Block Size and Its Impact on Storage Performance
Explore structured vs unstructured data, how storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads.
Join the DZone community and get the full member experience.
Join For FreeThis article analyzes the correlation between block sizes and their impact on storage performance. This paper deals with definitions and understanding of structured data vs unstructured data, how various storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads. It also highlights the calculation of throughput and the choice of storage product based on workload type.
Block Size and Its Importance
In computing, a physical record or data storage block is a sequence of bits/bytes referred to as a block. The amount of data processed or transferred in a single block within a system or storage device is referred to as the block size. It is one of the deciding factors for storage performance. Block size is a crucial element in performance benchmarking for storage products and categorizing the products into block, file, and object segments.
Structured vs Unstructured Data
Structured data is organized in a standardized format, usually in tables with rows and columns, making it easy for humans and software to access. It is often quantitative data, meaning it can be counted or measured, and can include data types like numbers, short text, and dates. Structured data is ideal for analysis and can be combined with other data sets for storage in a relational database.
Unstructured simply refers to datasets (typical large collections of files) that aren’t stored in a structured database format. Unstructured data has an internal structure, but it’s not predefined through data models. It might be human-generated, or machine-generated in a textual or a non-textual format. (Source)
Usually, the block size of structured data is in the range of 4KB to 128KB, and in some cases, it could go to 512KB as well. In contrast, the block size for unstructured data ranges much higher and could easily be in the MB range, as shown in the figure below.

Figure 1: The block size for structured vs unstructured data
OLTP or Online Transaction Processing is a type of data processing that consists of executing several transactions occurring concurrently — online banking, shopping, order entry, or sending text messages — whereas OLAP is an online analytical processing software technology you can use to analyze business data from different points of view. Organizations collect and store data from multiple data sources, such as websites, applications, smart meters, and internal systems. (Source)
Most of the OLTP workload follows structured data and most of the OLAP workload follows unstructured data patterns and the major difference between them is the block size.
Throughput/IOPS Formula Using Block Size
Storage throughput (also called data transfer rate) measures the amount of data transferred to and from the storage device per second. Normally, throughput is measured in MB/s. Throughput is closely related to IOPS and block size.
IOPS (input/output operations per second) is the standard unit of measurement for the maximum number of reads/writes to noncontiguous storage locations. Here is the formula highlighting the IOPS and throughput relation:
MBps = (IOPS * KB per IO) /1024
or
IOPS = (MBps Throughput / KB per IO) * 1024
In the above formula, KB per IO is the block size. Hence, each workload is IO-driven or throughput-driven depending on the block size. If the IOPS are higher for any workload, it means that the block size is smaller, and if the throughput numbers are higher for any workload, then the block size is on the higher side.
Storage Performance Based on Block Sizes
Storage technologies respond based on block sizes, and hence, there would be different storage recommendations based on the block size and response time. Block storage would be more suitable for applications with smaller block sizes, while file level and object storage would be more suitable with bigger block sizes.
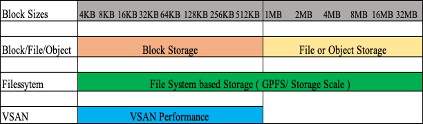
Figure 2: Storage technology and its range are based on block sizes
As shown in the figure above, block storage has been the choice for production workloads with smaller block sizes and these applications have higher IOPS limits. Each block storage release note contains the performance numbers concerning the number of IOPS each storage box can achieve. At the same time, file-level storage or any NFS storage is more suitable for larger block sizes, larger than 1MB.
Object storage, which is comparatively a new offering in the market, was introduced for storing files and folders across multiple sites and has a performance range like NFS.
Object storage would need load balancers to distribute the chunks across the storage systems which also helps in boosting performance. Both NFS and object storage have high response times compared to block storage as the I/O has to go through a network to reach the disk and back to complete the I/O cycle. The average response time for NFS and object storage is in the range of 10+ milliseconds.
Filesystem storage can cater to a larger range of block sizes. The architecture of filesystem storage can be tuned to handle most block-size striping and improve overall performance. Generally, filesystem storage is being used in the implementation of data lakes, analytical workloads, and high-performance computing. Most filesystem storage also uses agent-level software installed on the servers for better data distribution and improved performance over the network.
InfiniBand setup is preferred with file system storage for large-scale deployment of data lakes or HPC systems where the workload is throughput-driven and huge ingest data is expected in a short period.
VSAN was introduced as a block storage offering for VMware workloads and has been very successful across OLTP workloads. In the recent past, VSAN has been used for workloads with higher block sizes as well, specifically for backup workloads where response time requirements may not be critical. What works in the favor of VSAN is the new improved architecture and the cluster sizing which helps in overall performance.
Workloads, Block Size, and Suitable Storage
Since storage products have different performance levels for various block sizes, how do we choose the storage based on the block size of the workload? Here are a few such examples:

Figure 3: Workloads and their respective block sizes
In the table above, workloads and their respective block sizes are mentioned as an example. This figure helps in choosing the right kind of storage product based on the workload block size and overall performance requirements.
For block sizes that are less than 256 KB, most of the block storage would perform well, regardless of the vendor company, as the block storage architecture is most suitable for small block-size workloads. Similarly, bigger block-size workloads such as RMAN or Veeam backup software would be more suitable for NFS or object storage, as these are throughput-driven workloads. There would be other design parameters like throughput requirements, total capacity, and read/write percentage that would help in sizing the solution.
Final Thoughts
It is hoped that this study will help IT engineers and architects design their setups based on the nature of the application workload and block sizes.
Opinions expressed by DZone contributors are their own.
Comments