Applying Machine Learning for Predictive Capacity Planning in PostgreSQL Databases
Using LSTM machine learning models for PostgreSQL databases can effectively predict resource usage, helping to prevent bottlenecks and improve efficiency.
Join the DZone community and get the full member experience.
Join For FreeToday, the database world is rapidly moving towards AI and ML, and the workload of databases is expected to increase significantly. For a database administrator, it will be an additional responsibility to predict the workload of database infrastructure ahead of time and address the need. As databases scale and resource management become increasingly critical, traditional capacity planning methods often fall short, leading to performance issues and unplanned downtime. PostgreSQL, one of the most widely used open-source relational databases, is no exception. With increasing demands on CPU, memory, and disk space, database administrators (DBAs) must adopt proactive approaches to prevent bottlenecks and improve efficiency.
In this article, we'll explore how Long Short-Term Memory (LSTM) machine learning models can be applied to predict resource consumption in PostgreSQL databases. This approach enables DBAs to move from reactive to predictive capacity planning, thus reducing downtime, improving resource allocation, and minimizing over-provisioning costs.
Why Predictive Capacity Planning Matters
By leveraging machine learning, DBAs can predict future resource needs and address them before they become critical, resulting in:
- Reduced downtime: Early detection of resource shortages helps avoid disruptions.
- Improved efficiency: Resources are allocated based on real needs, preventing over-provisioning.
- Cost savings: In cloud environments, accurate resource predictions can reduce the cost of excess provisioning.
How Machine Learning Can Optimize PostgreSQL Resource Planning
To accurately predict PostgreSQL resource usage, we applied an optimized LSTM model, a type of recurrent neural network (RNN) that excels at capturing temporal patterns in time-series data. LSTMs are well-suited for understanding complex dependencies and sequences, making them ideal for predicting CPU, memory, and disk usage in PostgreSQL environments.
Methodology
Data Collection
Option 1
To build the LSTM model, we need to collect performance data from various PostgreSQL system server OS commands and db view, such as:
pg_stat_activity(active connections details within Postgres Database),vmstatfreedf
The data can be captured every few minutes for six months, providing a comprehensive dataset for training the model. The collected metrics can be stored in a dedicated table named capacity_metrics.
Sample Table Schema:
CREATE TABLE capacity_metrics (
time TIMESTAMPTZ PRIMARY KEY,
cpu_usage DECIMAL,
memory_usage DECIMAL,
disk_usage BIGINT,
active_connections INTEGER
);There are multiple ways to capture this system data into this history table. One of the ways is to write the Python script and schedule it through crontab for every few minutes.
Option 2
For testing flexibility, we can generate CPU, memory, and disk utilization metrics using code (synthetic data generation) and execute using the Google Colab Notebook. For this paper testing analysis, we used this option. The steps are explained in the following sections.
Machine Learning Model: Optimized LSTM
The LSTM model was selected for its ability to learn long-term dependencies in time-series data. Several optimizations were applied to improve its performance:
- Stacked LSTM layers: Two LSTM layers were stacked to capture complex patterns in the resource usage data.
- Dropout regularization: Dropout layers were added after each LSTM layer to prevent overfitting and improve generalization.
- Bidirectional LSTM: The model was made bidirectional to capture both forward and backward patterns in the data.
- Learning rate optimization: A learning rate of 0.001 was chosen for fine-tuning the model’s learning process.
The model was trained for 20 epochs with a batch size of 64, and performance was measured on unseen test data for CPU, memory, and storage (disk) usage.
Below is a summary of the steps along with Google Colab Notebook screenshots used in the data setup and machine learning experiment:
Step 1: Data Setup (Simulated CPU, Memory, Disk Usage Data for 6 Months)
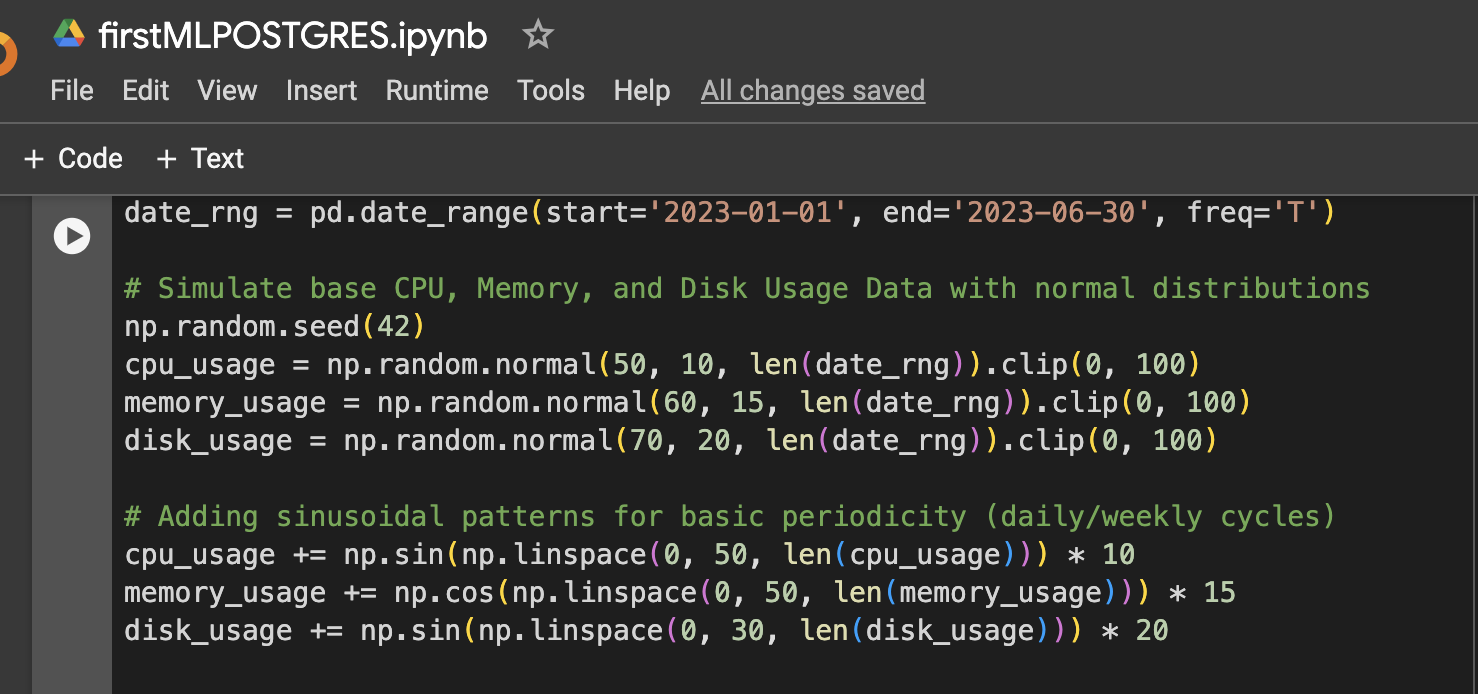
Step 2: Add More Variation to the Data
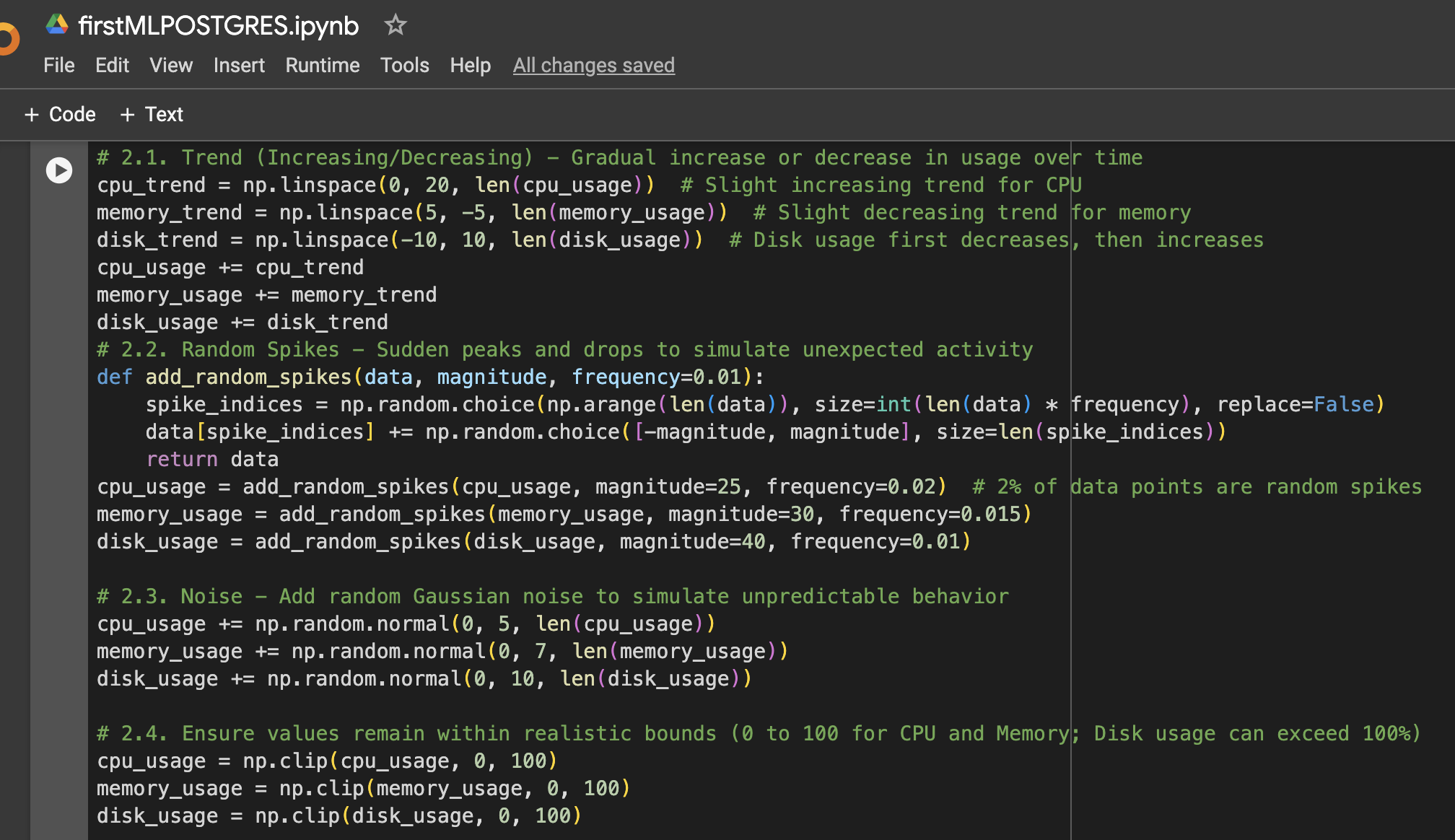
Step 3: Create DataFrame for Visualization or Further Usage
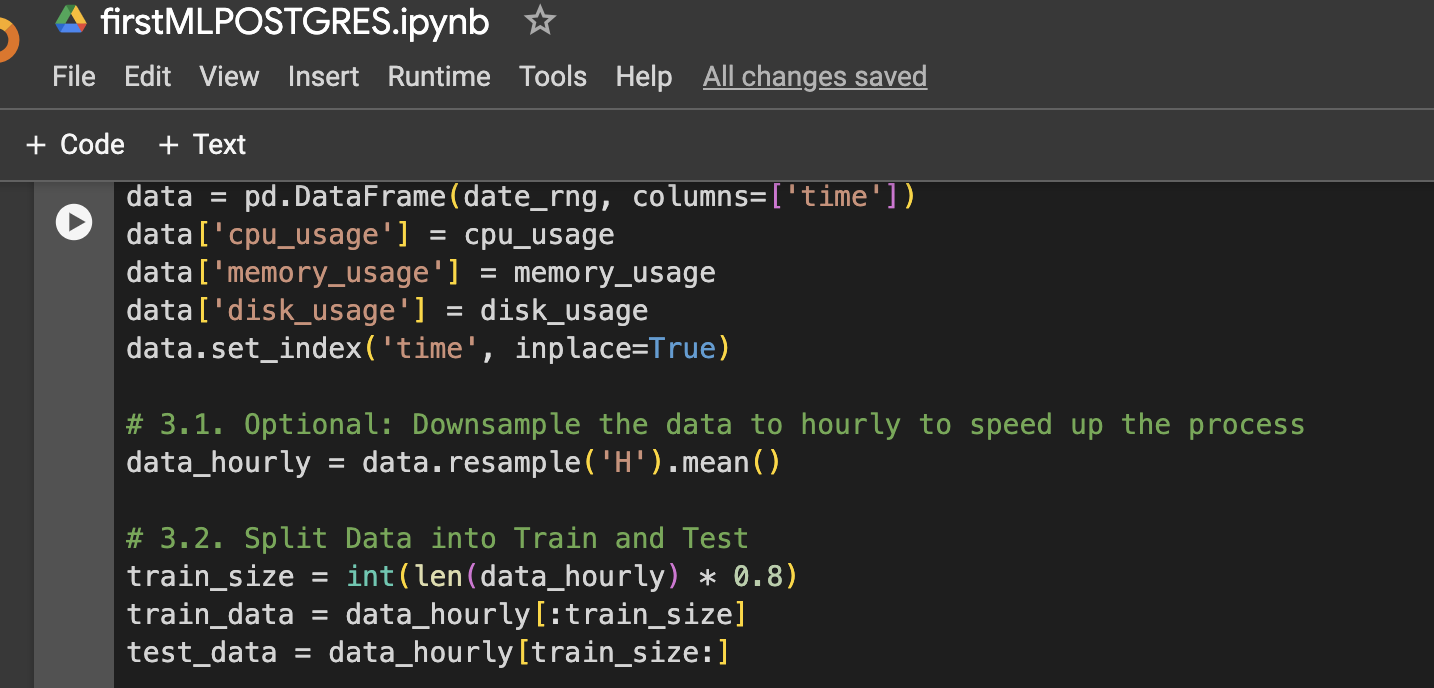
Step 4: Function to Prepare LSTM Data, Train, Predict, and Plot
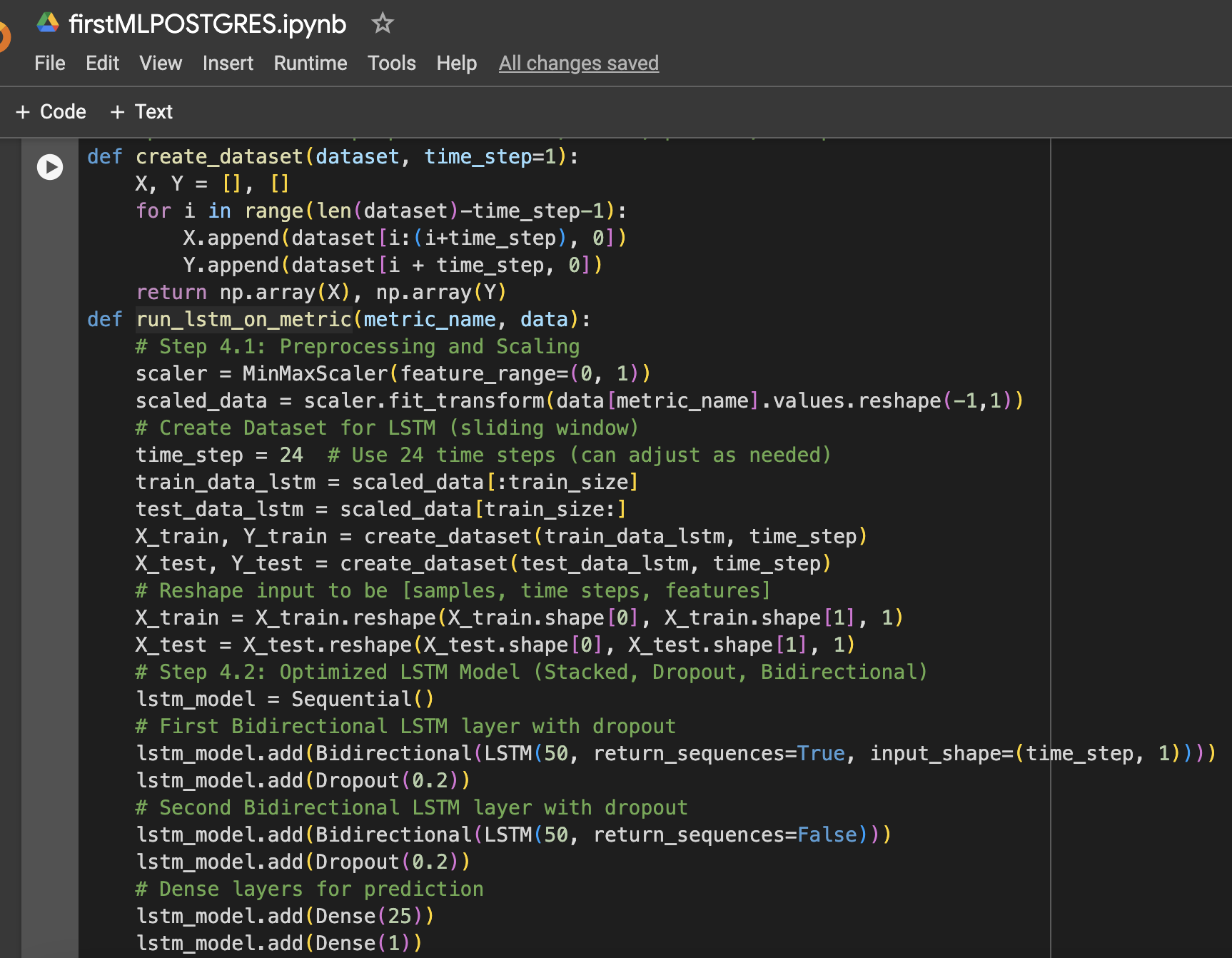
Step 5: Run the Model for CPU, Memory, and Storage
Results
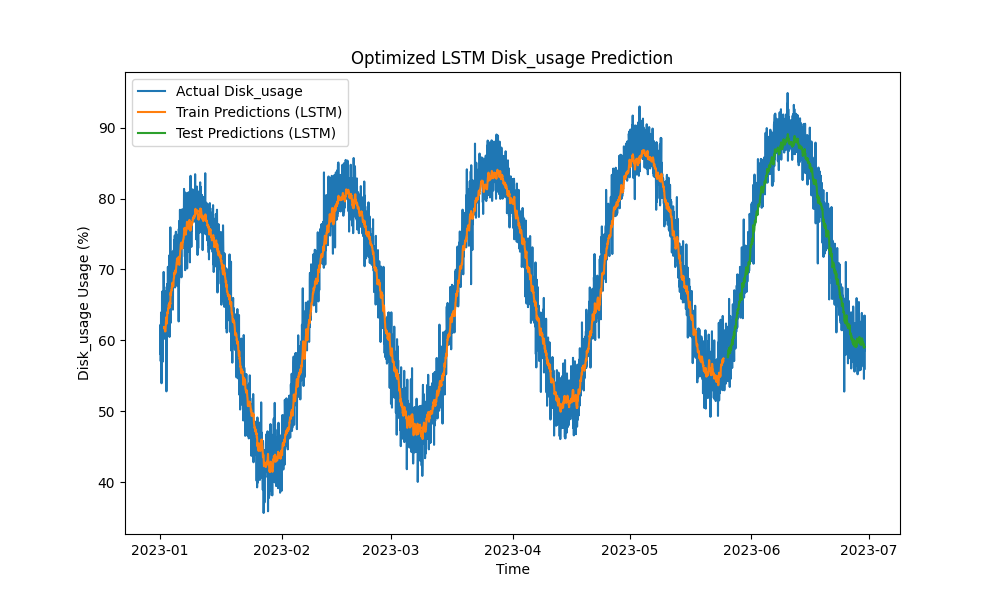
The optimized LSTM model outperformed traditional methods such as ARIMA and linear regression in predicting CPU, memory, and disk usage. The predictions closely tracked the actual resource usage, capturing both the short-term and long-term patterns effectively.
Here are the visualizations of the LSTM predictions:
Figure 1: Optimized LSTM CPU Usage Prediction
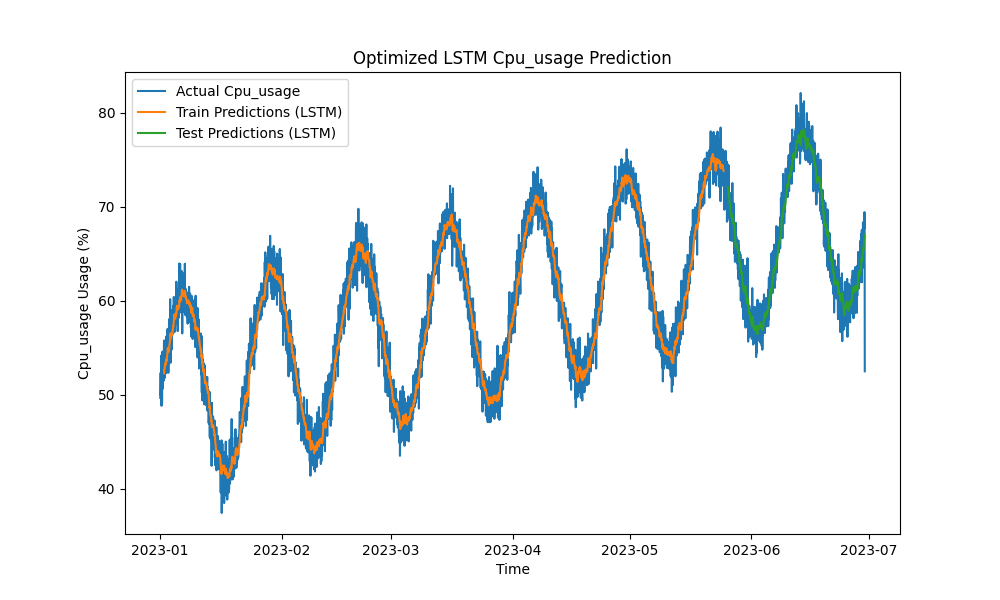
Figure 2: Optimized LSTM Memory Usage Prediction
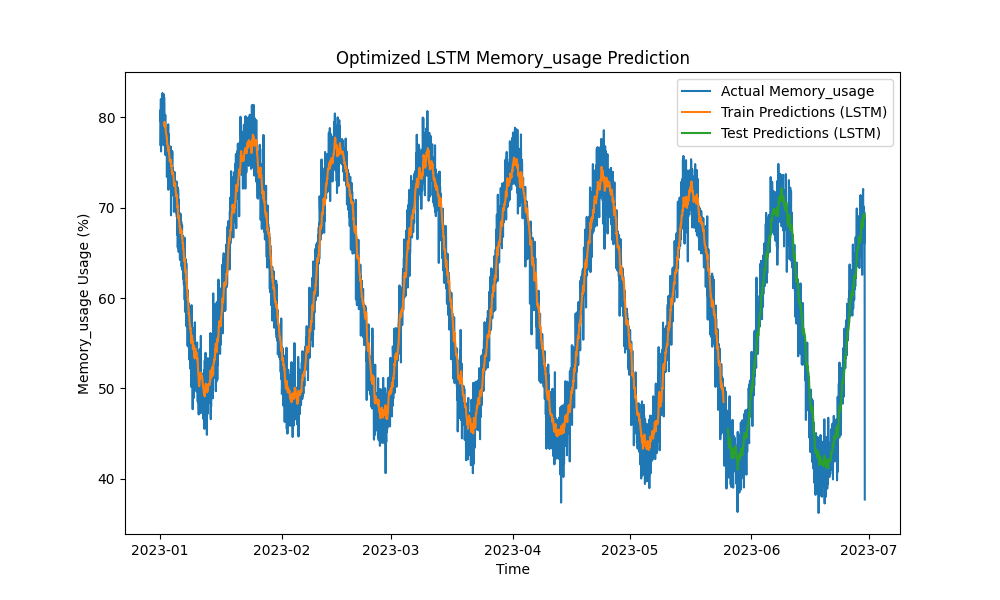
Figure 3: Optimized LSTM Disk Usage Prediction
Practical Integration With PostgreSQL Monitoring Tools
To maximize the utility of the LSTM model, various practical implementations within PostgreSQL's monitoring ecosystem can be explored:
- pgAdmin integration: pgAdmin can be extended to visualize real-time resource predictions alongside actual metrics, enabling DBAs to respond proactively to potential resource shortages.
- Grafana dashboards: PostgreSQL metrics can be integrated with Grafana to overlay LSTM predictions on performance graphs. Alerts can be configured to notify DBAs when predicted usage is expected to exceed predefined thresholds.
- Prometheus monitoring: Prometheus can scrape PostgreSQL metrics and use the LSTM predictions to alert, generate forecasts, and set up notifications based on predicted resource consumption.
- Automated scaling in cloud environments: In cloud-hosted PostgreSQL instances (e.g., AWS RDS, Google Cloud SQL), the LSTM model can trigger autoscaling services based on forecasted increases in resource demand.
- CI/CD pipelines: Machine learning models can be continuously updated with new data, retrained, and deployed in real-time through CI/CD pipelines, ensuring that predictions remain accurate as workloads evolve.
Conclusion
By applying LSTM machine learning models to predict CPU, memory, and disk usage, PostgreSQL capacity planning can shift from a reactive to a proactive approach. Our results show that the optimized LSTM model provides accurate predictions, enabling more efficient resource management and cost savings, particularly in cloud-hosted environments.
As database ecosystems grow more complex, these predictive tools become essential for DBAs looking to optimize resource utilization, prevent downtime, and ensure scalability. If you're managing PostgreSQL databases at scale, now is the time to leverage machine learning for predictive capacity planning and optimize your resource management before performance issues arise.
Future Work
Future improvements could include:
- Experimenting with additional neural network architectures (e.g., GRU or Transformer models) to handle more volatile workloads.
- Extending the methodology to multi-node and distributed PostgreSQL deployments, where network traffic and storage optimization also play significant roles.
- Implementing real-time alerts and further integrating predictions into PostgreSQL’s operational stack for more automated management.
- Experimenting with Oracle Automated Workload Repository (AWR) data for Oracle database workload predictions
Opinions expressed by DZone contributors are their own.
Comments