Bending CAP Theorem in Geo-Distributed Deployments With CRDTs
Learn about CRDTs, which maintain the additional decrements between syncs and across multiple concurrent writes with full correctness.
Join the DZone community and get the full member experience.
Join For Free12 years after the original CAP theorem, Eric Brewer wrote a great article on how the rules have changed on CAP. The summary is that using CRDTs (conflict-free replicated data types), one can create a new balance between C, A, and P — commonly referred to as strong eventual consistency.
I will provide a more practical guide here to why CRDTs are great for applications and how CRDT implementation in Redis to provide simplified development for applications running across multiple datacenters.
Why CRDTs?
CRDTs achieve an important goal:
Provide a mechanism that can simplify development of active-active geo-distributed deployments that can intelligently handle conflicting writes to achieve better CAP balance than existing CP or AP based databases.
Building complex distributed systems that behave correctly under a large variety of failures are hard. CRDTs make it safer and easier to deal with conflicting writes across geo-distributed active-active systems. It is ambitious. There is one big practical problem, however! CRDTs require the system to understand developer intent. Otherwise, how can you tell if a decimal value is a counter that should accumulate all increments/decrements or an absolute value with only its latest updated value wins?
For example, with starting value of 5 lets imagine we receive updates from datacenter 1 and 2 (DC1 and DC2)
- final value for a counter would be (5+3 in DC1) & (5+2 in DC2) == 10 Or
- final value for an abslute value would be - (5+3 in DC1) & (5+2 in DC2) == 7 or 8 depending on which happen later!
Which one did the developer intend? Should we use a counter logic or abslute number logic to resolve the conflicting writes?
Today, databases use either tables (row/columns) or documents (XML or JSON) as common-denominator building blocks for modeling data. These existing data modeling approaches cannot distinguish between a "products" table/JSON document vs. "customers" table/JSON document or how each attribute should behave under a conflicting write — counter/absolute.
Here is a more concrete example:
Customer record/document tracks customer cell phone calls and minutes for billing cycle metering.
Your
used-minutesvalue is incremented as you take calls.Your
callersarray records the caller details on all your calls.
Each recording can happen in US-east or US-west data center. When conflicting write happens to the
used-minutescounter and thecallersarray, the conflict handling logic needs to be smart.used-minutesneeds to understand local increments and accurately calculate final used minutes without double-counting the increases from the updates to each data center (east and west).callers, however, needs to maintain both additions to the array so that no caller detail is lost when accumulating caller details.
In NoSQL and relational databases, however, in table/XML/JSON, the basic types like counters or arrays are not distinguished in handling conflicting writes. In most NoSQLs, LWW (last-writer-wins) semantics is fairly common. In an active-active geo distributed deployment, LWW would cause lost-updates in both in used-minutes and in callers type column. CRDTs devise a mechanism that won't suffer lost-updates.
On the other hand, CRDT provides a simple and safe way to resolve these conflicts based on developer intent. Redis provides structures as the core data modeling tools. Redis provides counters, sets, bitmaps, lists, tables, etc., and each data structure comes with its own commands. In Redis, detecting developers intent is simpler. A counter type data can use INCRBY to increment used-minutes and use a SADD to add a new member to a set for tracking callers. In turn, Redis CRDTs can resolve conflicting writes by looking at data types and commands used and apply logic to resolve conflict in a way that understands the developers intent.
What Are CRDTs?
Conflict-free replicated data types (CRDTs) refer to replicated data structures that can be independently updated without costly coordination (such as two-phase-commit) and with built-in conflict resolutions that are smarter than (LWW last writer wins).
What is great about the use of CRDTs is that the developers simply don't have to deal with the complexity of distributed concurrent writes. The CRDTs takes on the required conflict resolution and tracking.
Using CRDTs in Applications
There are a few occasions that make CRDTs essential for geo-distributed apps.
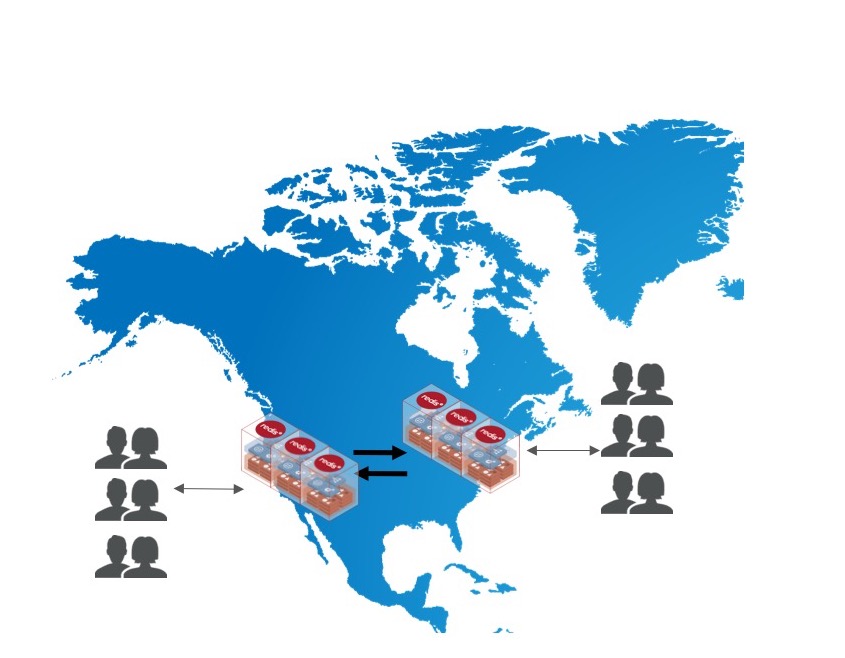
1. Geo-Failover Across Data Centers
Data centers can experience either momentary or long-lasting failures or simply undergo maintenance. In all cases, there is a geo-failover that takes place to redirect local users to the remaining available geography.
There are a number of issues that can go wrong under geo failover that can cause lost-updates. Here is an example.
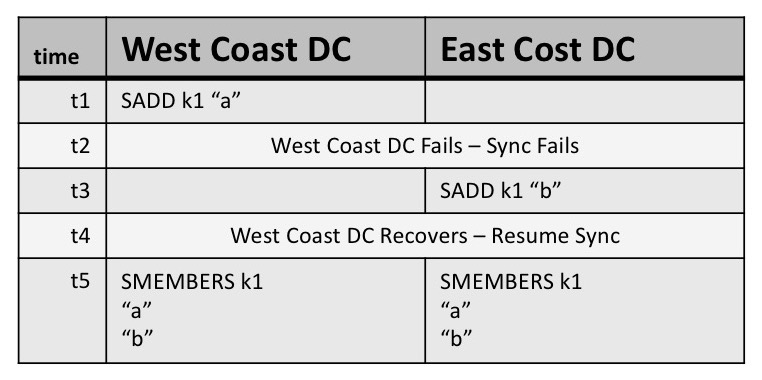
Imagine we have a shopping-cart maintained in a Redis Set. The cart is updated as users add products like "a" and "b". However, while the shopper is live, a west coast DC failure requires us to continue shopping cart updates for this user to go to east coast DC. Once the west coast DC recovers (at t4), with CRDTs, the shopping cart would correctly reflect all items user had in the shopping cart even though a geo-failover happened.
In this case, if you happen to be using a database that does LWW (last-writer-wins), the shopping cart can only contain either only "a" or only "b" because only one of your updates to k1 the shopping cart key will survive. This is a lost update! CRDTs make it safer. You don't lose any of your updates to the shopping cart.
2. Geo-Distributed Concurrent Writes (Active-Active)
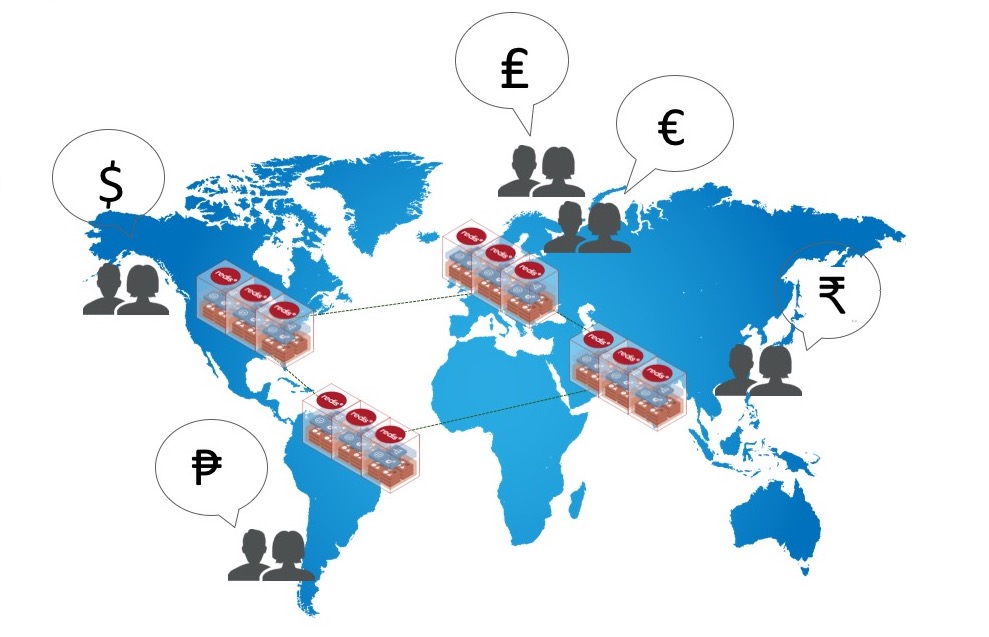 There are many apps in which capturing, metering, analyzing distributed events is required. These could be apps detecting fraud, social apps collecting interactions, chat, and other communications apps allowing conversations and so on. In these cases, a concurrent update to a Redis HashTable or Set happens across multiple regions. Databases that cannot merge these concurrent updates correctly will lose data.
There are many apps in which capturing, metering, analyzing distributed events is required. These could be apps detecting fraud, social apps collecting interactions, chat, and other communications apps allowing conversations and so on. In these cases, a concurrent update to a Redis HashTable or Set happens across multiple regions. Databases that cannot merge these concurrent updates correctly will lose data.
Let's pick up our previous example. Imagine a case where we are metering minutes usage under an account and we need to report the remaining time. The caller gets calls from many different users worldwide and there are many local databases that read and write data as calls are made that reduce minutes from both the caller and the receiver of the call.
User1 has 100 minutes of remaining talk time. At time t1, a US cell tower records a ten-minute call. Remaining minutes are decremented on key user1::used-minutes by 10.
At t2, the cell tower records a 15-minute call from Europe. This time, the European data center receives the write as the caller's cell tower is located there. However, as the call at t1 has not been replicated to the European data center yet, the local record still shows that the caller has 100 minutes and reports remaining minutes "85" with the GET on user1::used-minutes.
At t3, clusters in US and European data centers sync.
At t4, both data centers correctly report that the user has 75 minutes remaining.
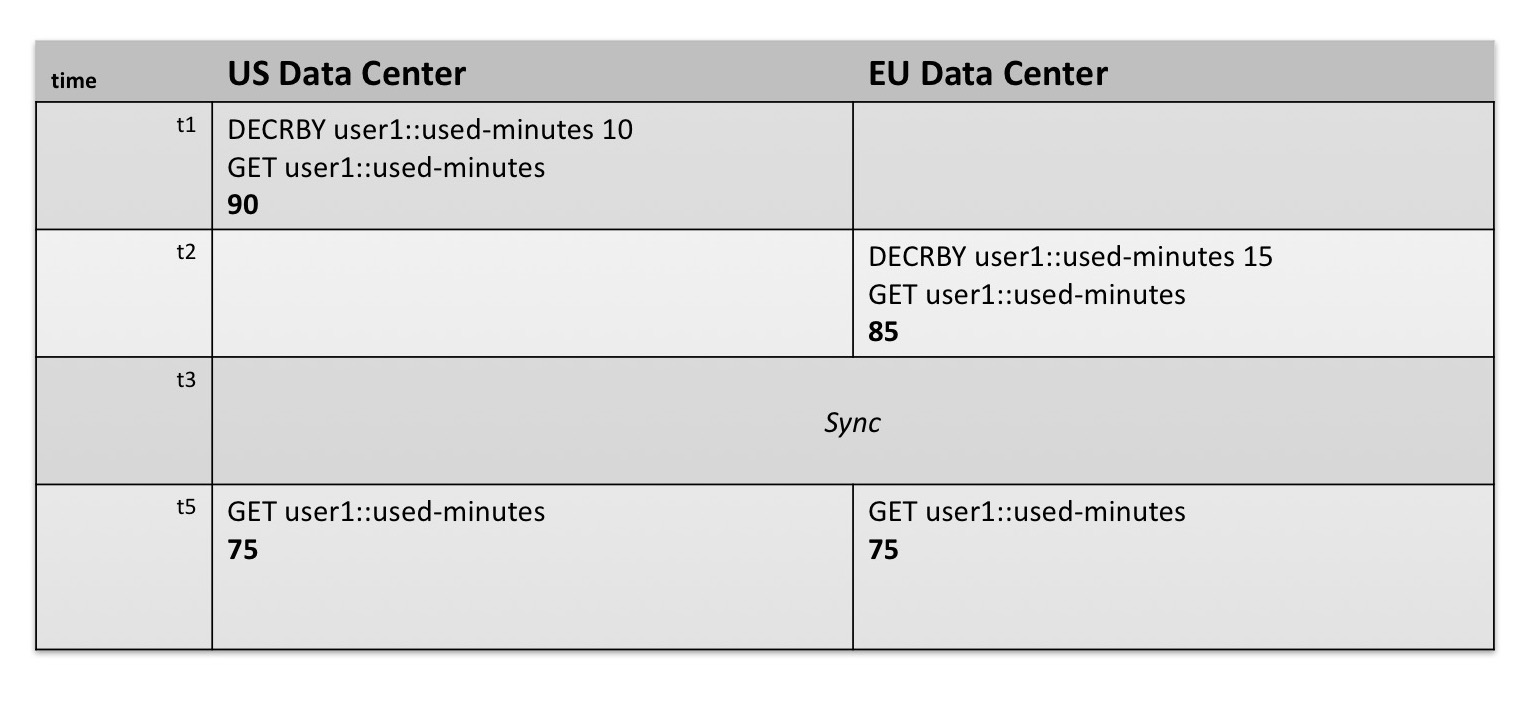
In this case, if the database misses accurately, adding up the remaining minutes or simply maintaining an absolute number of remaining minutes, we experience a lost update. CRDTs maintain the additional decrements between syncs and across multiple concurrent writes with full correctness.
We just scratched the surface here with CRDTs and what the Redis CRDT implementation can do in active-active geo-distributed deployments.
If you'd like to get hand on with CRDTs in Redis, you can get started here.
Opinions expressed by DZone contributors are their own.
Comments