Azure Databricks: 14 Best Practices For a Developer
From the choice of programming language to Git integration, this article covers 14 recommended best practices for developers working with Azure Databricks.
Join the DZone community and get the full member experience.
Join For Free1. Choice of Programming Language
- The language depends on the type of cluster. A cluster can comprise of two modes, i.e., Standard and High Concurrency. A High Concurrency cluster supports R, Python, and SQL, whereas a Standard cluster supports Scala, Java, SQL, Python, and R.
- Spark is developed in Scala and is the underlying processing engine of Databricks. Scala performs better than Python and SQL. Hence, for the Standard cluster, Scala is the recommended language for developing Spark jobs.
2. ADF for Invoking Databricks Notebooks
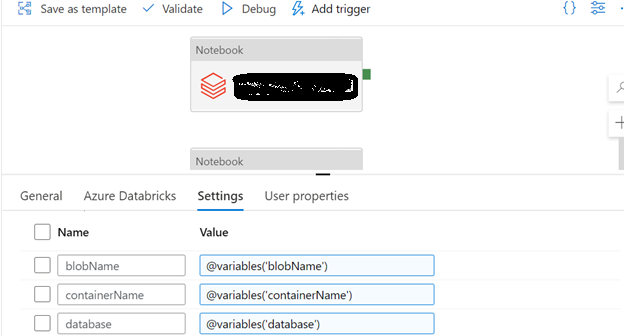
- Eliminate Hardcoding: In certain scenarios, Databricks requires some configuration information related to other Azure services such as storage account name, database server name, etc. The ADF pipeline uses pipeline variables for storing the configuration details. During the Databricks notebook invocation within the ADF pipeline, the configuration details are transferred from pipeline variables to Databricks widget variables, thereby eliminating hardcoding in the Databricks notebooks.
![Databricks Notebook Settings]()
- Notebook Dependencies: It is relatively easier to establish notebook dependencies in ADF than in Databricks itself. In case of failure, debugging a series of notebook invocations in an ADF pipeline is convenient.
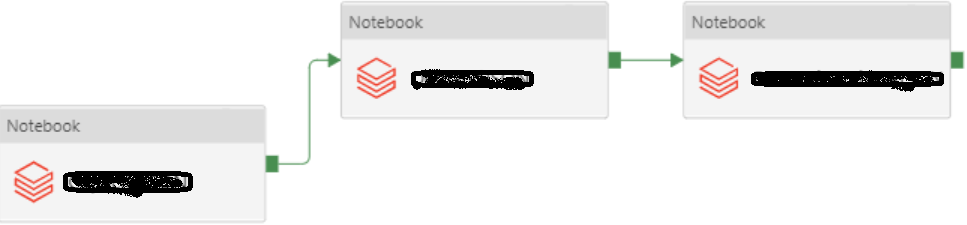
- Cheap: When a Notebook is invoked through ADF, the Ephemeral job cluster pattern is used for processing the spark job because the lifecycle of the cluster is tied to the job lifecycle. These short-life clusters cost lesser than the clusters which are created using the Databricks UI.
3. Using Widget Variables
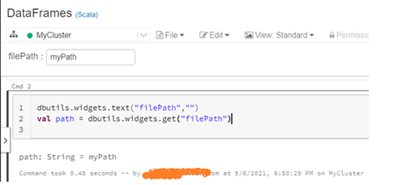
The configuration details are made accessible to the Databricks code through the widget variables. The configuration data is transferred from pipeline variable to widget variables when the notebook is invoked in the ADF pipeline. During the development phase, to model the behavior of a notebook run by ADF, widget variables are manually created using the following line of code.

Executing the above line of code will create a labeled text box at top of the notebook. The required value can be typed in this text box. This way, a notebook can be tested before executing it from an ADF pipeline.
4. Key Vault for Storing Access Keys
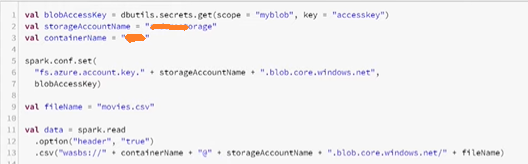
Avoid hardcoding of sensitive information within the code. Store all the sensitive information such as storage account keys, database username, database password, etc., in a key vault. Access the key vault in Databricks through a secret scope.
5. Organization of Notebooks
Suppose multiple teams work on a single Databricks workspace. In that case, it's advisable to create separate folders for each group. The notebooks corresponding to each of these groups are stored in their respective folders.
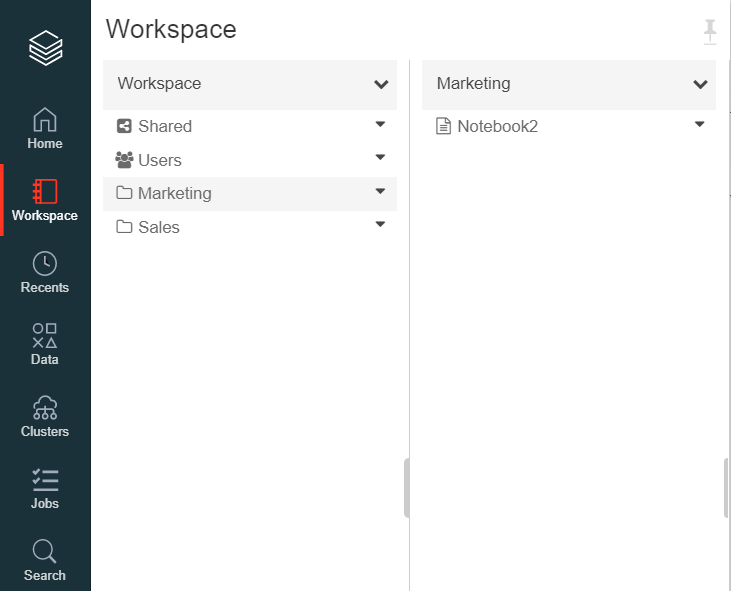
In the above screenshot, there are two folders in the Databricks workspace, Sales and Marketing. Developers from the Sales and Marketing team can create notebooks in their respective folders.
6. Include Appropriate Documentation
Every high-level programming language provides a feature for adding comments in the code script. In addition to this, Databricks provides a feature for writing well-formatted documentation/text in the notebook cells. Use "%md" in a cell for adding the required documentation.
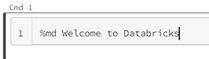
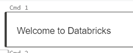
7. Use AutoComplete to Avoid Typographical Errors
This is a useful feature while developing programs in Databricks notebooks. You can use the 'tab' button for auto-complete suggestions. This helps in eliminating typographical errors.
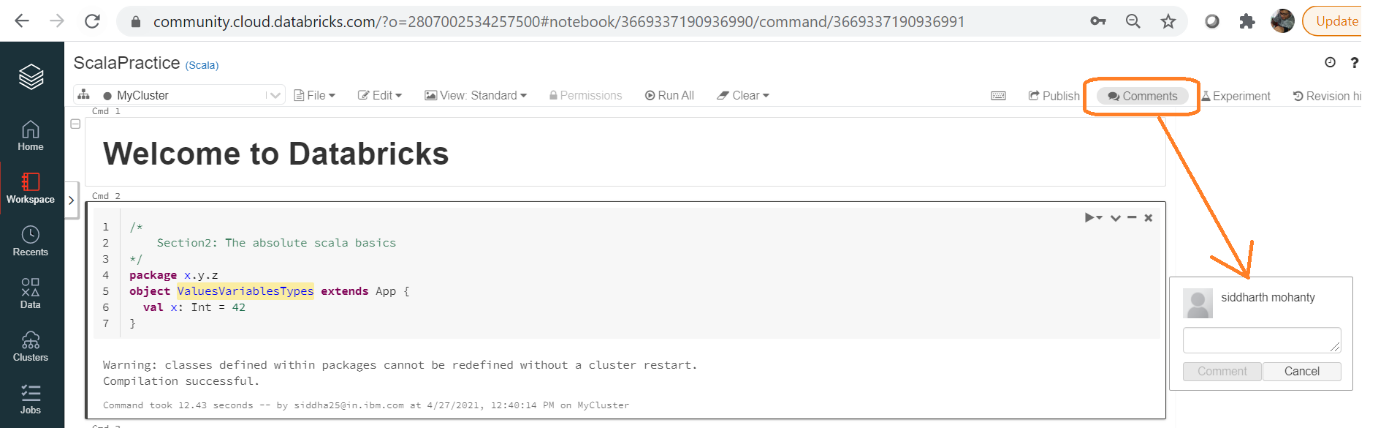
8. Use the 'Comments' Feature for Code Review
Code reviews are convenient due to the "Comments" option in Databricks. The reviewer can easily add the comments by highlighting the affected code.
9. Use the 'Format SQL' Option for Formatting the SQL Cells
A well-formatted SQL query is easy to read and understand. Databricks offers a dedicated feature for formatting SQL cells. Use this feature as much as possible. The "Format SQL code" option can be found in the "Edit" section.
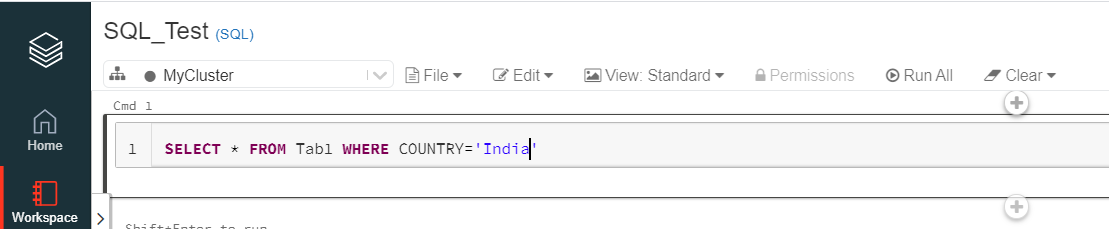

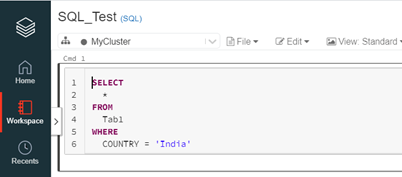
10. Always Keep Checking the 'Advisor' Option
After the first run, the Advisor option analyses the entire run and, if required, suggest some optimizations. Implementing the suggestions might drastically increase the efficiency of the job. 
11. Run a Notebook From Another Notebook
It is always a good practice to include all the repeatedly used operations such as read/write on Data Lake, SQL Database, etc., in one generic Notebook. The same Notebook can be used to set the Spark configurations, mounting ADLS path to DBFS, fetching the secrets from secret scope, etc.
For using the operations defined in the generic Notebook from other notebooks, it should be invoked using the "run" command. The following relative path can be used if both the notebooks, i.e., “FGCurated” and “Test” are in the same directory.
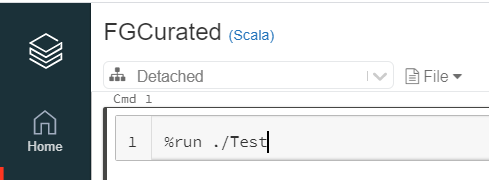
12. Spark Session Isolation
It is a good practice to use isolated Spark sessions due to security reasons. The Spark session isolation is enabled by default. If there is a requirement to share data across multiple Spark sessions, use the createOrReplaceGlobalTempView instead of createOrReplaceTempView. The session isolation can be disabled by setting spark.databricks.session.share as true. Enabling this option lets createOrReplaceTempView to share data across multiple Spark sessions.
13. Git Integration
During the development phase, it is a good practice to link the notebook to a GIT feature branch. In case the notebook is deleted accidentally, the changes continue to persist in the feature branch.
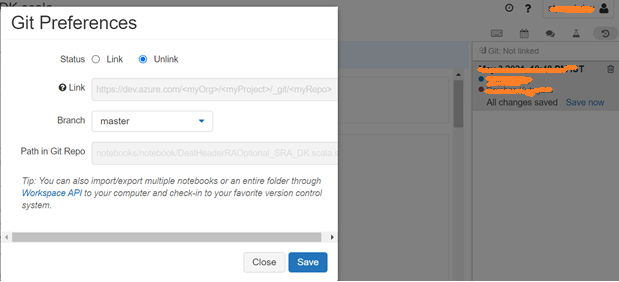
14. Directly Viewing the Content of a File
If you want to inspect some records in a flat-file such as CSV or JSON, following the Databricks command is handy. This approach avoids loading the data into a Dataframe and then displaying the data.
dbutils.fs.head(“<path>”)
An alternative way for viewing data directly is by using the following SQL statement.
xxxxxxxxxx
display(spark.sql("SELECT * FROM csv.`/databricks-datasets/airlines/part-00000`"))

This approach works for both flat and binary files. For reading other formats such as JSON or parquet, in the query, replace the string "csv" with either "json" or "parquet".
display(spark.sql("SELECT * FROM json.`/databricks-datasets/airlines/part-00000`"))
display(spark.sql("SELECT * FROM parquet.`/databricks-datasets/airlines/part-00000`"))
Opinions expressed by DZone contributors are their own.
Comments