Command Query Responsibility Segregation (CQRS)
In this article, dive into distinct command/query roles, potential database setups, and the implications of data synchronization.
Join the DZone community and get the full member experience.
Join For FreeThe Initial Need Leading to CQRS
The traditional CRUD (Create, Read, Update, Delete) pattern has been a mainstay in system architectures for many years. In CRUD, reading and writing operations are usually handled by the same data model and often by the same database schema. While this approach is straightforward and intuitive, it becomes less effective as systems scale and as requirements become more complex.
For instance, consider a large-scale e-commerce application with millions of users. This system may face conflicting demands: it needs to quickly read product details, reviews, and user profiles, but it also has to handle thousands of transactions, inventory updates, and order placements efficiently. As both reading and writing operations grow, using a single model for both can lead to bottlenecks, impacting performance and user experience.
Basics of the CQRS Pattern
CQRS was introduced to address these scaling challenges. The essence of the pattern lies in its name — Command Query Responsibility Segregation. Here, commands are responsible for any change in the system’s state (like placing an order or updating a user profile), while queries handle data retrieval without any side effects.
In a CQRS system, these two operations are treated as entirely distinct responsibilities, often with separate data models, databases, or even separate servers or services. This allows each to be tuned, scaled, and maintained independently of the other, aligning with the specific demands of each operation.
CQRS Components
Commands
Commands are the directive components that perform actions or changes within the system. They should be named to reflect the intent and context, such as PlaceOrder or UpdateUserProfile. Importantly, commands should be responsible for changes, and therefore should not return data. Further exploration into how commands handle validation, authorization, and business logic would illuminate their role within the CQRS pattern.
Queries
Queries, on the other hand, handle all request-for-data operations. The focus could be on how these are constructed to provide optimized, denormalized views of the data tailored for specific use cases. You may delve into different strategies for structuring and optimizing query services to deal with potentially complex read models.
Command and Query Handlers
Handlers serve as the brokers that facilitate the execution of commands and queries. Command handlers are responsible for executing the logic tied to data mutations while ensuring validations and business rules are adhered to. Query handlers manage the retrieval of data, potentially involving complex aggregations or joins to form the requested read model.
Single Database vs Dual Database Approach
Single Database
In this model, both command and query operations are performed on a single database, but with distinct models or schemas. Even though both operations share the same physical storage, they might utilize different tables, views, or indexes optimized for their specific requirements.
It could be represented as follows:
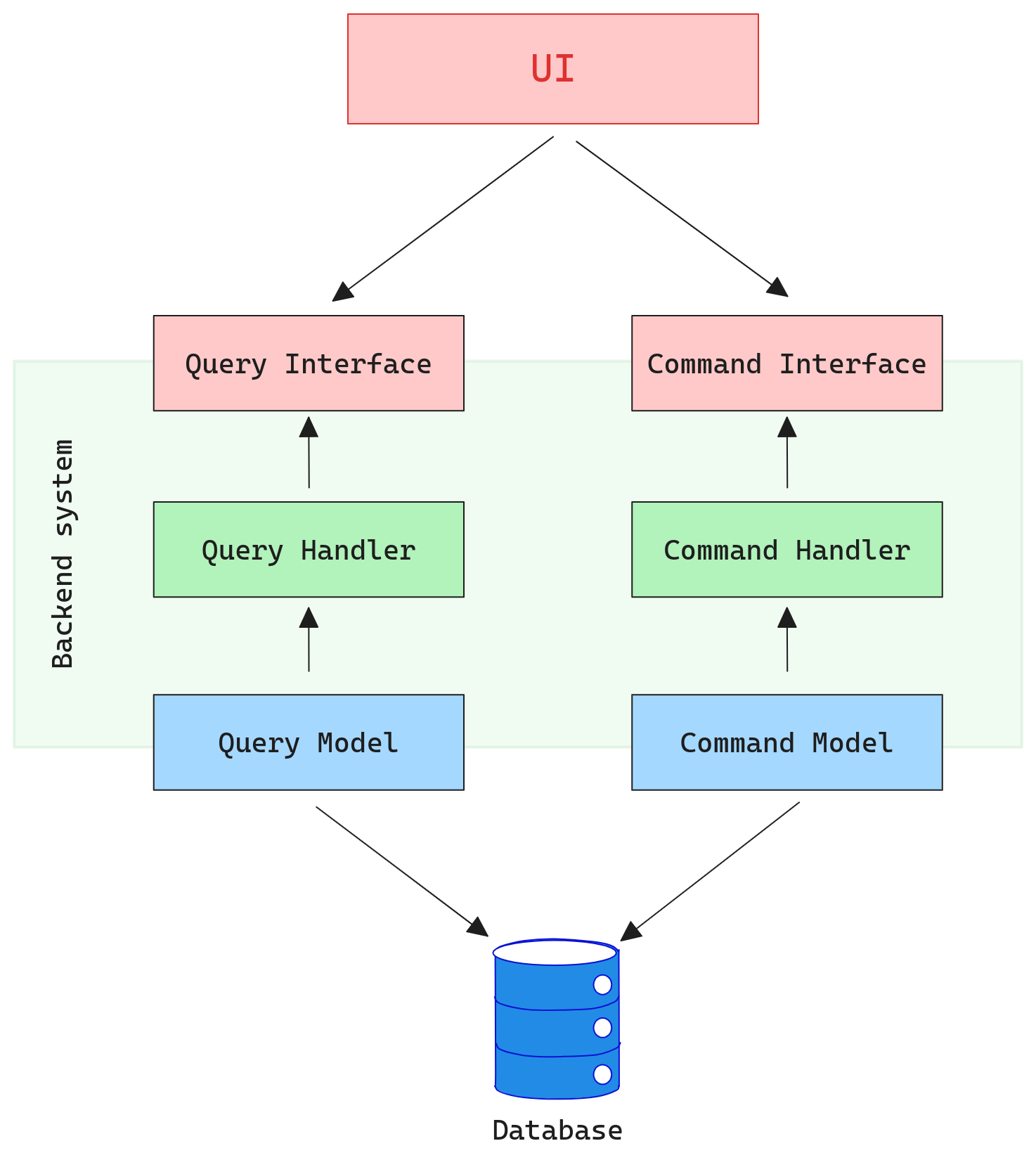
Single database representation
Benefits
- Simplified infrastructure and reduced overhead
- Immediate consistency, as there’s no lag between write and read operations
Trade-Offs
- The shared resource can still become a bottleneck during heavy concurrent operations.
- Less flexibility in tuning and scaling operations independently
Dual Database Approach
Here, command and query operations are entirely separated, using two distinct databases or storage systems. The write database is dedicated to handling commands, while the read database serves query operations. A handle synchronization system must be added.
It could be represented as follows:
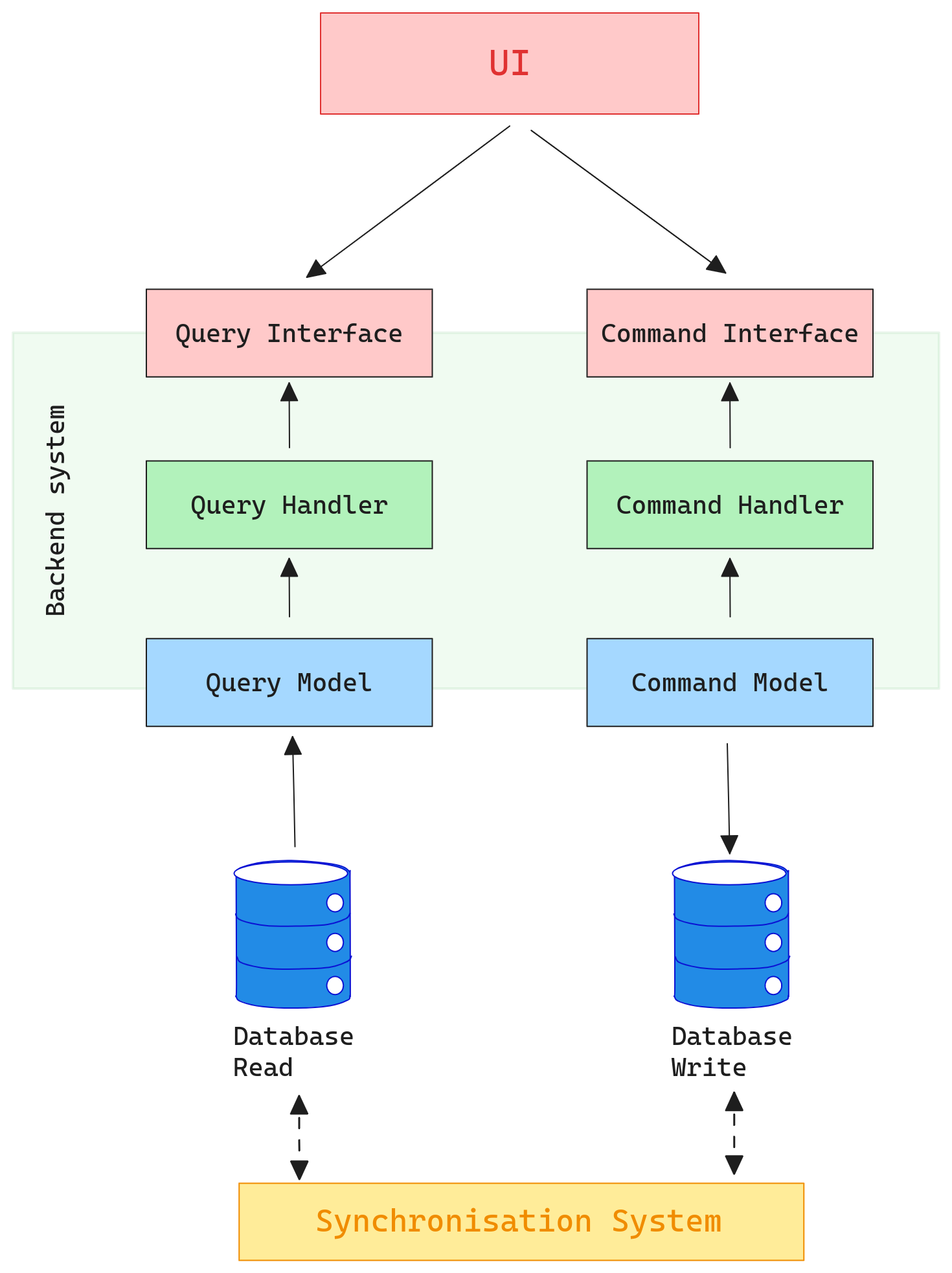
Multi database representation
Benefits
- Individual tuning, scaling, and optimization for each operation
- Potential for each database to be hosted on different servers or services, distributing load; database solutions could also be different to allow more modularity for specific needs.
Trade-Offs
- Introduces complexity in ensuring data consistency between the two databases
- Requires synchronization mechanisms to bridge the potential misalignment or latency between the write and read databases: For instance, a write operation may update the command database, but the read database might not immediately reflect these changes. To address this, synchronization techniques can range from simple polling to more intricate methods like Event Sourcing, where modifications are captured as a series of events and replayed to update the read database.
The single database approach offers simplicity; the dual database configuration provides more flexibility and scalability at the cost of added complexity. The choice between these approaches depends on the specific requirements and challenges of the system in question, particularly around performance needs and consistency requirements.
Benefits and Trade-Offs of CQRS Pattern
Benefits
- Performance optimization: By separating read and write logic, you can independently scale and optimize each aspect. For instance, if a system is read-heavy, you can allocate more resources to handling queries without being bogged down by the demands of write operations.
- Flexibility and scalability: With separate models for reading and writing, it’s easier to introduce changes in one without affecting the other. This segregation not only allows for more agile development and easier scalability but also offers protection against common issues associated with eager entity loading. By distinctly handling reads and writes, systems can be optimized to avoid unnecessary data loading, thereby improving performance and reducing resource consumption.
- Simplified codebase: Separating command and query logic can lead to a more maintainable and less error-prone codebase. Each model has a clear responsibility, reducing the likelihood of bugs introduced due to intertwined logic.
Trade-Offs
- Data consistency: As there might be different models for read and write, achieving data consistency can be challenging. CQRS often goes hand-in-hand with the “eventual consistency” model, which might not be suitable for all applications.
- Complexity overhead: Introducing CQRS can add complexity, especially if it’s paired with other patterns like Event Sourcing. It’s crucial to assess whether the benefits gained outweigh the added intricacy.
- Increased development effort: Having separate models for reading and writing means, in essence, maintaining two distinct parts of the system. This can increase the initial development effort and also the ongoing maintenance overhead.
Conclusion
CQRS offers a transformative approach to data management, bringing forth significant advantages in terms of performance, scalability, and code clarity. However, it’s not a silver bullet. Like all architectural decisions, adopting CQRS should be a measured choice, considering both its benefits and the challenges it introduces. For systems where scalability and performance are paramount, and where the trade-offs are acceptable, CQRS can be a game-changer, elevating the system’s robustness and responsiveness to new heights.
Published at DZone with permission of Pier-Jean MALANDRINO. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments