AWS S3 Access via API Gateway, IaC, and More
If you are currently developing or looking to start developing apps on the AWS serverless stack, then keep on reading for useful and interesting insights.
Join the DZone community and get the full member experience.
Join For FreeIf you are currently developing or looking to start developing apps on the AWS serverless stack, I think you will find this article interesting and helpful.
Earlier this year I published an article on DZone describing my journey from cloud architecture to cloud reliability engineering. This journey started with a Python Flask POC and ended with a full-fledged AWS serverless application. I also developed a DevOps pipeline with GitHub, CodeBuild, Terraform Enterprise, and an observability pipeline with CloudWatch, PagerDuty, and ServiceNow.
Scripting the entire AWS technology stack with infrastructure as code (IaC) — HashiCorp Terraform was cool. Creating a fully functional application stack throughout SDLC environments in 10 minutes — that was even cooler.
The initial design described in the previous article included a CRUD API for the client investment profile (CIP) data using the AWS Serverless Stack. The CIP JSON payload contained the record metadata and a binary proposal document. The message payload size was initially estimated to be around 4 MB. Since both AWS API Gateway and Lambda support this payload size, I decided to engineer this REST API for synchronous data ingestion. This design significantly simplified error handling in real-time.
Here is the simplified architecture and it is reduced to the relevant context.
Current Sate

This solution worked just fine until late into UAT when the payload size suddenly increased beyond 6 MB. The API Gateways returned the following error message with the error code 413:
{
"message": "Request Too Long"
}
One potential solution was to abandon the serverless design and revert to the Flask microservice deployed on either EC2 or ECS. Although this option did not entail a significant re-engineering overhaul, its major drawback was compromising the initial objectives for the serverless design, performance tuning, elastic scalability, and optimal cost for each Lambda function based on usage. I set out to find another solution for ingesting a large API payload while leaving the rest of the application architecture intact.
Target State

Here is the solution outline, built on top of the previous architecture, also simplified for this article:
- SaaS app calls an external API proxy.
- The external API proxy invokes the existing API if the payload size is less than 5 MB and the new API for a larger payload size.
- Both APIs are private and accessible via a VPC Endpoint.
Let’s walk through the new API design that can ingest a large message payload:
4. The API backend is the S3 service. The API invokes the PutObject command to store the JSON payload in an S3 bucket.
5. S3 bucket triggers SQS on the PutObject event.
6. Lambda “long polls” the SQS queue.
7. Once triggered, the Lambda function retrieves the JSON payload from the S3 bucket.
8. The Lambda function executes the same logic as the other Lambda function triggered by the API Gateway. It made sense to deploy the same codebase for both Lambda functions to avoid code duplication.
Codebase

In the rest of this article, I will take you through the steps of creating the proxy API Gateway to store documents in S3 without a single line of code.
The first step is to add binary media type to your API Setting so the API Gateway can encode and decode the message payload based on the Content-Type HTTP header.
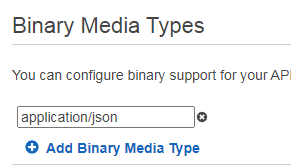
The AWS API Gateway threats an API route as a resource or composition of multiple resources. I created a static resource called proposals, a path parameter as a dynamic resource called item, and the POST HTTP method.
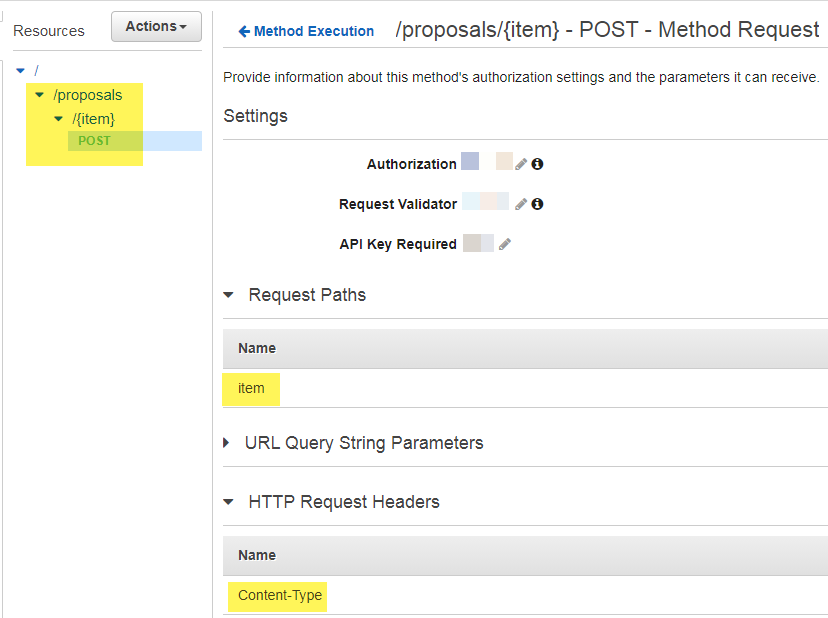
In Method Request, I declared the path parameter called item and the header Content-Type. Think of it as the variable declaration section to be referenced later.
Method Request
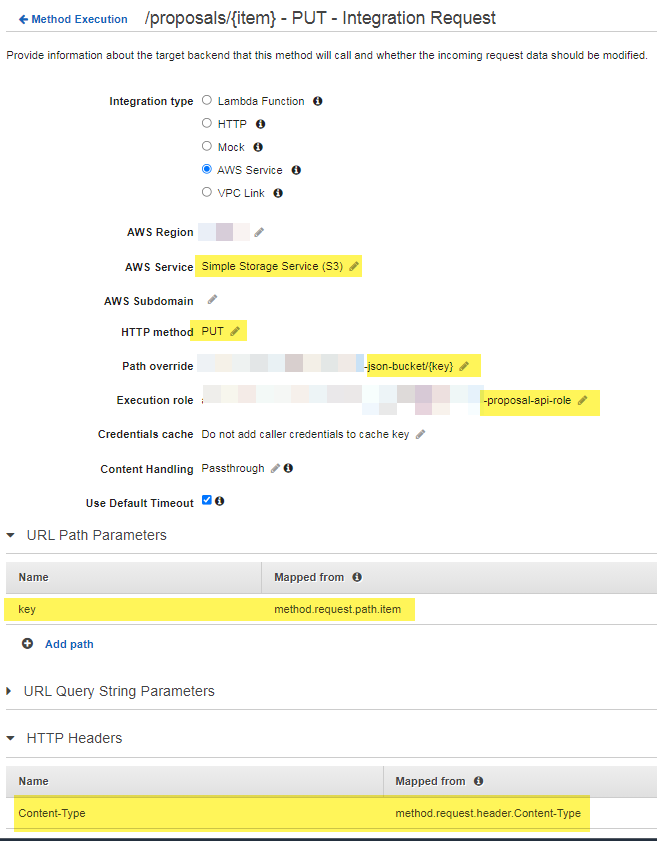
The Integration Request section is where I configured the backend integration. In this case, the backend is another AWS service S3. I provided the S3 bucket name and the execution role.
Important detail: The "key" path parameter referenced in the Path Overwrite is mapped to the "item" path parameter defined in the Method Request section. The Content-Type header needed for S3 integration is mapped to the same API header.
Integration Request
As I am writing this article, I discovered that the role does not have explicit S3 Bucket Write permission, but the S3 bucket access policy must explicitly declare the S3:PutObject permission.
Bucket Access Policy

Once the API has been developed and tested, I had another task of recreating this API across multiple SDLC environments. Doing this work manually and repeatedly would be a tedious and error-prone effort.
At the beginning of this article, I mentioned HashiCorp Terraform as the IaC provider. There is a Terraform resource module to create an AWS API Gateway, linked here.
REST API Terraform Resource

This module is simple to understand and to follow. I found that declaring each resource, method, and integration manually for every API route would be a painstaking effort to ensure that all module dependencies are properly cross-referenced. Thankfully, Terraform offers another way to declare the REST API with the OpenAPI specification. You can export the OpenAPI JSON from the existing API Stage section and include it in the Terraform REST API module as follows:
- Export OpenAPI
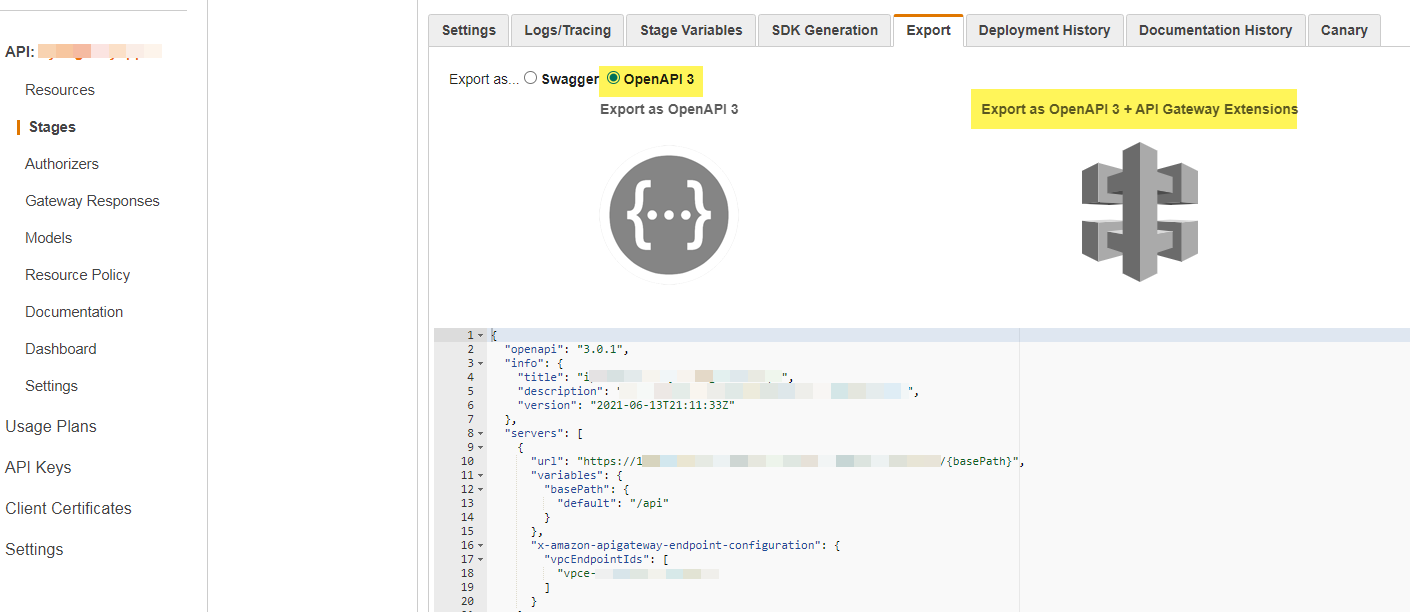
- Include OpenAPI in Terraform API Resource
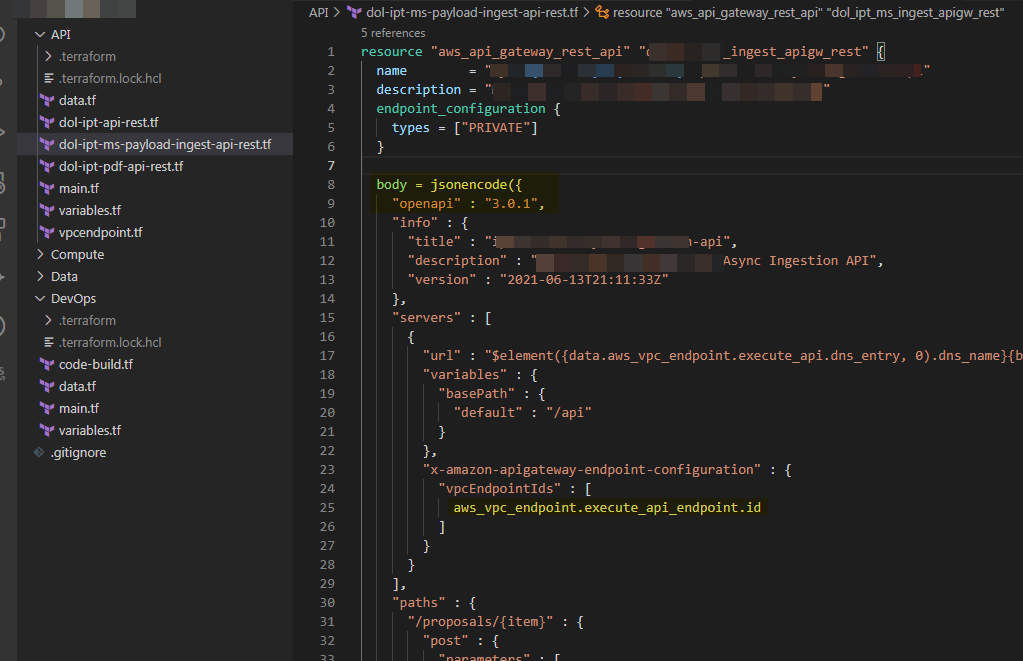
Please make sure to externalize all SDLC and AWS account-specific dependencies such as roles, buckets, and VPC endpoints to Terraform variables and data sources.
Run the following commands:
terraform initterraform fmtterraform validate
You need to execute the following commands if you do not use Terraform Enterprise:
terraform planterraform apply
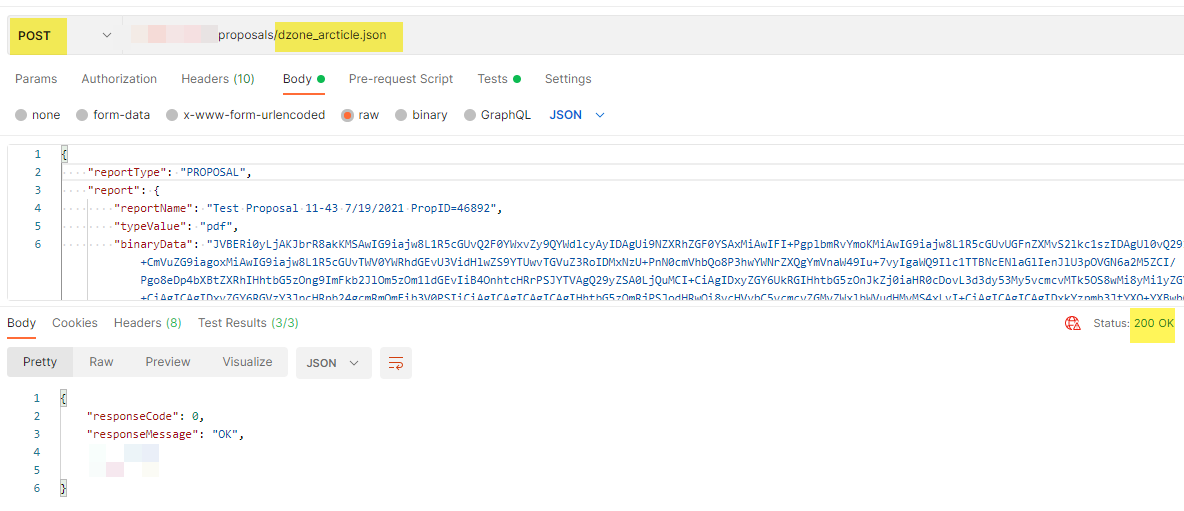
You are now ready to validate your API.
Execute the POST request.
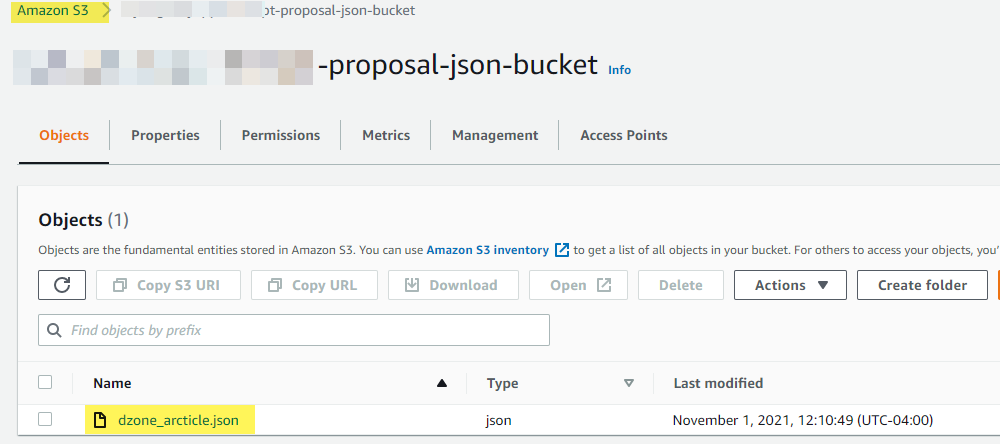
Verify that the JSON payload exists in the S3 bucket.
Great Success!!!
I hope you have enjoyed this read. You can apply this integration pattern for a large variety of use cases to ingest data and documents via API for event-driven processing. If you have any questions, please feel free to post them here or reach out to me on LinkedIn.
Opinions expressed by DZone contributors are their own.
Comments