Building a Data Pipeline Using QuestDB and Confluent Kafka
Let's dive into a tutorial on how to build a data pipeline using Confluent Kafka, QuestDB, and Python.
Join the DZone community and get the full member experience.
Join For FreeA data pipeline, at its base, is a series of data processing measures that are used to automate the transport and transformation of data between systems or data stores. Data pipelines can be used for a wide range of use cases in a business, including aggregating data on customers for recommendation purposes or customer relationship management, combining and transforming data from multiple sources, as well as collating/streaming real-time data from sensors or transactions.
For example, a company like Airbnb could have data pipelines that go back and forth between their application and their platform of choice to improve customer service. Netflix utilizes a recommendation data pipeline that automates the data science steps for generating movie and series recommendations. Also, depending on the rate at which it updates, a batch or streaming data pipeline can be used to generate and update the data used in an analytics dashboard for stakeholders.
In this article, you will learn how to implement a data pipeline that utilizes Kafka to aggregate data from multiple sources into a QuestDB database. Specifically, you will see the implementation of a streaming data pipeline that collates cryptocurrency market price data from CoinCap into a QuestDB instance where metrics, analytics, and further dashboards can be made.

Data Pipelines Using Kafka and QuestDB
Data pipelines are made up of a data source (e.g., applications, databases, or web services), a processing or transformation procedure (actions such as moving or modifying the data, occurring in parallel or in sequence with each other), and a destination (e.g., another application, repository, or web service).
The type or format of data being moved or transformed, the size of the data, and the rate at which it will be moved or transformed (batch or stream processing) are some other considerations you need to be aware of when building data pipelines. A data pipeline that only needs to be triggered once a month will be different from one made to handle real-time notifications from your application.
Apache Kafka is an open-source distributed event platform optimized for processing and modifying streaming data in real-time. It is a fast and scalable option for creating high-performing, low-latency data pipelines and building functionality for the data integration of high-volume streaming data from multiple sources. Kafka is a fairly popular tool used by thousands of companies.
QuestDB is a high-performance, open-source SQL database designed to process time-series data with ease and speed. It is a relational column-oriented database with applications in areas such as IoT, sensor data and observability, financial services, and machine learning. The database’s functionality is written in Java with a supported REST API and support for the PostgreSQL wire protocol and InfluxDB line protocol, allowing for multiple ways to ingest and query data in QuestDB.
Preparation
QuestDB can be installed using Docker, TAR files, or a package manager such as Homebrew. And Confluent offers a Kafka distribution, Confluent Platform, with add-ons that ease your data pipeline process and can be installed using Docker images or its downloaded TAR file.
Note: Confluent Platform is licensed separately from Apache Kafka. If you wish to use this setup in production environment, make sure to read through the Confluent Platform Licenses.
As for market data, you can utilize the CoinCap API to collate ETH market data. But there are also other streaming financial data resources.
All files used in the article are available in this GitHub repository. You can clone the repository to work through the steps directly:
git clone https://github.com/Soot3/coincap_kafka_questdb.git
Install QuestDB and Kafka
For the purpose of this article, you can install both using a Docker Compose file that creates the required Docker containers for the Kafka and QuestDB pipeline:
--- version: "3" services: zookeeper: image: confluentinc/cp-zookeeper:7.0.1 hostname: zookeeper container_name: zookeeper ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 broker: image: confluentinc/cp-server:7.0.1 hostname: broker container_name: broker depends_on: - zookeeper ports: - "9092:9092" - "9101:9101" environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181" KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092 KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1 KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 KAFKA_JMX_PORT: 9101 KAFKA_JMX_HOSTNAME: localhost KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081 CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092 CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1 CONFLUENT_METRICS_ENABLE: "true" CONFLUENT_SUPPORT_CUSTOMER_ID: "anonymous"kafka-connect: image: yitaekhwang/cp-kafka-connect-postgres:6.1.0 hostname: connect container_name: connect depends_on: - broker - zookeeper ports: - "8083:8083" environment: CONNECT_BOOTSTRAP_SERVERS: "broker:29092" CONNECT_REST_ADVERTISED_HOST_NAME: connect CONNECT_REST_PORT: 8083 CONNECT_GROUP_ID: compose-connect-group CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000 CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1 CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1 CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverterquestdb: image: questdb/questdb:latest pull_policy: always hostname: questdb container_name: questdb ports: - "9000:9000" - "8812:8812"
In sequential order, this Docker Compose file installs Confluent-managed Kafka tools, Zookeeper, and Kafka broker, which manage the connections and processes in the Kafka ecosystem. Then, it installs a JDBC Connector that will enable the connection between Kafka and any relational database such as QuestDB, this particular JDBC connector image is a custom connector created to simplify the connection between Confluent’s Kafka service and your Postgres database Finally, it installs the latest version of QuestDB.
You can set up Kafka and QuestDB by moving to the Docker directory and then running the Docker Compose file:
cd coincap_kafka_questdb/docker docker-compose up -d
The installation process should take a few minutes. You can check if the services are up and working with docker-compose ps. Once you see the connect container status as healthy your cluster will be ready to go.
Connect Kafka and QuestDB
At this point, your Kafka cluster and QuestDB instance are still unconnected, with no avenue to pass data between them. Using your installed connector, you can create this connection by setting the configuration settings for the connector:
{
"name": "postgres-sink-eth",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "topic_ETH",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"connection.url": "jdbc:postgresql://questdb:8812/qdb?useSSL=false",
"connection.user": "admin",
"connection.password": "quest",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "true",
"auto.create": "false",
"insert.mode": "insert",
"pk.mode": "none"
}
}
Here, you are setting the topic or topics that the connection monitors, the format for the message entries, and the authentication details for the connection. QuestDB then accepts admin and quest as user and password by default.
You can send this configuration to your installed connector using the following command:
curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" --data @postgres-sink-eth.json http://localhost:8083/connectors
When successfully executed, you should be able to see a response in JSON that includes the configuration above.
At this point, you have a connected QuestDB instance that will monitor the topic_ETH topic and pull any records sent to it for storage on the database. You can then create a table for the records on your database.
QuestDB has an interactive web console for that and can be accessed at localhost:9000. Here, you can query the data and generate some simple visualizations directly. Use the following command to create a table for your CoinCap records:
CREATE TABLE topic_ETH (`timestamp` timestamp, currency symbol, amount float)
This creates a formatted table for your records, the next step involves generating records that will be sent to this table.
Generate Market Data Using CoinCap API and Python
Using CoinCap’s API and some Python code, you can create a Kafka Producer that will generate data in real time:
# importing packages import time, json import datetime as dt import requests from kafka import KafkaProducer# initializing Kafka Producer Client producer = KafkaProducer(bootstrap_servers=['localhost:9092'], value_serializer=lambda x: json.dumps(x,default=str).encode('utf-8'))print('Initialized Kafka producer at {}'.format(dt.datetime.utcnow()))# Creating a continuous loop to process the real-time data while True: # API request uri = 'http://api.coincap.io/v2/assets/ethereum' res = requests.request("GET",uri)start_time = time.time() # Processing API response if successful if (res.status_code==200): # read json response raw_data = json.loads(res.content)# add the schema for Kafka data = {'schema': { 'type': 'struct', 'fields': [{'type': 'string', 'optional': False, 'field': 'currency' }, {'type': 'float', 'optional': False, 'field': 'amount' }, {'type': 'string', 'optional': False, 'field': 'timestamp'}], 'optional': False, 'name': 'Coincap', }, 'payload': {'timestamp': dt.datetime.utcnow(), 'currency': raw_data['data']['id'], 'amount': float(raw_data['data']['priceUsd'])}}print('API request succeeded at time {0}'.format(dt.datetime.utcnow()))producer.send(topic="topic_ETH",value=data)print('Sent record to topic at time {}'.format(dt.datetime.utcnow()))else: print('Failed API request at time {0}'.format(dt.datetime.utcnow()))end_time = time.time() time_interval = end_time - start_time # setting the API to be queried every 15 seconds time.sleep(15 - time_interval)
This Python code queries the CoinCap API in a continuous loop that generates the market price of ETH every 15 seconds. It then processes this data and sends it to the Kafka topic topic_ETH, where it can be consumed by QuestDB. The data schema and payload used here is just an example as it doesn’t utilize some QuestDB optimizations such as partitions.
You can run this code with the following commands:
# move back to the parent directory
cd ..
# Installing needed Python packages
pip install -r requirements.txt
# Run the python code
python producer.py
Note: If you are having issues installing the dependencies using the requirements.txt file, particularly if you are getting a Microsoft Visual C++ error, please check your Python version first. The Confluent-Kafka-Python package supports a few Python versions on Windows at the time of writing, specifically Python 3.7, 3.8, and 3.9. If you get an error that
librdkafka/rdkafka.his not found, you can try following the steps at this GitHub Issue. In our particular case with an Apple M1 we solved this problem by executing
brew install librdkafka
export LIBRARY_PATH=/opt/homebrew/Cellar/librdkafka/1.8.2/lib
export C_INCLUDE_PATH=/opt/homebrew/Cellar/librdkafka/1.8.2/include
pip3 install -r requirements.txt
With the producer script up and running, you will be collating ETH market prices every fifteen seconds, where this data will be sent to your Kafka topic. Your QuestDB instance then automatically updates its database with the data from the monitored Kafka topic. With this data pipeline and connection in place, your QuestDB instance will be populated with data at 15-second intervals.
Try running the following command a few times to observe the database updating itself from the Kafka topic:
SELECT * FROM 'topic_ETH'
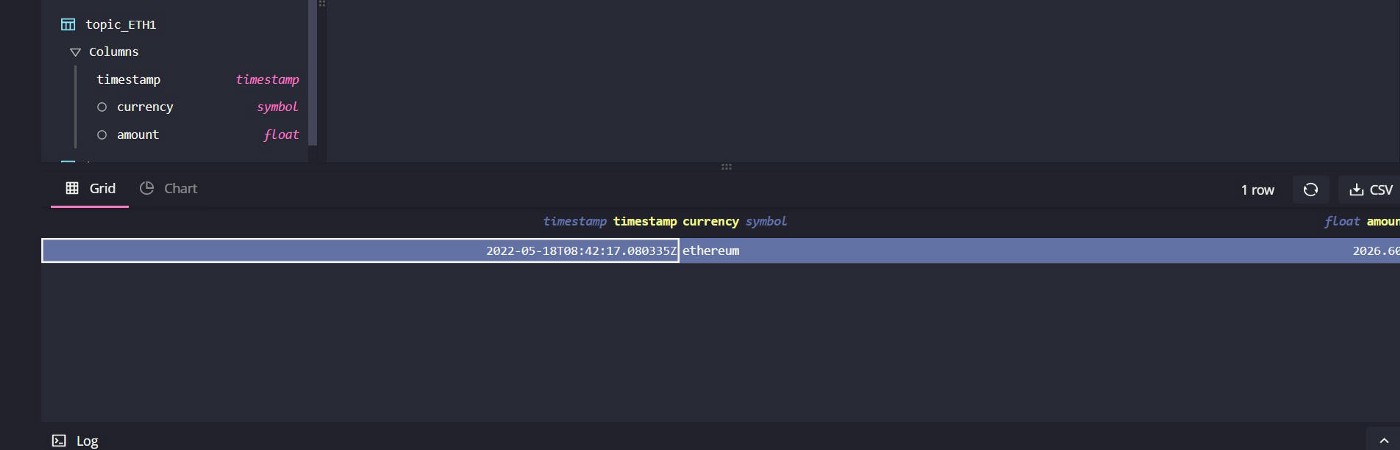
With the data on your QuestDB instance, you can query or modify it and even generate more records to be sent to other Kafka topics, creating materialized views and key performance indicators from your data.
Note: To take down the installed containers used in this article, move to the coincap_kafka_questdb/docker directory and run the following command:
docker-compose down
Conclusion
Data pipelines are a central consideration in the effective movement and transformation of data for your use. To efficiently collate raw data from where they are generated and transform this raw data into valuable insights, you need data pipelines.
In this article, you learned how to collate data with Kafka and implement a data pipeline that collects real-time ETH market data and stores data to QuestDB through Kafka connections.
QuestDB is an open-source SQL database with a focus on fast performance and ease of use. It is an optimized storage for high-volume time-series data, whether from your financial services or sensor applications, where time-series data are constantly being generated. It satisfies the need for high-performance ingestion and query times. Used in conjunction with Kafka, you can aggregate data from multiple sources, modify them, and store them for use at a constantly updating rate that fits your end user or application.
Published at DZone with permission of Sooter Saalu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments