Privacy-Preserving AI: What It Is and Why It Matters?
AI solutions should be designed in such a way that they can learn without being able to identify individuals by name or other direct identifiers.
Join the DZone community and get the full member experience.
Join For FreeLet's start with an example; suppose your employer uses an AI system to analyze employee data and make decisions about hiring and promotion. In that case, there's a chance it could use your race or gender as one of its criteria features for making those decisions. If this happens without your knowledge or consent, especially if you don't agree with how they're being used, then there could be legal implications for both the company and the employees. This problem has been at least partially addressed by restricting access to certain types of sensitive information like faces and gender while still allowing access through other channels such as text search terms or GPS coordinates. However, these solutions still don't fully solve all privacy concerns since there will always be ways around them.
This problem has been at least partially addressed by restricting access to certain types of sensitive information like faces and gender while still allowing access through other channels such as text search terms or GPS coordinates, but these solutions still don't fully solve all privacy concerns since there will always be ways around them; someone could not take pictures without including any faces at all.
Why It Matters
Now imagine if Facebook had been able to use facial recognition software on all those photos uploaded over the years; they could easily build up an extensive database containing thousands upon thousands of faces without ever asking permission from any users. Likewise, a government agency or corporation could use an AI system like this one at airports or checkpoints without asking permission from anyone who might pass through those checkpoints or considering how many times we've seen companies like Facebook ask us for access so that "our friends" can see what we're doing (and vice versa). This is particularly concerning because many applications where users can share their data with friends and family members. In these cases, sharing personal information may be voluntary but still allow outsiders access due to default privacy settings in most apps that makes sensitive data available publicly by default or require affirmative action from users before making any changes (such as turning off location services).
What Can Be Done?
AI solutions should be designed in such a way that they can learn without being able to identify individuals by name or other direct identifiers. This is important because it ensures that your data remains anonymous and private while allowing the machine-learning algorithm to make accurate predictions. An example of this kind of AI system is one that predicts whether someone will be diagnosed with a specific disease in the future based on their genome sequence data. In this case, before making any predictions about an individual's likelihood of developing cancer or Alzheimer's disease based on their genetic makeup, all personal information should be removed from the dataset (e.g., names, religion, nationality, and so on). This allows researchers to study trends across large populations without compromising anyone's privacy. These types of systems are called "de-identified," meaning any information about the individuals in the dataset is removed before it is used. It is a privacy protection measure that allows researchers and other individuals with access to de-identified datasets to analyze the information without compromising the privacy of those represented within it. Now, de-identifying is not the same as anonymizing data: anonymized datasets may still contain indirect identifiers like zip codes, birthdates, or phone numbers, which could be used to identify individuals if they were linked together with other sources (such as census records). For example, your 10-digit mobile number may be changed with a different set of digits, but this would still be the same across the dataset.
Approaches for Making AI More Private and Secure
Differential Privacy
Differential privacy is a widely used technique for privacy-preserving ML. The goal of differential privacy is to protect the privacy of individual data points in a dataset by adding noise to the data. The noise is added to ensure that the ML model's output is not affected significantly. It involves adding a carefully calibrated amount of noise to the data, making it difficult to identify an individual's data. The amount of noise added to the data is determined by a parameter called epsilon. The higher the epsilon value, the more noise is added to the data and the greater the privacy protection. However, as the number of noise increases, the accuracy of the ML model decreases. Therefore, finding an optimal value for epsilon is crucial to achieving a balance between privacy and accuracy.
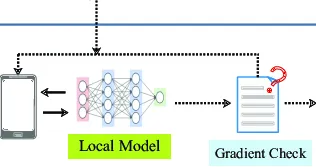
Federated Learning
Various applications have used Federated learning, including natural language processing, image classification, and recommendation systems. In addition, federated learning can be used in situations where data privacy is crucial and can also be used in situations where data is not easily transferable to a central location. For example, it can be used for training ML models on mobile devices, where users may not want to share their data with a central server.
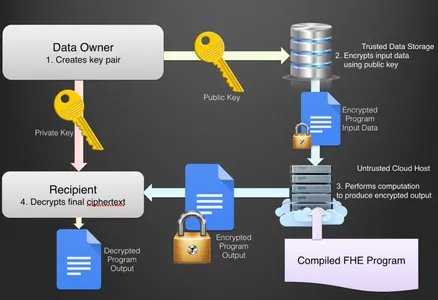
Homomorphic Encryption
Homomorphic encryption allows the system to perform operations on the encrypted data without decrypting it. This technique can be used to train ML models on encrypted data, ensuring that the data remains private. Homomorphic encryption can be applied to various ML models, including linear regression, decision trees, and neural networks. Encryption involves using mathematical operations on encrypted data without decrypting it. This technique is particularly useful when working with sensitive data that cannot be shared, such as medical records or financial data. However, homomorphic encryption is computationally expensive, which makes it less practical for some applications.
Libraries to Build Privacy-Preserving Models
Conclusion
Privacy is becoming an increasingly important concern in the field of AI. Fortunately, there are several techniques available for developing privacy-preserving models. Differential privacy, federated learning, and homomorphic encryption are just a few examples of these techniques. With the right approach, we can continue to make progress in the field of machine learning while also addressing privacy concerns.
I hope this article gives you a better understanding of why it is essential to have privacy-preserving systems and how best we can protect individual privacy while developing a more robust and advanced Artificial Intelligence system.
Opinions expressed by DZone contributors are their own.
Comments