Approaches to Cloud-Native Application Security
Securing a cloud-native application properly is not trivial. API gateways and mutual trust are key to ensuring our communication channels are kept safe.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Microservices and Containerization Trend Report.
For more:
Read the Report
Securing cloud-native applications requires proper understanding of the interfaces (boundaries) being exposed by your microservices to various consumers. Proper tools and mechanisms need to be applied on each boundary to achieve the right level of security. Properly securing the infrastructure on which your application runs is also very important. This includes securing container images, securely running container runtimes, and properly configuring and using the container orchestration system (Kubernetes).
Microservices Security Landscape
In a pre-microservices era, most applications followed the MVC architecture. Today, we call these monolithic applications. Compared to such applications, a cloud-native application is highly distributed, as shown in Figure 1.
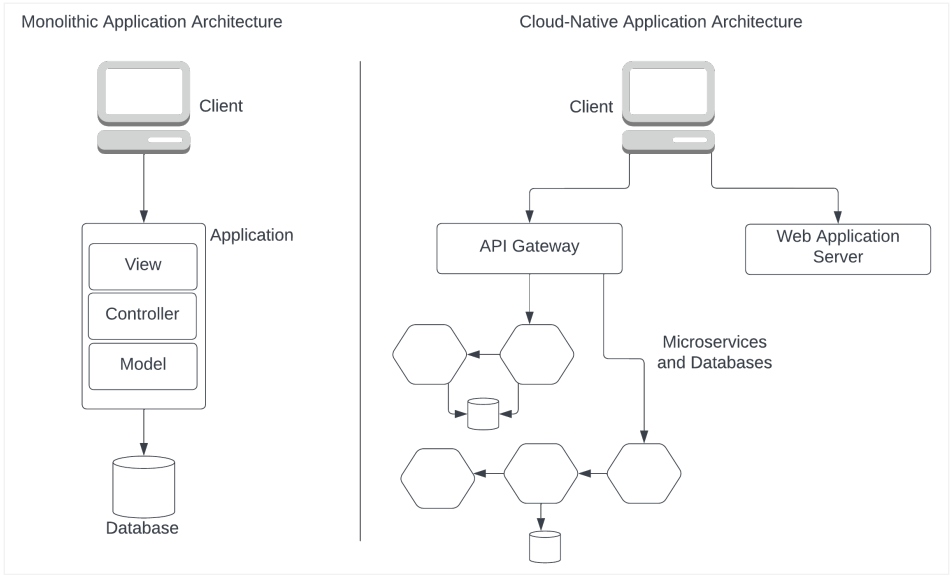
Figure 1: Monolithic vs. cloud-native application
A monolithic application typically has one entry point. Beyond that, everything happens within a single process, except for database calls or similar interactions. Comparatively, the surface of exposure in a cloud-native application is much higher. As shown in Figure 1, a cloud-native application typically has multiple components (services) that communicate over the network. Each entry point into any given component needs to be appropriately secured.
Securing Application Boundaries
Let's elaborate further on application boundaries and understand the actual boundaries that we need to worry about.
Identifying Communication Boundaries in a Cloud-Native Application
A typical cloud-native application's backend architecture would consist of several business domains. Each business domain encapsulates a set of microservices. Take a retail system, for example; order processing and inventory management can be two business domains that have their own collection of microservices.
Microservices within a business domain would be able to communicate with each other securely with no boundaries. This is illustrated in Figure 2 as "Intra-domain east-west traffic." Secure communication within this domain can be implemented using mutual TLS. Mutual TLS can be implemented using a service mesh. A more lightweight approach could be to pass around an authorization token issued by one of the gateways. We will discuss this approach later in the article.
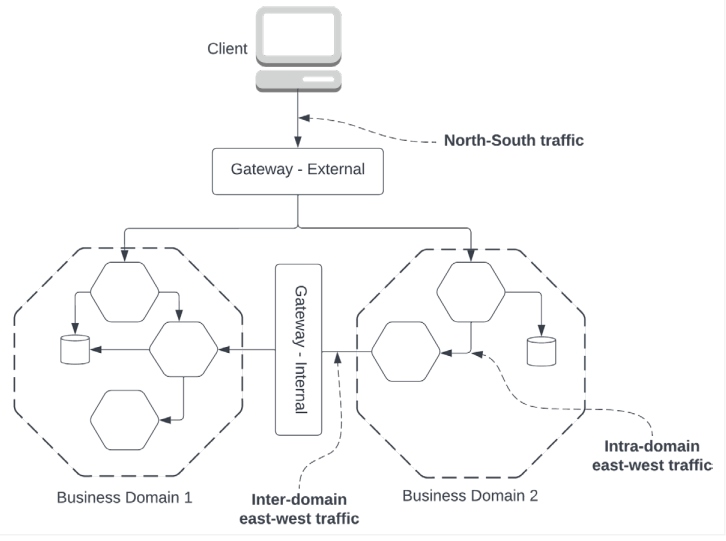
Figure 2: Cloud-native application architecture
Microservices across business domains should not be able to communicate with each other freely unless they are exposed as APIs and explicitly allowed to communicate.
This is illustrated as "Inter-domain east-west traffic" in Figure 2. This concept of business domain boundaries is further explained in the paper "Cell-Based Architecture."
There is a clear boundary that separates all microservices from the client applications (web/ mobile apps). This is illustrated as "North-South traffic" in Figure 2.
APIs and the Use of API Gateways To Secure a Cloud-Native Application
Next, let's identify what we define as APIs and microservices. Any microservice (or collection) that needs to be exposed out of a given boundary needs to be defined as an API. An API typically has a specification such as OpenAPI, GraphQL, AsyncAPI, and so on. An API gateway is used to expose APIs across boundaries. An API gateway's main tasks are as follows:
- Accept messages from calling clients.
- Ensure the client has possession of the right level of authentication/authorization.
- Forward the message to the correct target (microservice).
As shown in Figure 2, an API gateway protects the cloud-native application at the north-south channel as well as the interdomain east-west channel.
The Role of OAuth2.0 in Securing Cloud-Native Applications
A client calling an API needs to obtain an OAuth2.0 access token from a token service before it can talk to the API. The API gateway validates the token and ensures it is issued by a trusted authority before it allows access to the target. This is shown in Figure 3. Although gaining access to APIs is common, types of tokens and how you get them differ based on the use case these tokens are used for.
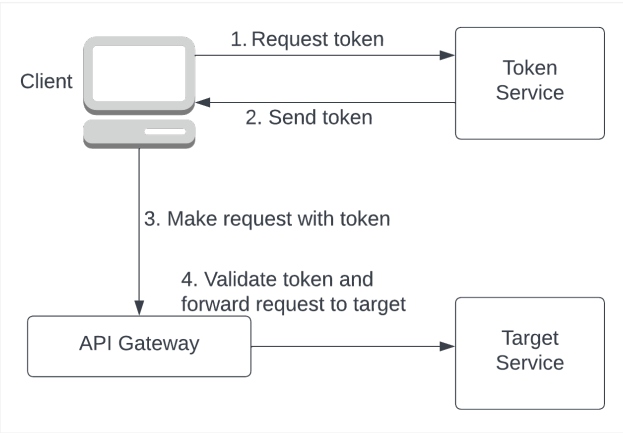
Figure 3: Workflow for obtaining and using an OAuth2.0 access token
The OAuth2.0 specification has a concept called Grant Types that define the steps for getting access tokens. Advanced API Security, by Prabath Siriwardena, is a good book for understanding OAuth2.0 concepts and its use cases.
Authorization for Cloud-Native Applications
Possession of a valid access token is the primary requirement for a client to access an API. One of the key benefits of access tokens is that it not only allows you to call an API, but it can also specify the type of action you can perform with it.
Authorization Using OAuth2.0 Scopes
Imagine a product catalog API that has two operations: One for retrieving the product list (GET /product-list) and the other for modifying the product list (PUT /product-list). In a retail store application, all users should be able to retrieve the product list while only selected users should be able to modify the product list.
The standard way to model this on an API is to say the product list update operation requires a special "scope." Unless the token being used to access this API bears this scope, the request will not be permitted. The OpenAPI specification allows binding scopes to an operation.
Once the client knows that it requires a special scope to access an operation, it requests the token service to issue a token bearing the required scope. When verifying that the requesting user/client is authorized to obtain the requested scope(s), the token service binds the relevant scopes to the token. This workflow is shown in Figure 4.
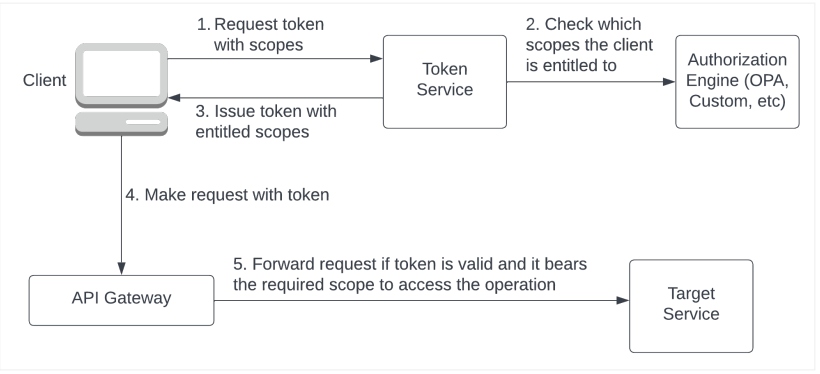
Figure 4: Access an API with scopes
We can see that authentication and authorization are terminated at the API gateway. But there can be cases where the actual microservices need to know details of the user/client accessing the service for performing business logic. This requirement is done by the API gateway issuing a secondary JWT formatted token (not an access token) and forwarding it to the target service. This secondary token can be passed around the microservices within that domain and used for building mutual trust within that domain.
Authorization With OPA
Beyond permissions, we may need to implement other authorization rules in cloud-native applications. Consider restricting access to a certain application functionality available between 8 a.m. to 6 p.m. on weekdays. While these can be implemented in the source code of the microservice, that is not a good practice.
These are organizational policies that can change. The best practice is to externalize such policies from code.
Open Policy Agent (OPA) is a lightweight general-purpose policy engine that has no dependency on the microservice. Authorization rules can be implemented in Rego and mounted to OPA.
Figure 5 illustrates the patterns in which OPA can be used for authorization rules.
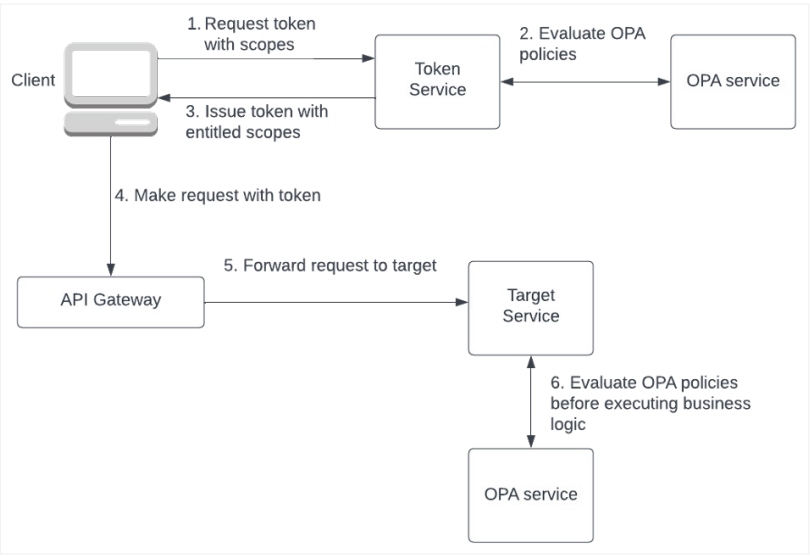
Figure 5: Using OPA for authorization
Securing Containers With Docker
Docker is the most popular tool for packaging and distributing microservices. A Docker container encapsulates a microservice and its dependencies and is stored in a container registry (private or public).
Figure 6: Docker build and push
Externalizing Application Secrets
A microservice usually has dependencies on databases, third-party APIs, other microservices, and so on. To connect to these types of systems, a microservice may depend on sensitive information (secrets) such as certificates and passwords. In a monolithic application, these types of information are stored in a server configuration file.
Only privileged users get access to server configuration files. But in the microservices world, it is common for developers to store this information in property files along with the code of the microservice. When a developer builds such a container and pushes it to the container registry, this information becomes available for anyone who can access the container image!
To prevent this from happening, we need to externalize application secrets from code. Let's take a look at a sample Dockerfile in a Java program that does this:
FROM openjdk:17-jdk-alpine
ADD builds/sample-java-program.jar \
sample-java-program.jar
ENV CONFIG_FILE=/opt/configs/service.properties
ENTRYPOINT ["java", "-jar", "sample-java-program.jar"]The third line in this Dockerfile instructs Docker to create an environment variable named CONFIG_FILE and point it to the /opt/configs/service.properties location. Instead of having secrets hard coded in source code or the code read from a fixed file location, the microservice's code should be written so that it looks up the value of this environment variable to determine the configuration file location and load its contents to memory. With this, we have successfully avoided secrets within the code. If we build a Docker container with this file, it will not contain any sensitive information. Next, let's look at how we can externalize the values we need.
Before running a Docker image built from the above Dockerfile, we need to mount it to a location that has the actual configuration file with the proper values. This can be done with the following Docker run command:
:\> docker run -p 8090:8090 --mount type=bind, \ source="/hostmachine/configs/service.properties" \
target="/opt/configs/service.properties"The source section contains a path of the filesystem on the container's host machine. The target section contains a path on the container filesystem. The --mount command instructs the Docker runtime to mount the source onto the target, meaning that the service.properties file can now be securely maintained on the host machine's filesystem and mounted to container runtimes before starting the containers. This way, we externalize sensitive information from the microservice itself on Docker.
Docker Content Trust
Modern software is made up of a lot of dependencies. A software supply chain is a collection of software dependencies all the way from application code through CI/CD and up to production. Software supply chain attacks have been quite frequent due to a malicious piece of software making its way into an application runtime through its dependency chain.
Cloud-native applications running on Docker depend on Docker images pulled down from one or more repositories. An unsuspecting developer could rely on a malicious Docker image that later compromises their application. To prevent this, Docker introduced a mechanism called Docker Content Trust (DCT), which allows image publishers to sign images using a cryptographic key and the users of Docker images to verify the images before use. Using DCT in your development and CI/CD flows will ensure that you only rely on trusted and verified Docker images in your cloud-native application.
Developers need to set an environment variable named DOCKER_CONTENT_TRUST and set its value to 1 to enforce DCT in all the environments on which Docker is used. For example: :\> export DOCKER_CONTENT_TRUST=1. Once this environment variable is set, it affects the following Docker commands: push, build, create, pull, and run. This means that if you try to issue a docker run command on an unverified image, your command will fail.
Docker Privileges
Any operating system has a super user known as root. All Docker containers by default run as the root user. This is not necessarily bad, thanks to the namespace partitions on the Linux Kernel. However, if you are using file mounts in your containers, an attacker gaining access to the container runtime can be very harmful. Another problem running containers with root access is that it grants an attacker access to the container runtime to install additional tools into the container. These tools can harm the application in various ways such as scanning for open ports and so on.
Docker provides a way to run containers as non-privileged users. The root user ID in Linux is 0. Docker allows us to run Docker containers by passing in a user ID and group ID. The following command would start the Docker container under user ID 900 and group ID 300. Since this is a non-root user, the actions it can perform on the container are limited.
Docker run --name sample-program --user 900:300 nuwan/sample-program:v1Conclusion
Securing a cloud-native application properly is not trivial. API gateways and mutual trust are key to ensuring our communication channels are kept safe and we have a zero-trust architecture. OAuth2.0, scopes, and OPA (or similar) are fundamental to ensuring APIs are properly authenticated and authorized.
Going beyond this scope, we also need to be concerned about using proper security best practices on Kubernetes, properly handling secrets (passwords), securing event-driven APIs, and more. APIs, microservices, and containers are fundamental to cloud-native applications. Every developer needs to keep themselves up to date with the latest security advancements and best practices.
This is an article from DZone's 2022 Microservices and Containerization Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments