.mean(prev_data[:30])
return result
Here you can see a few different examples of car points calculated, before and after post-processing.
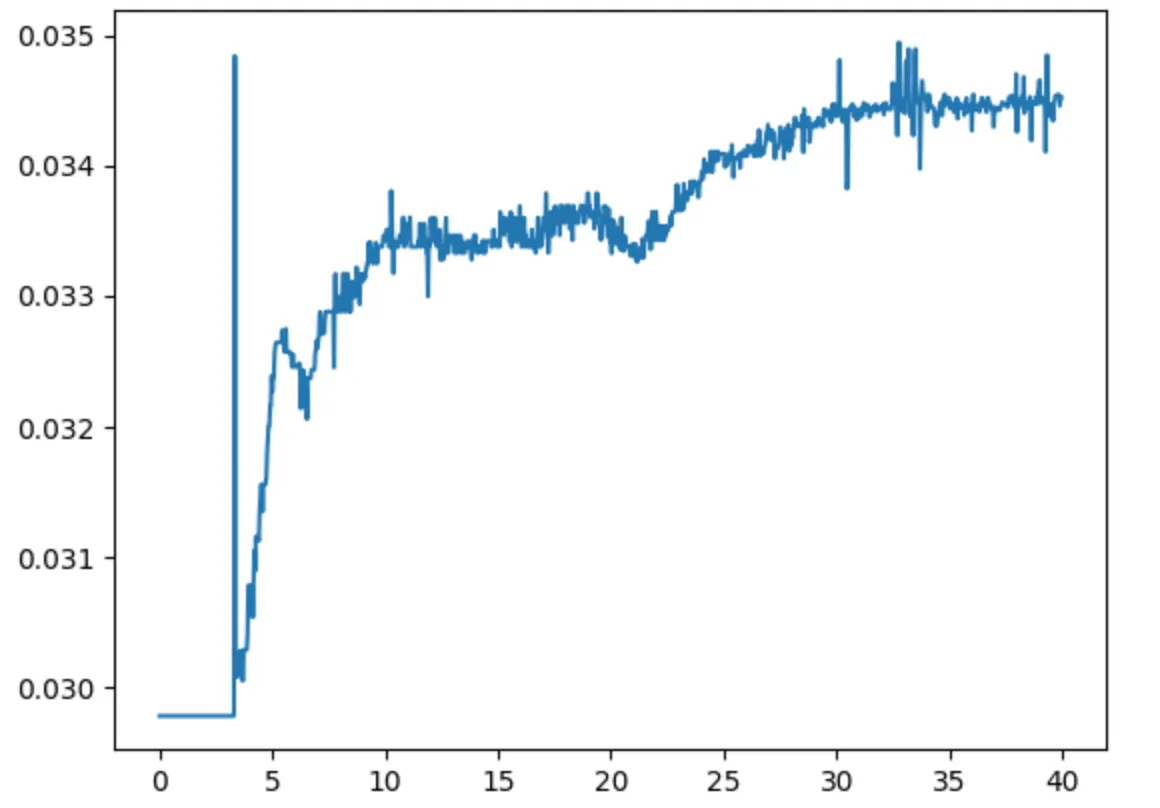
1st Sample: Best Quality Achieved During LSO
Before post-processing, the noise in range was: 0.0 to 0.1.
After post-processing, the noise range was reduced x3 times: 0.030 to 0.035.
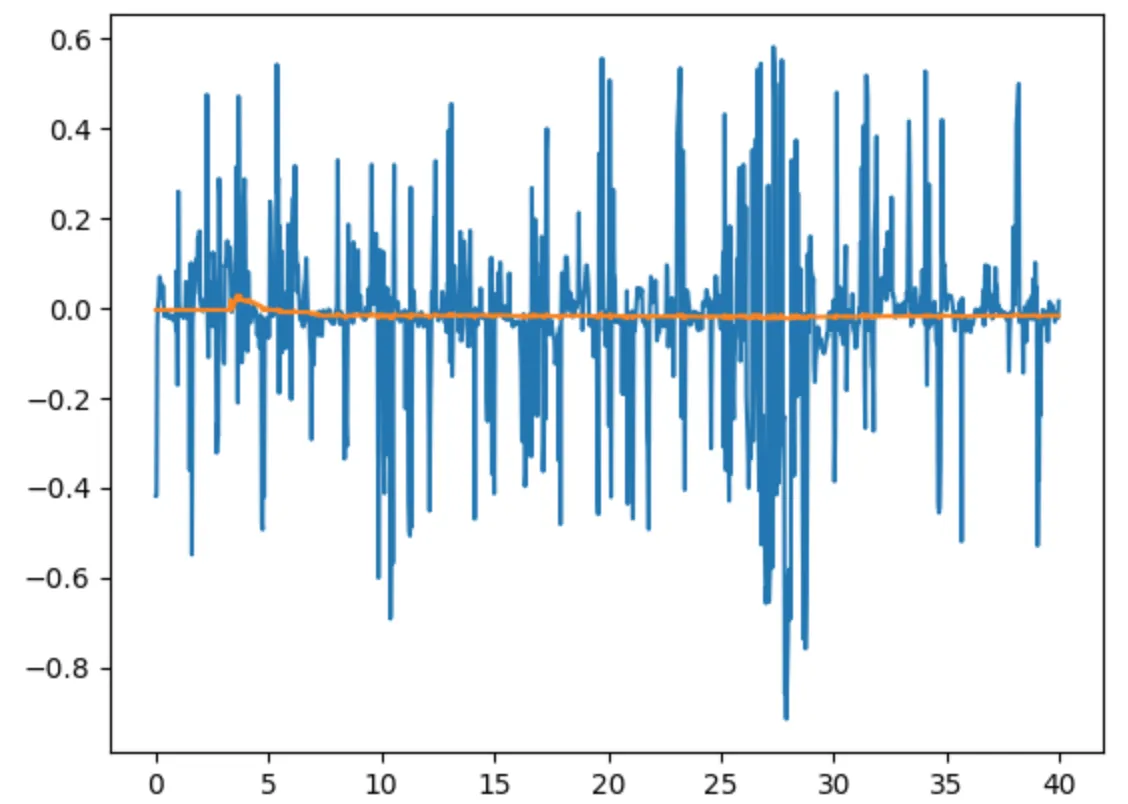
2nd Sample: A Car Turning to the Right and Then to the Left Somewhere Between 30 and 35 Seconds
Before post-processing: the noise range was: 0.0 to 0.2.
After post-processing, the noise range reduced x10 times: 0.02 to 0.04.
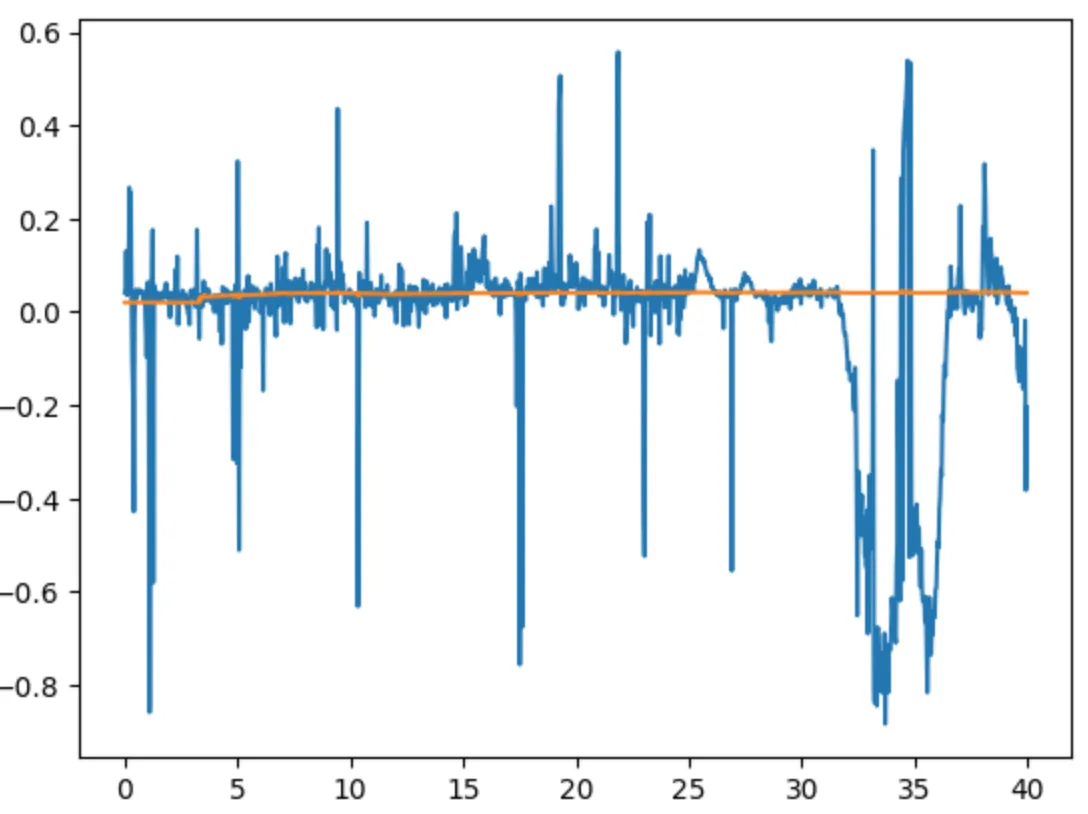
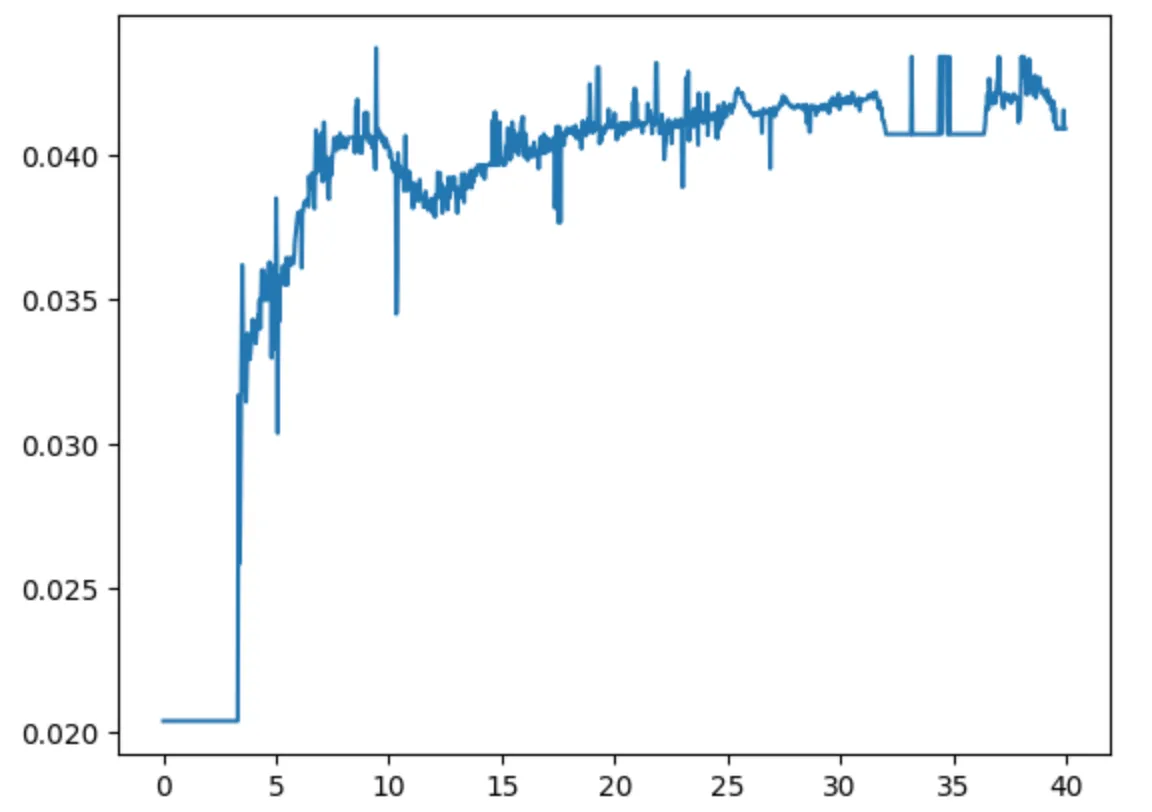
3nd Sample: Worst Quality Captured by LSO
Before post-processing, the noise range was: -0.6 to 0.4.
After post-processing, the noise range reduced x50 times: -0.01 to 0.03.
Averaging
Averaging of data is another way to post-process the data. The idea is to take a mean of the last n-points.
def smooth_data(data, n):
result = np.copy(data)
if n <= 1:
return result
for i in range(len(data)):
arr_st = i - int(n /2)
if arr_st < 0:
arr_st = 0
arr_end = arr_st + n
if arr_end > len(data):
arr_end = len(data)
arr_st = arr_end - n
if arr_st < 0:
arr_st = 0
if arr_st == arr_end:
break
result[i] = np.sum(data[arr_st: arr_end]) / (arr_end - arr_st)
return result
It is not that good for camera calibration, however, it is quite accurate about the direction of the car, essentially when the car changes its direction of movement. Please see the chart and video below:
At the beginning of the video, you can notice, that the direction of the cursor slightly shifted to the left, if you take a closer look at precisely where the left lane overlapped by car hood pixels, you will notice that the driver is slightly shifting his car to the left for couple seconds before he makes a right turn on the ramp, during the right turn direction cursor is moved to the right, so cursor in averaging mode is quite accurately demonstrates where car wheels turning the car on that video.
Conclusion
At this point, we have completed all four steps for camera calibration:
We generated optical flow from video frames
We used LSO to find car motion direction
We used angle deviation to drop some optical flow vector outliers, to increase the accuracy of LSO calculation.
And finally, we used post-processing to do the actual calibration
As you can see the approach is very logical and mathematically grounded. It provides a certain level of calculation accuracy, and I’ve explained a few places where it can be improved even more.
Besides theoretical grounding — provided video also demonstrates the feasibility of the approach.
ML or Not ML
Typically Machine Learning and Neural Network image processing capabilities can solve this camera calibration problem. And NN itself is a very accurate but slow way to calculate Optical Flow.
Which approach is actually better ML or this elegant solution described above?
There are pros and cons for both.
The main disadvantage of Neuron Network, which is actually an advantage at the same time, is that it can only learn from what it’s seen before. The advantage is that if there is any problem with the NN model, fixing the problem is as simple as retraining by feeding a few more videos where NN made a mistake.
Using SLO with Optical Flow doesn’t require any video to learn. This algorithm is supposed to work in any condition since it doesn’t require learning at all, which is good. As a con, each algorithm has its own limitations. With proper dedication it could be improved, however, it might not be as simple as just feeding more videos with NN. However, this algorithm can show much better resilience for very unusual conditions with NN, since it uses very definite logic for calculation.
For reliability it is worth considering redundancy, if a system is built of multiple different approaches, where evaluation is done by feeding results of multiple models, it would lead to an increase of the overall system resiliency and it could be better than just depending on a single approach.





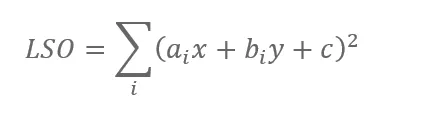
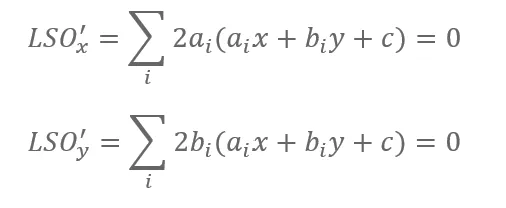
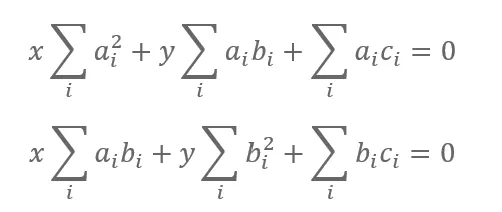
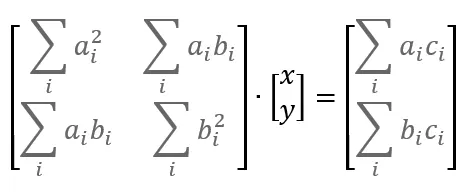
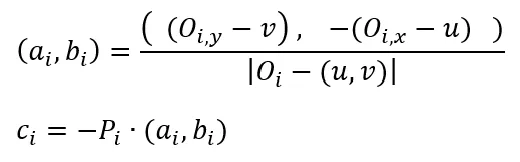

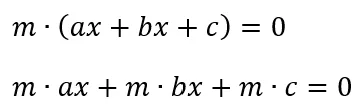
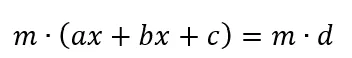


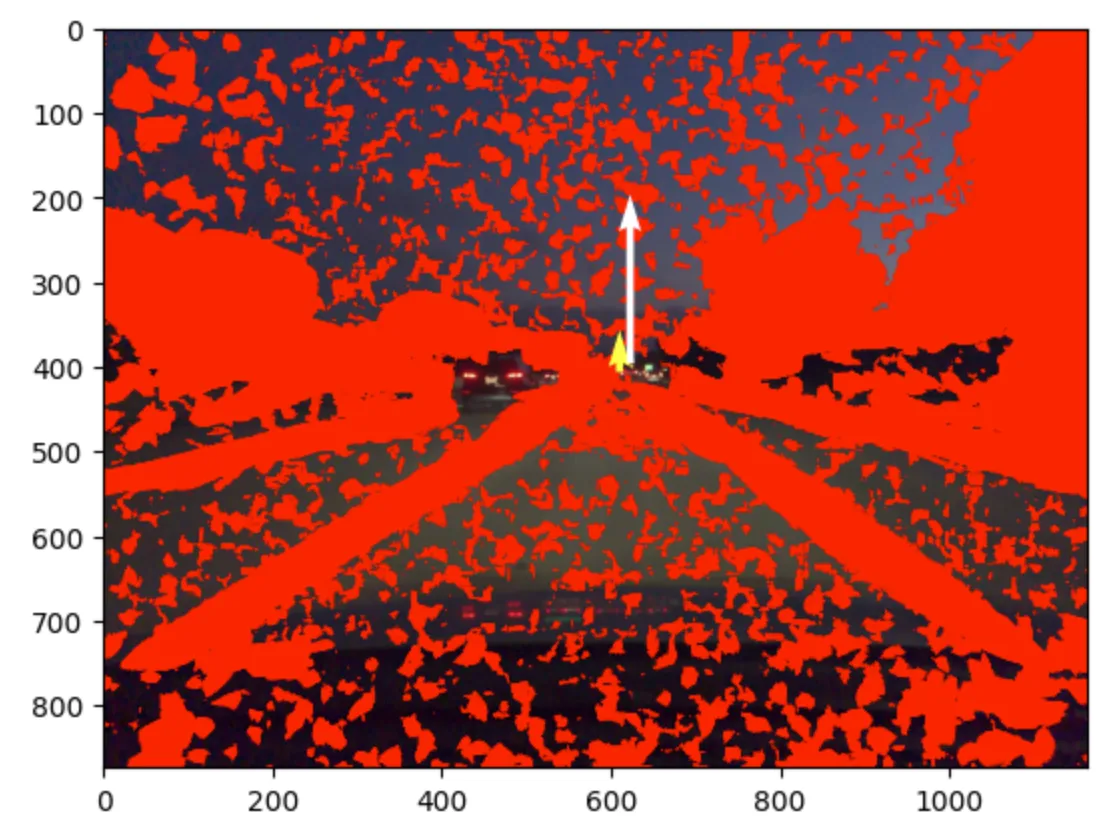
 Camera Calibration
Camera Calibration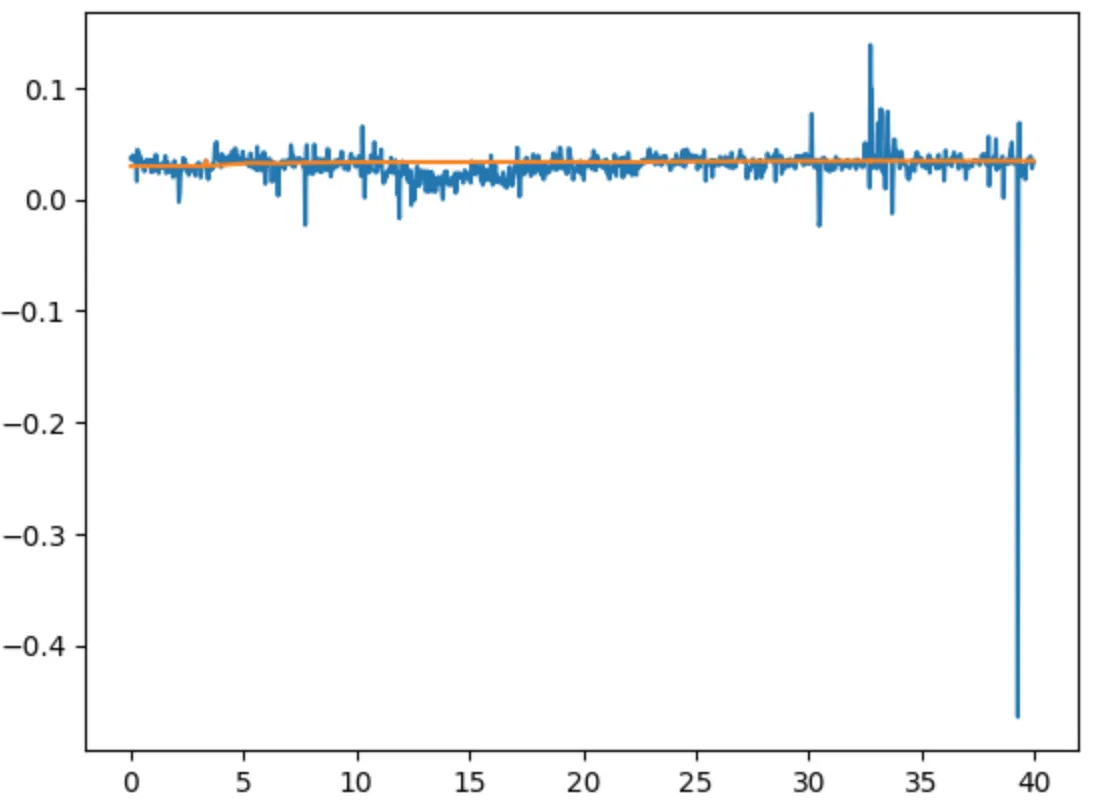
 After post-processing, the noise range reduced x50 times: -0.01 to 0.03.
After post-processing, the noise range reduced x50 times: -0.01 to 0.03.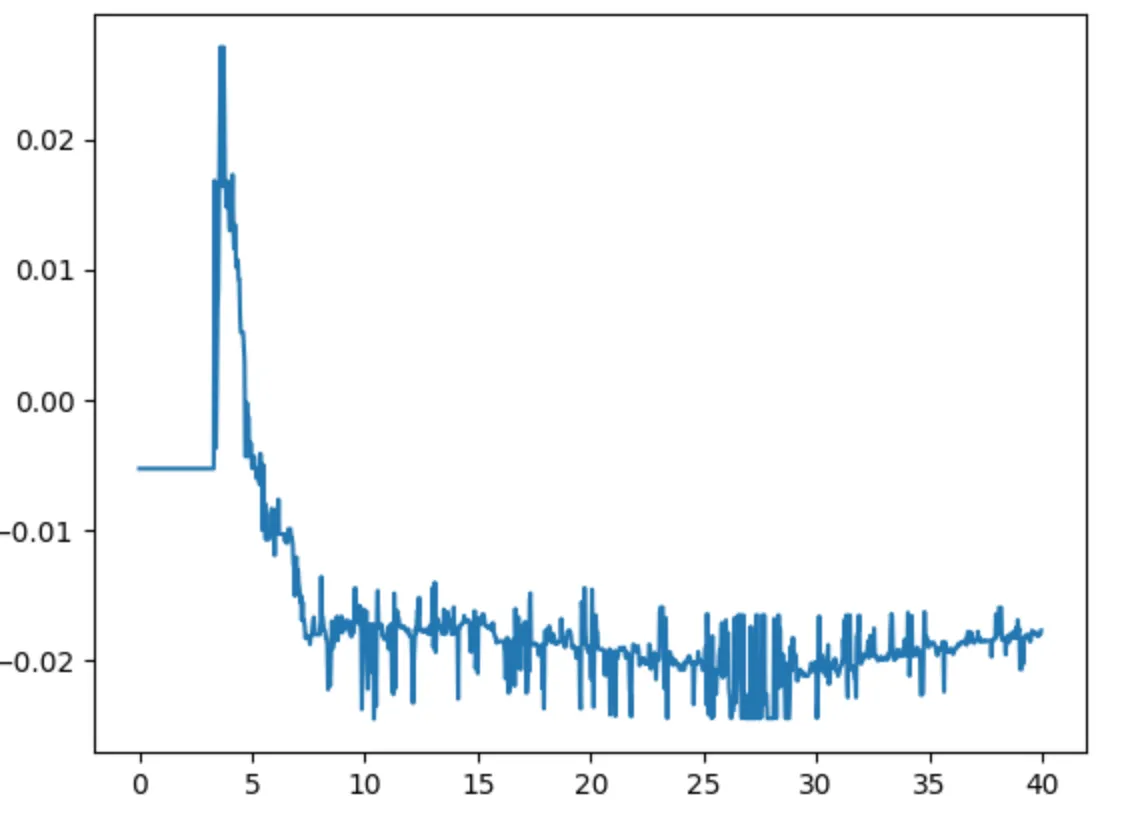 Averaging
Averaging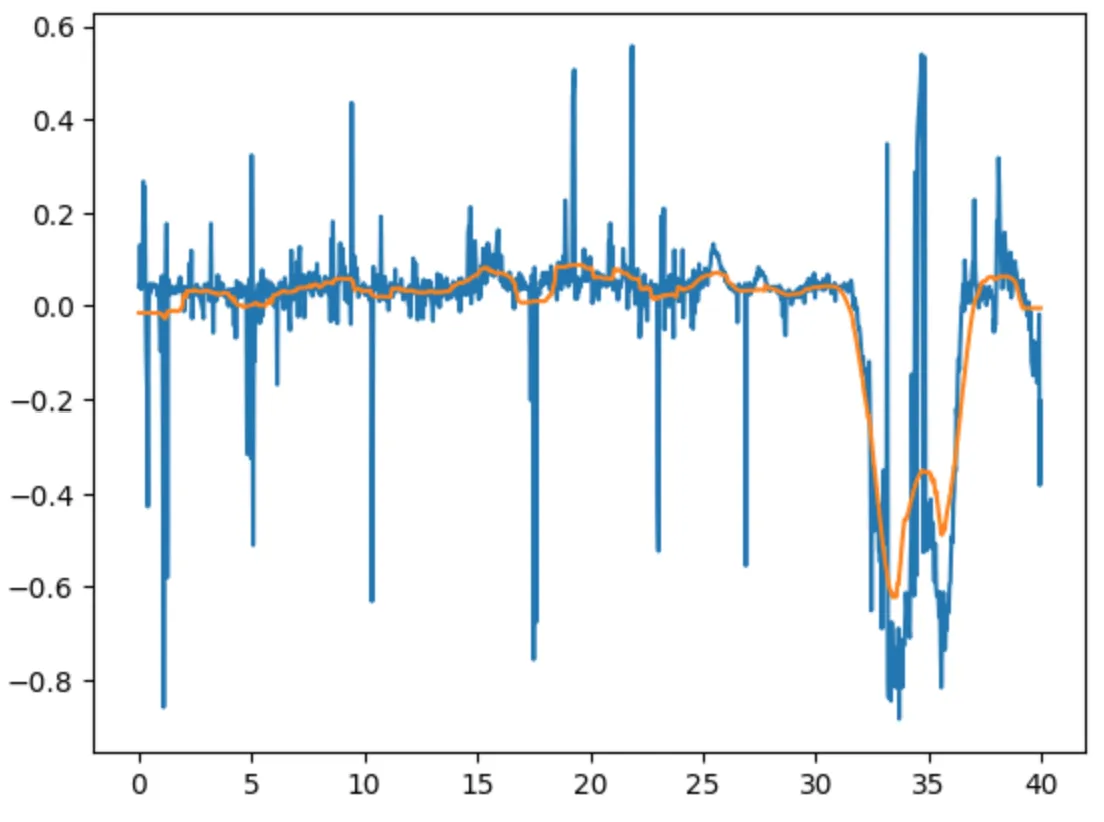
Comments