Circos: An Amazing Tool for Visualizing Big Data
Join the DZone community and get the full member experience.
Join For Freestoring massive amounts of data in a nosql data store is just one side of the big data equation. being able to visualize your data in such a way that you can easily gain deeper insights , is where things really start to get interesting. lately, i've been exploring various options for visualizing (directed) graphs, including circos . circos is an amazing software package that visualizes your data through a circular layout . although it's originally designed for displaying genomic data , it allows to create good-looking figures from data in any field. just transform your data set into a tabular format and you are ready to go. the figure below illustrates the core concept behind circos. the table's columns and rows are represented by segments around the circle. individual cells are shown as ribbons , which connect the corresponding row and column segments. the ribbons themselves are proportional in width to the value in the cell.
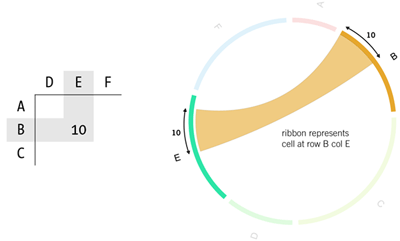
when visualizing a directed graph , nodes are displayed as segments on the circle and the size of the ribbons is proportional to the value of some property of the relationships. the proportional size of the segments and ribbons with respect to the full data set allows you to easily identify the key data points within your table. in my case, i want to better understand the flow of visitors to and within the datablend site and blog; where do visitors come from (direct, referral, search, ...) and how do they navigate between pages. the rest of this article details how to 1) retrieve the raw visit information through the google analytics api, 2) persist this information as a graph in neo4j and 3) query and preprocess this data for visualization through circos. as always, the complete source code can be found on the datablend public github repository .
1. retrieving your google analytics data
let's start by retrieving the raw google analytics data . the google analytics data api provides access to all dimensions and metrics that can be queried through the web application. in my case, i'm interested in retrieving the previous page path property for each page view. if a visitor enters through a page outside of the datablend website, the previous page path is marked as (entrance) . otherwise, it contains the internal path . we will use google's java data api to connect and retrieve this information. we are particularly interested in the pagepath , pagetitle , previouspagepath and medium dimensions, while our metric of choice is the number of pageviews . after setting the date range, the feed of entries that satisfy this criteria can be retrieved. for ease of use, we transform this data to a domain entity and filter/clean the data accordingly. if a visit originates from outside the datablend website, we store the specific medium (direct, referral, search, ...) as previous path.
// authenticate
analyticsservice = new analyticsservice(configuration.service);
analyticsservice.setusercredentials(configuration.client_username, configuration.client_pass);
// create query
dataquery query = new dataquery(new url(configuration.data_url));
query.setids(configuration.table_id);
query.setdimensions("ga:medium,ga:previouspagepath,ga:pagepath,ga:pagetitle");
query.setmetrics("ga:pageviews");
query.setstartdate(datestring);
query.setenddate(datestring);
// execute
datafeed feed = analyticsservice.getfeed(createqueryurl(date), datafeed.class);
// iterate and clean
for (dataentry entry : feed.getentries()) {
string pagepath = entry.stringvalueof("ga:pagepath");
string pagetitle = entry.stringvalueof("ga:pagetitle");
string previouspagepath = entry.stringvalueof("ga:previouspagepath");
string medium = entry.stringvalueof("ga:medium");
long views = entry.longvalueof("ga:pageviews");
// filter the data
if (filter(pagepath) && filter(previouspagepath) && (!clean(previouspagepath).equals(clean(pagepath)))) {
// check criteria are satisfied
navigation navigation = new navigation(clean(previouspagepath), clean(pagepath), pagetitle, date, views);
if (navigation.getsource().equals("(entrance)")) {
// in case of an entrace, save its medium instead
navigation.setsource(medium);
}
navigations.add(navigation);
}
}
2. storing navigational data as a directed graph in neo4j
the set of site navigations can easily be stored as a directed graph in the neo4j graph database . nodes are site paths (or mediums), while relationships are the navigations themselves. we start by retrieving the navigations for a particular date range and retrieve (or lazily create) the nodes representing the source and target paths (or mediums). next we de-normalize the pageviews metric (for instance, 6 individual relationships will be created for 6 page-views). although this de-normalization step is not really required, i did so to make sure that the degree of my nodes is correct if i would perform other types of calculations. for each individual navigation relationship, we also store the date of visit .
// retrieve navigations for a particular date
list navigations = retrieval.getnavigations(date);
// save them in the graph database
transaction tx = graphdb.begintx();
// iterate and create
for (navigation nav : navigations) {
node source = getpath(nav.getsource());
node target = getpath(nav.gettarget());
if (!target.hasproperty("title")) {
target.setproperty("title", nav.gettargettitle());
}
for (long i = 0; i < nav.getamount(); i++) {
// duplicate relationships
relationship transition = source.createrelationshipto(target, relationships.navigation);
transition.setproperty("date", date.gettime()); // save time as long
}
}
// commit
tx.success();
tx.finish();
3. creating the circos tabular data format
the circos tabular data format is quite easy to construct. it's basically a tab-delimited file with row and column headers. a cell is interpreted as a value that flows from the row entity to the column entity . we will use the neo4j cypher query language to retrieve the data of interest, namely all navigations that occurred within a certain time period . doing so allows us to create historical visualizations of our navigations and observe how visit flow behaviors are changing over time.
// access the graph database
graphdb = new embeddedgraphdatabase("var/analytics");
engine = new executionengine(graphdb);
// execute the data range cypher query
map params = new hashmap();
params.put("fromdate", from.gettime());
params.put("todate", to.gettime());
// execute the query
executionresult result = engine.execute("start sourcepath=node:index(\"path:*\") " +
"match sourcepath-[r]->targetpath " +
"where r.date >= {fromdate} and r.date <= {todate} " +
"return sourcepath,targetpath",
params);
next, we create the tab delimited file itself. we iterate through all entries (i.e. navigations) that match our cypher query and store them in a temporary list. afterwards, we start building the two-dimensional array by normalizing (i.e. summing) the number of navigations between the source and target paths. at the end, we filter this occurrence matrix on the minimal number of required navigations. this ensures that we will only create segments for paths that are relevant in the total population. as a final step, we print the occurrences matrix as a tab-delimited file. for each path, we will use a shorthand as the circos renderer seems to have problem with long string identifiers.
// retrieve the results
iterator> it = result.javaiterator();
list navigations = new arraylist();
map titles = new hashmap();
set paths = new hashset();
// iterate the results
while (it.hasnext()) {
map record = it.next();
string source = (string)((node) record.get("sourcepath")).getproperty("path");
string target = (string) ((node) record.get("targetpath")).getproperty("path");
string targettitle = (string) ((node) record.get("targetpath")).getproperty("title");
// reuse the navigation object as temorary holder
navigations.add(new navigation(source, target, targettitle, new date(), 1));
paths.add(source);
paths.add(target);
if (!titles.containskey(target)) {
titles.put(target, targettitle);
}
}
// retrieve the various paths
list pathids = arrays.aslist(paths.toarray(new string[]{}));
// create the matrix that holds the info
int[][] occurences = new int[pathids.size()][pathids.size()];
// iterate through all the navigations and update accordingly
for (navigation navigation : navigations) {
int sourceindex = pathids.indexof(navigation.getsource());
int targetindex = pathids.indexof(navigation.gettarget());
occurences[sourceindex][targetindex] = occurences[sourceindex][targetindex] + 1;
}
// matrix build, filter on threshold
for (int i = 0; i < occurences.length; i++) {
for (int j = 0; j < occurences.length; j++) {
if (occurences[i][j] < threshold) {
occurences[i][j] = 0;
}
}
// print
printcircosdata(pathids, titles, occurences);
the text below is a sample of the output generated by the printcircosdata method. it first prints the legend (matching shorthands with actual paths). next it prints the tab-delimited circos table.
link0 - /?p=411/wp-admin - storing and querying rdf data in neo4j through sail - datablend link1 - /?p=1146 - visualizing rdf schema inferencing through neo4j, tinkerpop, sail and gephi - datablend link2 - /?p=164 - big data / concise articles - datablend link3 - referral - null link4 - /?p=1400 - the joy of algorithms and nosql revisited: the mongodb aggregation framework - datablend ... datal0l1l2l3l4... l000000 l100000 l200000 l3059400197 l400000
4. use the circos power
although circos can be installed on your local computer, we will use its online version to create the visualization of our data. upload your tab-delimited file and just wait a few seconds before enjoying the beautiful rendering of your site's navigation information.
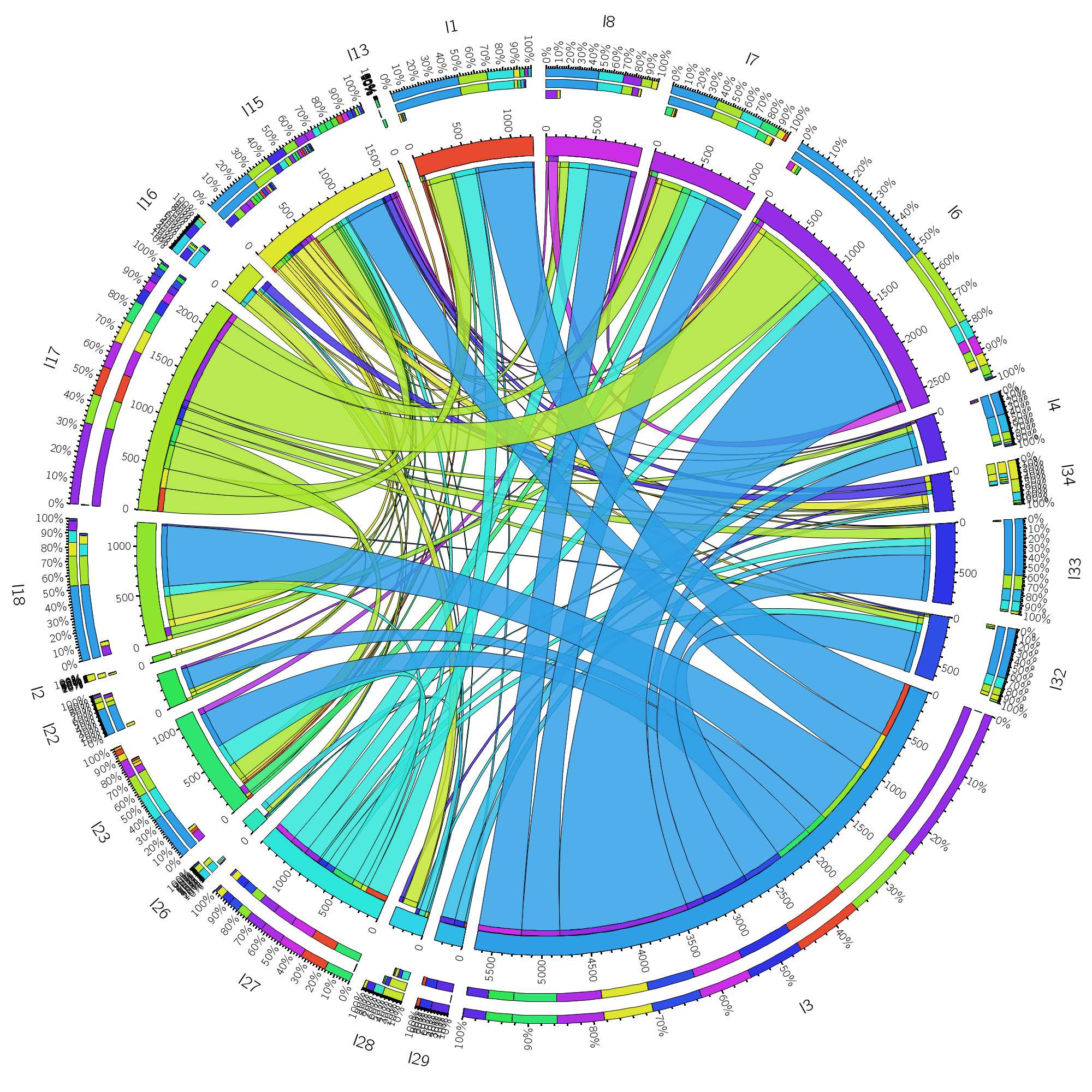
with just a glimpse of an eye we can already see that the l3-segment (i.e. the referrals) is significantly larger (almost 6000 navigations) compared to the others segments. the outer 3 rings visualize the total amounts of navigations that are leaving and entering this particular path. in case of referrals, no navigations have this path as target (indicated by the empty middle ring). its total segment count (inner ring) is entirely build up out of navigations that have a referral as source. the l6-segment seems to be the path that attracts the most traffic (around 2500 navigations). this segment visualizes the navigation data related to my "the joy of algorithms and nosql: a mongodb example" -article. most of its traffic is received through referrals, while a decent amount is also generated through direct (l17-segment) and search (l27-segment) traffic. the l15-segment (my blog's main page) is the only path that receives an almost equal amount of incoming and outgoing traffic.
with just a few tweaks to the circos input data, we can easily focus on particular types of navigation data. in the figure below, i made sure that referral and search navigations are visualized more prominently through the use of 2 separate colors.
