Comprehensive Gun Detection for Schools: An AI-Based Approach Leveraging Audio and Video Insights
The focus is on identifying guns visually and discerning gun-related sounds, creating a comprehensive system for threat detection.
Join the DZone community and get the full member experience.
Join For FreeThis article discusses a new approach to detecting guns in educational institutions by leveraging visual and auditory cues. The system below combines YOLOv7 for image recognition and pyAudioAnalysis for audio analysis to identify guns visually and discern gun-related sounds. The aim is to create a comprehensive security framework that can detect possible threats and ensure the safety of schools in a constantly changing security landscape.
Unified Approach: Merging Visual and Auditory Cues
Visual: Gun Detection Approaches
Image-Based Gun Detection With YOLO (You Only Look Once)
In 2016, Joseph Redmon and Santosh Divvala introduced YOLO (You Only Look Once), a one-stage object detection system that stands out for its image-based gun detection feature. YOLO works by dividing the input image into a grid and efficiently predicting bounding boxes and class probabilities. It is versatile in handling objects of different scales and is suitable for time-sensitive applications due to its real-time processing capability.
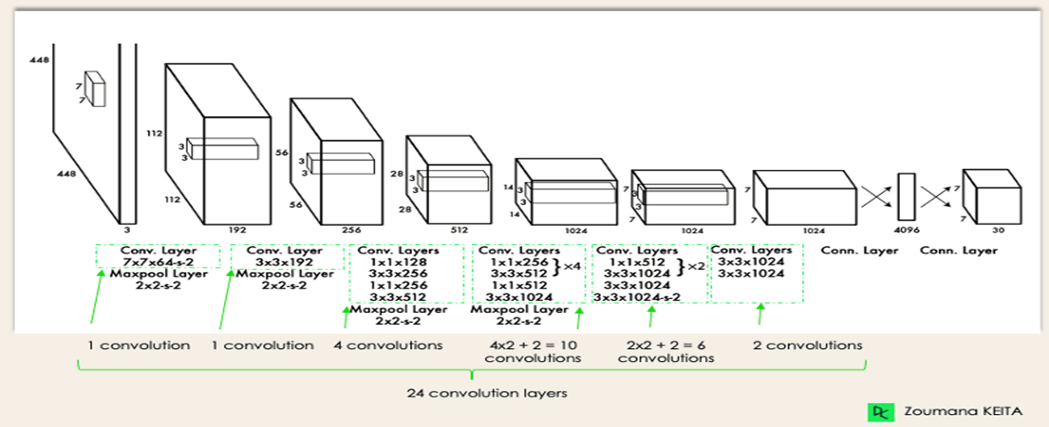
YOLO Architecture from the original paper
Image-Based Gun Detection With Faster R-CNN
Faster R-CNN, also known as region-based Convolutional Neural Network, is a popular and effective object detection model introduced by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun in 2015. It addresses the limitations of the original R-CNN and Fast R-CNN models and achieves better performance in terms of both accuracy and speed. 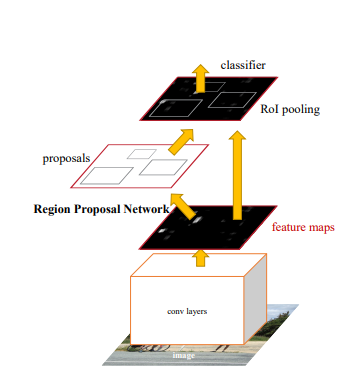
R-CNN Diagram from the original paper
Comparison of Approaches
Two popular object detection algorithms are YOLOv and Faster R-CNN. YOLOv is known for its real-time processing and ability to handle a wide variety of objects. However, it may require significant computational resources during training. On the other hand, Faster R-CNN is known for its high accuracy in object detection. However, its implementation is complex and demands substantial computational resources.
When choosing between the two algorithms, it's important to consider the specific needs of the application. If real-time processing and versatility are important factors, YOLOv7 may be the better choice. However, if uncompromising accuracy is paramount, Faster R-CNN is the way to go.
Auditory Cues: Audio-Based Gun Detection Approaches
PyAudioAnalysis is a robust tool for feature extraction and classification from audio signals. It efficiently supports model training, but effective usage requires careful tuning and dataset preparation.
Transfer learning is an alternative audio processing approach, utilizing pre-trained models to leverage existing knowledge. While advantageous, it may necessitate fine-tuning for task-specific requirements.
Environmental sound recognition models, tailored for recognizing environmental sounds, offer another avenue. Customization may be required, and accuracy hinges on extensive datasets.
In conclusion, PyAudioAnalysis is recommended for its versatility. For targeted audio recognition tasks, consider transfer learning to harness pre-trained models effectively.
Overall Unified Approach: Advantages and Significance
Advantages
- Comprehensive threat detection: Integrating image and audio processing provides a nuanced threat detection mechanism.
- Enhanced accuracy: The combination of visual and auditory cues improves overall accuracy in identifying potential threats.
- Versatility: The system is adaptable to diverse scenarios, offering a unified solution for threat detection.
Conclusion
In conclusion, the unified approach combining YOLOv7 and pyAudioAnalysis emerges as a powerful solution for comprehensive gun detection. Understanding the strengths and considerations of each component allows security practitioners to tailor the approach to meet specific environmental requirements, fostering a safer and more secure space.
Let’s Deep Dive Into Implementation Details
Integrating YOLOv for Gun Detection
- The script utilizes the YOLOv model for image-based inference on video frames, identifying potential gun objects in real-time.
- Bounding box coordinates and labels are extracted from the model's predictions.
Training the Audio Classifier
- The script employs pyAudioAnalysis to feature and train an audio classifier using datasets containing gun and non-gun sounds.
- The SVM-based audio model is trained to classify audio signals into gun or non-gun categories.
Synergy of Image and Audio Processing
Unified Threat Detection
- The script combines image and audio-based threat detection by running YOLOv concurrently with pyAudioAnalysis during video capture.
- Visual cues from image analysis and auditory information from audio classification harmonize to enhance overall threat detection capabilities.
Real-Time Notifications With Twilio Integration
- The unified system includes Twilio integration for real-time SMS notifications when a gun is detected visually or through audio.
- Twilio credentials are incorporated into the script for seamless communication.
import cv2
import torch
from pyAudioAnalysis import audioTrainTest as aT
from twilio.rest import Client
# Load YOLOv model
def load_yolov5_model():
return torch.hub.load('ultralytics/yolov5:v5.0', 'yolov5s', pretrained=True)
# Train the audio classifier
def train_audio_classifier():
aT.featureAndTrain(["audio_dataset/gun", "audio_dataset/non_gun"], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, "svm", "svm_gun_model")
# Send SMS notification using Twilio
def send_sms_notification(account_sid, auth_token, twilio_phone_number, recipient_phone_number, message):
client = Client(account_sid, auth_token)
try:
message = client.messages.create(
body=message,
from_=twilio_phone_number,
to=recipient_phone_number
)
print(f"Notification sent with SID: {message.sid}")
except Exception as e:
print(f"Failed to send notification: {e}")
# Main function for gun detection
def detect_gun():
# Load models
model = load_yolov5_model()
train_audio_classifier()
# Open video capture (use 0 for the default camera)
cap = cv2.VideoCapture(0)
while True:
# Read a frame from the video stream
ret, frame = cap.read()
if not ret:
break
# Perform image-based inference
results = model(frame)
# Get bounding box coordinates and labels
bboxes = results.xyxy[0].cpu().numpy()
labels = results.names[0][results.xyxy[0][:, -1].long()].cpu().numpy()
# Filter out gun detections
gun_detections = [(bboxes[i, :-1], labels[i]) for i in range(len(bboxes)) if results.names[0][labels[i]] in gun_classes]
# Draw bounding boxes on the frame
for (x_min, y_min, x_max, y_max), label in gun_detections:
cv2.rectangle(frame, (int(x_min), int(y_min)), (int(x_max), int(y_max)), (0, 255, 0), 2)
cv2.putText(frame, results.names[0][label], (int(x_min), int(y_min) - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# Perform audio-based classification
audio_file_path = "test_audio_file.wav" # Replace with your own audio file path
result, _, _, _ = aT.fileClassification(audio_file_path, "svm_gun_model", "svm")
# Send SMS notification if gun is detected either visually or through audio
if len(gun_detections) > 0 or result == "gun":
message = "Gun detected! Please investigate immediately."
send_sms_notification(account_sid, auth_token, twilio_phone_number, recipient_phone_number, message)
# Display the result
cv2.imshow('Gun Detection', frame)
# Break the loop if 'q' key is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release the video capture object and close the OpenCV window
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
# Twilio credentials (replace with your own)
account_sid = 'account_sid'
auth_token = 'auth_token'
twilio_phone_number = 'twilio_phone_number'
recipient_phone_number = 'recipient_phone_number'
# Define classes for gun detection
gun_classes = ['pistol', 'rifle', 'gun', 'firearm'] # Add more if necessary
# Run the gun detection
detect_gun()
Opinions expressed by DZone contributors are their own.
Comments