AWS Step Function for Modernization of Integration Involving High-Volume Transaction: A Case Study
The serverless offerings of AWS are getting more and more popular. But it remains a challenge to know them well enough to leverage them properly.
Join the DZone community and get the full member experience.
Join For FreeThe serverless offerings of AWS (or any other public cloud provider today) are getting more and more popular. One of the biggest reasons is of course not needing to think about infra (server provisioning and so on). The other reasons include the offerings themselves, which at times fit well into the technical need for finding solutions to the given problems. But on the other side, it remains a challenge to know the offerings in detail to leverage them properly. There could be always some new feature hidden deep inside the bulk of the documentation.
Background
A retail company decided to leverage the AWS Serverless offering for modernizing their on-premises integrations for order management business process. We can go serverless in the cloud in various ways, but the initial solutioning was decided to leverage the Step Function and Lambda Function along with some more integration offerings from AWS, namely SNS, SQS, and EventBridge.
The coding was done, so the unit testing and system integration testing followed by the UAT. Everything looked fine. It went live and started handling the transactions quite well. And then one day, there was an unplanned AWS outage spanning almost a whole business day. What could happen next? Let’s see.
Challenge With the Initial Solution
The outage brought on a disastrous situation. While the integration was designed to get triggered by an EventBridge schedule, it was the Lambda Function which would pull the inbound payloads from the SQS which would in turn subscribe to the SNS topic where the order management system would publish the payloads when an order would be placed from the portal, due to the outage, the inbound payloads got piled up in the SQS. Not only that, but the messages which were ingested into the database got piled up unprocessed.
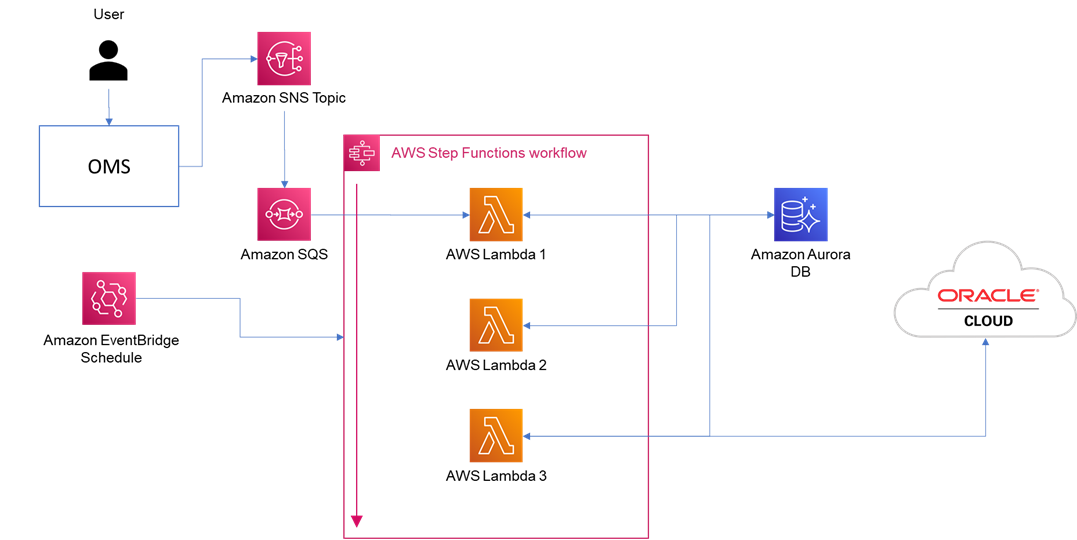
And then the real challenge began once the outage was restored. The flows started progressing, but the rate of the payloads getting processed were too low to cope with the business need. That low rate being allowed, the whole set of pending transactions would take months to complete, which was obviously not rationally acceptable. So, the need for the moment became to enhance the solution in a way that scales up when needed to reduce the backlogs.
Improved Solution
The current design had three Lambda Functions — the first one would pull the payloads from the SQS and insert it into the database, the second one would parse those and insert the values as records in another table in the database, the third one would process the records, i.e., invoke Oracle ERP APIs (the company is using Oracle ERP as matter of their choice) to create, update, or delete the purchase orders there. The Step Function would be triggered by the EventBridge rule. At first, the Lambda 1 would be executed inserting the pulled payloads into the table. The Lambda 2 would then iterate over the unparsed payloads in the database to parse each of the payloads and insert the respective records into the database. Lambda 3 would then iterate over the unprocessed records in the table and process those as required by invoking APIs and so on.
The catch is: The queries used to select the unparsed or unprocessed records from the database would be limited by the maximum number of records those could fetch based on how much time the respective Lambda Function would take to process those. This is required because Lambda Function in AWS can run only up to 15 minutes, beyond which it will time out and stop its execution abruptly.
That’s fair enough from the AWS offering perspective, because Lambda Function is not intended to be used for long-running jobs. Also, it's fair to raise a question on the initial design decision to use Lambda Function for this integration. A better solution could be leveraging an EC2 instance or a containerized solution leveraging AWS Fargate, if staying serverless was one of the key requirements. But here, we would focus only on the capability of the Step Function to scale up to handle the given situation. The same feature of the Step Function can be leveraged in other scenarios that might appear when modernizing integrations, especially when there is a need for orchestration or workflow and when we prefer to go serverless.
AWS Step Function comes with some features that help achieving parallel execution. The State Machine of a Step Function is basically a collection of states and there are some defined state types which must be mentioned for each state. The state type that is commonly used to trigger a Lambda Function is "Task." As the name explains, the Lambda Function is supposed to perform some tasks.
Out of the remaining state types, two which are relevant to this topic are "Map" and "Parallel." Well, the answer to this problem is Map State, but why am I mentioning the "Parallel?" There is a thin line of difference between them, but the names can really be misleading at times. It is worth explaining the difference in this context.
To explain in simple words — a Parallel State is for performing two or more set of tasks in parallel but on the same input. A Map State is for performing a same set of tasks concurrently on each item of a given list of inputs. The below diagrams can be helpful to understand it better.
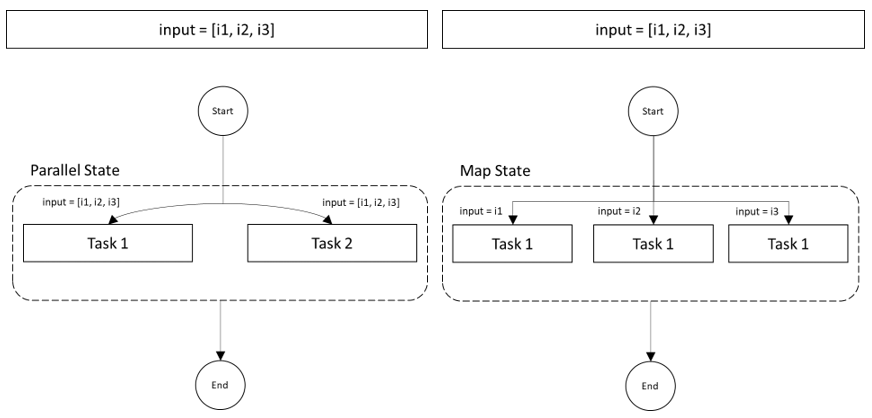
The above diagram may make it clear why Map State is the desired option in this case. To explain the improved solution more specifically in detail:
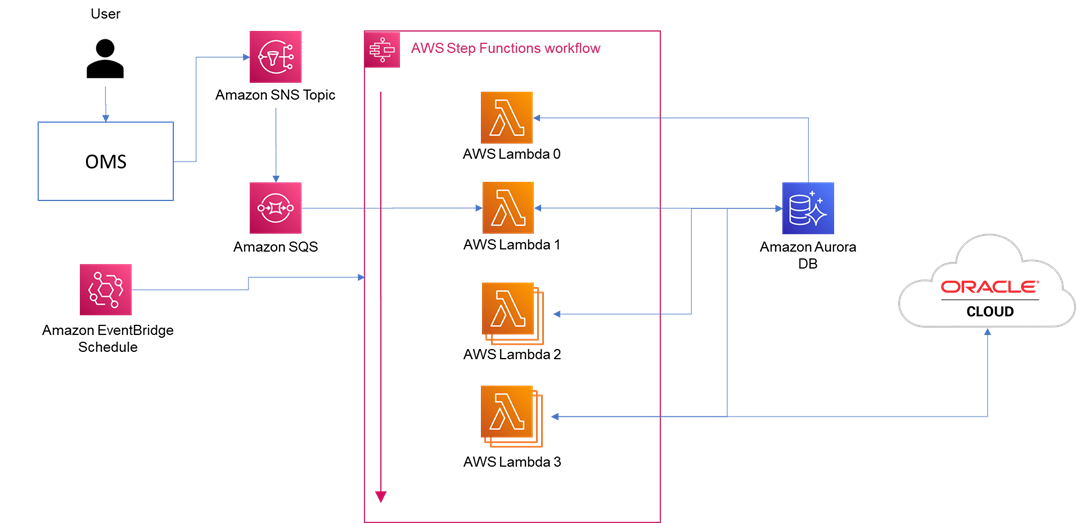
- The Lambda 2 and 3 need to be inside two Map States respective to each of them.
- A new Lambda 0 needs to be incorporated which would first prepare the input arrays of the Lambda 2 and 3. It would do that by querying the database tables to fetch the unparsed and unprocessed records.
- The Lambda 1 will not require to be in a Map State, as that would still pull the messages from the SQS and insert into the table.
- In every execution of the State Machine, the Lambda 0 would prepare the input arrays based on what was inserted into the tables by the Lambda 1 and the Lambda 2 in the previous execution of the State Machine which would respectively become the input for the Lambda 2 and the Lambda 3 in the current execution of the State Machine.
- The input array of Lambda 2 would be a list of the list of unique identifiers of the inserted payloads. The input array of Lambda 3 would be a list of the list of unique identifiers of the parsed records.
- Step Function requires the input array to be set at the field ItemsPath (this is specific to the Map State, i.e., “Type”: “Map”. It would be set from the Lambda Function code of the Lambda 0 and would be propagated through the Step Function.
- The value of the field MaxConcurrency would be set as 0 (the default value so also the same) which means there is no quota on parallelism and the State Machine would execute as much in parallel as possible. However, the architect/development team would decide the sizes of the inner and outer lists of the input arrays which would respectively mean the number of payloads/records that the Lambda Function would be allowed to process per instance of execution and the number of instances of the execution (in other words, the number of iterations) which in turn would be the limit of parallelism as well. The database would be queried by the Lambda 0 according to these configurable numbers (Lambda Function’s environment variable could be leveraged).
After this solution was implemented, the backlog took around 24 hours to get cleared. However, it was not an all-green situation. The backlog was cleared but the Operations Team observed further challenges over time which were even more deep-rooted to the fundamental design decisions of this solution.
Further Challenges
Like it happens in any standard retail order management business process, the high-level steps of the order journey remain, like Purchase Order (PO) Creation > Receipt of the PO > Invoice Generation of the PO > Return/Replacement Processing (if any). There were integrations for each of these modules which were modernized following the same design pattern. That said, the challenges observed over the time were as below.
- Time Lag Issue – Many times, it was observed that the PO for which the integration tried to generate the invoice or receipt was not even created in the Oracle ERP at that point of time. It could be due to various reasons, but typically, the observation was depending on the transactional volume. Some PO creation and the respective receipt creation would get delayed, and by the time those were processed, the integration would get the invoice generation request. This is mainly because the source application responsible for the invoice generation is agnostic about the PO creation status.
A possible solution could be usage of SNS FIFO topic with SQS FIFO queue to achieve the fan-out pattern across all these integrations to ensure the sequence of events are processed in the same sequence as generated. But there could be many other ways of solving this issue (e.g., publishing the PO creation status to an SNS topic and have all the involved systems subscribed to that topic to sync it across those systems and so on) subject to the technical feasibilities and dependencies.
- Intermittent Lack of Parallelism Issue – Despite using the Map State in the Step Function, it was observed that sometimes some iterations would not start until the previous ones are completed. This issue increases especially when the input array size is greater than 40. This is a known limitation as mentioned in the AWS documentation.
There could be two possible ways to resolve this.
- The concurrency limit could be restricted such that it does not exceed 40. However, that might again impact or limit the desired performance of the integration.
- In order to achieve higher concurrency, the State Machines could be nested that cascades the Map States. In this way, the Step Function code would become more complex but higher concurrency can be achieved.
Takeaway
Modernization of integrations using Lambda Functions alone may not always be a favorable option, especially when the integration has huge transformation logic and a high volume of transactional requirements. It may shoot up the cost too high in those cases, or sometimes fail miserably to scale up. However, some of the Step Function features (when used to orchestrate the tasks defined in Lambda Functions) may be helpful to come up with decent and flexible solutions in terms of scalability.
Sample Code of Step Function
The below is sample code with similar orchestration logic as described in the improved solution for this case study. This is not the exact solution, but just an indicative sample.
{
"Comment": "A description of my state machine",
"StartAt": "Process ID Concurrently",
"States": {
"Process ID Concurrently": {
"Type": "Map",
"ItemsPath": "$.id",
"Iterator": {
"StartAt": "Perform ID Task",
"States": {
"Perform ID Task": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:495125011821:function:ProcessUniqueID:$LATEST",
"End": true
}
}
},
"ResultPath": null,
"Next": "Process Name Concurrently"
},
"Process Name Concurrently": {
"Type": "Map",
"ItemsPath": "$.name",
"Iterator": {
"StartAt": "Perform Name Task",
"States": {
"Perform Name Task": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:495125011821:function:ProcessUniqueName:$LATEST",
"End": true
}
}
},
"End": true
}
}
}Sample Execution
The above sample Step Function, when executed with an input as seen in the screenshot below, identifies the iterations for each Map State and executes them concurrently.

The below timestamps show that each of the three iterations of the first Map State started exactly at the same time, ensuring concurrency.
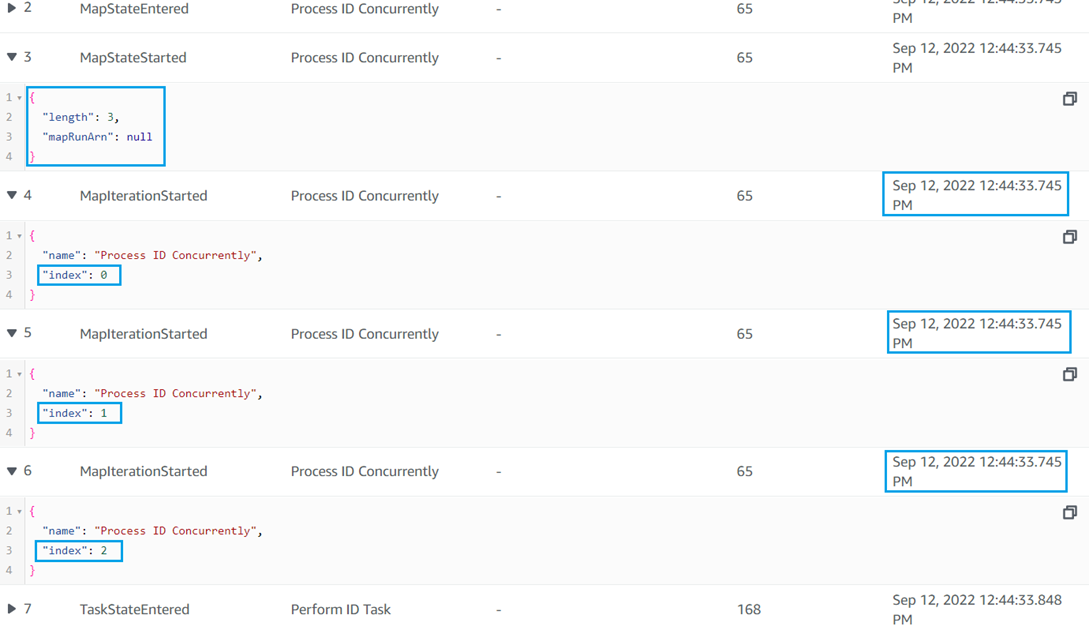
The below timestamps show that each of the two iterations of the second Map State started exactly at the same time, ensuring concurrency. Also, it is noticeable that this state started after the first Map State was completed, i.e., two separate Map States are not concurrently executed.
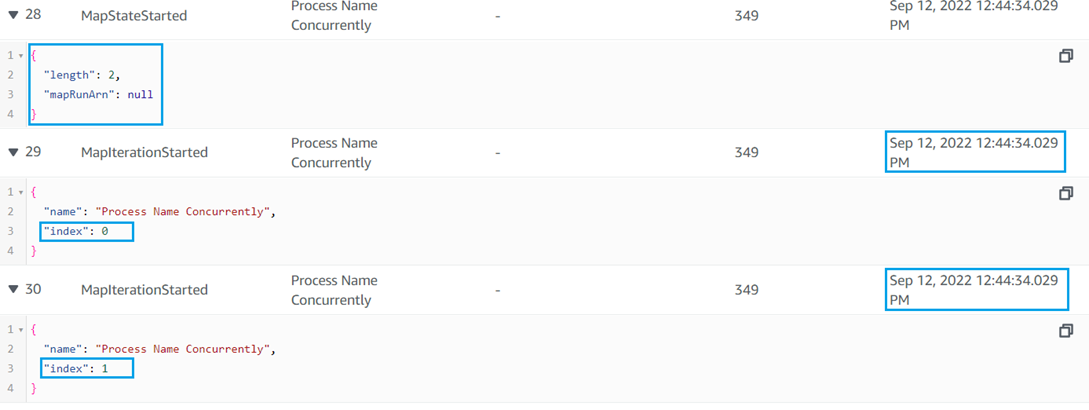
The below screenshot shows the three iterations for the first Map State have taken each item in the outer list of the JSON input as their individual inputs.
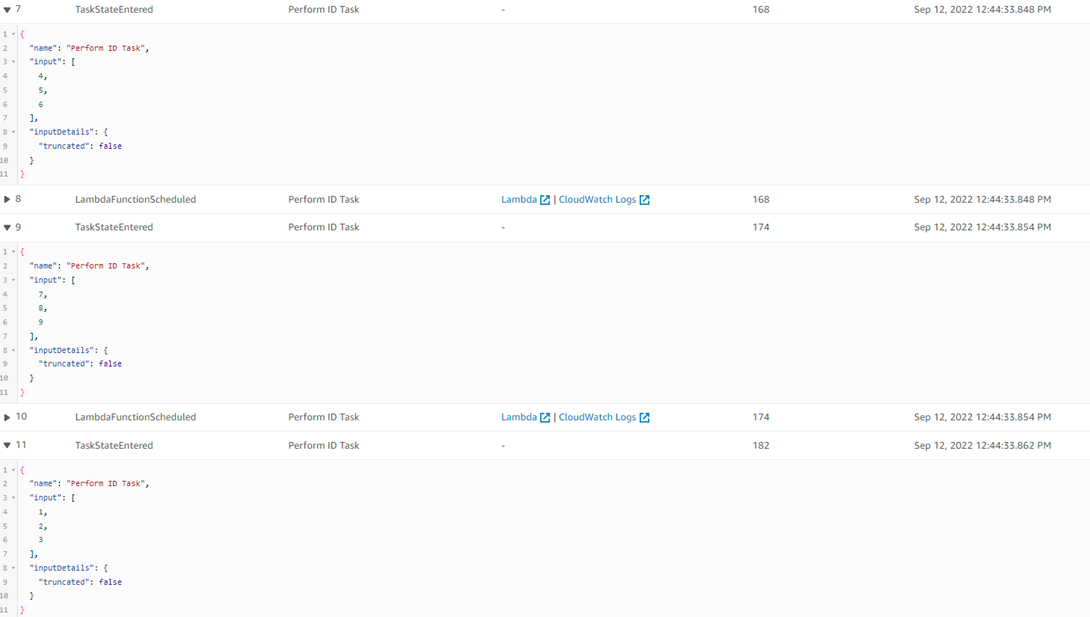
The below screenshot shows the two iterations for the second Map State have taken each item in the outer list of the JSON input as their individual inputs.
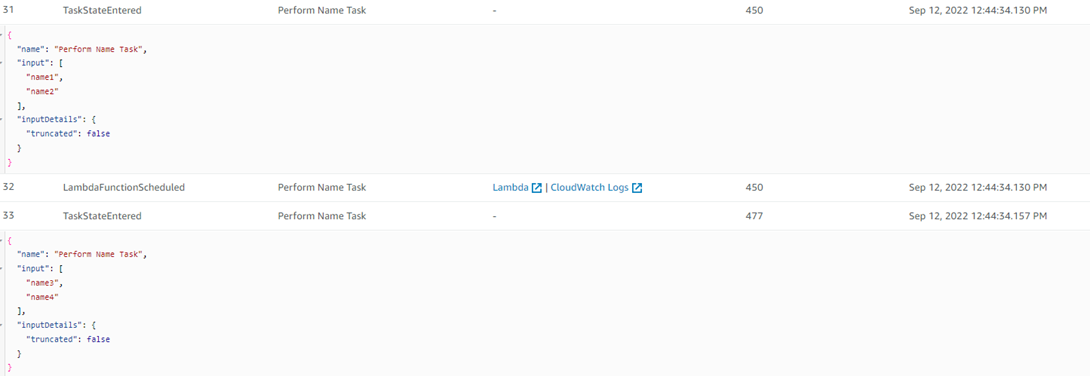
The below screenshot shows the CouldWatch Log for the Lambda (ProcessUniqueID) which is invoked from the first Map State to perform the ID Task.
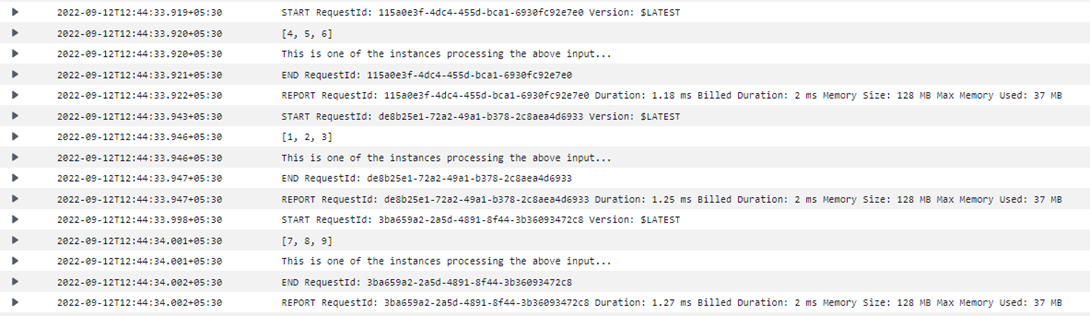
The below screenshot shows the CouldWatch Log for the Lambda (ProcessUniqueName) which is invoked from the second Map State to perform the Name Task.


Opinions expressed by DZone contributors are their own.
Comments