Build Your First Neural Network With Eclipse Deeplearning4j
See how to build your first neural network.
Join the DZone community and get the full member experience.
Join For Free
in the previous article , we had an introduction to deep learning and neural networks. here, we will explore how to design a network depending on the task we want to solve.
there is indeed an incredibly high number of parameters and topology choices to deal with when working with neural networks. how many hidden layers should i set up? what activation function should they use? what are good values for the learning rate? should i use a classical multilayer neural network, a convolutional neural network (cnn), a recurrent neural network (rnn), or one of the other architectures available? these questions are just the tip of the iceberg when deciding to approach a problem with these techniques.
there are plenty of other parameters, algorithms, and techniques that you will have to guess and try before seeing some sort of decent result. unfortunately, there are no great blueprints for this. most of the time, experience from endless trial and error experiments can give you some useful hints.
however, one thing may be more clear than others: the input and output dimension and mapping. after all, the first (input) and last (output) layers are the interfaces of the network to the outside world, its api in a manner of speaking.
if you carefully designed these two layers and how the input and output of the training set will be mapped to them, well, you may keep your training set and reuse it as-is while changing so many other things, for instance:
- the number of hidden layers
- the kind of network
- activation functions
- learning rate
- tens of other parameters
- (but also) the programming language
- (and even) the deep learning library or framework
and i know i am probably missing some other things.
remember: whatever the problem is, you need to think about how to build the training set and the list of input and output pairs that should let the network learn and generalize a solution.
let's look at an example. a classical starting point is the mnist dataset, which is somehow considered a sort of "hello world" in the deep learning path. well, it's much more than this. it is like a reference example, against which you can test a new network paradigm or technique.
so what is this mnist? it is a dataset of 70,000 images of 28×28 pixels, representing handwritten 0-9 digits. 60,000 are part of the training set, which is the set used to train the network, while the remaining 10,000 are part of the test set, which is the set used to measure how the network is really learning (in fact this set, being excluded from the training, plays the role of a "third party judge").
inside this dataset, we'll find pairs of input (=images) and output (=0-9 classification) that may look like this:

however, as we have seen in the previous article, each input and output must be in a binary form when submitted to the network, not just for the training, but also in the testing phase.
so how can we transform the above samples (which are easily interpreted by a human being) into a binary pattern that fits well into a neural model?
well, we can find many ways to accomplish this task. let's examine one common way to do this.
first of all, we need to pay attention to the data type of our input and output data. in this case, we have images (that are two-dimensional matrixes) as input, while as output, we have a discrete value with just 10 chances.
it's pretty clear that, at least in this specific case, finding a pattern for the output is far easier than for the input, so we will start with the former.
a common way to map this kind of output in a binary pattern consists in using 10 nodes (n in general, where n is the number of possible output in a classification task) in the output layer, associate each one to a possible outcome and fire up just one of them, that is the one that corresponds to the outcome.
in this way, we have the following binary representation for each output

regarding the input, well, a very basic approach consists in "serializing" each row of the two-dimensional image matrix.
let's say, for example, we have a 3×3 image (this is simple just for focusing on the concept)

that we can represent with the following matrix

then we can map it into the 9-digit value 001010010.
back to mnist dataset, where each image is a 28×28 pixel image, we will have an input composed by 784 binary digits.
the dataset can be represented by a sequence of 70,000 rows, each one with 784 (input) + 10 (output) values.

out of these 70,000 items, we will have to take out a subset, e.g. 10,000, and use it for the test dataset, leaving the other 60,000 for the training set.
whatever machine learning framework you adopt, almost certainly you'll find mnist among the first examples. it is considered so fundamental that you'll find it packaged and organized to be used with just a few lines of code out-of-the-box.
this is very handy since it just works, no hassles!
but there may be a flaw with this approach. you may not see clearly how the dataset is made. in other words, you may have some difficulty when you decide to apply the same neural network used in mnist to a similar, but different, use case. let's say, for example, you have a set of 50×50 images to be classified in 2 categories. how do you proceed?
we will start from mnist images, but we'll see in detail how to transform them into a dataset.
since we are practical and want to see some code running, we have to choose a framework to do that. we will do it with deeplearning4j , a deep learning framework available for the java language.
in order to get your first mnist sample code running, you could just go to this page and copy and run this java code. there are two key-lines that are too concise to understand how exactly the training and test datasets were built.
datasetiterator mnisttrain = new mnistdatasetiterator(batchsize, true, rngseed);
datasetiterator mnisttest = new mnistdatasetiterator(batchsize, false, rngseed);in this tutorial, we will replace these with more detailed lines of code. so, you can generalize from this example and experiment with other datasets and maybe with your own images, which may not be 28×28 or maybe not event 0-9 digits!
in order to do so, we need to download the mnist images dataset. you can download it from several sources and formats, but here we have a hint.
if you look at some other java classes in the same github repository, for example here , in a comment, we read:
* data is downloaded from
* wget http://github.com/myleott/mnist_png/raw/master/mnist_png.tar.gz
* followed by tar xzvf mnist_png.tar.gzok, so let's download this and unzip somewhere, e.g. in /home/<user>/dl4j/, so we have the following situation:
as you can see, the dataset is split into two folders: training and testing, each one containing 10 subfolders, labeled 0 to 9, each one containing thousands (almost 6,000) of image samples of handwritten digits correspondent to the label identified by the subfolder name.
so, for instance, the training/0 subfolder shows something like this:

we are now ready to start working with eclipse: let's start it with a brand new workspace and create a new simple maven project (skip archetype selection).

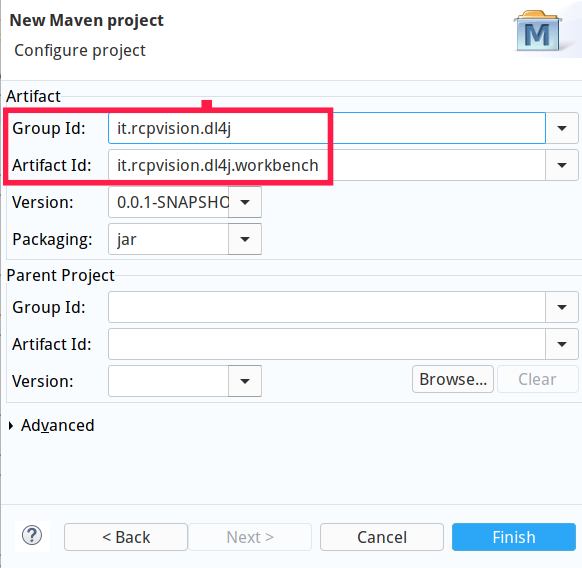
give it a group id and an artifact id , e.g. it.rcpvision.dl4j and it.rcpvision.dl4j.workbench.
now open file pom.xml and add a dependency to deeplearning4j and other needed libraries.
<dependencies>
<dependency>
<groupid>org.nd4j</groupid>
<artifactid>nd4j-native-platform</artifactid>
<version>1.0.0-beta4</version>
</dependency>
<dependency>
<groupid>org.deeplearning4j</groupid>
<artifactid>deeplearning4j-core</artifactid>
<version>1.0.0-beta4</version>
</dependency>
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-jdk14</artifactid>
<version>1.7.26</version>
</dependency>
</dependencies>then create a package called it.rcpvision.dl4j.workbench and a java class named mniststep1 with an empty main method.
in order to avoid doubts about imports of subsequent classes, here are the needed imports:
import java.io.file;
import java.io.ioexception;
import java.util.collections;
import java.util.list;
import java.util.random;import org.datavec.image.loader.nativeimageloader;
import org.deeplearning4j.datasets.iterator.impl.listdatasetiterator;
import org.deeplearning4j.nn.conf.multilayerconfiguration;
import org.deeplearning4j.nn.conf.neuralnetconfiguration;
import org.deeplearning4j.nn.conf.layers.denselayer;
import org.deeplearning4j.nn.conf.layers.outputlayer;
import org.deeplearning4j.nn.multilayer.multilayernetwork;
import org.deeplearning4j.nn.weights.weightinit;
import org.deeplearning4j.optimize.listeners.scoreiterationlistener;
import org.nd4j.evaluation.classification.evaluation;
import org.nd4j.linalg.activations.activation;
import org.nd4j.linalg.api.ndarray.indarray;
import org.nd4j.linalg.dataset.dataset;
import org.nd4j.linalg.dataset.api.iterator.datasetiterator;
import org.nd4j.linalg.dataset.api.preprocessor.imagepreprocessingscaler;
import org.nd4j.linalg.factory.nd4j;
import org.nd4j.linalg.learning.config.nesterovs;
import org.nd4j.linalg.lossfunctions.lossfunctions.lossfunction;
import org.slf4j.logger;
import org.slf4j.loggerfactory;let's define the constants we will use throughout the rest of the code:
//the absolute path of the folder containing mnist training and testing subfolders
private static final string mnist_dataset_root_folder = "/home/vincenzo/dl4j/mnist_png/";
//height and widht in pixel of each image
private static final int height = 28;
private static final int width = 28;
//the total number of images into the training and testing set
private static final int n_samples_training = 60000;
private static final int n_samples_testing = 10000;
//the number of possible outcomes of the network for each input,
//correspondent to the 0..9 digit classification
private static final int n_outcomes = 10;now, since we need to build two separate datasets (one for the training and another for the testing ) that work in the same way and that only differ from the data they contain, it makes sense to create a reusable method for both.
so, let's define a method with the following signature:
private static datasetiterator getdatasetiterator(string folderpath, int nsamples) throws ioexceptionthe first parameter is the absolute path of the folder (training or testing) that contains the 0..9 subfolders with the samples, while the second is the total number of sample images included in the folder itself.
in this method, we start by listing the 0..9 subfolders.
file folder = new file(folderpath);
file[] digitfolders = folder.listfiles();then, we create two objects that will help us translate each image into a sequence of 0..1 input values.
nativeimageloader nil = new nativeimageloader(height, width);
imagepreprocessingscaler scaler = new imagepreprocessingscaler(0,1);the first ( nativeimageloader ) will be responsible for reading the image pixels as a sequence of 0..255 integer values (where 0 is black and 255 is white — please note that each image has a white foreground and black background).
the second ( imagepreprocessingscaler ) will scale each of the above values in a 0..1 (float) range so that every 255 integer value will become 1.
then we need to prepare the arrays that will hold the input and output (remember, we are into a generic method that will handle both the training and testing set in the same way)
indarray input = nd4j.create(new int[]{ nsamples, height*width });
indarray output = nd4j.create(new int[]{ nsamples, n_outcomes });in this way, the input is a matrix with nsamples rows and 784 columns (the serialized 28×28 pixels of the image), while the output has the same number of rows (this dimension always matches between input and output), but 10 columns (the outcomes).
now it's time to scan each 0..9 folder and each image inside them, transform the image, and the correspondent label (the digit it represents) into floating 0..1 values and populate the input and output matrixes.
int n = 0;
//scan all 0..9 digit subfolders
for (file digitfolder : digitfolders) {
//take note of the digit in processing, since it will be used as a label
int labeldigit = integer.parseint(digitfolder.getname());
//scan all the images of the digit in processing
file[] imagefiles = digitfolder.listfiles();
for (file imagefile : imagefiles) {
//read the image as a one dimensional array of 0..255 values
indarray img = nil.asrowvector(imagefile);
//scale the 0..255 integer values into a 0..1 floating range
//note that the transform() method returns void, since it updates its input array
scaler.transform(img);
//copy the img array into the input matrix, in the next row
input.putrow( n, img );
//in the same row of the output matrix, fire (set to 1 value) the column correspondent to the label
output.put( n, labeldigit, 1.0 );
//row counter increment
n++;
}
}now, by composing the input and output matrixes, our method can build and return a datasetiterator that the network can use.
//join input and output matrixes into a dataset
dataset dataset = new dataset( input, output );
//convert the dataset into a list
list<dataset> listdataset = dataset.aslist();
//shuffle its content randomly
collections.shuffle( listdataset, new random(system.currenttimemillis()) );
//set a batch size
int batchsize = 10;
//build and return a dataset iterator that the network can use
datasetiterator dsi = new listdatasetiterator<dataset>( listdataset, batchsize );
return dsi;with this method available, we can now start using it with the main method in order to build the training dataset iterator.
long t0 = system.currenttimemillis();
datasetiterator dsi = getdatasetiterator(mnist_dataset_root_folder + "training", n_samples_training);now we can build the network, just as in the above mentioned deeplearning4j example in this github repository.
int rngseed = 123;
int nepochs = 2; // number of training epochs
log.info("build model....");
multilayerconfiguration conf = new neuralnetconfiguration.builder()
.seed(rngseed) //include a random seed for reproducibility
// use stochastic gradient descent as an optimization algorithm
.updater(new nesterovs(0.006, 0.9))
.l2(1e-4)
.list()
.layer(new denselayer.builder() //create the first, input layer with xavier initialization
.nin(height*width)
.nout(1000)
.activation(activation.relu)
.weightinit(weightinit.xavier)
.build())
.layer(new outputlayer.builder(lossfunction.negativeloglikelihood) //create hidden layer
.nin(1000)
.nout(n_outcomes)
.activation(activation.softmax)
.weightinit(weightinit.xavier)
.build())
.build();here, we have a simple, fully-connected network with one hidden layer containing 1000 nodes.
then the network can be trained using our brand new training dataset iterator (dsi).
multilayernetwork model = new multilayernetwork(conf);
model.init();
//print the score with every 500 iteration
model.setlisteners(new scoreiterationlistener(500));
log.info("train model....");
model.fit(dsi, nepochs);after this phase (which may take quite a while), we can reuse our method to build the testing set iterator and evaluate this set while printing some statistics about how now the network performs over the testing set.
datasetiterator testdsi = getdatasetiterator( mnist_dataset_root_folder + "testing", n_samples_testing);
log.info("evaluate model....");
evaluation eval = model.evaluate(testdsi);
log.info(eval.stats());
long t1 = system.currenttimemillis();
double t = (double)(t1 - t0) / 1000.0;
log.info("\n\ntotal time: "+t+" seconds");as we can see in the following image, we can reach an accuracy of 97% even with an extremely simple network.
less than one and a half minutes for a complete training and testing phase (all included); not bad!

Published at DZone with permission of Vincenzo Caselli, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments