Building a Product Recommendation Engine With Apache Cassandra and Apache Pulsar
How a hypothetical contractor accelerated AI with Apache Pulsar and Apache Cassandra. This article details important aspects of the journey to AI/ML.
Join the DZone community and get the full member experience.
Join For FreeThe journey to implementing artificial intelligence and machine learning solutions requires solving a lot of common challenges that routinely crop up in digital systems: updating legacy systems, eliminating batch processes, and using innovative technologies that are grounded in AI/ML to improve the customer experience in ways that seemed like science fiction just a few years ago.
To illustrate this evolution, let’s follow a hypothetical contractor who was hired to help implement AI/ML solutions at a big-box retailer. This is the first in a series of articles that will detail important aspects of the journey to AI/ML.
The Problem
It’s the first day at BigBoxCo on the “Infrastructure” team. After working through the obligatory human resources activities, I received my contractor badge and made my way over to my new workspace. After meeting the team, I was told that we have a meeting with the “Recommendations” team this morning. My system access isn’t quite working yet, so hopefully, IT will get that squared away while we’re in the meeting.
In the meeting room, it’s just a few of us: my manager and two other engineers from my new team, and one engineer from the Recommendations team. We start off with some introductions and then move on to discuss an issue from the week prior. Evidently, there was some kind of overnight batch failure last week, and they’re still feeling the effects of that.
It seems like the current product recommendations are driven by data collected from customer orders. With each order, there’s a new association between the products ordered, which is recorded. When customers view product pages, they can get recommendations based on how many other customers bought the current product alongside different products.
The product recommendations are served to users on bigboxco.com via a microservice layer in the cloud. The microservice layer uses a local (cloud) data center deployment of Apache Cassandra to serve up the results.
How the results are collected and served, though, is a different story altogether. Essentially, the results of associations between products (purchased together) are compiled during a MapReduce job. This is the batch process that failed last week. While this batch process has never been fast, it has become slower and more brittle over time. In fact, sometimes, the process takes two or even three days to run.
Improving the Experience
After the meeting, I checked my computer, and it looked like I could finally log in. As I’m looking around, our principal engineer (PE) comes by and introduces himself. I told him about the meeting with the Recommendations team, and he gave me a little more of the history behind the Recommendation service.
It sounds like that batch process has been in place for about ten years. The engineer who designed it has moved on; not many people in the organization really understand it, and nobody wants to touch it.
The other problem, I begin to explain, is that the dataset driving each recommendation is almost always a couple of days old. While this might not be a big deal in the grand scheme of things, if the recommendation data could be made more up-to-date, it would benefit the short-term promotions that marketing runs.
He nods in agreement and says he’s definitely open to suggestions on improving the system.
Maybe a Graph Problem?
At the onset, this sounds to me like a graph problem. We have customers who log on to the site and buy products. Before that, when they look at a product or add it to the cart, we can show recommendations in the form of “Customers who bought X also bought Y.” The site has this today in that the recommendations service does exactly this: It returns the top four additional products that are frequently purchased together.
But we’d have to have some way to “rank” the products because the mapping of one product to every other purchased at the same time by any of our 200 million customers is going to get big, fast. So, we can rank them by the number of times they appear in an order.
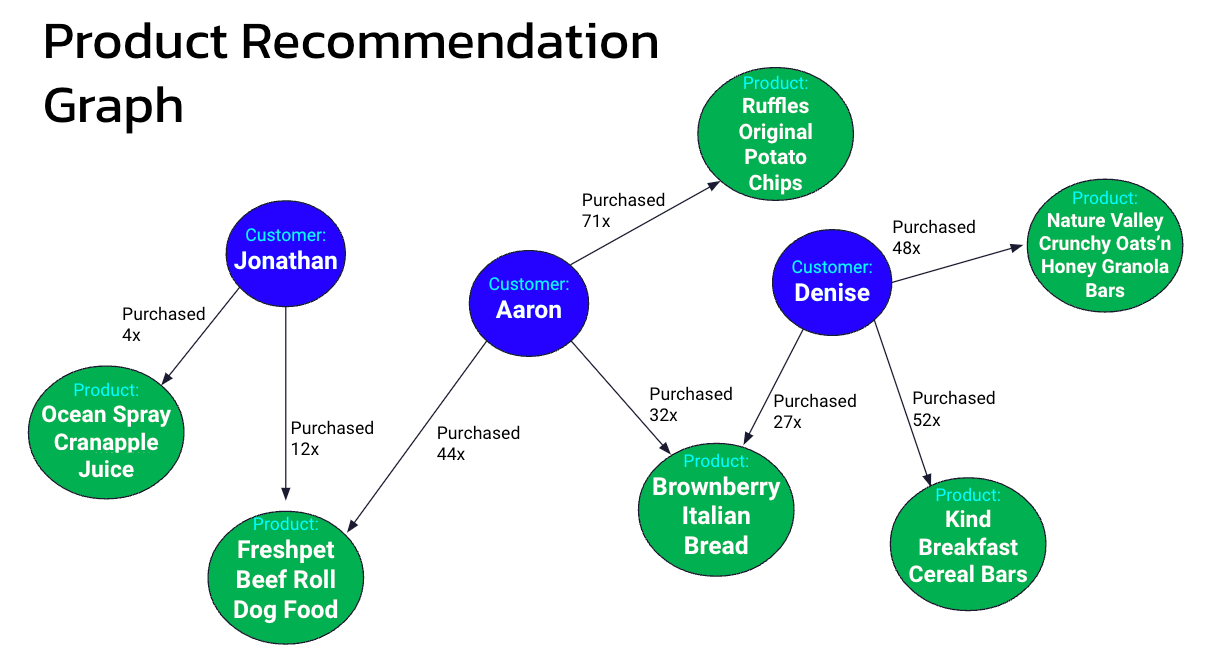
A product recommendation graph showing the relationship between customers and their purchased products.
After modeling this out and running it on our graph database with real volumes of data, I quickly realized that this wasn’t going to work. The traversal from one product to nearby customers to their products and computing the products that appear most takes somewhere in the neighborhood of 10 seconds. Essentially, we’ve “punted” on the two-day batch problem to have each lookup, putting the traversal latency precisely where we don’t want it: in front of the customer.
But perhaps that graph model isn’t too far off from what we need to do here. In fact, the approach described above is a machine learning (ML) technique known as “collaborative filtering.” Essentially, collaborative filtering is an approach that examines the similarity of certain data objects based on activity with other users, and it enables us to make predictions based on that data. In our case, we will be implicitly collecting cart/order data from our customer base, and we will use it to make better product recommendations to increase online sales.
Implementation
First of all, let’s look at data collection. Adding an extra service call to the shopping “place order” function isn’t too big of a deal. In fact, it already exists; it’s just that data gets stored in a database and processed later. Make no mistake: We still want to include the batch processing. But we’ll also want to process that cart data in real-time so we can feed it right back into the online data set and use it immediately afterward.
We’ll start out by putting in an event streaming solution like Apache Pulsar. That way, all new cart activity is put on a Pulsar topic, where it is consumed and sent to both the underlying batch database and to help train our real-time ML model.
As for the latter, our Pulsar consumer will write to a Cassandra table (shown in Figure 2) designed simply to hold entries for each product in the order. The product then has a row for all of the other products from that and other orders:
CREATE TABLE order_products_mapping (
id text,
added_product_id text,
cart_id uuid,
qty int,
PRIMARY KEY (id, added_product_id, cart_id)
) WITH CLUSTERING ORDER BY (added_product_id ASC, cart_id ASC);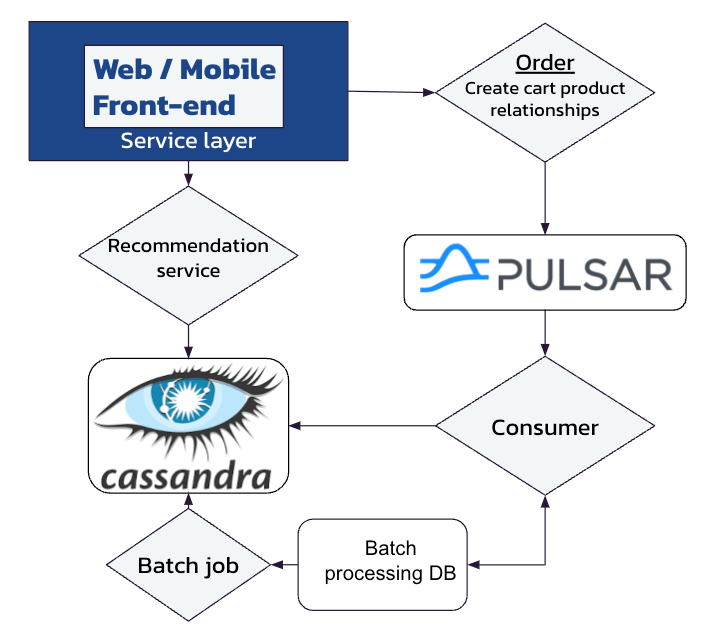
Augmenting an existing batch-fed recommendation system with Apache Pulsar and Apache Cassandra.
We can then query this table for a particular product (“DSH915” in this example), like this:
SELECT added_product_id, SUM(qty)
FROm order_products_mapping
WHERE id='DSH915'
GROUP BY added_product_id;
added_product_id | system.sum(qty)
------------------+-----------------
APC30 | 7
ECJ112 | 1
LN355 | 2
LS534 | 4
RCE857 | 3
RSH2112 | 5
TSD925 | 1
(7 rows)We can then take the top four results and put them into the product recommendations table, ready for the recommendation service to query by `product_id`:
SELECT * FROM product_recommendations
WHERE product_id='DSH915';
product_id | tier | recommended_id | score
------------+------+----------------+-------
DSH915 | 1 | APC30 | 7
DSH915 | 2 | RSH2112 | 5
DSH915 | 3 | LS534 | 4
DSH915 | 4 | RCE857 | 3
(4 rows)In this way, the new recommendation data is constantly being kept up to date. Also, all of the infrastructure assets described above are located in the local data center. Therefore, the process of pulling product relationships from an order, sending them through a Pulsar topic and processing them into recommendations stored in Cassandra happens in less than a second. With this simple data model, Cassandra is capable of serving the requested recommendations in single-digit milliseconds.
Conclusions and Next Steps
We’ll want to be sure to examine how our data is being written to our Cassandra tables in the long term. This way we can get ahead of potential problems related to things like unbound row growth and in-place updates.
Some additional heuristic filters may be necessary to add as well, like a “do not recommend” list. This is because there are some products that our customers will buy either once or infrequently, and recommending them will only take space away from other products that they are much more likely to buy on impulse. For example, recommending a purchase of something from our appliance division such as a washing machine is not likely to yield an “impulse buy.”
Another future improvement would be to implement a real-time AI/ML platform like Kaskada to handle both the product relationship streaming and to serve the recommendation data to the service directly.
Fortunately, we did come up with a way to augment the existing, sluggish batch process using Pulsar to feed the cart-add events to be processed in real time. Once we get a feel for how this system performs in the long run, we should consider shutting down the legacy batch process. The PE acknowledged that we made good progress with the new solution, and, better yet, that we have also begun to lay the groundwork to eliminate some technical debt. In the end, everyone feels good about that.
In an upcoming article, we’ll take a look at improving product promotions with vector searching.
Published at DZone with permission of Aaron Ploetz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments