Best Practices for Creating Highly Reliable Applications in Mule 4
Don't want to lose your data at any cost? Follow this tutorial to learn best practices for creating highly reliable applications in Mule 4.
Join the DZone community and get the full member experience.
Join For FreeIn this blog, I would like to share a few best practices for creating highly reliable applications in Mule 4.
Reliability aspires to have zero message or data loss after a Mule application stops or crashes.
Most of the configuration details (relevant to reliability) shared here are taken from MuleSoft Documentation/Articles.
1. Asynchronous Processing: Use Persistent VM Queues | Use Anypoint MQ | Use External Message Broker (JMS-Based)
Use Persistent VM Queues
Persistent queues are slower but reliable.
When running a Mule application in single runtime instance mode, persistent queues work by serializing and storing the contents on the disk. However, when running the Mule application in cluster runtime instance mode, the persistent queues are backed up in the memory grid. In either single or cluster runtime instance mode, when using persistent queues, the data you send must be serializable.
CloudHub (1.0) deployed applications have the option to utilize CloudHub Persistent Queues. CloudHub Persistent Queues is a Cloud Service that allows messages that are published to VM queues to be stored externally to the application.
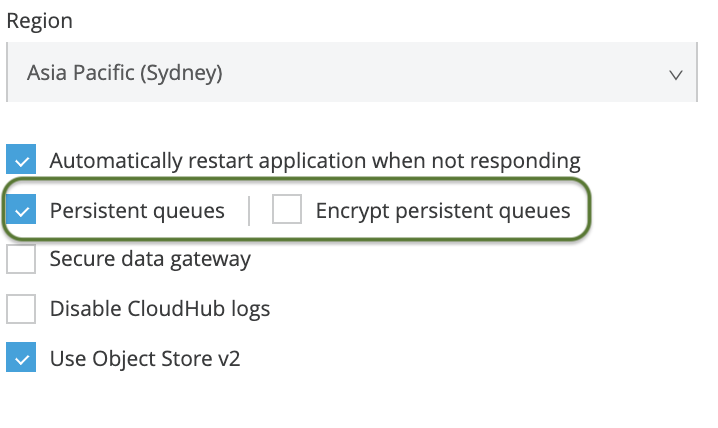
How To Enable CloudHub Persistent Queues
CloudHub Persistent queues can be enabled on a per-application basis, and the option is found in Runtime Manager → Application → Settings page. If your organization has the entitlement, you may also choose to encrypt the persistent queues for added security. This feature is only available for customers who have Platinum and above subscriptions.
Use Anypoint MQ
Anypoint MQ is a multi-tenant, cloud messaging service that enables customers to perform advanced asynchronous messaging scenarios between their applications. Anypoint MQ is fully integrated with the Anypoint Platform, offering role-based access control, client management, and connectors.
Anypoint MQ ensures secure, reliable message delivery.
Automatically enables persistent data storage across multiple data centers to ensure that your message queue architecture can handle data center outages and has full disaster recovery. Encrypts message queues to secure data at rest, or send messages to dead letter queues for additional reliability.
How To Use Anypoint MQ
Install and Configure Anypoint MQ
- Log in to Anypoint Platform using your Enterprise Mule credentials, and click MQ.
- Click Access Management, then Users or Roles, to create an Anypoint MQ user or role.
- From MQ, create a queue, message exchange, or FIFO queue.
- Click a queue or message exchange name in the detail to access the Message Sender to send messages to a queue or message exchange and to use the Message Browser to get messages from a queue.
- From MQ, click Client Apps to register an app. You can view the client app ID and client secret for the app.
In Anypoint Studio
- Install the Anypoint MQ connector using Anypoint Exchange.
- Create a new Mule project with needed building blocks, such as an HTTP connector, Anypoint MQ connector, Set Payload, and a Logger.
- Configure the Anypoint MQ connector and provide the client app ID and client secret of the app.
- Set the Anypoint MQ connector operation to publish or consume messages or to accept (ACK) or not accept (NACK) a message.
- Run the Mule app.
Use External Message Broker (JMS-Based)
Anypoint Connector for JMS (Java Message Service) (JMS Connector) enables sending and receiving messages to queues and topics for any messaging service that implements the JMS specification.
How To Configure JMS Connector
Configure a Source
You can configure one of these 3 input sources to use with JMS Connector:
- JMS > On New Message — Initiates a flow by listening for incoming messages
- HTTP > Listener — Initiates a flow each time it receives a request on the configured host and port
- Scheduler — Initiates a flow when a time-based condition is met
To configure an On New Message source, follow these steps:
- In the Mule Palette view, select JMS > On New Message.
- Drag On New Message to the Studio canvas.
- In the On New Message configuration screen, optionally change the value of the Display Name field.
- Click the plus sign (+) next to the Connector configuration field to configure a global element that can be used by all instances of the source in the app.
- In the JMS Config window, for Connection, select either one of the connection types to provide to this configuration:
- Active MQ Connection
- Active MQ Connection - No Connectivity Test — (DEPRECATED)
- Generic Connection
- On the General tab, specify the connection information for the connector, such as required libraries for the broker, JMS specification, cache strategy, authentication, and connection factory.
- On the TLS/SSL tab, optionally specify a TLS configuration.
- On the Advanced tab, optionally specify a reconnection strategy and XA connection pool.
- Click OK to close the window.
- In the On New Message configuration screen, in Destination, specify the name of the destination from where to consume the message.
- Configure other optional fields in the On New Message configuration screen.
Add a Connector Operation
To add an operation for JMS Connector, follow these steps:
- In the Mule Palette view, select JMS Connector and then select the desired operation.
- Drag the operation onto the Studio canvas and to the right of the input source.
2. State Management — Use Persistent Object Store | Use Persistent VM Queues | Use External Storage (DB, FTP, Etc.)
Use Persistent Object Store
Object store is a storage container that stores key-values information. Object Store can be persistent or transient (non-persistent).
Persistent OS will not lose any information (key-value) in case of application restart where in non-persistent (key-value) information is lost.
How To Use/Enable Persistent Object Store
Use the Default Object Store
By default, each Mule app has an Object Store that is persistent and always available to the app without any configuration. Flows can use it to persist and share data.
If you want to use the default Object Store, you can specify a key for the Object Store without selecting or creating an Object Store reference for the Object Store operation, and without specifying an objectStore attribute in the XML element for the Object Store component.
The Mule app is deployed to CloudHub workers using Runtime Manager, but the contents of the default Object Store are not visible in Runtime Manager in the Application Data page for the app.
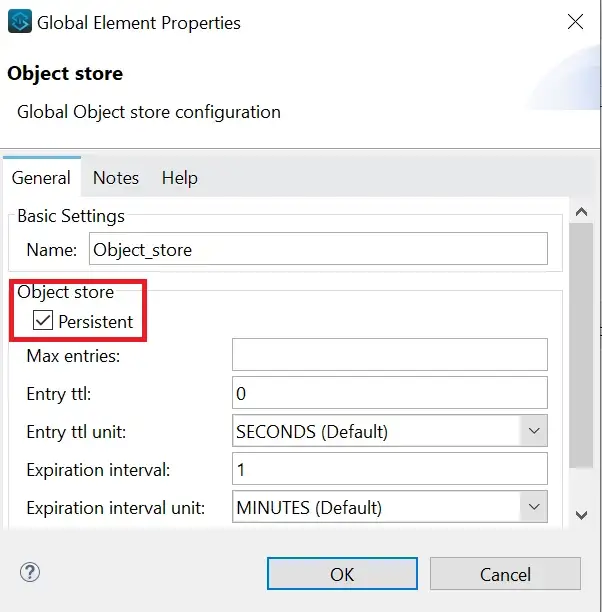
Use a Custom Object Store
Custom Object Stores must specify an objectStore attribute. These Object Stores can be configured to behave differently than the default Object Store. For example, you can indicate whether the Object Store is persistent (so that the Object Store data survives a Mule Runtime crash) or transient (where data does not survive a Mule Runtime crash).
Use Persistent Gateway
Anypoint Runtime Fabric provides Persistence Gateway.
Enable Mule applications deployed to a Mule runtime instance to store and share data across application replicas and restarts, hence ensuring reliability.
After Persistence Gateway is configured in Anypoint Runtime Fabric, it is available for Mule applications deployed to Mule runtime engine, version 4.2.1 or later. When configured, users can select Use Persistent Object Storage when deploying an application using Runtime Manager.
Mule applications use the Object Store v2 REST API via the Object Store Connector to connect to Persistence Gateway. This enables you to deploy to both Anypoint Runtime Fabric and CloudHub without having to modify your Mule application.
How To Configure Persistence Gateway
During configuration, Persistence Gateway creates the required database schema. Afterwards, when an application deployed to Runtime Fabric is configured to use persistent object storage, the Persistence Gateway writes the necessary rows to the database.
To configure Persistence Gateway, you must create a Kubernetes custom resource that allows the cluster to connect to your persistence data store.
Create a Kubernetes Secret
kubectl create secret generic <SECRET NAME> -n rtf --from-literal=persistence-gateway-creds='postgres://username:pass@host:port/databasename'Create a Custom Resource for Your Data Store
- Copy the custom resource template from Kubernetes Custom Resource Template to a file called
custom-resource.yaml. - Ensure the value of
secretRef: namematches thenamefield defined in your Kubernetes secret file. - Modify other fields of the custom resource template as required for your environment.
- Run
kubectl apply -f custom-resource.yaml.
Check the Logs of the Persistence Gateway Pod To Ensure It Can Communicate With the Database
kubectl get pods -n rtfLook for Pods With the Name Prefix persistence-gateway
kubectl logs -f persistence-gateway-6dfb98949c-7xns9 -nrtfUse Persistent VM Queues
Refer to the one above under ‘Asynchronous Processing’.
Use External Storage
Another option is persist your data in external storage systems such as DB, FTP, External Cache, etc. Mule applications can use connectors to connect to these systems.
Different external stores provide various Quality of Service (QoS) levels, hence ensuring reliability:
- Persistence
- Transactional
- Replication
- Eviction policies (Least Frequently Used)
- High Availability via Cluster
- Faster data retrieval via Partitioning
- Automatic Failover
3. Reconnection Strategy
When an operation in a Mule application fails to connect to an external server, the default behavior is for the operation to fail immediately and return a connectivity error.
In order to ensure no data loss, you can modify this default behavior by configuring a reconnection strategy for the operation.
Reconnection strategy is one of the ways to achieve reliability goals.
How To Configure Reconnection Strategy
You can configure a reconnection strategy for an operation either by modifying the operation properties or by modifying the configuration of the global element for the operation.
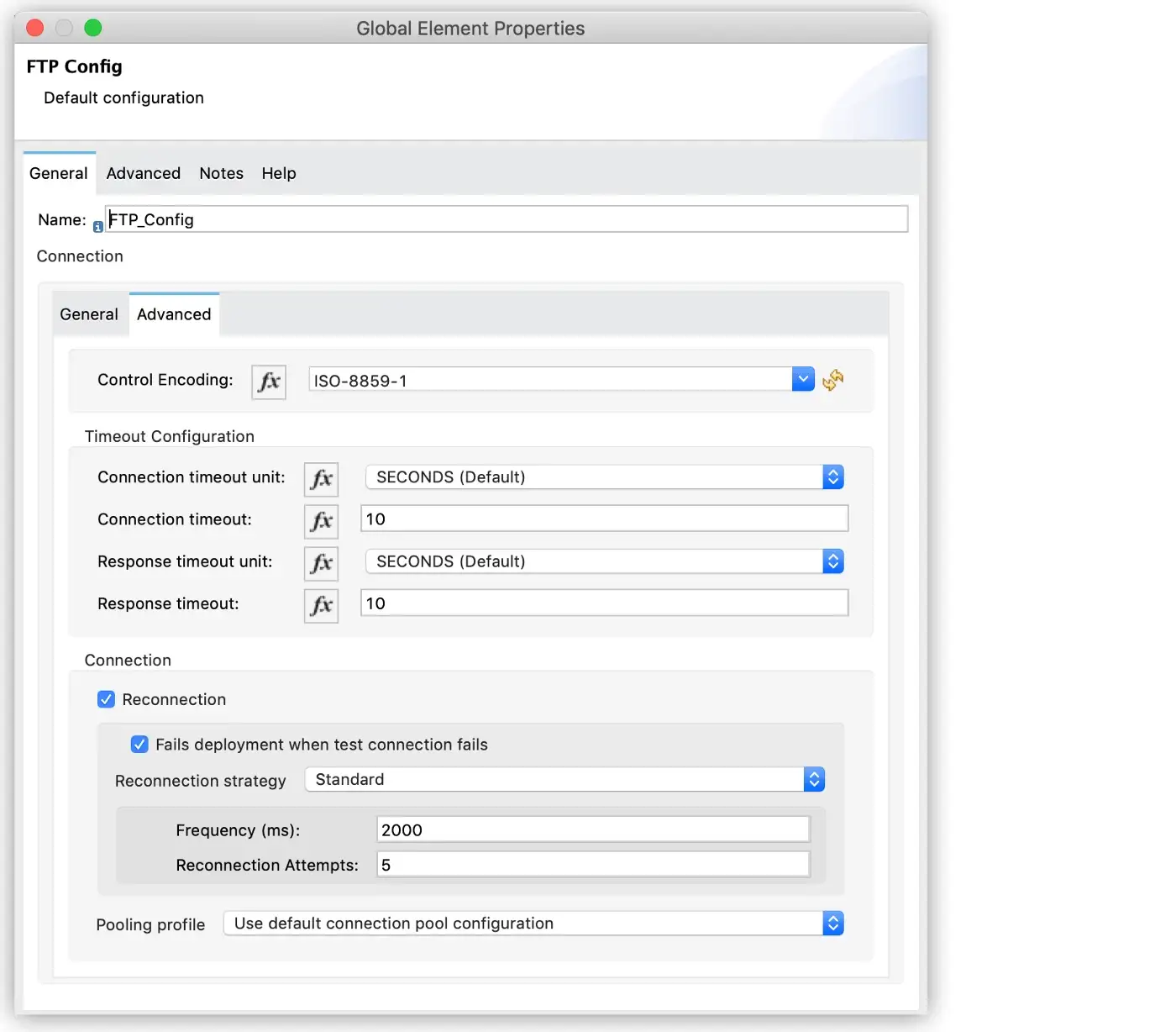
Connectivity tests run when the Mule application starts, then periodically while the application runs. The reconnection strategy dictates what to do when connectivity fails.
The following are the available reconnection strategies and their behaviors:
- None: Is the default behavior, which immediately returns a connectivity error if the attempt to connect is unsuccessful.
- Standard (
reconnect): Sets the number of reconnection attempts and the interval at which to execute them before returning a connectivity error. - Forever (
reconnect-forever): Attempts to reconnect continually at a given interval.
Sample code in XML:
<ftp:config name="FTP_Config" doc:name="FTP Config" >
<ftp:connection host="ftp.someftphost.com" port="21" username="myusername" password="mypassword" >
<reconnection failsDeployment="true" >
<reconnect count="5"/>
</reconnection>
</ftp:connection>
</ftp:config>
<flow name="reconnectionsFlow" >
<ftp:listener doc:name="On New or Updated File" config-ref="FTP_Config">
<scheduling-strategy >
<fixed-frequency />
</scheduling-strategy>
</ftp:listener>
</flow><ftp:connection host="ftp.someftphost.com" port="21" username="myusername" password="mypassword" >
<reconnection>
<reconnect-forever frequency="4000"></reconnect>
</reconnection>
</ftp:connection>By default, a failed connectivity test is just logged, and the Mule application starts anyway or continues to run without trying to reconnect. However, a reconnection strategy can be configured on some connector operations to try to connect instead repeatedly.
The configuration attributes/parameters are as follows:
Attributes of <reconnection>
failsDeployment : If true, causes the deployment to fail when the test connection fails. Defaults to false .
Attributes of <reconnect>
blocking : If false, the reconnection strategy runs in a separate, nonblocking thread. Defaults to true .
frequency : How often (in ms) to reconnect. Defaults to 2000.
count : How many reconnection attempts to make. Defaults to 2.
Attributes of <reconnect-forever>
blocking : If false, the reconnection strategy runs in a separate, nonblocking thread. Defaults to true .
frequency : Specifies how often (in ms) to reconnect. Defaults to 2000.
4. Redelivery Policy
A Redelivery Policy is a filter that helps you conserve resources by limiting the number of times the Mule runtime engine (Mule) executes messages that generate errors.
Redelivery policy is one of the ways to achieve reliability goals.
You can add a redelivery policy to any source in a flow.
When you add a redelivery policy to a flow’s source, Mule evaluates the received data before it executes the flow’s components. If a message delivery fails a specified number of times, the redelivery policy prevents the flow from processing the received data and raises a REDELIVERY_EXHAUSTEDerror.
How To Configure Redelivery Policy
A redelivery policy is configured on the event source in a flow such as HTTP Listener; On New or Updated File; On New Message of JMS Connector, etc., to specify the no. of times the “same” event emitted by the event source can be processed by the flow before raising a REDELIVERY_EXHAUSTED error.
Redelivery policy cannot be configured on a scheduler event source.
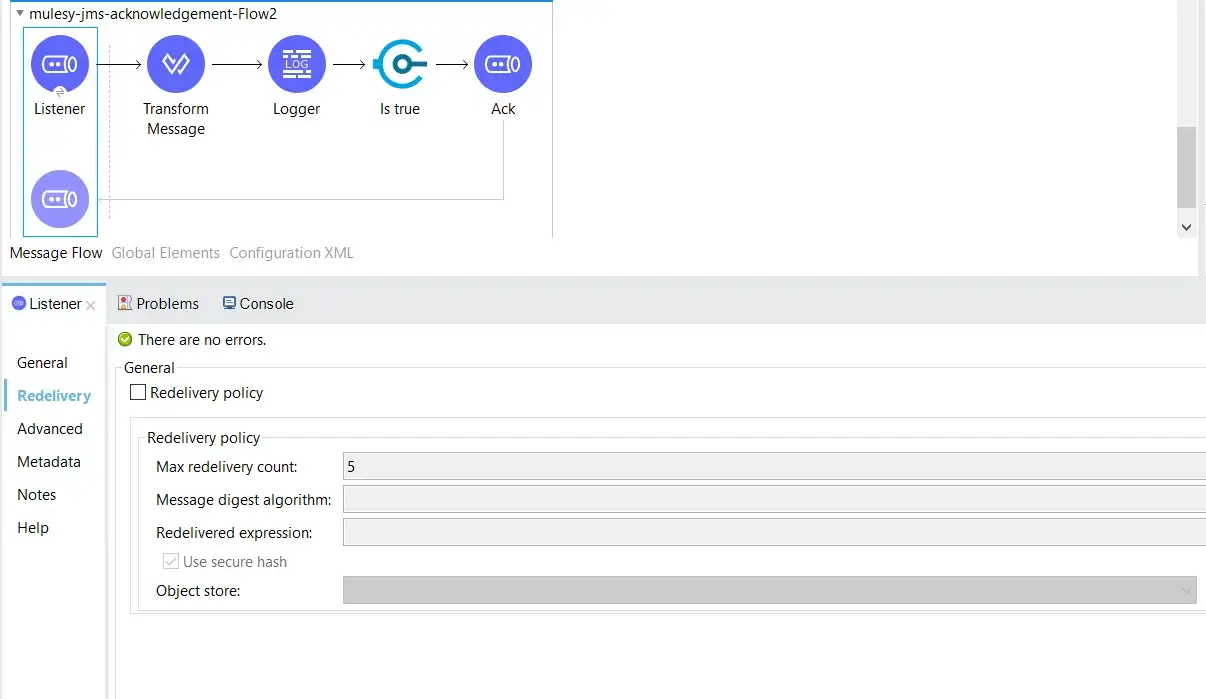
These are the configuration parameters:
- Max Redelivery Count: Maximum number of times that a message can be redelivered to the flow and processed unsuccessfully before raising a
MULE:REDELIVERY_EXHAUSTEDerror. Defaults to 5.- 0 means no delivery
- -1 means infinite redeliveries
- Use Secure Hash: Indicates whether to use a secure hash algorithm to identify a redelivered message. Defaults to True.
- Message Digest Algorithm: Secure hashing algorithm to use for the message. If the payload of the message is a Java object, Mule ignores the Message Digest Algorithm value and returns the value that the payload’s
hashCode()returned. Defaults to SHA-256. - ID Expression: Defines one or more expressions that determine when a message has been redelivered. This property can be set only if the value of Use Secure Hash is False.
- Object Store: Object Store in which the redelivery counter for each message is stored. You can configure the Object Store as a reference or an inner element.
How Redelivery Policy Works
Each time the source receives a new message, Mule identifies the message by generating its key.
- If the processing flow causes an exception, Mule increments the counter associated with the message key. When the counter reaches a value greater than the configured
maxRedeliveryCountvalue, Mule throws aMULE:REDELIVERY_EXHAUSTEDerror. - If the processing flow does not cause an exception, its counter is reset.
5. File-Stored Repeatable Streaming Strategy
Mule 4 introduces repeatable streams as its default framework for handling streams. Repeatable streams enable you to:
- Read a stream more than once.
- Have concurrent access to the stream.
File storage is the default streaming strategy in Mule 4 and ensures reliability.
This strategy initially uses an in-memory buffer size of 512 KB. For larger streams, the strategy creates a temporary file to the disk to store the contents without overflowing your memory.
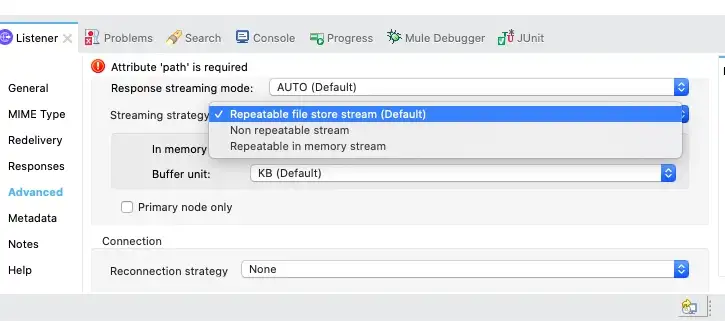
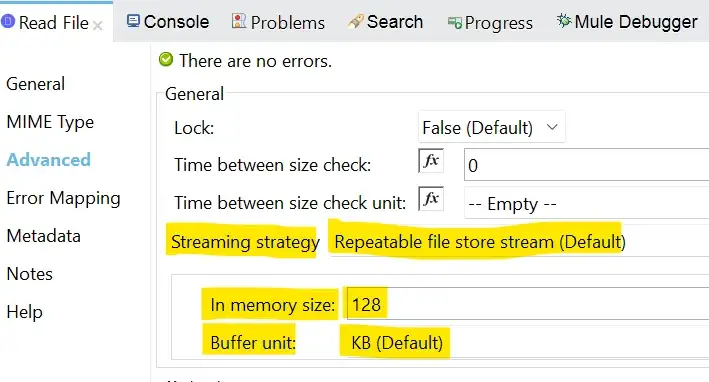
If you need to handle large or small files, you can change the buffer size (inMemorySize) to optimize performance:
- Configuring a larger buffer size increases performance by avoiding the number of times the runtime needs to write the buffer to your disk, but it also limits the number of concurrent requests your application can process.
- Configuring a smaller buffer size saves memory load.
You can also set the buffer’s unit of measurement (bufferUnit).
Sample code in XML:
<file:read path="smallFile.json">
<repeatable-file-store-stream
inMemorySize="10"
bufferUnit="KB"/>
</file:read>You can refer to Productively for JS-based software programs well-loved by people.
6. Transaction Management
Transactions are operations in a Mule app for which the result cannot remain indeterminate. When a series of steps in a flow must succeed or fail as one unit, Mule uses a transaction to demarcate that unit.
The transaction demarcation ensures there is no data loss and hence reliability.
Transaction Types
Mule supports Single Resource (Local, the default) and Extended Architecture (XA) transaction types (transactionType). The only components that can define the transaction type are message sources (For example, jms:listener and vm:listener) and the Try scope.
Single Resource Transactions (also known as a simple transaction or local transaction) only use a single resource to send or receive messages: JMS broker, VM queues, or JDBC connections.
Sample code in XML:
<flow name="asdFlow" doc:id="2a67b1ee-0394-44a8-b6d9-9ce4f94f1ae2" >
<jms:listener config-ref="JMS_Config" destination="test.in" transactionalAction="ALWAYS_BEGIN"/>
<!-- Other operations -->
<jms:publish config-ref="JMS_Config" destination="test.out" transactionalAction="ALWAYS_JOIN"/>
</flow>Mule only commits messages that successfully pass through the complete flow. If, at any point in the flow, a message throws an error that is propagated (i.e., it is not handled by an on-error-continue), Mule rolls back the transaction.
Extended Architecture Transactions (or XA Transactions) can be used to group a series of operations from multiple transactional resources, such as VM, JMS, or Database, into a single reliable global transaction.
The XA (eXtended Architecture) standard is an X/Open group standard that specifies the interface between a global transaction manager and local transactional resource managers. The XA protocol defines a 2-phase commit protocol that can be used to reliably coordinate and sequence a series of atomic operations across multiple servers of different types. Each local XA resource manager supports the A.C.I.D properties (Atomicity, Consistency, Isolation, and Durability), which help guarantee completion of a sequence of operations in the resource managed by the XA resource manager.
Sample code in XML:
<flow name="exampleFlow" >
<try transactionalAction="ALWAYS_BEGIN" transactionType="XA">
<set-payload value="Hello World"/>
<vm:publish queueName="someVmQueue" config-ref="VM_Config"/>
<jms:consume config-ref="JMS_Config" destination="someQueue"/>
<db:insert config-ref="Database_Config">
<db:sql>${insertQuery}</db:sql>
</db:insert>
</try>
<error-handler>
<on-error-propagate enableNotifications="true" logException="true"/>
</error-handler>
</flow>If the db:insert operation fails, the transaction is rolled back (i.e., it is not handled by an on-error-continue) before the error handler (on-error-propagate) is executed. Therefore, the message sent through the vm:publish is not confirmed to be sent, and the message in the jms:consume is not actually consumed, so it is available next time to be consumed again.
The following table describes the characteristics of each transaction type and the requisites for an operation to join the transaction:

Common connector operations that support transactions in Mule 4:
- JMS — Publish; Consume
- VM — Publish; Consume
- Database — All operations
Transactional Actions
A Transactional Action (transactionalAction) defines the type of action that operations take regarding transactions.
The following table describes all available transactional actions:
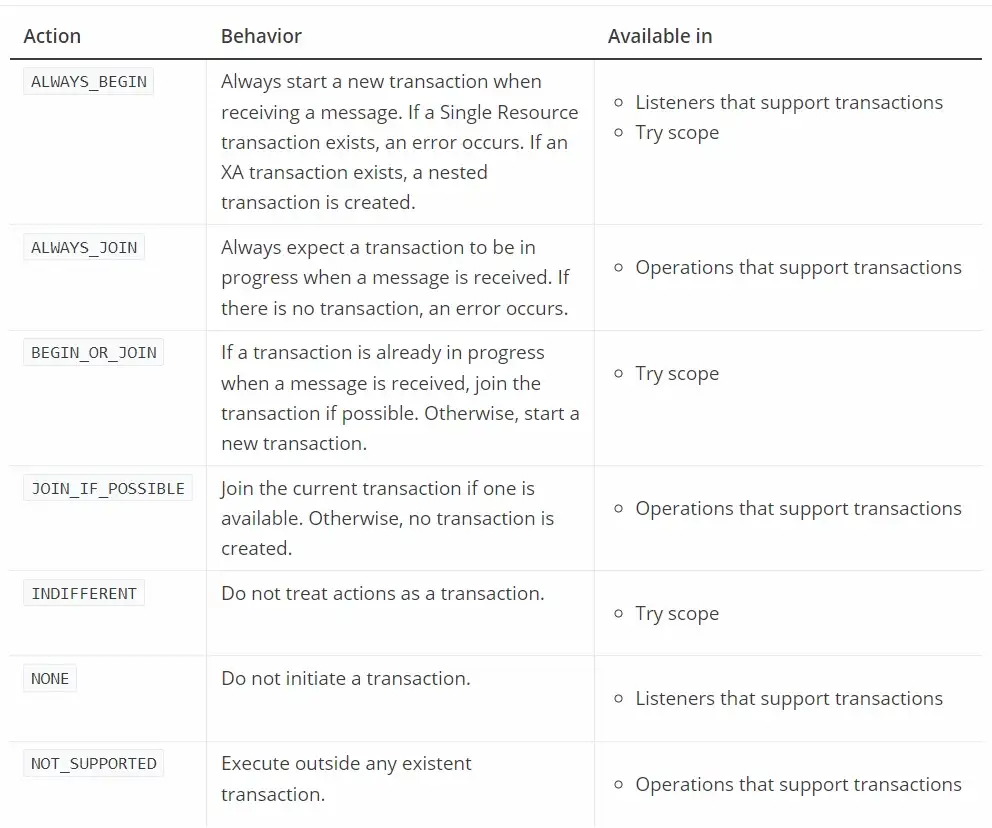
How To Configure a Transaction
In the Message Source
You can start a transaction from a message source. In this case, the entire flow becomes a transaction.
To initiate a transaction from a message source, configure its Transaction type and Transactional action:
- In Anypoint Studio: Open the Listener’s Advanced tab, and set the Transaction type and the Transactional action values:
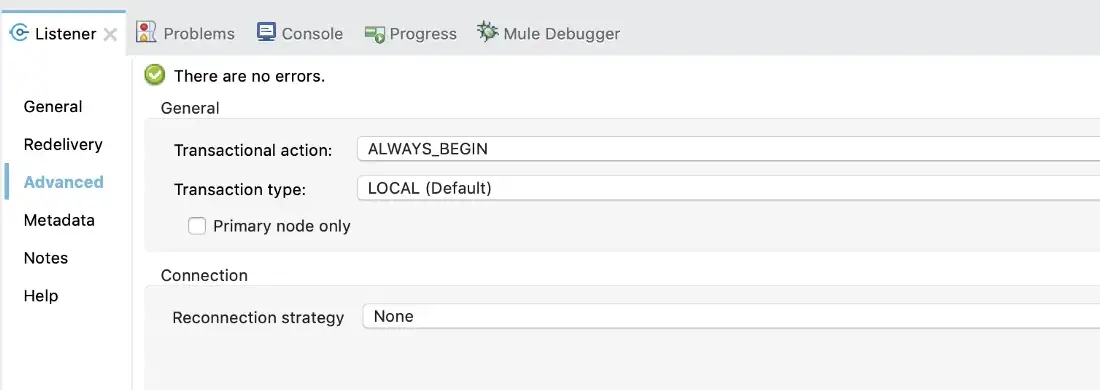
- In the Configuration XML: Add the
transactionalActionelement and thetransactionTypeelement (if necessary), and set their values:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:vm="http://www.mulesoft.org/schema/mule/vm"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd">
<vm:config name="VM_Config1" >
<vm:queues >
<vm:queue queueName="input" />
<vm:queue queueName="output" />
</vm:queues>
</vm:config>
<flow name="source-transactionsFlow">
<vm:listener config-ref="VM_Config1" queueName="input" transactionalAction="ALWAYS_BEGIN"/>
<http:request method="GET" url="www.google.com"/>
<vm:publish config-ref="VM_Config1" queueName="output"/>
</flow>
</mule>In a Try Scope
A Mule flow can also begin with a non-transactional connector (such as HTTP) that requires a transaction within the flow. In such a situation, you use the Try scope to set up a transaction.
You can configure a transaction in a Try scope component by setting a Transaction type and Transactional action:
- In Anypoint Studio: Open the Try scope’s General tab, and set the Transaction type and the Transactional action values:
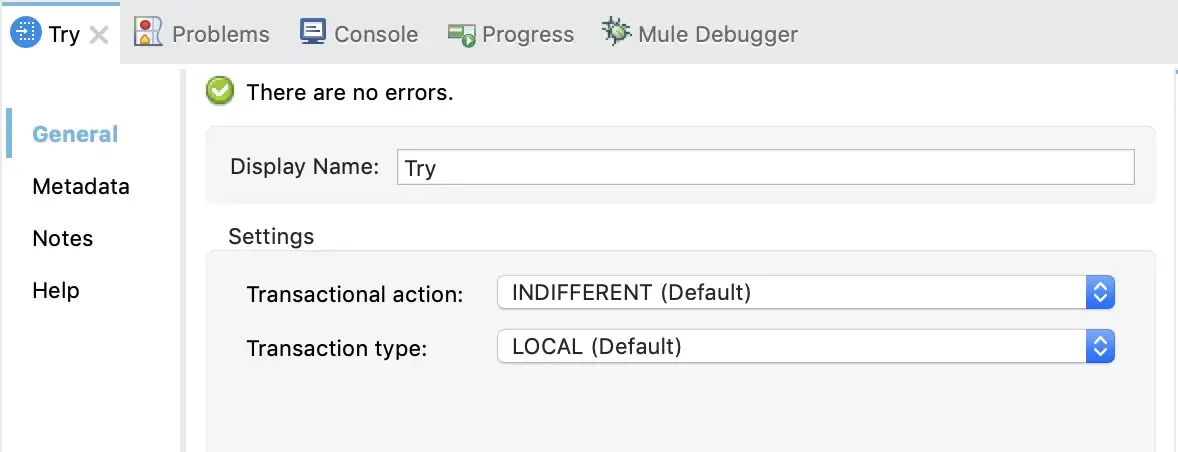
- In the Configuration XML: Add the
transactionalActionelement and thetransactionTypeelement (if necessary), and set their values:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:vm="http://www.mulesoft.org/schema/mule/vm" xmlns:db="http://www.mulesoft.org/schema/mule/db"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/db http://www.mulesoft.org/schema/mule/db/current/mule-db.xsd
http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd">
<db:config name="Database_Config">
<db:derby-connection database="myDb" create="true" />
</db:config>
<vm:config name="VM_Config">
<vm:queues>
<vm:queue queueName="myQueue" />
</vm:queues>
</vm:config>
<flow name="transactionsFlow">
<try transactionalAction="ALWAYS_BEGIN" transactionType="XA">
<db:insert doc:name="Insert" transactionalAction="ALWAYS_JOIN">
<db:sql>
INSERT INTO main_flow_audit (errorType, description) VALUES (:errorType, :description)
</db:sql>
<db:input-parameters><![CDATA[
#[{
'errorType' : 'AUTHENTICATION',
'description' : 'invalid authentication credentials',
}]
]]></db:input-parameters>
</db:insert>
<vm:publish config-ref="VM_Config" queueName="myQueue" transactionalAction="ALWAYS_JOIN"/>
</try>
</flow>
</mule>Bitronix Transaction Manager
Bitronix is available as the XA Transaction Manager for Mule applications. Bitronix Transaction Manager allows Mule to automatically recover interrupted transactions on restart.
How to Configure a Mule Application To Use Bitronix
To use Bitronix (in a Single application or in all Applications in a Mule domain), declare it as a global configuration element in the Mule application:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:bti="http://www.mulesoft.org/schema/mule/ee/bti"
xsi:schemaLocation="
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/ee/bti http://www.mulesoft.org/schema/mule/ee/bti/current/mule-bti-ee.xsd">
<bti:transaction-manager/>
...
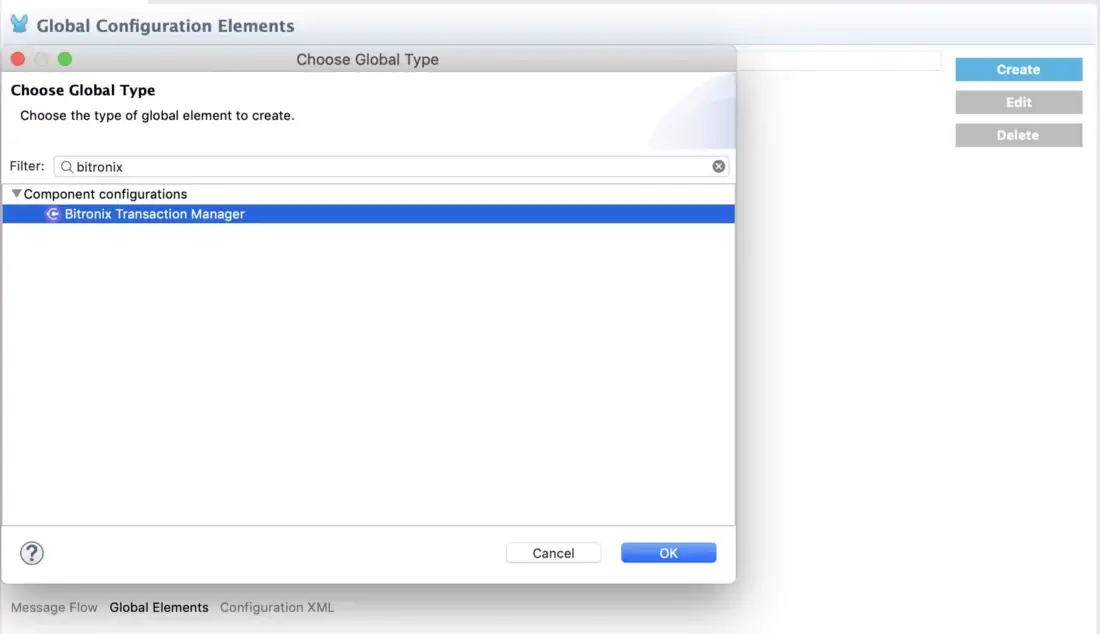
</mule>You can add Bitronix to your application or domain from Studio by following these steps:
- Go to the Global Elements tab.
- Click on Create button.
- Search for
Bitronix Transaction Manager.
The table below lists configuration attributes for Bitronix:

7. Batch Jobs
The Batch Job component is designed for reliable, asynchronous processing of larger-than-memory data sets. It automatically splits source data and stores it into persistent queues, which makes it possible to process large data sets.
Since persistent queues are used internally, it will not result in loss of data and hence ensure reliability.
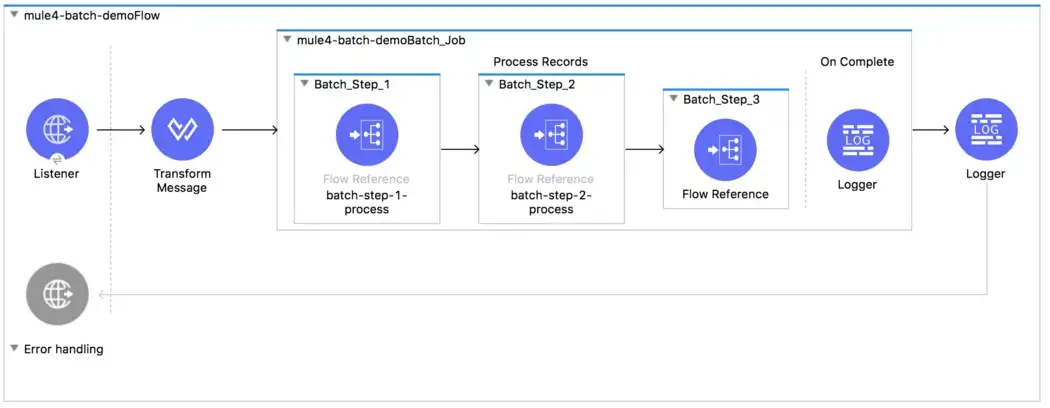
This component can be configured as follows:
- Filtering Records to Process within a Batch Step: To filter records, the Batch Step supports
acceptExpressionandacceptPolicy. Both are optional. - Performing Bulk Operations from a Batch Aggregator: Aggregation is useful for sending multiple records within an array to an external server.
- Changing the Record Block Size: To improve performance, Mule runtime queues and schedules batch records in blocks of up to 100 records per thread. This behavior reduces the number of I/O requests and improves an operation’s load.
- Setting a Max Concurrency Limit on Batch Job Instances: The Max Concurrency (
maxConcurrency) field limits the number of record blocks to process concurrently.
8. Until Successful Scope
The Until Successful Scope executes processors within it in order until they all succeed or the scope exhausts the maximum number of retries. Until Successful runs synchronously. If any processor within the scope fails to connect or to produce a successful result, Until Successful retries all the processors within it, including the one that failed, until all configured retries are exhausted. If a retry succeeds, the scope proceeds to the next component. If the final retry does not succeed, Until Successful produces an error.
Until Successful Scope is similar to Redelivery policy, hence it is one of the ways to achieve reliability goals.
How To Configure Until Successful Scope
To configure an Until Successful scope, add the <until-successful> XML element inside an application flow.
You can configure the following attributes in the Until Successful scope:

Sample code in XML:
<!-- FTP Connector config-->
<ftp:config name="FTP_Config" doc:name="FTP Config" >
<ftp:connection workingDir="${ftp.dir}" host="${ftp.host}" />
</ftp:config>
<flow name="untilSuccessfulFlow" >
<!-- Scheduler component to trigger the flow-->
<scheduler doc:name="Scheduler" >
<scheduling-strategy >
<fixed-frequency frequency="15" timeUnit="SECONDS"/>
</scheduling-strategy>
</scheduler>
<!-- Until Successful scope-->
<until-successful maxRetries="5" doc:name="Until Successful" millisBetweenRetries="3000">
<!-- FTP Write operation that executes as part of the Until Successful Scope -->
<ftp:write doc:name="Write" config-ref="FTP_Config" path="/"/>
</until-successful>
<logger level="INFO" doc:name="File upload success" message="File upload success"/>
<!-- Error Handler at flow level-->
<error-handler>
<on-error-continue enableNotifications="true" logException="true" doc:name="On Error Continue" type="RETRY_EXHAUSTED">
<logger level="INFO" doc:name="File upload failed" message="File upload failed"/>
</on-error-continue>
</error-handler>
</flow>The above XML example configures a flow triggered by a Scheduler component and an Until Successful scope that executes an FTP Write operation.
9. First Successful Router
The First Successful router iterates through a list of configured processing routes until one of the routes executes successfully. If any processing route fails execution (throws an error), the router executes the next configured route. If none of the configured routes execute successfully, the First Successful Router throws an error.
The First Successful router stops executing routes after one of them completes successfully.
First Successful Router ensures reliability by trying to execute all routes until one of them is successful.
Sample code in XML:
<first-successful doc:name="First Successful" doc:id="6ae009e7-ebe5-47cf-b860-db6d51a31251" >
<route>
<file:read doc:name="Read non existent file" doc:id="199cdb01-cb43-404e-acfd-211fe5a9167e" path="nonExistentFile"/>
<set-variable value="1" doc:name="Set successfulRoute var to route 1" doc:id="c740b39e-a1c4-41d6-8a28-0766ca815ec6" variableName="successfulRoute"/>
</route>
<route>
<set-payload value="#[vars.nonExistentVar!]" doc:name="Set Payload with non existent variable" doc:id="0cc9ac4d-5622-4e10-971c-99073cb58df0" />
<set-variable value="2" doc:name="Set successfulRoute var to route 2" doc:id="88f15c26-d242-4b11-af49-492c35625b84" variableName="successfulRoute" />
</route>
<route>
<set-variable value="3" doc:name="Set successfulRoute var to route 3" doc:id="446afb25-0181-45e5-b04a-68ecb98b57b7" variableName="successfulRoute" />
</route>
<route >
<logger level="INFO" doc:name="Logger" doc:id="b94b905a-3a68-4c88-b753-464bc3d0cfeb" message="This route is never going to be executed"/>
</route>
</first-successful>10. Reliability Pattern
A Reliability pattern is a design that results in reliable messaging for an application, even if the application receives messages from a non-transactional connector. A reliability pattern couples a reliable acquisition flow with an application logic flow.
As the name says it all, this design pattern is to achieve reliability goals.
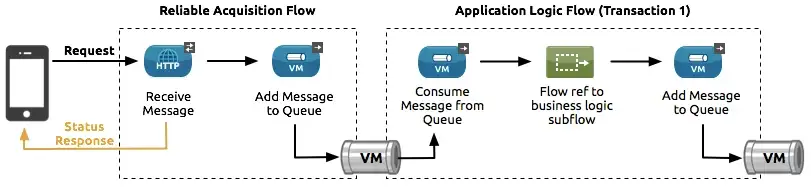
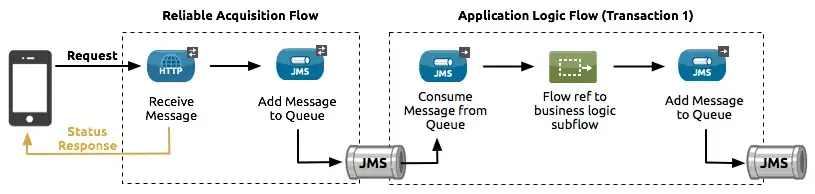
The reliable acquisition flow (the left side of the diagram) delivers a message reliably from a message source that does not implement transactions to an outbound operation of a connector that implements transactions. The operation can be of any type of transactional endpoint, such as VM or JMS. If the reliable acquisition flow cannot deliver the message, it ensures that the message isn’t lost.
