Building Resiliency With Effective Error Management
Learn different ways you can design and build tough systems with excellent error codes and handling.
Join the DZone community and get the full member experience.
Join For FreeBuilding resilient systems requires comprehensive error management. Errors could occur in any part of the system / or its ecosystem and there are different ways of handling these e.g.
- Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. – this is addressed through monitoring and redundancy. Redundancy in power, network, cooling systems, and possibly everything else relevant. Redundancy by building additional data centers
- Hardware - servers/storage hardware/software faults such as disk failure, disk full, other hardware failures, servers running out of allocated resources, server software behaving abnormally, intra DC network connectivity issues, etc. - Again the approach here is the same. Monitor the servers on various parameters and build redundancy. There are various High availability deployment patterns that are employed and with the advent of containerization bundled with the power of DevOps, more efficient patterns of solving this problem have also emerged.
Architects and designers of the systems need to take care of the availability aspects of their components while designing the system as per the business need and the cost implications. In today's world, cloud providers take care of the rest usually.
- Faults in Applications – Irrespective of whether the application is being deployed in the cloud or on-premise or irrespective of the technical stack of the application – this is something that is the responsibility of the individual application teams. Cloud deployments probably will help reduce the errors instances, some technical stacks could be more mature than the other ones but the errors will occur and these will need to be handled. With Microservices-based distributed architectures, it becomes even more interesting.
There are various steps in making applications resilient to faults:
- Minimizing the errors by applying alternate architectural/design patterns. For e.g. Asynchronous handling of user requests may help avoid situations of servers overloading and even provide a consistent experience to users.
- Graceful error handling by the application.
- Raise an incident if needed – The important part here is reliably raising an incident based on the need and not letting the user requests fall through the cracks. This is the fallback scenario for applications when they are not able to handle the errors. While this would be used to address the issues offline ( and applications may not choose this as a route always to solve the error at hand directly) even more importantly, this is a crucial step for offline analysis of errors and taking preventive steps against their recurring.
Brief Note on the Patterns
There are multiple architectural patterns to address the fault resiliency of applications and a lot depends on functional requirements and NFRs. The resiliency approach in terms of design also depends on the architectural paradigm of the application – if it is microservices-based, a good amount of focus would be on microservices integration dependency related errors. In events-based architectures, the focus would also be on reliability in terms of processing idempotency, data loss when things go wrong apart from normal error handling. In synchronous API-based applications, while applications can simply throw the error back to the caller some kind of monitoring/incident management could sometimes be useful if the problem lasts longer. In batch-based components, the focus could be on the ability to restart/resume a batch in an idempotent manner.
Application Error Handling
On the error handling part in the applications, a careful upfront thought as part of the design process is important. Even if the details are being left out for later but at a high level, an approach should be defined which again may vary depending on the use cases and design of the application.
Error Codes
How we define error codes is also an important part of error handling. There are no general conventions/guidelines on error codes and every application/system goes about its own way of defining error codes. However, error codes if given some thought and if standardized across the organization can help in a significant way. It's like having a common definition that everyone in the organization understands. Further, having error codes that are self-explanatory/intuitive can help in increased productivity during resolution, can help in offline analysis on for e.g. most occurring errors across systems, errors occurring during peak loads, systems that are most susceptible to a particular kind of errors, etc. and This can then go a long way in engineering taking some long term mitigation actions on such errors – This could even be a crucial metric in the overall DevOps of the organization.
Error Handling
Below is an example of how one can go about handling errors in an application that is based on events-based architecture. Some of the steps mentioned could vary for other architectural patterns.
Applications need to distinguish retryable errors from the non-retryable ones. If there is something wrong with the input message itself, usually, there is no point retrying on such an error unless there is a manual intervention. On the other hand, a problem with DB connectivity is worth retrying.

When applications are retrying on errors, they could choose a uniform configuration for retrying across all the retryable errors or they may want to fine-tune it with the help of “Error retry configuration”. For example, in the case of events-based services, a problem with the availability of an infrastructure component can be given more time to be remediated before retrying as opposed to let's say some temporary issue related to concurrency. At the very least, infrastructure errors are worth retrying for a higher duration. There is no point halting the retry of the current event and consuming new events if the basic infrastructure service unavailability itself will not allow to process those.
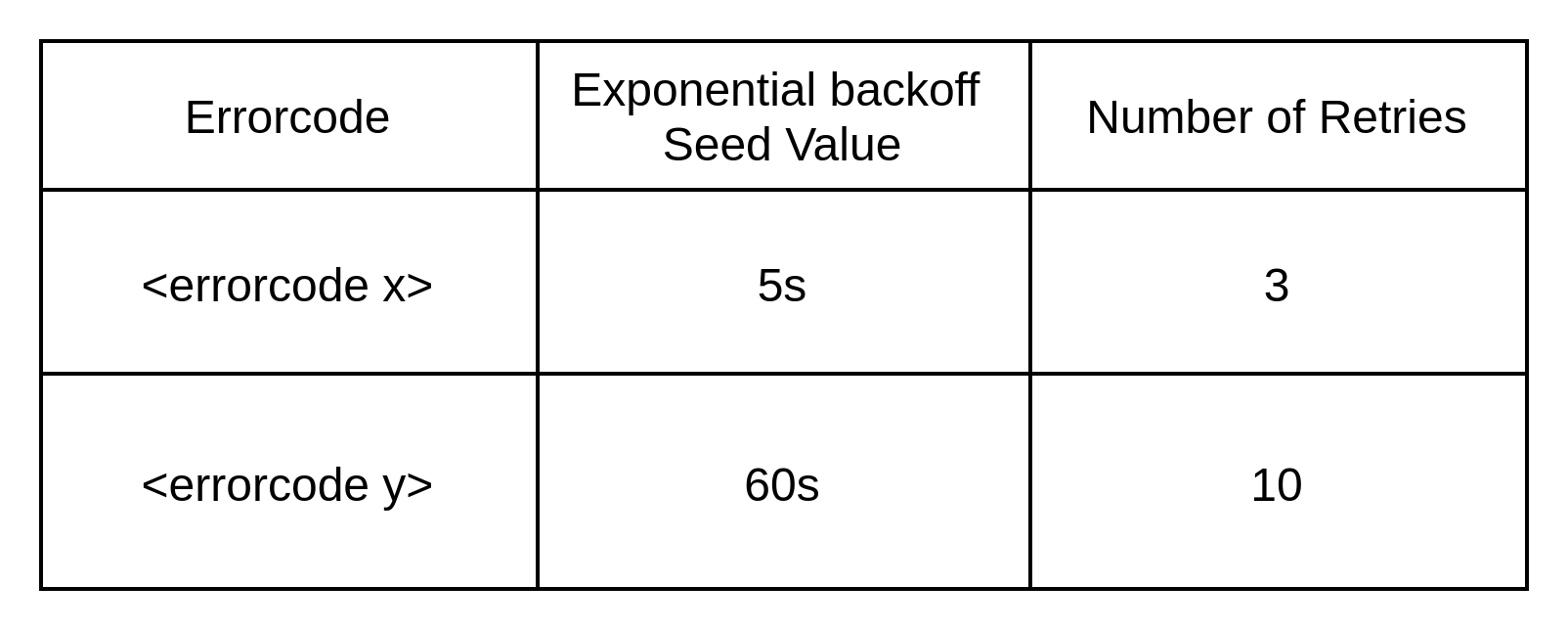
Raising Incidents
In the end, when all retries have failed, there needs to be a way to escalate the error and raise an incident whenever needed. There are cases where the problem can simply be thrown back to the user through notifications and it is upon that user to resubmit the needed request but that leads to a bad user experience if the problem was due to some internal technical issue. This is especially true in the case of events-based architectures. Asynchronous integration patterns usually make use of DLQ as another error handling pattern. However, DLQ is only a temporary step in the overall process. Whether through DLQ or by other means, if there is a way to reliably escalate the error so that it leads to the creation of an incident/dispatch of an operational alert, that would be a desirable outcome. How can we design such an integration with an incident management system/ alert management system? Here are a few options.
The first approach utilizes the logging feature which is available in all the applications and the least resistant and assured path to reporting an error. When an application is done with all the retries and it is trying to escalate an error, we need to try ad give it the most reliable path where there are fewer chances of error. Logging fits in well in that criteria. However, we want to separate out these logs from all other error logs otherwise the incident management system will be flooded with errors that may not be relevant. We call these logs “Error alerts” – Logging of these error alerts can be done by a dedicated library/component whose job is to format the error alert with the required and maximum amount of information and log it in the required format. An example would be:
{
"logType": "ErrorAlert",
"errorCode": "subA.compA.DB.DatabaseA.Access_Error",
"businessObjectId": "234323",
"businessObjectName": "ACCOUNT",
"InputDetails" : "<Input object/ event object>",
"InputContext" : " any context info with the input",
"datetime": "date time of the error",
"errorDetails" : "Error trace",
"..other info as needed": "..."
}These logs are read by a log aggregator (which would already be there due to the log monitoring stack most of the organizations employ). The log aggregator would route these logs to a different component whose action is to read these log events, read a configuration and raise incidents/ alerts as needed. There is again a DLQ handling needed here if things go wrong which will require monitoring and addressing.

The creation of an incident/ alert requires some configuration so that a meaningful and actionable incident can be created. Below is an example of the configuration attributes needed. This could be dependent on a specific indent management system employed by the organization. This configuration could also drive different kinds of actions. Given that the error codes follow a particular taxonomy across the organization, this could very well become a central configuration if needed.
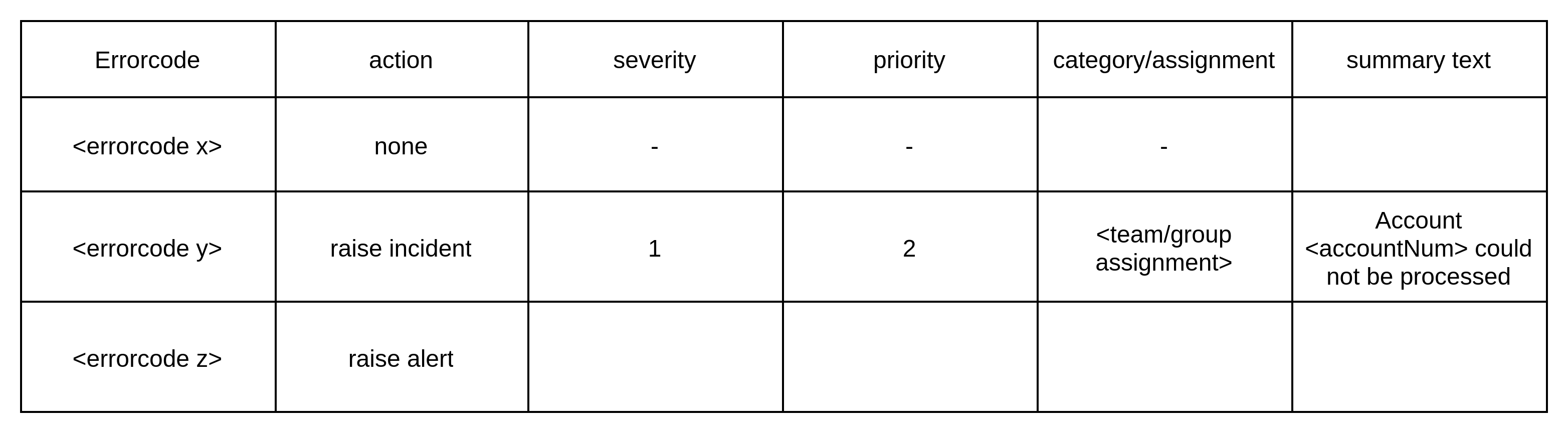
The second approach is similar but is based on DLQ.
Error alert dispatcher component writes to a DLQ instead of writing into logs. Everything else remains quite similar.

Which Approach Is Better?
A log-based approach is more resilient from an application point of view, but there are a few shortcomings as well:
1. More moving parts/integrations before the error reaches the incident management system. That will need to be handled.
2. Risk of log loss – That’s something that should be checked. If there is such a risk, then this approach is not a good one. In general, logs data criticality is not very high but if we are using it for raising incidents, then it would be good to check if it would be good to rely on that. In the implementation we went with, we realized that there was a risk of loss of logs data at peak volumes and hence we had to discard this approach but that may not be the case with all logging environments.
DLQ based approach has its own pros and cons:
1. The primary or possibly only con I see is the step of connecting to DLQ. Do we need some kind of DLQ over DLQ on some other messaging system as a redundancy? That chain could be endless. Depends on the criticality of data.
2. Another con could be the number of message routers that will need to connect to the central bus for dispatching the error alerts if we combine all the applications in the organization. Maybe some kind of federation would be needed but that’s where the solution starts getting a little complex with additional chances of error.
3. Rest everything looks okay. There are fewer components to integrate otherwise and with bus-based integration, there is higher reliability on the transmission of error alert events.
Conclusion
A holistic approach is needed to manage the errors and application error handling needs to be part of that. It needs to integrate seamlessly into the overall error/issue management of IT in the organization. While this write-up addresses integrating the application error handling into the incident management system, a similar approach would need to be applied for hardware issues as well. These all need to come together in a single place in an automated manner so that errors/issues can be further correlated and a single resolution can be applied to resolve all those.
Having said that, either of the approaches relies on the ability of the incident management system to integrate with modern technologies such as APIs or some kind of SDKs. This could differ from one platform to another. This is an important and key dependency for this to work. Another concern could be the creation of duplicate incidents, flooding the incident management system. That's something incident management systems should be providing out of the box as they are the master of the incident data. Solutions can be built around it to address this issue but that could be overly complicated and risky. Incident management systems are starting to address this problem through to support more and more intelligent deduplication of incidents.
Opinions expressed by DZone contributors are their own.
Comments