Zero Trust: Storage and Search
This article relates to the problem of the safe processing of covered stored data in databases managed by public cloud providers.
Join the DZone community and get the full member experience.
Join For FreeIf we look at the banking market (7.5 trillion euro in 2022) and insurance ($5.6 trillion in 2022) applications, we will find it very regulative. Responsibility to act with personal data securely leads many companies to have a private cloud to store the data, even if it is not a cost-effective solution. Data disclosure should not be possible to hold the business.
Same time storage of data in a way it can not be processed for reading in a natural way may make this storage at public cloud compliant and cost-efficient.
Reading and searching for this covered data without disclosing covered data internals might make this approach even more attractive. It will grant properties of the database with a high possible security level of stored data. Even if privileges to data access are used incorrectly, then internal data representation as a covered blob will become a second level of data protection.
Secure Storage
The question is: how to cover the data? There are three conceptual ways:
- Encryption
- Covering by mask
- Sliced storage
It is possible to store each of the database items encrypted. This way, a person needs to have credentials to decrypt the covered data and read the internals. Access to the database is not enough to get the credentials.

Encrypted data storage
Covering by mask is similar to encryption but has some usage differences. All of the database items are covered by xor with some predefined values. These values are stored separately and disclosed on the client side only when query results data need to be obtained.
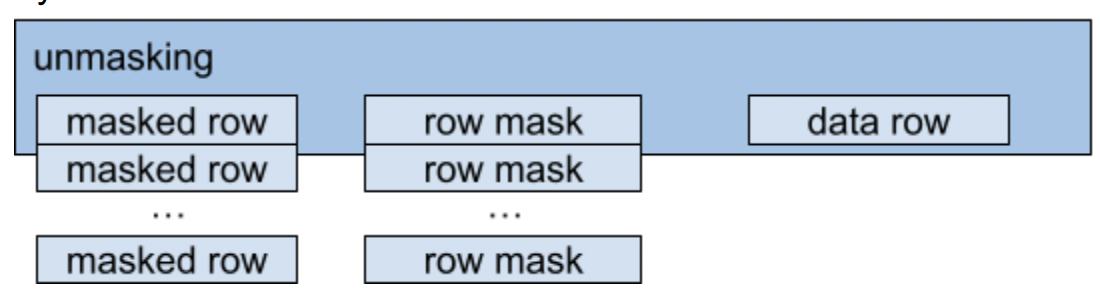
Masked data storage
Sliced storage is the way to store each of the data items by slices at different storages. To get valuable data items, we need to have access to both storages and have knowledge of how to combine the parts at one value.
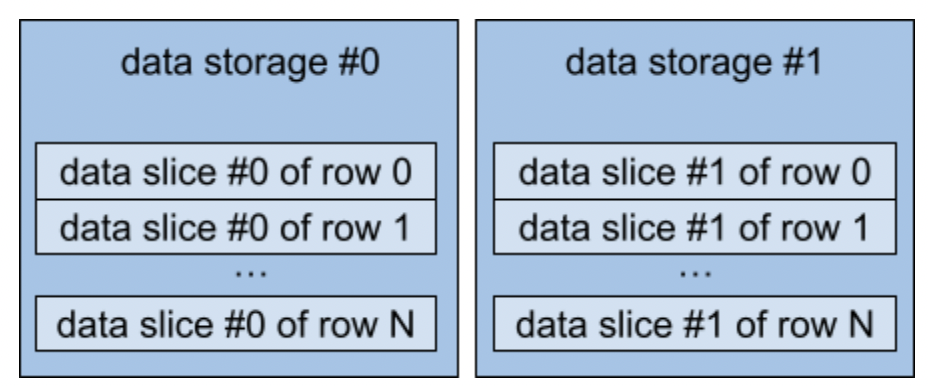
Sliced data storage
Search Techniques
Storing data securely is useful when we can process this data in one of two ways:
- Discover data internals and process them on the cloud side.
- The process covered data in natural form without disclosure of internals on the cloud side.
The first approach is clear in implementation but has a significant disadvantage; data needs to be disclosed. In several cases, it comes very naturally to send keys to the storage side and use it there to make processing faster. But in terms of security, this is a dangerous way. Keys can be used for improper actions.
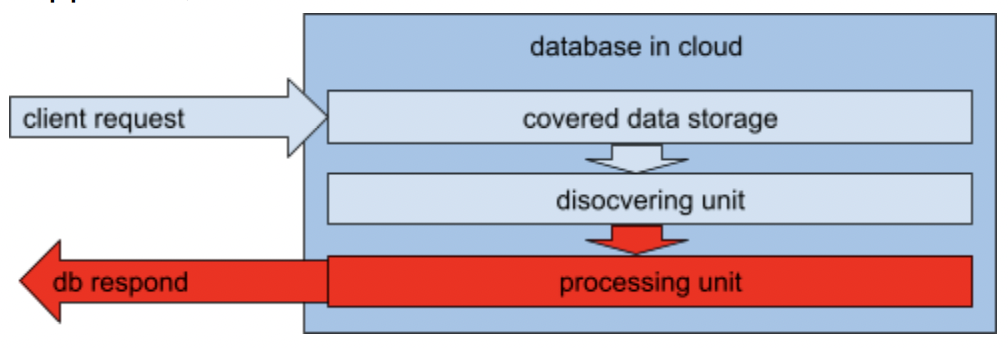
The danger of discovering on processing at cloud.
The second approach makes all of the actions harder to implement. But it will hold the data covered during all of the actions on the public cloud side. To find the exact key, we need to encrypt it the proper way with the proper credentials; then, we need to find this encrypted value in encrypted form. The rest of the column items for this specific key can be delivered at the encrypted side to the client and decrypted there next.
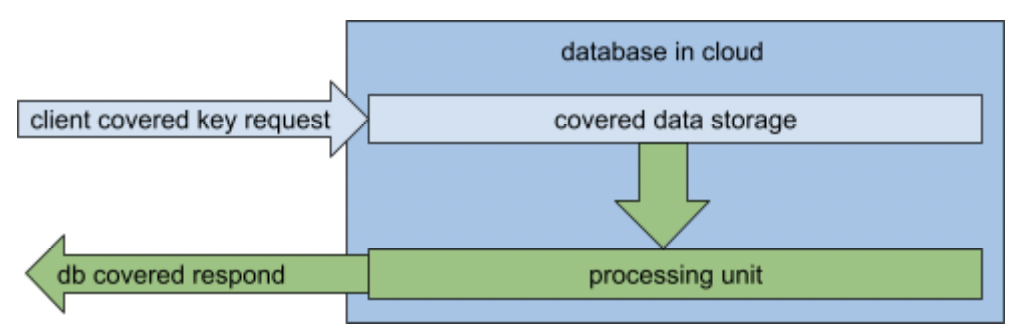
The safe way of covering key data processing.
Time Profile to Add and Search for the Data
Let’s look, will the approach to secure data search be significantly longer? As we can see, the search on covered data does not differ from the search on not covered data except for one point. On searching for non-concrete data (predicate usage on request), we need to make decryption for each of the items that form the predicate at the search algorithm. So worst case efficiency of the search will go down as the ratio of non-covered data storage to covering.
Conclusion
The market has many faces, and some solutions need additional parts to be adopted for sensitive clients. The approach reviewed in this article briefly might make the usage of public clouds easier for companies that need to hold their client data safe and secure.
Opinions expressed by DZone contributors are their own.
Comments