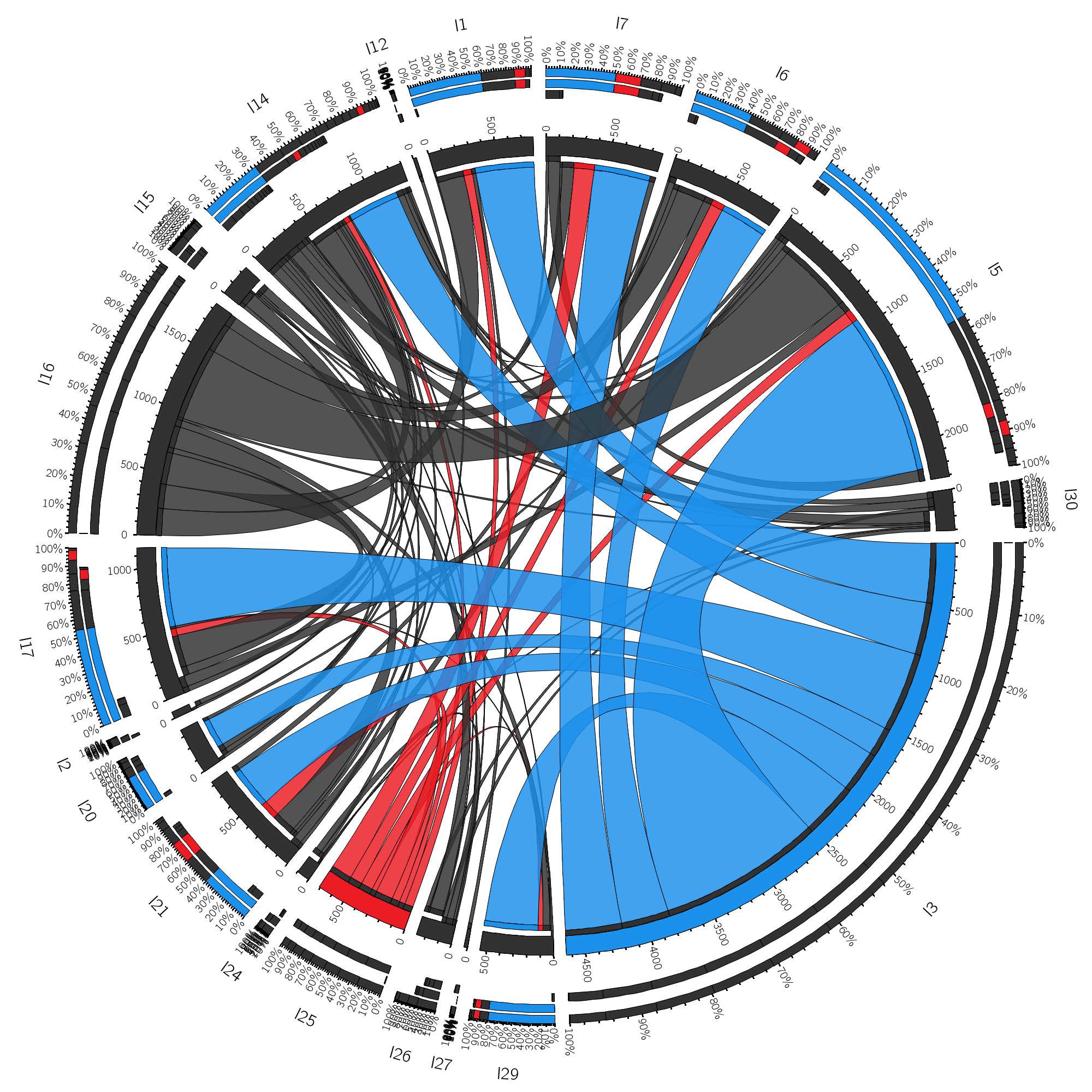
5. conclusions
in the era of big data, visualizations are becoming crucial as they enable us to mine our large data sets for certain patterns of interest. circos specializes in a very specific type of visualization, but does its job extremely well. i would be delighted to hear about other types of visualizations for directed graphs.
Published at DZone with permission of Davy Suvee, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments