Can Distributed Tracing Replace Logging?
This article compares observability frameworks, focusing on logging versus distributed tracing. Tracing has advantages and can address logging challenges.
Join the DZone community and get the full member experience.
Join For FreeMonitoring, Logging, and Tracing are often highlighted as the three fundamental pillars of a contemporary Observability framework. Conventional wisdom suggests that all three pieces of technology are equally critical and have their own place in the Observability stack. As more of the world shifts to the cloud, containerized, and distributed systems, will one of these pillars end up becoming more critical than the other?
We predict that this will most likely be the case. In this article, we compare the roles of two of these Observability pillars, Distributed Tracing vs. Logging, and see which best suits the needs of an increasingly cloud-native world.
Let's delve further into the topic, beginning with Logging.
Logging Is as Old as Programming Itself
Logs have been used since time immemorial to understand how the software works, track program flow, and root cause issues, if there are any. As software and infrastructure evolved, logs, too, have evolved to capture a variety of datasets.
Today, a log in a backend application can capture anything from request response data, error messages, and codes for error reporting, stack traces, metrics such as response times, custom log messages, and all the way up to business-specific events such as user activities and transactions. Different log platforms may also generate their own specific format of logs.
And therefore, lies a massive problem in a cloud-native distributed world.
Much of Logging Today Is Completely Unstructured
The fact that most logs are unstructured has both upsides and downsides. For one, it allows for flexibility and freedom to log any information that a developer feels is necessary. They are quick to implement (easy implementation code), efficient from a processing standpoint (processing or serialization is required to conform to a specific format), and generally easy to work with, given so many drop-in tools and frameworks.
In this example, the log file has captured an error scenario:
[2023-05-20 14:30:27] ERROR - Exception occurred while processing request: java.lang.NullPointerException: null pointer in method doSomething() at com.example.MyService.processRequest(MyService.java:123)- Timestamp: [2023-05-20 14:30:27] indicates the date and time when the error occurred.
- Log level: ERROR signifies that it's an error log entry.
- Message: Exception occurred while processing request: briefly describes the error.
- Exception Details: java.lang.NullPointerException: null pointer in the method doSomething() indicates the specific exception that was thrown; a NullPointerException occurred in the doSomething() method.
- Stack trace: at com.example.MyService.processRequest(MyService.java:123) shows the location in the code where the exception occurred.
However, there are many downsides to unstructured Logging. They have limited readability at large volumes. Poor searchability makes troubleshooting and debugging microservices time-consuming.
These problems compound as applications become more complex.

Structured Logs to the Rescue
The logical mitigation to this is where a log adheres to a predefined format or schema, aka structured data. This increases readability and searchability and makes the log suitable for automated analysis.
For instance, companies tend to standardize and create JSON formats with clearly defined keys and values so you can extract and analyze relevant information more easily.
The resulting data looks something like this, the exact same parameters passed as before but in clearly defined keys and values.
{
"timestamp": "2023-05-20T14:30:27Z",
"level": "ERROR",
"message": "Exception occurred while processing request",
"exception": {
"type": "java.lang.NullPointerException",
"message": "null pointer in method doSomething()",
"stackTrace": "at com.example.MyService.processRequest(MyService.java:123)"
}
}Structured log data greatly add to readability and searchability. When executed well, they bring down debug times massively. Companies like Elastic can also convert unstructured to structured logs during indexing and by using processes like Dynamic Mapping, where the datatype of each field is dynamically determined based on the content. However, this is not always 100%, given the variety of data and customization possible. Problems begin to surface at multiple levels - at a personnel level, at an organizational level, and at an industry level.
At a personnel level, the seamless adoption of standardized formats across teams is extremely challenging. Different teams across the entire app stack may use their own logging practices and monitoring systems or would have implemented different logging libraries during the initial scale-up phase. Retrofitting new logging mechanisms into legacy applications requires significant effort. Add training, dev., and ops teams to this new paradigm and the cost balloons.
At the org level, structured log files may require changes to the logging infrastructure. Traditional text-based log storage and analysis tools may not be optimized for structured log formats, requiring the adoption of new log management systems and/ or monitoring systems capable of efficiently handling structured log files. There's also this complexity of striking a balance between providing enough structure to make logs useful for analysis while allowing flexibility for different types of log entries.
At the industry level, Logging has been one of the biggest standardization challenges. The diversity of data types, use cases, and vendors makes this incredibly challenging. Yet, new projects are always coming up to promote consistent log formats and practices.

A project worth mentioning is the Logging for Cloud-Native Applications (LogCNCF) initiative. You can see the landscape of logging projects here. Projects like FluentD attempt to standardize data collection, unify Logging with structured JSON and make the architecture pluggable with data sources and outputs. However, we believe that adoption will take time and will most definitely not cover older, legacy technologies.
The question, then, is how is all this going to work itself out in this increasingly microservices architecture world?
Context Propagation: The Holy Grail
Modern applications talk to each other countless times. If a problem (logic bug or a performance issue) occurs in one service, it can have a cascading effect on other services. Request, response, version numbers, state, feature flag, and many such data points of connected services will be relevant while debugging issues.
However, logging today is inherently limited to gathering info only for that particular microservice that has been instrumented. Hence, understanding interdependencies and pinpointing the exact service or component causing the issue requires complex JOINS across multiple log files of multiple services.
Here's the challenge - to execute seamless JOINS, you need to context propagate across all peer services. Sounds great in theory but extremely difficult in practice. Here's a great thread on Twitter talking about this exact same problem.
There is, however, a great solution for this clear and present challenge.
The Most Powerful JOIN Statement in the Distributed World: Distributed Tracing
A distributed trace effectively enables a JOIN operation across the complete distributed transaction.
Here's a real-world example of context propagation for logs with tracing enabled:
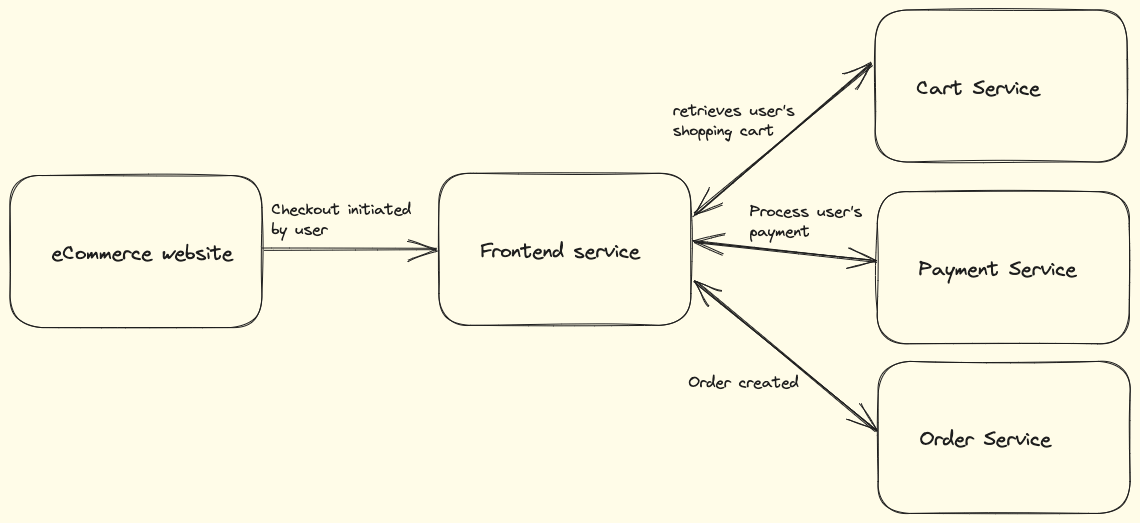
- Starting point: An e-commerce user initiates a checkout process by adding items to the shopping cart.
- Frontend service: The frontend service handles the user's request and generates a trace identifier to track the entire checkout process. The trace identifier is included in the log entries. Example log entry:
[2023-05-20 14:30:27|Trace ID: 1234567890] INFO - User initiated checkout process
User ID: 9876- Cart service: The frontend service communicates with the cart service to retrieve the user's shopping cart items. The trace identifier is propagated to the cart service. Example log entry in the cart service:
[2023-05-20 14:30:30|Trace ID: 1234567890] DEBUG - Retrieved cart items for user
User ID: 9876
Cart Items: [Item 1, Item 2, Item 3]- Payment service: The frontend service communicates with the payment service to process the user's payment. The trace identifier is passed to the payment service. Example log entry in the payment service:
[2023-05-20 14:30:35|Trace ID: 1234567890] INFO - Processing payment for user
User ID: 9876
Payment Amount: $100.00- Order service: After the payment is successfully processed, the frontend service communicates with the order service to create an order. The trace identifier is propagated to the order service. Example log entry in the order service:
[2023-05-20 14:30:40|Trace ID: 1234567890] INFO - Created order for user
User ID: 9876
Order ID: 54321Throughout the checkout process, the trace identifier is propagated across different services. This allows log entries to be correlated based on the trace identifier, enabling end-to-end tracing of a single user's journey across the entire architecture.
Now imagine doing this if tracing was not available. You'd need to do the following to get to some basic related data. TL;DR, THIS WON'T SCALE.
- Define a unique identifier: The frontend service needs to generate a unique identifier, e.g., checkout_id, for each checkout request and include it in the log entries. This approach requires manual handling of the header propagation in each service.
- Context passing via message queues: If you're using message queues for communication between services, you've to include checkout_id as a property in the messages. Each service that consumes the message can extract the checkout_id from the message properties and include it in its log entries. This approach ensures the checkout_id travels with the message and is available to downstream services.
- Service-level context storage: You can maintain a shared context storage system (e.g., a cache or database) accessible by all services involved in the checkout process. When the frontend service generates checkout_id, it can store it in this shared context storage system along with any other relevant information. Each service can then retrieve checkout_id from the shared storage system and include it in its log entries. This approach requires careful synchronization and management of the shared context storage system.
- Custom correlation via parsing logs: Extract and parse the checkout_id from log entries in each service and use custom log analysis techniques to correlate across log files. This approach involves writing code or using log analysis tools to search for log entries with matching checkout_id values and analyzing them together.
- Once any or all of this is executed, you can then perform a JOIN-like operation.
Tracing vs. Logging: Distributed Tracing Will Most Likely Subsume Logging in Most Organizations
Where data progression through logs relies heavily on manual instrumentation, tracing represents ease because it is completely automatic. As a result, standardization is a given. No wonder one of the most widely adopted standardization projects over the last few years has been Open Telemetry. Suddenly, information on peer services that are super relevant to debugging any issue (performance issues, exceptions, any non-200 response) for a given service becomes available to the developer.
A log will still be the fundamental unit for debugging; after all, they provide the final clue to the problem at hand. But they will be subsumed within a single tracing platform. Within this unified platform, users can visualize performance bottlenecks and request/response flows and track system errors without the need to switch between multiple user interfaces.

Unfortunately, Tracing Has Not Yet Been Widely Adopted, and for Good Reasons
First up, multiple applications need to be instrumented together. This can be time-consuming, especially in large codebases or when working with multiple languages or frameworks. On top of this, tracing generates a significant amount of spans that need to be collected, stored, and analyzed effectively. Since most vendors charge on the spans ingested, this presents a real headache for developers when it comes to debugging; which of these traces should be dropped, and which ones retained? As a result, various sampling techniques have come about that help with this very problem (This requires an article of its own). But this is all going to change.
The Future of Observability Is Bright!
The field of Observability, in general, and tracing, in particular, is continuously evolving. Hypothetically if these challenges associated with tracing are removed, we believe the world of Observability will forever change. Tracing will subsume Logging, visualization of incident propagation will become intuitive, and all related data for debugging will reside in a single platform. The possibilities, as a result, will have no bounds!
Published at DZone with permission of Varun Ramamurthy. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments