Build an Automated Product Classifier Using Open Source Tools and Amazon SageMaker
Discuss the process of developing an automated product classifier using a pre-trained machine learning (ML) model, Hugging Face, and Amazon SageMaker.
Join the DZone community and get the full member experience.
Join For FreeThis article was authored by AWS Sr. Developer Advocate Mohammed Fazalullah Qudrath and AWS Solutions Architect Saubia Khan, and published with permission.
In the world of e-commerce, product reviews are essential for fostering client trust and loyalty. However, manually reading through tens of thousands of user evaluations to identify recurring themes and sentiments may be a time-consuming and daunting endeavor. Here comes the role of automatic product classifiers. Using machine learning techniques, an automated product classifier may categorize user reviews based on specified categories or feelings.
In this blog article, we will discuss the process of developing an automated product classifier using a pre-trained machine learning (ML) model, Hugging Face, and Amazon SageMaker. The automated product classifier will read user reviews to evaluate if they could be valuable to other users. We will examine the advantages of this method and present a step-by-step tutorial for constructing your own automatic product classifier.
How Do You Define a "Useful" Product Review?
If you visit an online retail website and look at a product, you’ll see reviews of that product from people who have bought it. On Amazon.com, for example, reviewers can rate the product out of 5 stars and leave a comment about it. Other users of the site can read these reviews and highlight if they found the review useful.
The precise definition of a "useful" review varies according to your needs, but in this case, we are looking for information that will provide genuine insights into the product. For example, does the review tell you why they liked the product? Does the product work as expected? Is it good quality or did it fall apart on the first day? Was it packaged properly? This is the kind of information that adds value and helps a potential customer to decide whether to buy the item or not, and it becomes especially relevant when there is a wide range of similar products available.
Conversely, comments that are not useful to a potential purchaser might focus on issues unrelated to the actual product — the product arrived late because of the weather, or did the wrong item get delivered, or may simply be an irrelevant comment.
Also, as the number of online reviews grows, it becomes increasingly challenging to manually check each review to understand the customer sentiment and provide relevant recommendations. Therefore, automating the review classification process using Natural Language Processing (NLP) and ML is becoming a necessity.
We’re going to build and train a machine-learning model that reads text reviews and is able to determine if that review would be useful to other users. We will use a pre-trained model from Hugging Face, the dataset will be from AWS Data Exchange, and the model will be tuned and deployed on Amazon SageMaker. We chose Hugging Face because it is developer-focused, user-friendly, and provides documentation to help guide developers in integrating the models for APIs and other use cases.
Why Use a Pre-Trained Model?
Building a model that can read and understand text contents and recognize or generate images requires vast quantities of data, computing power, and time. Using a pre-trained model reduces infrastructure costs, lowers the carbon footprint, and saves time on training by using transfer learning by leveraging models that have already been trained on a specific task. Hugging Face makes this process convenient and accessible, as you will soon find out.
In this example, we are using a framework on Hugging Face to train the model and then deploy it using Amazon SageMaker, which helps you build, train, and deploy ML models for any use case with fully managed infrastructure, tools, and workflows.
We downloaded the *Helpful Sentences from Reviews* dataset from the AWS Data Exchange, which contains more than 100 petabytes of high-value, cloud-optimized datasets that have been made available for public use from organizations such as NOAA, NASA, and the UK Met Office.
The dataset is downloaded in two files (train.json and test.json) and contains data such as the sentence, image, text, and the helpful score.
Data Prep
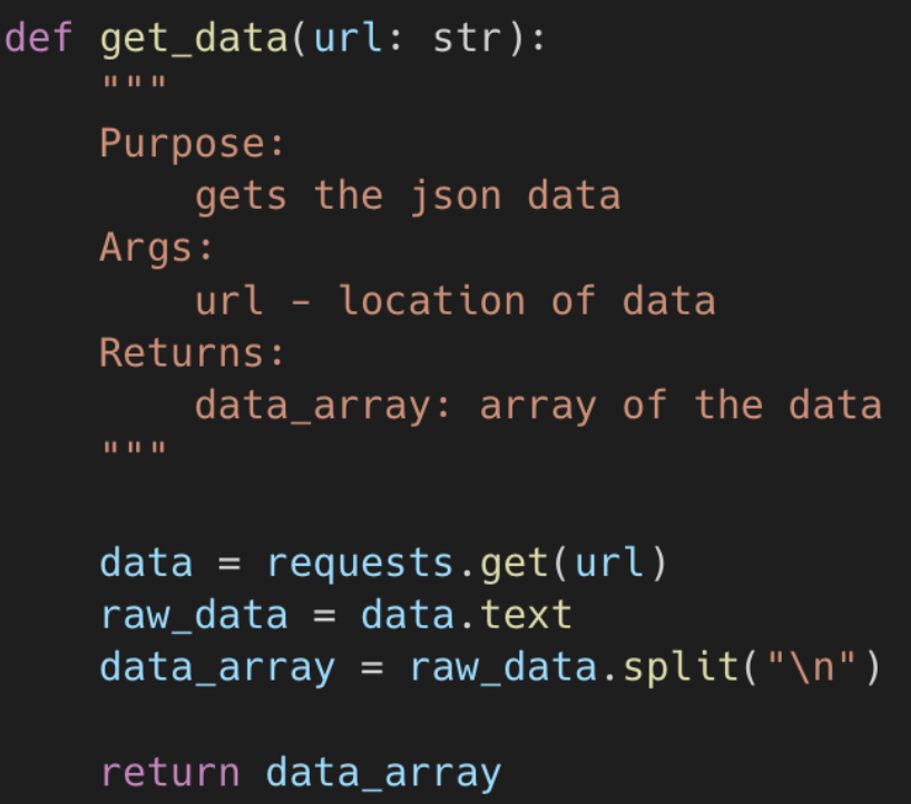
Using a basic GET request, we first retrieve the data.

The JSON data are, however, in an unsuitable format for tuning the pre-trained model.
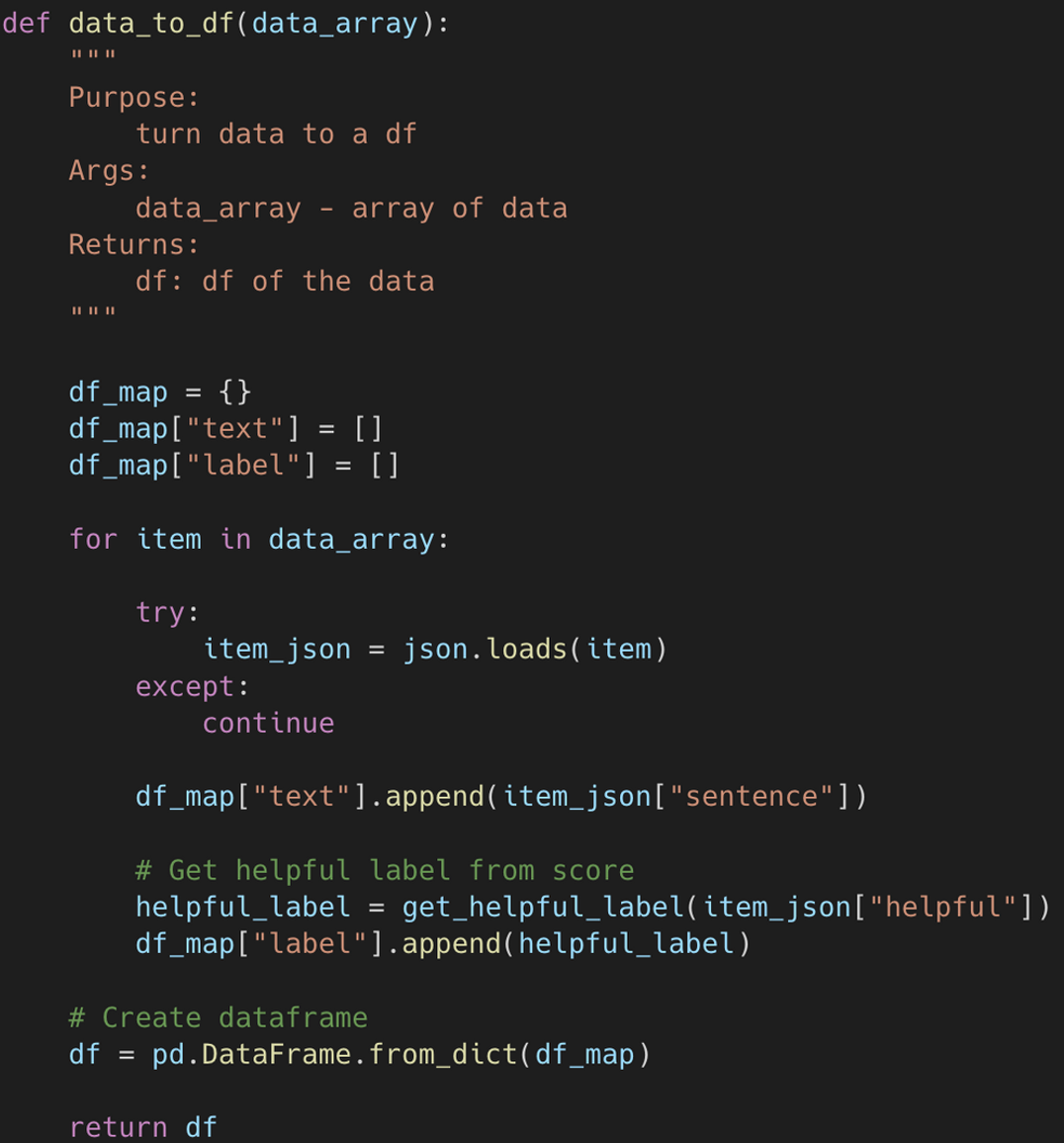
Therefore, we simply transform the data into individual arrays and convert them to CSV format.

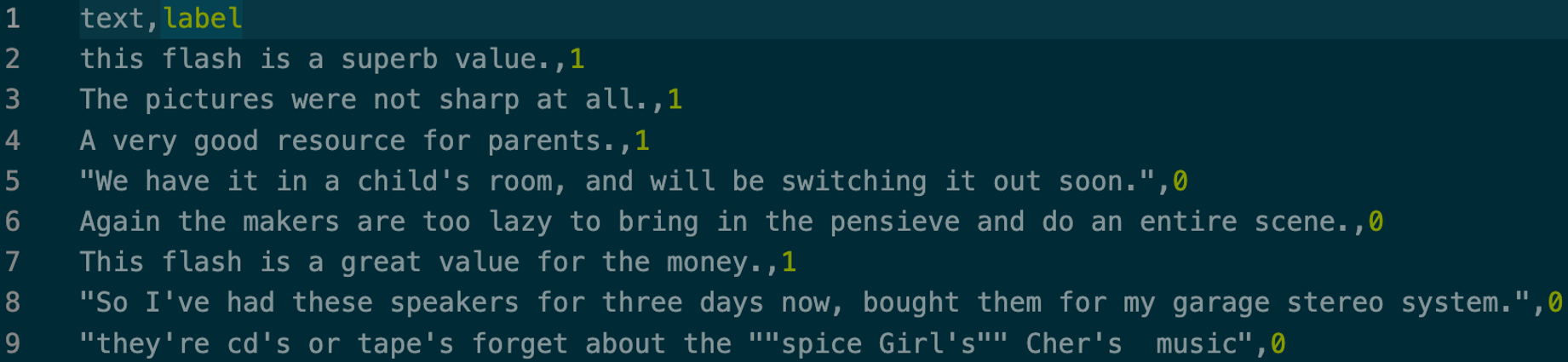
As this is a classification issue, we require a label indicating whether or not this review is useful. Given that the scores range from 0.3 to 1.7 and are of a numeric nature, it is necessary to normalize them between 0 (Not Helpful) and 1 (Helpful).

Model Training
Recall that Hugging Face provides a developer's first experience. It uses PyTorch and TensorFlow underneath the hood to make, for example, training a simple classifier easier. To train our classifier with the dataset, we have just created, we are leveraging the pre-trained model BERT, a state-of-art model for NLP-related tasks. The process of retraining a pre-trained model on a dataset specific to your task is also known as transfer learning.
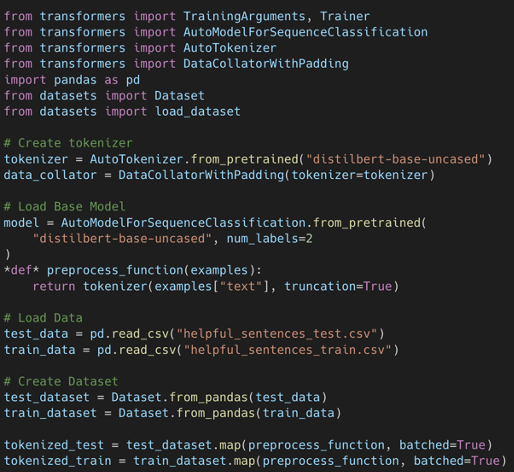
When training a model locally, you would define metrics for your training job as well as generate checkpoints every so many epochs. For instance, every 500 epochs, you will save the output of the model for testing purposes. On a local machine, this process becomes time-consuming and leads to overheating your local machine. If you had several datasets with different types of data processing and transformations, it is not scalable. This is where Amazon SageMaker comes in.
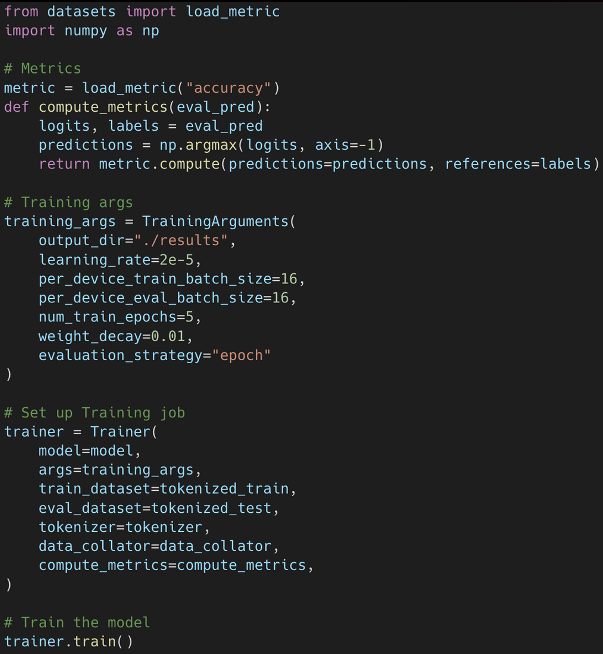
Amazon SageMaker provides several tools, particularly for model training and deployment, that reduces training time from weeks to hours with further optimized infrastructure. We can choose from several CPU or GPU options for training, and then Amazon SageMaker will take care of creating and managing training jobs. In addition, once the training job is completed, SageMaker will eliminate the infrastructure on your behalf.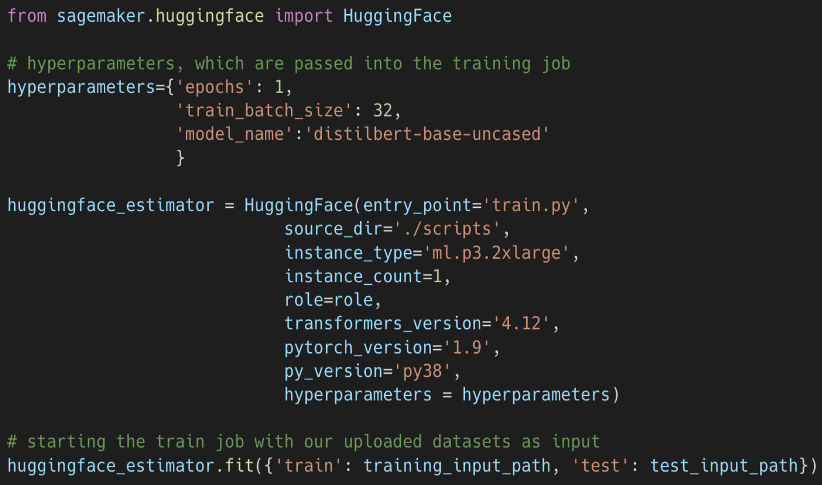
Model Evaluation
Once training is complete, we can evaluate the model. Hugging Face provides a framework that enables the utilization of dozens of prominent metrics. This facilitates the evaluation, comparison, and reporting of model performance. For our classifier, we will incorporate measures such as F1 score and precision directly into the training pipeline. This allows us to monitor the model's performance as it is being trained.
Model Deployment
Hugging Face Hub offers sample code for target deployment choices, such as Amazon SageMaker. The code enables users to identify what is utilized, train the model, and create an inference-capable SageMaker endpoint.
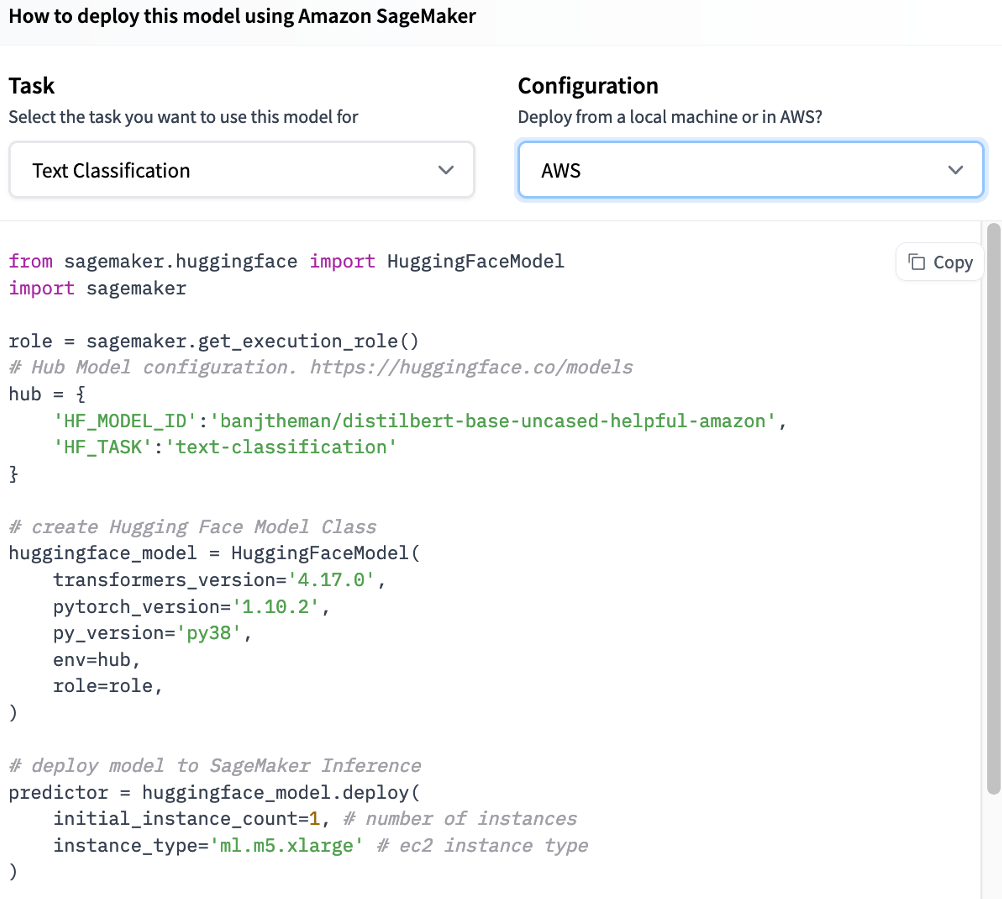
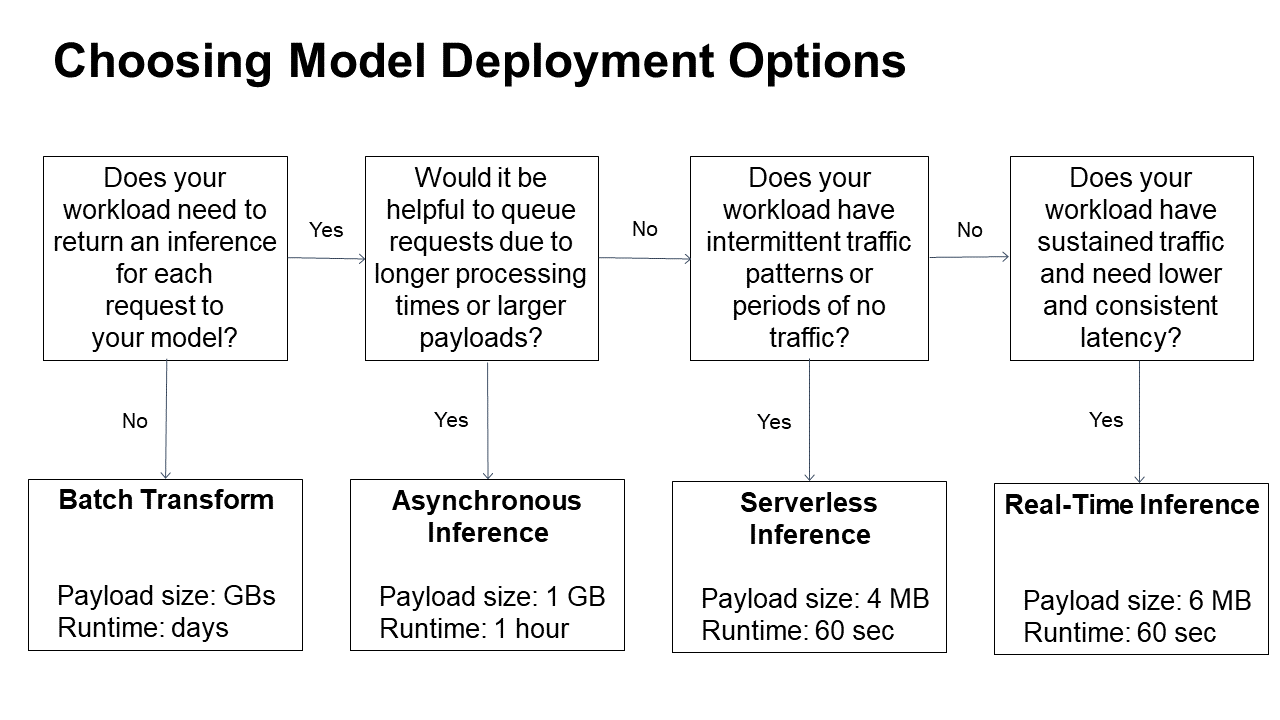
 Amazon SageMaker inference offers four options for deployment:
Amazon SageMaker inference offers four options for deployment:
- Real-time inference: This is one of the most popular and is ideal for workloads that require real-time, sub-second, low-latency, autoscaling, and GPU and CPU support. This option is ideal for A/B testing and interactive workloads.
- Batch transform: This is suitable for large batches of data that have no real-time requirement and no persistent endpoint. This means the processing can take place outside busy hours, such as overnight, to save money.
- Asynchronous inference: This inference method operates in near real-time and can process large 1GB+ payloads. It can handle long timeouts (15 minutes) and saves costs by auto-scaling inferences when there are no incoming requests.
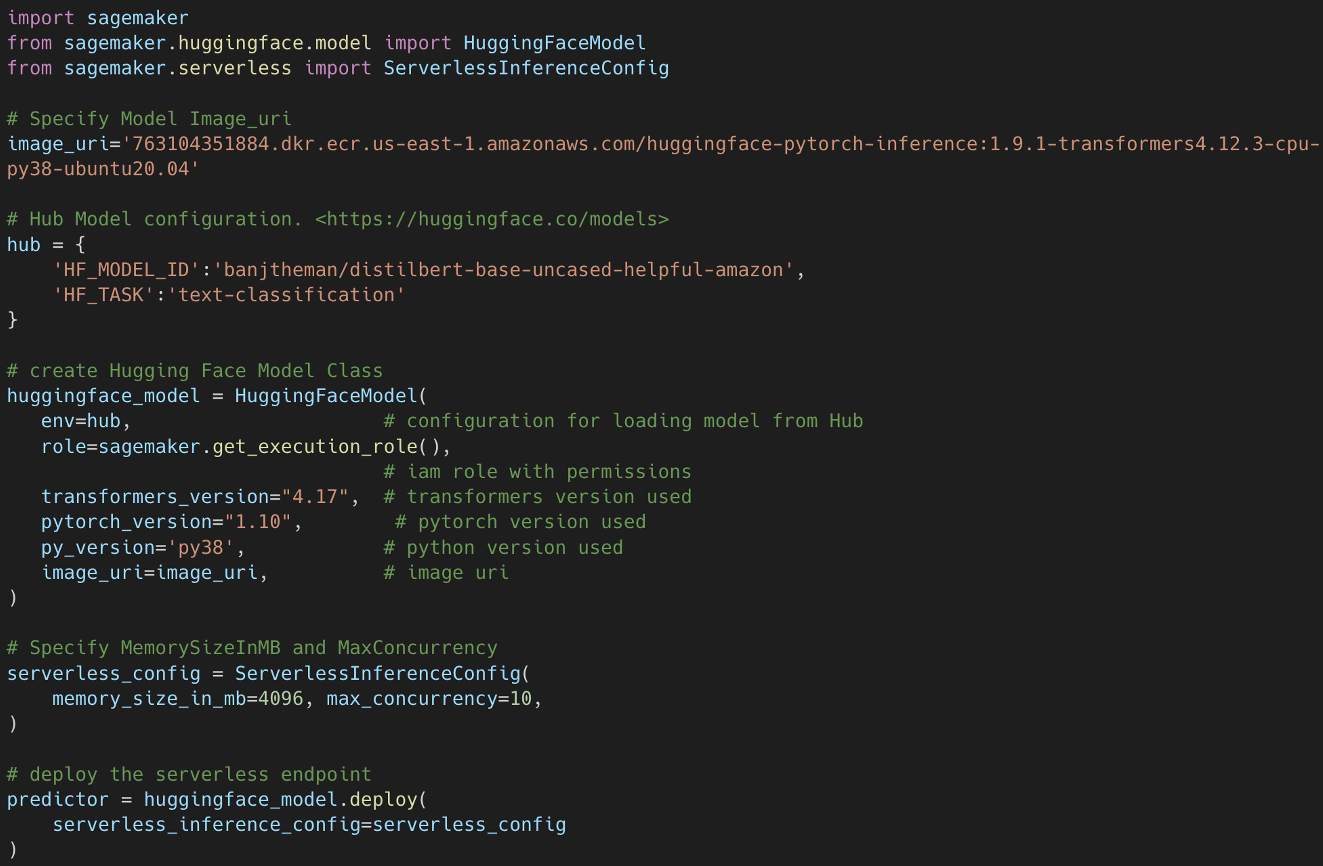
- Serverless inference: This is the latest offering and was introduced in 2022. Serverless inference auto-scales infrastructure depending on traffic, so users only pay for the resources they use. Developers simply set the maximum memory limits and maximum concurrency levels, and Amazon SageMaker will auto-provision resources to match demand. This allows model deployments to be done easily without managing the underlying infrastructure.
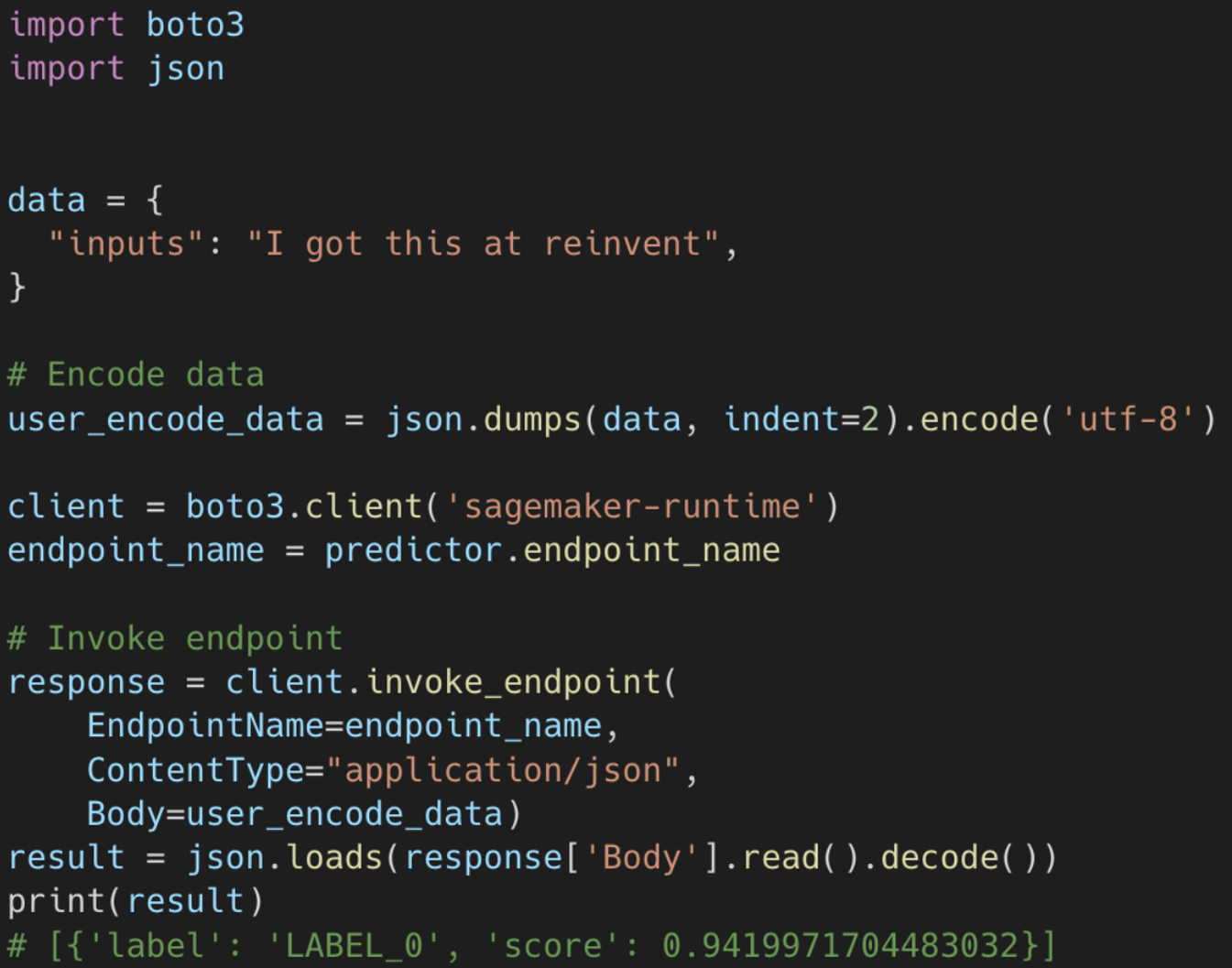
After training a model, using Amazon SageMaker, we can create an endpoint that serves predictions. For our classifier, we are creating and deploying a SageMaker Serverless Inference endpoint. We provide memory size (MB) and maximum concurrency configurations. Then Amazon SageMaker will create and manage the endpoint for us. Now that the endpoint is up and running, we can use any SDK, such as boto3 for Python, to send client requests and receive responses back. This process can be wrapped in a lambda function where we are calling the SageMaker endpoint for inference.
Summary
In summary, NLP has made tremendous progress in recent years, with the development of sophisticated language models that have revolutionized the field. With the help of powerful tools and frameworks, like Amazon SageMaker and Hugging Face, developers can train and evaluate these models more efficiently and effectively. As language models continue to grow in complexity, it is essential to have the right tools and resources to stay ahead of the curve.
If interested to watch the on-demand session on this topic presented at AWS re:Invent 2022, then click here.
Opinions expressed by DZone contributors are their own.
Comments