Orchestrating the Cloud: Increase Deployment Speed and Avoid Downtime by Orchestrating Infrastructure, Databases, and Containers
Learn about must-have features of cloud orchestration automation and walk through implementation methods for single cloud and cloud-agnostic scenarios.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Cloud Native: Championing Cloud Development Across the SDLC.
Simplicity is a key selling point of cloud technology. Rather than worrying about racking and stacking equipment, configuring networks, and installing operating systems, developers can just click through a friendly web interface and quickly deploy an application. Of course, that friendly web interface hides serious complexity, and deploying an application is just the first and easiest step toward a performant and reliable system.
Once an application grows beyond a single deployment, issues begin to creep in. New versions require database schema changes or added components, and multiple team members can change configurations. The application must also be scaled to serve more users, provide redundancy to ensure reliability, and manage backups to protect data. While it might be possible to manage this complexity using that friendly web interface, we need automated cloud orchestration to deliver consistently at speed.
There are many choices for cloud orchestration, so which one is best for a particular application? Let's use a case study to consider two key decisions in the trade space:
- The number of different technologies we must learn and manage
- Our ability to migrate to a different cloud environment with minimal changes to the automation
However, before we look at the case study, let's start by understanding some must-have features of any cloud automation.
Cloud Orchestration Must-Haves
Our goal with cloud orchestration automation is to manage the complexity of deploying and operating a cloud-native application. We want to be confident that we understand how our application is configured, that we can quickly restore an application after outages, and that we can manage changes over time with confidence in bug fixes and new capabilities while avoiding unscheduled downtime.
Repeatability and Idempotence
Cloud-native applications use many cloud resources, each with different configuration options. Problems with infrastructure or applications can leave resources in an unknown state. Even worse, our automation might fail due to network or configuration issues. We need to run our automation confidently, even when cloud resources are in an unknown state.
This key property is called idempotence, which simplifies our workflow as we can run the automation no matter the current system state and be confident that successful completion places the system in the desired state. Idempotence is typically accomplished by having the automation check the current state of each resource, including its configuration parameters, and applying only necessary changes. This kind of smart resource application demands dedicated orchestration technology rather than simple scripting.
Change Tracking and Control
Automation needs to change over time as we respond to changes in application design or scaling needs. As needs change, we must manage automation changes as dueling versions will defeat the purpose of idempotence. This means we need Infrastructure as Code (IaC), where cloud orchestration automation is managed identically to other developed software, including change tracking and version management, typically in a Git repository such as this example. Change tracking helps us identify the source of issues sooner by knowing what changes have been made. For this reason, we should modify our cloud environments only by automation, never manually, so we can know that the repository matches the system state — and so we can ensure changes are reviewed, understood, and tested prior to deployment.
Multiple Environment Support
To test automation prior to production deployment, we need our tooling to support multiple environments. Ideally, we can support rapid creation and destruction of dynamic test environments because this increases confidence that there are no lingering required manual configurations and enables us to test our automation by using it. Even better, dynamic environments allow us to easily test changes to the deployed application, creating unique environments for developers, complex changes, or staging purposes prior to production. Cloud automation accomplishes multi-environment support through variables or parameters passed from a configuration file, environment variables, or on the command line.
Managed Rollout
Together, idempotent orchestration, a Git repository, and rapid deployment of dynamic environments bring the concept of dynamic environments to production, enabling managed rollouts for new application versions. There are multiple managed rollout techniques, including blue-green deployments and canary deployments. What they have in common is that a rollout consists of separately deploying the new version, transitioning users over to the new version either at once or incrementally, then removing the old version. Managed rollouts can eliminate application downtime when moving to new versions, and they enable rapid detection of problems coupled with automated fallback to a known working version. However, a managed rollout is complicated to implement as not all cloud resources support it natively, and changes to application architecture and design are typically required.
Case Study: Implementing Cloud Automation
Let's explore the key features of cloud automation in the context of a simple application. We'll deploy the same application using both a cloud-agnostic approach and a single-cloud approach to illustrate how both solutions provide the necessary features of cloud automation, but with differences in implementation and various advantages and disadvantages. Our simple application is based on Node, backed by a PostgreSQL database, and provides an interface to create, retrieve, update, and delete a list of to-do items. The full deployment solutions can be seen in this repository.
Before we look at differences between the two deployments, it's worth considering what they have in common:
- Use a Git repository for change control of the IaC configuration
- Are designed for idempotent execution, so both have a simple "run the automation" workflow
- Allow for configuration parameters (e.g., cloud region data, unique names) that can be used to adapt the same automation to multiple environments
Cloud-Agnostic Solution
Our first deployment, as illustrated in Figure 1, uses Terraform (or OpenTofu) to deploy a Kubernetes cluster into a cloud environment. Terraform then deploys a Helm chart, with both the application and PostgreSQL database.
