AWS CDK: Infrastructure as Abstract Data Types, Part 2
In part 2 of this journey into the CDK world, explore how to use basic building blocks like constructs by taking advantage of Quarkus features.
Join the DZone community and get the full member experience.
Join For FreeIf you're a Java software developer and you weren't living on the planet Mars during these last years, then you certainly know what Quarkus is. And just in case you don't, you may find it out here.
With Quarkus, the field of enterprise cloud-native applications development has never been so comfortable and it never took advantage of such a friendly and professional working environment. The Internet abounds with posts and articles explaining why and how Quarkus is a must for the enterprise, cloud-native software developer. And of course, CDK applications aren't on the sidelines: on the opposite, they can greatly take advantage of the Quarkus features to become smaller, faster, and more aligned with requirements nowadays.
CDK With Quarkus
Let's look at our first CDK with Quarkus example in the code repository. Go to the Maven module named cdk-quarkus and open the file pom.xml to see how to combine specific CDK and Quarkus dependencies and plugins.
...
<dependency>
<groupId>io.quarkus.platform</groupId>
<artifactId>quarkus-bom</artifactId>
<version>${quarkus.platform.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>io.quarkiverse.amazonservices</groupId>
<artifactId>quarkus-amazon-services-bom</artifactId>
<version>${quarkus-amazon-services.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
In addition to the aws-cdk-lib artifact which represents the CDK API library and is inherited from the parent Maven module, the dependencies above are required in order to develop CDK Quarkus applications. The first one, quarkus-bom, is the Bill of Material (BOM) which includes all the other required Quarkus artifacts. Here, we're using Quarkus 3.11 which is the most recent release as of this writing. The second one is the BOM of the Quarkus extensions required to interact with AWS services.
Another mandatory requirement of Quarkus applications is the use of the quarkus-maven-plugin which is responsible for running the build and augmentation process. Let's recall that as opposed to more traditional frameworks like Spring or Jakarta EE where the application's initialization and configuration steps happen at the runtime, Quarkus performs them at build time, in a specific phase called "augmentation." Consequently, Quarkus doesn't rely on Java introspection and reflection, which is one of the reasons it is much faster than Spring, but needs to use the jandex-maven-plugin to build an index helping to discover annotated classes and beans in external modules.
This is almost all as far as the Quarkus master POM is concerned. Let's look now at the CDK submodule. But first, we need to recall that, in order to synthesize and deploy a CDK application, we need a specific working environment defined by the cdk.json file. Hence, trying to use CDK commands in a project not having at its root this file will fail.
One of the essential functions of the cdk.json file aims to define how to run the CDK application. By default, the cdk init app --language java command, used to scaffold the project's skeleton, will generate the following JSON statement:
...
"app": "mvn -e -q compile exec:java"
...
This means that whenever we run a cdk deploy ... command, such that to synthesize a CloudFormation stack and deploy it, the maven-exec-plugin will be used to compile and package the code, before starting the associated main Java class. This is the most general case, the one of a classical Java CDK application. But to run a Quarkus application, we need to observe some special conditions.
Quarkus packages an application as either a fast or a thin JAR and, if you aren't familiar with these terms, please don't hesitate to consult the documentation which explains them in detail. What interests us here is the fact that, by default, a fast JAR will be generated, under the name of quarkus-run.jar in the target/quarkus-app directory. Unless we're using Quarkus extensions for AWS, in which case a thin JAR is generated, in target/$finalName-runner.jar file, where $finalName is the value of the same element in pom.xml.
In our case, we're using Quarkus extensions for AWS and, hence, a thin JAR will be created by the Maven build process. In order to run a Quarkus thin JAR, we need to manually modify the cdk.json file to replace the line above with the following one:
...
"app": "java -jar target/quarkus-app/quarkus-run.jar"
...
The other important point to notice here is that, in general, a Quarkus application is exposing a REST API whose endpoint is started by the command above. But in our case, the one of a CDK application, there isn't any REST API and, hence, this endpoint needs to be specified in a different way. Look at our main class in the cdk-quarkus-api-gatewaymodule.
@QuarkusMain
public class CdkApiGatewayMain
{
public static void main(String... args)
{
Quarkus.run(CdkApiGatewayApp.class, args);
}
}
Here, the @QuarkusMain annotation flags the subsequent class as the application's main endpoint and, further, using the io.quarkus.runtime.Quarkus.run() method will execute the mentioned class until it receives a signal like Ctrl-C, or one of the exit methods of the same API is called.
So, we just saw how the CDK Quarkus application is started and that, once started, it runs the CdkApiGAtewayApp until it exits. This class is our CDK one which implements the App and that we've already seen in the previous post. But this time it looks differently, as you may see:
@ApplicationScoped
public class CdkApiGatewayApp implements QuarkusApplication
{
private CdkApiGatewayStack cdkApiGatewayStack;
private App app;
@Inject
public CdkApiGatewayApp (App app, CdkApiGatewayStack cdkApiGatewayStack)
{
this.app = app;
this.cdkApiGatewayStack = cdkApiGatewayStack;
}
@Override
public int run(String... args) throws Exception
{
Tags.of(app).add("project", "API Gateway with Quarkus");
Tags.of(app).add("environment", "development");
Tags.of(app).add("application", "CdkApiGatewayApp");
cdkApiGatewayStack.initStack();
app.synth();
return 0;
}
}The first thing to notice is that this time, we're using the CDI (Context and Dependency Injection) implemented by Quarkus, also called ArC, which is a subset of the Jakarta CDI 4.1 specifications. It also has another particularity: it's a build-time CDI, as opposed to the runtime Jakarta EE one. The difference lies in the augmentation process, as explained previously.
Another important point to observe is that the class implements the io.quarkus.runtime.QuarkusApplication interface which allows it to customize and perform specific actions in the context bootstrapped by the CdkApiGatewayMain class. As a matter of fact, it isn't recommended to perform such operations directly in the CdkApiGatewayMain since, at that point, Quarkus isn't completely bootstrapped and started yet.
We need to define our class as @ApplicationScoped, such that to be instantiated only once. We also used constructor injection and took advantage of the producer pattern, as you may see in the CdkApiGatewayProducer class. We override the io.quarkus.runtime.QuarkusApplication.run() method such that to customize our App object by tagging it, as we already did in the previous example, and to invoke CdkApiGatewayStack, responsible to instantiate and initialize our CloudFormation stack. Last but not least, the app.synth() statement is synthesizing this stack and, once executed, our infrastructure, as defined by the CdkApiGatewayStack, should be deployed on the AWS cloud.
Here is now the CdkApiGatewayStack class:
@Singleton
public class CdkApiGatewayStack extends Stack
{
@Inject
LambdaWithBucketConstructConfig config;
@ConfigProperty(name = "cdk.lambda-with-bucket-construct-id", defaultValue = "LambdaWithBucketConstructId")
String lambdaWithBucketConstructId;
@Inject
public CdkApiGatewayStack(final App scope,
final @ConfigProperty(name = "cdk.stack-id", defaultValue = "QuarkusApiGatewayStack") String stackId,
final StackProps props)
{
super(scope, stackId, props);
}
public void initStack()
{
String functionUrl = new LambdaWithBucketConstruct(this, lambdaWithBucketConstructId, config).getFunctionUrl();
CfnOutput.Builder.create(this, "FunctionURLOutput").value(functionUrl).build();
}
}
This class has changed as well, compared to its previous release. It's a singleton that uses the concept of construct, which was introduced formerly. As a matter of fact, instead of defining the stack structure here, in this class, as we did before, we do it by encapsulating the stack's elements together with their configuration in a construct that facilitates easily assembled cloud applications. In our project, this construct is a part of a separate module, named cdk-simple-construct, such that we could reuse it repeatedly and increase the application's modularity.
public class LambdaWithBucketConstruct extends Construct
{
private FunctionUrl functionUrl;
public LambdaWithBucketConstruct(final Construct scope, final String id, LambdaWithBucketConstructConfig config)
{
super(scope, id);
Role role = Role.Builder.create(this, config.functionProps().id() + "-role")
.assumedBy(new ServicePrincipal("lambda.amazonaws.com")).build();
role.addManagedPolicy(ManagedPolicy.fromAwsManagedPolicyName("AmazonS3FullAccess"));
role.addManagedPolicy(ManagedPolicy.fromAwsManagedPolicyName("CloudWatchFullAccess"));
IFunction function = Function.Builder.create(this, config.functionProps().id())
.runtime(Runtime.JAVA_21)
.role(role)
.handler(config.functionProps().handler())
.memorySize(config.functionProps().ram())
.timeout(Duration.seconds(config.functionProps().timeout()))
.functionName(config.functionProps().function())
.code(Code.fromAsset((String) this.getNode().tryGetContext("zip")))
.build();
functionUrl = function.addFunctionUrl(FunctionUrlOptions.builder().authType(FunctionUrlAuthType.NONE).build());
new Bucket(this, config.bucketProps().bucketId(), BucketProps.builder().bucketName(config.bucketProps().bucketName()).build());
}
public String getFunctionUrl()
{
return functionUrl.getUrl();
}
}
This is our construct which encapsulates our stack elements: a Lambda function with its associated IAM role and an S3 bucket. As you can see, it extends the software.construct.Construct class and its constructor, in addition to the standard scopeand id, parameters take a configuration object named LambdaWithBucketConstructConfig which defines, among others, properties related to the Lambda function and the S3 bucket belonging to the stack.
Please notice that the Lambda function needs the IAM-managed policy AmazonS3FullAccess in order to read, write, delete, etc. to/from the associated S3 bucket. And since for tracing purposes, we need to log messages to the CloudWatch service, the IAM-managed policy CloudWatchFullAccess is required as well. These two policies are associated with a role whose naming convention consists of appending the suffix -role to the Lambda function name. Once this role is created, it will be attached to the Lambda function.
As for the Lambda function body, please notice how this is created from an asset dynamically extracted from the deployment context. We'll come back in a few moments with more details concerning this point.
Last but not least, please notice how after the Lambda function is created, a URL is attached to it and cached such that it can be retrieved by the consumer. This way we completely decouple the infrastructure logic (i.e., the Lambda function itself) from the business logic; i.e., the Java code executed by the Lambda function, in our case, a REST API implemented as a Quarkus JAX-RS (RESTeasy) endpoint, acting as a proxy for the API Gateway exposed by AWS.
Coming back to the CdkApiGatewayStack class, we can see how on behalf of the Quarkus CDI implementation, we inject the configuration object LambdaWithBucketConstructConfig declared externally, as well as how we use the Eclipse MicroProfile Configuration to define its ID. Once the LambdaWithBucketConstruct instantiated, the only thing left to do is to display the Lambda function URL such that we can call it with different consumers, whether JUnit integration tests, curl utility, or postman.
We just have seen the whole mechanics which allows us to decouple the two fundamental CDK building blocks App and Stack. We also have seen how to abstract the Stack building block by making it an external module which, once compiled and built as a standalone artifact, can simply be injected wherever needed. Additionally, we have seen the code executed by the Lambda function in our stack can be plugged in as well by providing it as an asset, in the form of a ZIP file, for example, and stored in the CDK deployment context. This code is, too, an external module named quarkus-api and consists of a REST API having a couple of endpoints allowing us to get some information, like the host IP address or the S3 bucket's associated attributes.
It's interesting to notice how Quarkus takes advantage of the Qute templates to render HTML pages. For example, the following endpoint displays the attributes of the S3 bucket that has been created as a part of the stack.
...
@Inject
Template s3Info;
@Inject
S3Client s3;
...
@GET
@Path("info/{bucketName}")
@Produces(MediaType.TEXT_HTML)
public TemplateInstance getBucketInfo(@PathParam("bucketName") String bucketName)
{
Bucket bucket = s3.listBuckets().buckets().stream().filter(b -> b.name().equals(bucketName))
.findFirst().orElseThrow();
TemplateInstance templateInstance = s3Info.data("bucketName", bucketName, "awsRegionName",
s3.getBucketLocation(GetBucketLocationRequest.builder().bucket(bucketName).build())
.locationConstraintAsString(),
"arn", String.format(S3_FMT, bucketName), "creationDate",
LocalDateTime.ofInstant(bucket.creationDate(), ZoneId.systemDefault()), "versioning",
s3.getBucketVersioning(GetBucketVersioningRequest.builder().bucket(bucketName).build()));
return templateInstance.data("tags",
s3.getBucketTagging(GetBucketTaggingRequest.builder().bucket(bucketName).build()).tagSet());
}
This endpoint returns a TemplateInstance whose structure is defined in the file src/main/resources/templates/s3info.htmland which is filled with data retrieved by interrogating the S3 bucket in our stack, on behalf of the S3Client class provided by the AWS SDK.
A couple of integration tests are provided and they take advantage of the Quarkus integration with AWS, thanks to which it is possible to run local cloud services, on behalf of testcontainers and localstack. In order to run them, proceed as follows:
$ git clone https://github.com/nicolasduminil/cdk
$ cd cdk/cdk-quarkus/quarkus-api
$ mvn verify
Running the sequence of commands above will produce a quite verbose output and, at the end, you'll see something like this:
[INFO]
[INFO] Results:
[INFO]
[INFO] Tests run: 3, Failures: 0, Errors: 0, Skipped: 0
[INFO]
[INFO]
[INFO] --- failsafe:3.2.5:verify (default) @ quarkus-api ---
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 22.344 s
[INFO] Finished at: 2024-07-04T17:18:47+02:00
[INFO] ------------------------------------------------------------------------That's not a big deal - just a couple of integration tests executed against a localstack running in testcontainers to make sure that everything works as expected. But if you want to test against real AWS services, meaning that you fulfill the requirements, then you should proceed as follows:
$ git clone https://github.com/nicolasduminil/cdk
$ cd cdk
$ ./deploy.sh cdk-quarkus/cdk-quarkus-api-gateway cdk-quarkus/quarkus-api/
Running the script deploy.sh with the parameters shown above will synthesize and deploy your stack. These two parameters are:
- The CDK application module name: This is the name of the Maven module where your
cdk.jsonfile is. - The REST API module name: This is the name of the Maven module where the
function.zipfile is.
If you look at the deploy.sh file, you'll see the following:
...cdk deploy --all --context zip=~/cdk/$API_MODULE_NAME/target/function.zip...This command deploys the CDK app after having set in the zip context variable the function.zip location. Do you remember that the Lambda function has been created in the stack (LambdaWithBucketConstruct class) like this?
IFunction function = Function.Builder.create(this, config.functionProps().id())
...
.code(Code.fromAsset((String) this.getNode().tryGetContext("zip")))
.build();
The statement below gets the asset stored in the deployment context under the context variable zip and uses it as the code that will be executed by the Lambda function.
The output of the deploy.sh file execution (quite verbose as well) will finish by displaying the Lambda function URL:
...
Outputs:
QuarkusApiGatewayStack.FunctionURLOutput = https://...lambda-url.eu-west-3.on.aws/
Stack ARN:
arn:aws:cloudformation:eu-west-3:...:stack/QuarkusApiGatewayStack/...
...Now, in order to test your stack, you may fire your preferred browser at
https://<generated>.lambda-url.eu-west-3.on.aws/s3/info/my-bucket-8701 and should see something looking like this:
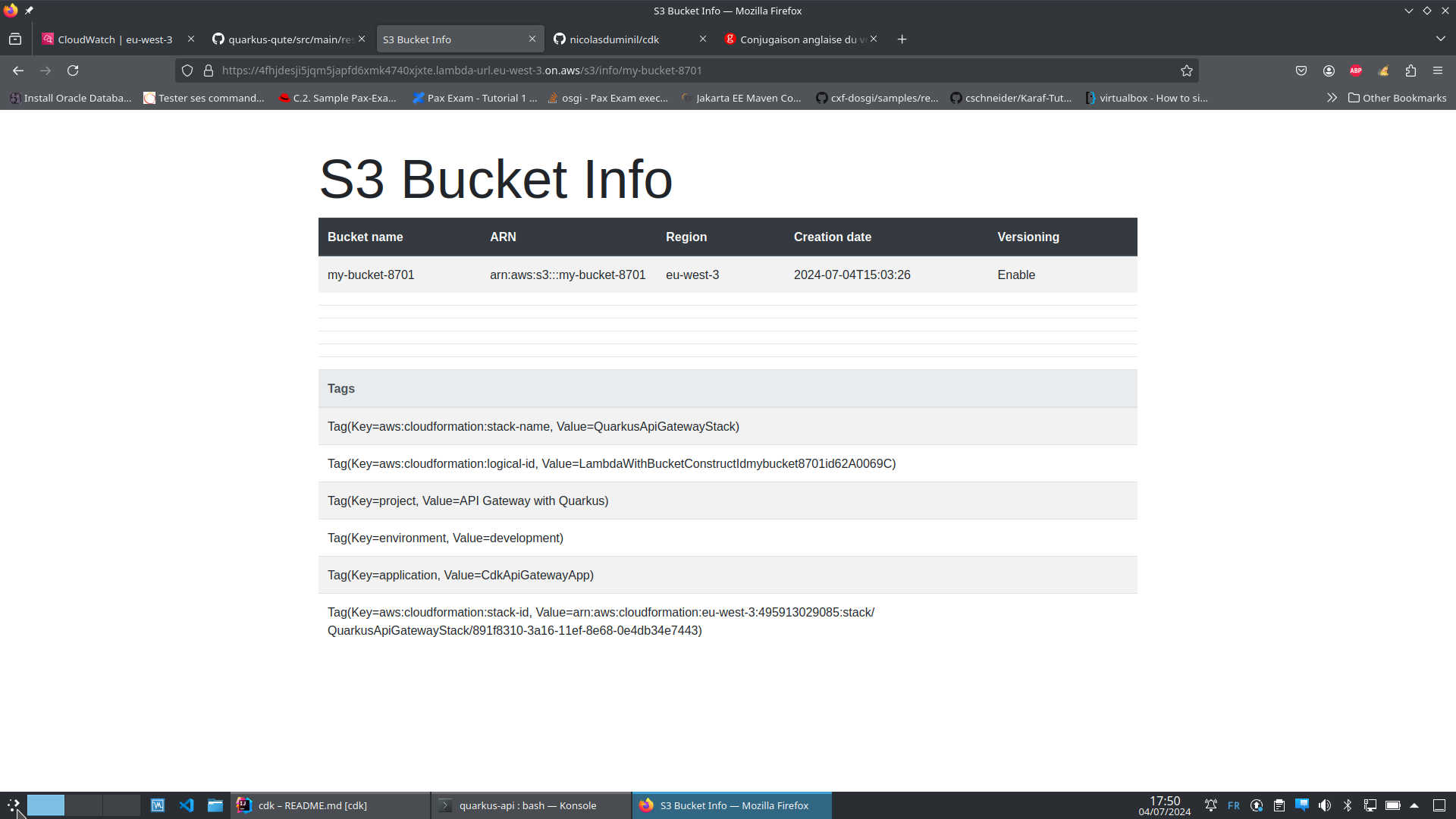
Conclusion
Your test is successful and you now know how to use CDK constructs to create infrastructure standalone modules and assemble them into AWS CloudFormation stacks. But there is more, so stay tuned!
Opinions expressed by DZone contributors are their own.
Comments