- For socket-based connections like HTTP, this means returning an “unsuccessful request” response to the client so that the client can retry the request.
- For resource-based connections like File or FTP, it means not deleting the file so that it can be reprocessed.
The application logic flow (the right side of the diagram) delivers the message from the message source that uses a transactional connector to the business logic for the application.
Sample code in XML:
<http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<vm:config name="VM_Config" doc:name="VM Config" >
<vm:queues >
<vm:queue queueName="toTransactionalVM" queueType="PERSISTENT"/>
</vm:queues>
</vm:config>
<flow name="reliable-data-acquisition">
<http:listener config-ref="HTTP_Listener_config" path="transactionalEndpoint"/>
<vm:publish config-ref="VM_Config" queueName="toTransactionalVM" sendCorrelationId="ALWAYS"/> (1)
</flow>
<!-- This is the application logic flow in the reliability pattern.
It is a wrapper around the sub-flow "business-logic-processing". -->
<flow name="main-flow">
<vm:listener doc:name="Listener" config-ref="VM_Config" queueName="toTransactionalVM"
transactionalAction="ALWAYS_BEGIN"/> (2)
<flow-ref name="business-logic-processing"/>
</flow>
<!-- In this sub-flow, the application starts processing the message. -->
<sub-flow name="business-logic-processing">
<logger level="INFO" doc:name="Logger" />
<!--
This is where the actual business-logic is performed.
-->
</sub-flow>General Considerations
When you implement a reliability pattern, consider the following points:
- When the connector (message source) allows it, always use a transaction.
- When you want to enlist multiple managed resources within the same transaction, use an XA transaction to bridge message sources.
- The reliability of JMS is tied to the MQ implementation and how it is configured. Most MQ implementations allow you to configure whether messages are stored only in memory, or persisted. You can achieve reliability only if you configure the MQ server to persistently store messages before sending them forward. Otherwise, you risk losing messages in case of an MQ server crash.
- Reliability has performance implications.
- If the outbound operation in the reliable acquisition flow is not transactional (for example, a flow from file-to-FTP), perform that operation inside a Try Scope. With this practice, you can confirm if the operation completes successfully or, in case it fails, log the error message.
11. Testing
Testing for Reliability is an important software testing technique that is performed by the team to ensure that the software is performing and functioning consistently in each environmental condition as well as in a specified period.
Ensure that your Mule application is fault free and is reliable for its intended purpose.
This testing incorporates the results from both functional and non-functional testing such as Stress testing, Security testing, Functional testing, Production testing, etc.
Types of Reliability Testing
- Feature Testing: The purpose of feature testing is to check the features and functionality of the software.
- Regression Testing: This is done to check that no new bugs have been introduced in the application because of fixing previous bugs. This is done after every change or updating software features and functionalities.
- Load Testing: This test is concluded to confirm the functionality of the software under the conditions of highest workload.
12. Validation Schemas
JSON Module Validation can be used to validate JSON against the JSON schema. It will show the exact error(s) with the JSON payload, and accordingly, we can notify the client about the incoming JSON error.
Similarly, we have XML Module Validation to validate XML against the XML schema.
These modules prevent errors from being thrown further in the flow if there was no such validation in place, hence saving you from the additional efforts in ensuring reliability, such as persisting into DB, pushing into DLQ, etc.
Click here for more information on how to configure.
13. Error Handling
The errors thrown from any of the above-mentioned practices should be handled properly to ensure no data loss.
How To Handle Errors
a. REDELIVERY_EXHAUSTED
Thrown from wherever the Redelivery policy is configured when the number of executions that raise an error is greater than the configured maxRedeliveryCount value.
In this case, On Error Continue scope, make sure to push/persist the message (current message in the process) into a Dead Letter Queue (DLQ) so that it is not lost. Once persisted into DLQ, any type of notification informing above the failure can be sent to the concerned team.
Sample code in XML:
<on-error-continue type="REDELIVERY_EXHAUSTED">
<vm:publish queuename="errorqueue"/>
</on-error-continue>b. RETRY_EXHAUSTED
Thrown from a given operation or from Until Successful scope, when retries of a certain execution block have been exhausted.
In this case, On Error Continue scope, make sure to push/persist the message (current message in the process) into a Dead Letter Queue (DLQ) so that it is not lost. Once persisted into DLQ, any type of notification informing above the failure can be sent to the concerned team.
Sample code in XML:
<on-error-continue type="RETRY_EXHAUSTED">
<vm:publish queuename="errorqueue"/>
</on-error-continue>c. Any errors within a Transaction
When an error occurs during a transaction, your application must either handle the error and continue or perform a rollback.
On Error Propagate
- If the
on-error-propagateerror handler is inside theerror-handlerscope corresponding to the component that began the transaction: The transaction is rolled back before executing the processors of theon-error-propagatescope. This means that the processors inside the error handler do not run within the transaction. - If the
on-error-propagateerror handler is inside an element that did not start the transaction: The transaction is not rolled back and the processors inside theon-error-propagateerror handler run within the transaction.
On Error Continue
The error is handled, the transaction remains active and is able to commit. The processors inside the on-error-continue run within the transaction.
In any of these cases, make sure to push the current message into DLQ or some storage system like DB.
d. Any errors in a Batch Job
Mule has three options for handling a record-level error:
- Finish processing Stop the execution of the current job instance. Finish the execution of the records currently in-flight, but do not pull any more records from the queues and set the job instance into a
FAILUREstate. The On Complete phase is invoked. - Continue processing the batch regardless of any failed records, using the
acceptExpressionandacceptPolicyattributes to instruct subsequent batch steps how to handle failed records. - Continue processing the batch regardless of any failed records (using the
acceptExpressionandacceptPolicyattributes to instruct subsequent batch steps on how to handle failed records) until the batch job accumulates a maximum number of failed records, at which point the execution will halt, just like in option 1.
In the last 2 cases, in the ONLY_FAILURES Batch Step, push the failed record into DLQ or some storage system like DB.
e. Error from the First Successful router
Handle the error thrown when none of the configured routes execute successfully by pushing the message into a DLQ or some storage system like DB.
Conclusion
This is an effort to collate solutions to various reliability issues in one place. Mule developers keen on building highly reliable applications can refer to the exhaustive list.
Keep in mind that with some of these solutions/practices, performance might take a hit, so be cautious while choosing.
Thank you for reading !! Hope you find this article helpful in whatever possible. Please don’t forget to like and share and feel free to share your thoughts in the comments section.
If interested, please go through my previous blog on how to build high performant Mule applications here.
Opinions expressed by DZone contributors are their own.
Comments