Figure 1. Cloud-agnostic deployment automation
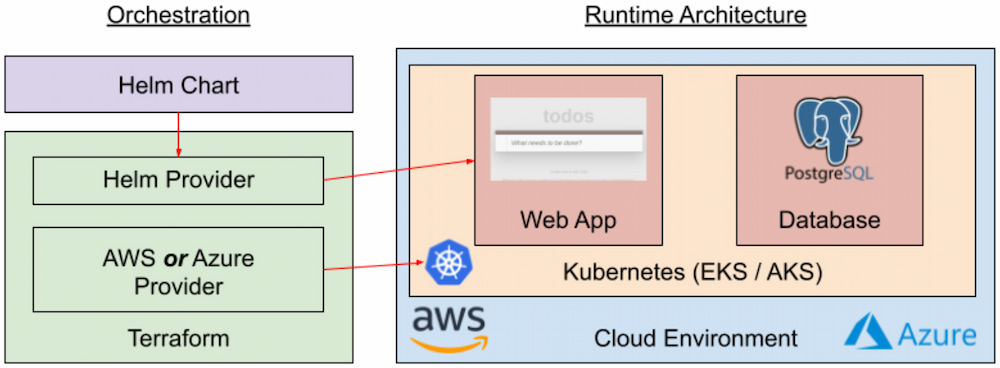
The primary advantage of this approach, as seen in the figure, is that the same deployment architecture is used to deploy to both Amazon Web Services (AWS) and Microsoft Azure. The container images and Helm chart are identical in both cases, and the Terraform workflow and syntax are also identical. Additionally, we can test container images, Kubernetes deployments, and Helm charts separately from the Terraform configuration that creates the Kubernetes environment, making it easy to reuse much of this automation to test changes to our application. Finally, with Terraform and Kubernetes, we're working at a high level of abstraction, so our automation code is short but can still take advantage of the reliability and scalability capabilities built into Kubernetes.
For example, an entire Azure Kubernetes Service (AKS) cluster is created in about 50 lines of Terraform configuration via the azurerm_kubernetes_cluster resource:
resource "azurerm_kubernetes_cluster" "k8s" {
location = azurerm_resource_group.rg.location
name = random_pet.azurerm_kubernetes_cluster_name.id
...
default_node_pool {
name = "agentpool"
vm_size = "Standard_D2_v2"
node_count = var.node_count
}
...
network_profile {
network_plugin = "kubenet"
load_balancer_sku = "standard"
}
}Even better, the Helm chart deployment is just five lines and is identical for AWS and Azure:
resource "helm_release" "todo" {
name = "todo"
repository = "https://book-of-kubernetes.github.io/helm/"
chart = "todo"
}However, a cloud-agnostic approach brings additional complexity. First, we must create and maintain configuration using multiple tools, requiring us to understand Terraform syntax, Kubernetes manifest YAML files, and Helm templates. Also, while the overall Terraform workflow is the same, the cloud provider configuration is different due to differences in Kubernetes cluster configuration and authentication. This means that adding a third cloud provider would require significant effort. Finally, if we wanted to use additional features such as cloud-native databases, we'd first need to understand the key configuration details of that cloud provider's database, then understand how to apply that configuration using Terraform. This means that we pay an additional price in complexity for each native cloud capability we use.
Single Cloud Solution
Our second deployment, illustrated in Figure 2, uses AWS CloudFormation to deploy an Elastic Compute Cloud (EC2) virtual machine and a Relational Database Service (RDS) cluster:
Figure 2. Single cloud deployment automation
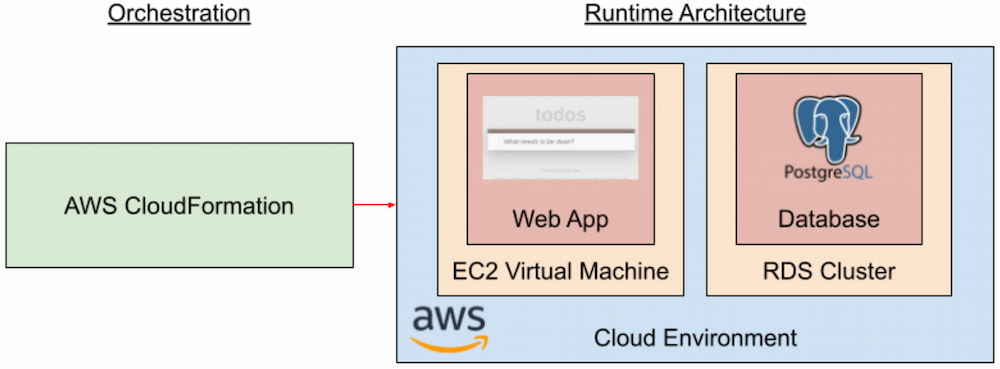
The biggest advantage of this approach is that we create a complete application deployment solution entirely in CloudFormation's YAML syntax. By using CloudFormation, we are working directly with AWS cloud resources, so there's a clear correspondence between resources in the AWS web console and our automation. As a result, we can take advantage of the specific cloud resources that are best suited for our application, such as RDS for our PostgreSQL database. This use of the best resources for our application can help us manage our application's scalability and reliability needs while also managing our cloud spend.
The tradeoff in exchange for this simplicity and clarity is a more verbose configuration. We're working at the level of specific cloud resources, so we have to specify each resource, including items such as routing tables and subnets that Terraform configures automatically. The resulting CloudFormation YAML is 275 lines and includes low-level details such as egress routing from our VPC to the internet:
TodoInternetRoute:
Type: AWS::EC2::Route
Properties:
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref TodoInternetGateway
RouteTableId: !Ref TodoRouteTableAlso, of course, the resources and configuration are AWS-specific, so if we wanted to adapt this automation to a different cloud environment, we would need to rewrite it from the ground up. Finally, while we can easily adapt this automation to create multiple deployments on AWS, it is not as flexible for testing changes to the application as we have to deploy a full RDS cluster for each new instance.
Conclusion
Our case study enabled us to exhibit key features and tradeoffs for cloud orchestration automation. There are many more than just these two options, but whatever solution is chosen should use an IaC repository for change control and a tool for idempotence and support for multiple environments. Within that cloud orchestration space, our deployment architecture and our tool selection will be driven by the importance of portability to new cloud environments compared to the cost in additional complexity.
This is an excerpt from DZone's 2024 Trend Report, Cloud Native: Championing Cloud Development Across the SDLC.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments