Apache NiFi 1.x Cheatsheet
This quick and easy guide will show you how to make Apache NiFi work for you, including processors, connections, and APIs.
Join the DZone community and get the full member experience.
Join For FreeApache NiFi is quickly becoming the go-to Open Source Big Data tool for all kinds of use cases. For me, it's my personal swiss army knife with 170 tools that I can easily connect together in a pipeline with scheduling, queueing, scale out clustering, monitoring, UI and extreme ease of use.
Apache NiFi was open sourced by NSA.
This Java tool provides a very user-friendly Web UI in which to develop your data flows which can encompass everything from ingesting files, consuming asynchronous messages, reading email, calling scripts, converting file formats and storing in Hadoop, databases, NoSQL stores, and more. It really is the modern data Swiss Army knife.
Documentation: https://nifi.apache.org/docs.html
Getting Started: https://nifi.apache.org/docs/nifi-docs/html/getting-started.html
Developers Guide: https://nifi.apache.org/developer-guide.html
Expression Language: https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html
The expression language is used in most processor configuration for allowing you to do basic transformations on attributes or portions of the incoming file. The expression language allows for flow control, boolean logic, string manipulation, encoding/decoding, string searching, math, type coercion and functions to return things like ID and IP address (ip() and UUID()).
User Guide: https://nifi.apache.org/docs/nifi-docs/html/user-guide.html
Admin Guide: https://nifi.apache.org/docs/nifi-docs/html/administration-guide.html
Logs: /nifi-x/logs/nifi-app.log and nifi-user.log.
Useful Processors:
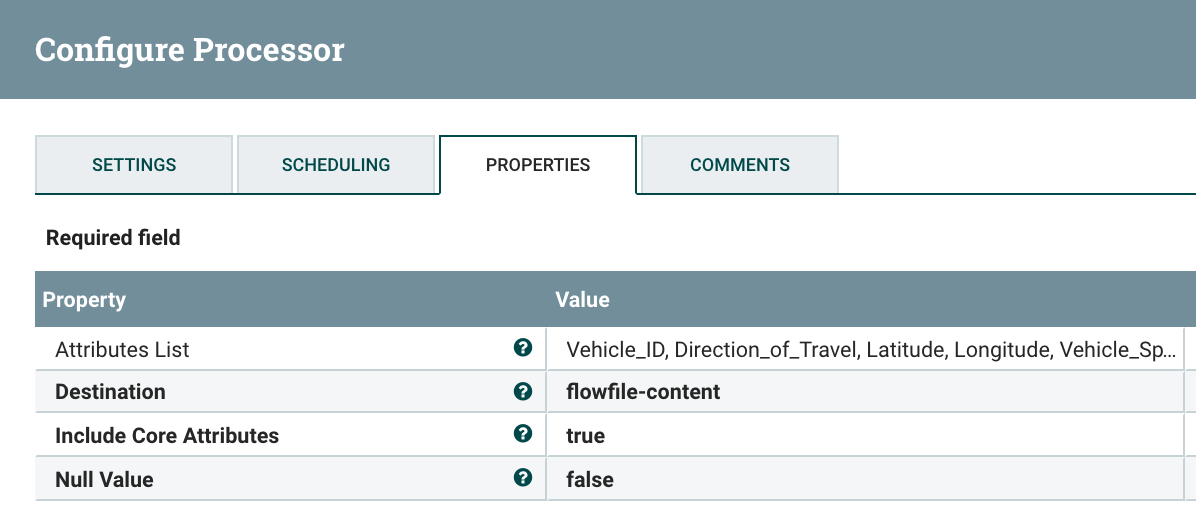
AttributesToJSON build a JSON FlowFile Content from Attributes. This processor I use all the time to build a new FlowFile. Once I have extracted all the attributes I wanted, manipulated them, converted, rounded, trimmed and augmented, then I convert them into a JSON file. Once I have a JSON file I can save that to a datastore like HDFS or convert it into another format with all the converters like JSON to AVRO. This is really handy.
![Image title]()
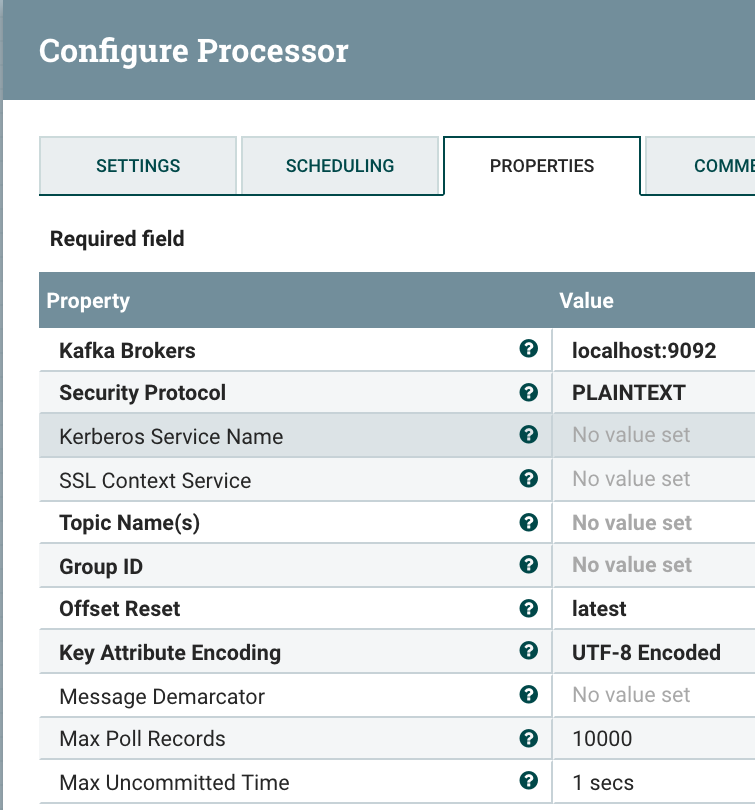
ConsumeKafka ingest Kafka messages, from Kafka 0.9.x Consumer API. You can also use ConsumeKafka_0_10 to read from a newer version of Kafka. Please check your Kafka server as there is a difference. For version 0.8.x, you need to use the GetKafka processor. If you have Kafka, this will all make sense. Very straight forward usage.
![Image title]()
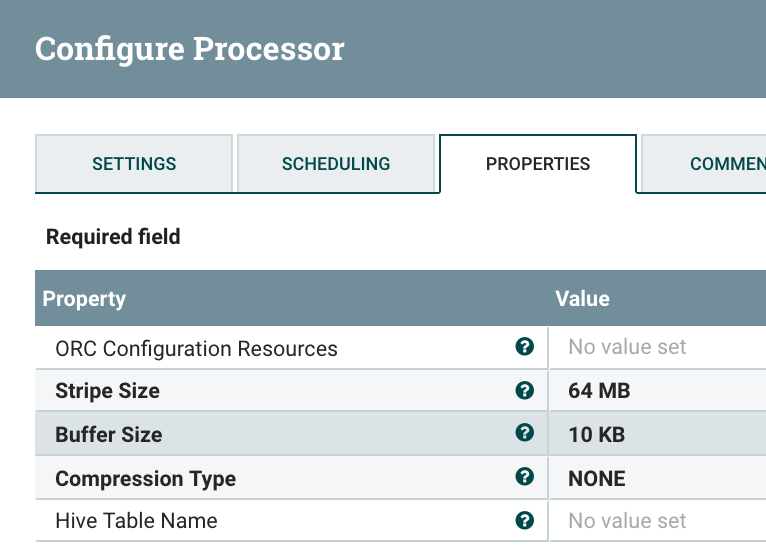
ConvertAvroToORC convert FlowFile content into an Apache ORC file.
![Image title]()
ConvertJSONtoAvro uses an AVRO Schema to convert your JSON document into an Apache AVRO file with schema.
![Image title]()
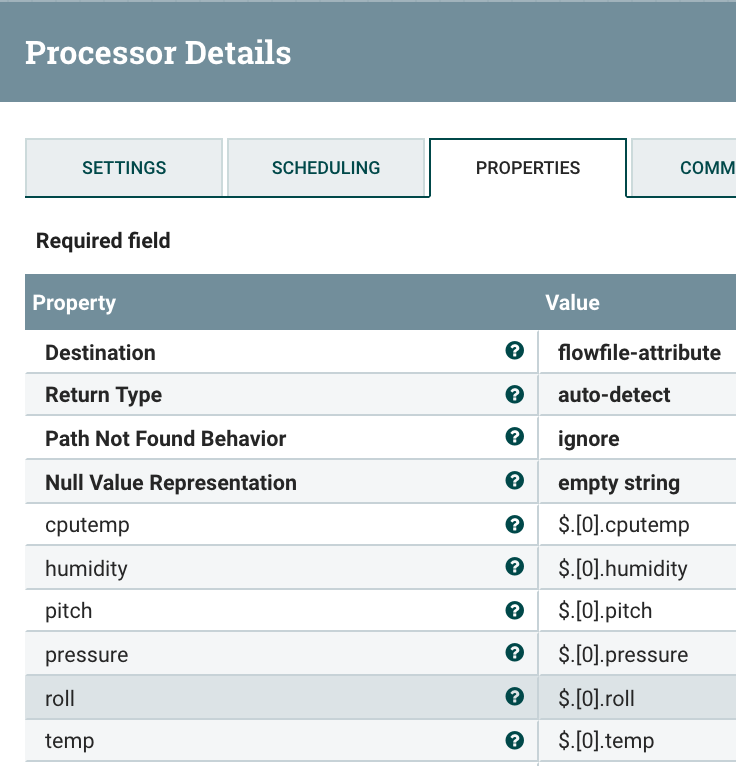
- EvaluateJSONPath extracts values from FlowFile content JSON, often used to pull JSON fields out into attributes. Use Case: Twitter Feed Ingest.
![Image title]()
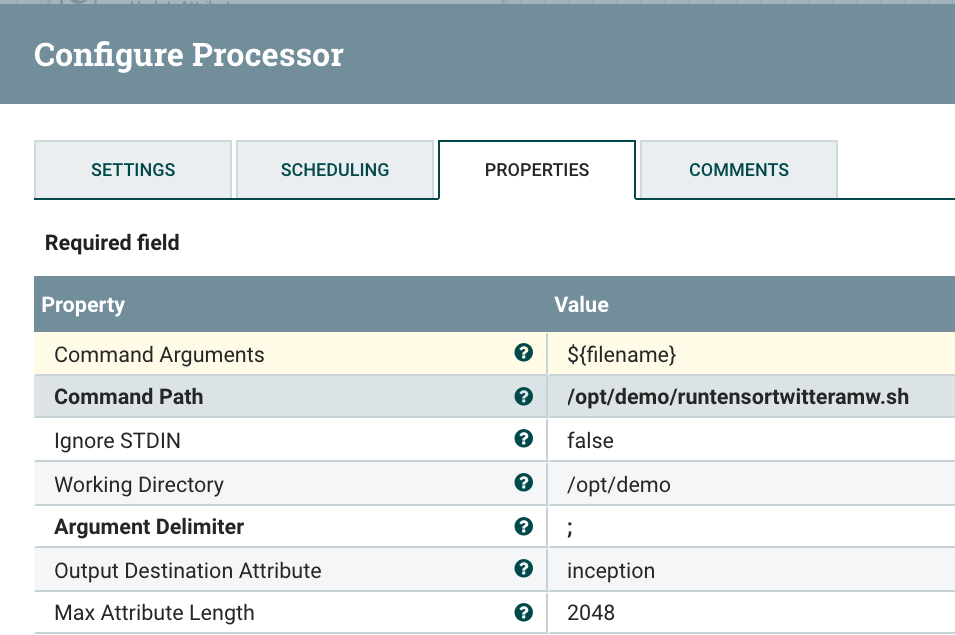
- ExecuteStreamCommand runs a command and brings in the results into the flow. This is useful for adding extra attributes to an existing flow. I use this to add Sentiment Analysis to a Twitter tweet.
![Image title]()
- ExtractMediaMetadata extracts metadata like size and embedded information like GPS coordinates from various media files like images. Use Case: Geo extraction from drone images. Uses Apache Tika.

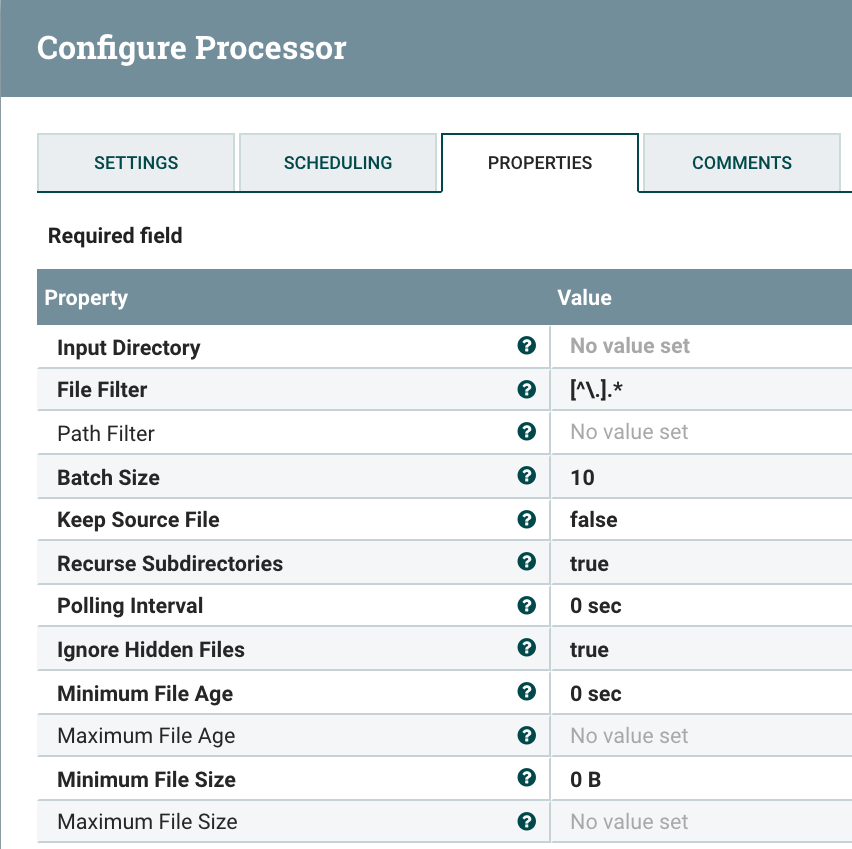
- GetFile reads all the files in a directory and adds them as files. Great for processing large quantities of files, will keep reading as they are added. It's expensive to watch for files, so use this only if you must and turn them off it, you are not using it.
![Image title]()
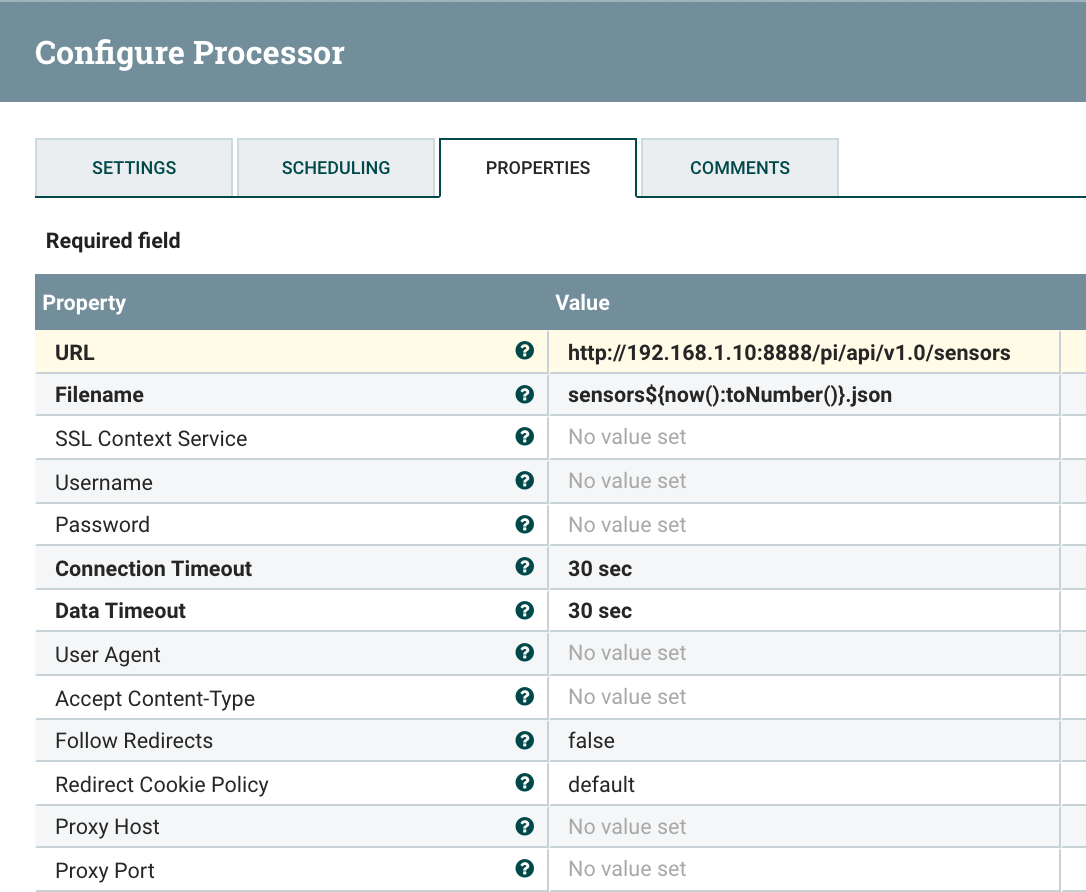
- GetHTTP extract content from HTTP and HTTP websites. You need an SSL Context for calling HTTPS sites and this requires cacert from your JDK.
![Image title]()
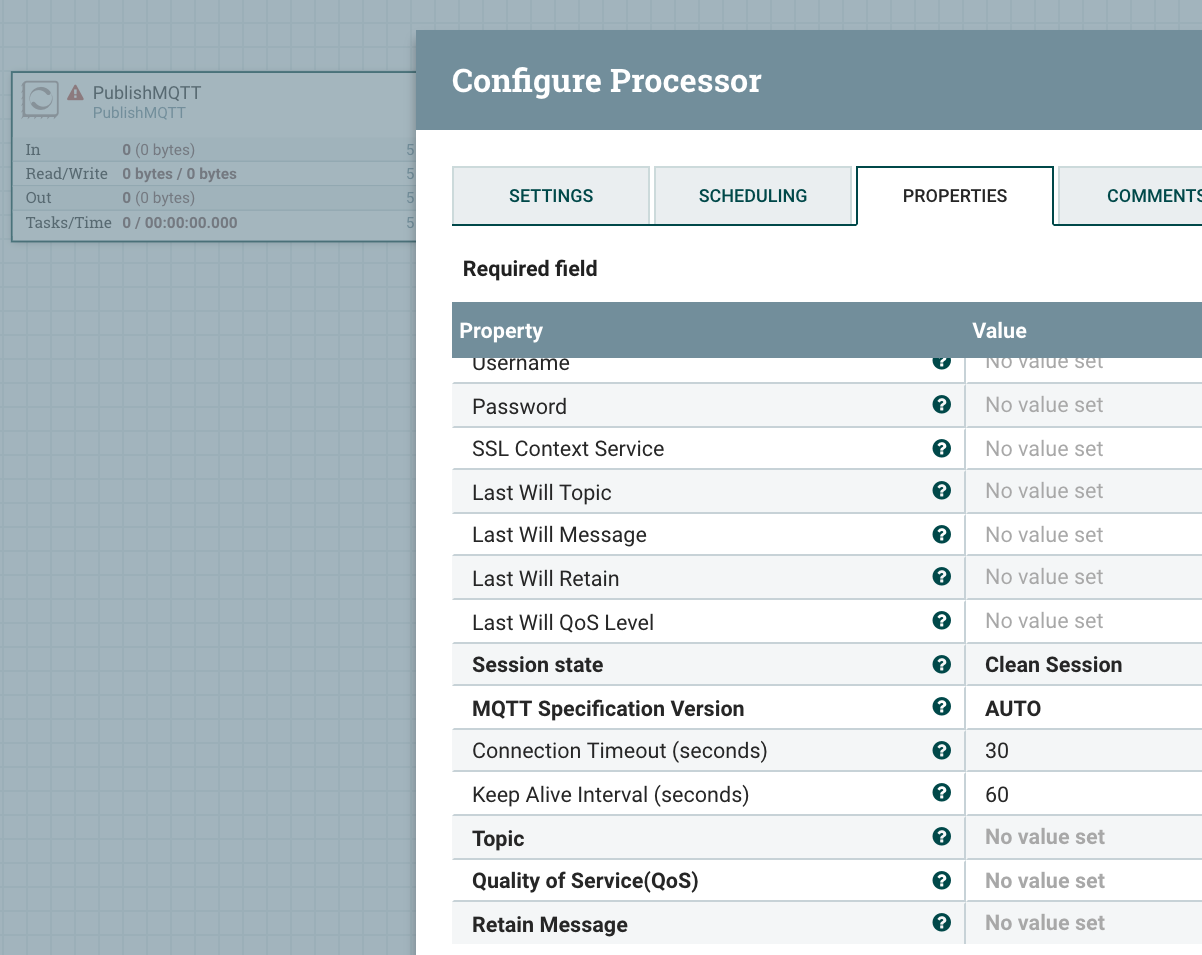
- PublishMQTT pushes a message to an MQTT queue. Use Case: IoT.
![Image title]()
- ConsumeMQTT reads a message from an MQTT queue. Use Case: IoT ingest.
![Image title]()



You will also need a few Controller Services, for Java developers think Connection Pools and a service to manage them:
DBCPConnectionPool for relational database sources, anything with a JDBC driver and Apache Phoenix. You will need a bunch of these if you know the full JDBC URL and # of connections you want, you are set.
HBase_1_1_2_ClientService for HBase connections, uses HBase and Zookeeper connection information.


HiveConnectionPool for Hive connections to Hadoop Hive data.
JMSConnectionFactoryProvider for connecting to JMS brokers.


Common NiFi REST API:
Apache NiFi provides a Rest API that allows for programmatic access to command a NiFi instance. You can start/stop processors, queues and display statistics and configuration. What's very interesting and kind of meta is that you can then call the Rest API from Apache NiFi. Along the same logs I was using Apache NiFi to read Apache NiFi logs.
GET /nifi-api/system-diagnostics
{"systemDiagnostics":{"aggregateSnapshot":
{"totalNonHeap":"338.38 MB",
"totalNonHeapBytes":354816000,
"usedNonHeap":"326.16 MB",
"usedNonHeapBytes":342000064,
"freeNonHeap":"12.22 MB",
"freeNonHeapBytes":12815936,
"maxNonHeap":"-1 bytes",
"maxNonHeapBytes":-1,
"totalHeap":"6 GB",
"totalHeapBytes":6442450944,
"usedHeap":"3.17 GB",
"usedHeapBytes":3407422960,
"freeHeap":"2.83 GB",
"freeHeapBytes":3035027984,
"maxHeap":"6 GB",
"maxHeapBytes":6442450944,
"heapUtilization":"53.0%",
"availableProcessors":8,
"processorLoadAverage":0.36,
"totalThreads":99,
"daemonThreads":53,
"flowFileRepositoryStorageUsage":
{"freeSpace":"44.39 GB",
"totalSpace":"79.99 GB",
"usedSpace":"35.59 GB",
"freeSpaceBytes":47666999296,
"totalSpaceBytes":85885063168,
"usedSpaceBytes":38218063872,
"utilization":"44.0%"},
"contentRepositoryStorageUsage":[
{"identifier":"default","freeSpace":"44.39 GB",
"totalSpace":"79.99 GB","usedSpace":"35.59 GB",
"freeSpaceBytes":47666999296,
"totalSpaceBytes":85885063168,
"usedSpaceBytes":38218063872,
"utilization":"44.0%"}],
"garbageCollection":[
{"name":"G1 Young Generation",
"collectionCount":2172338,
"collectionTime":"132:38:54.540",
"collectionMillis":477534540},
{"name":"G1 Old Generation","collectionCount":0,
"collectionTime":"00:00:00.000",
"collectionMillis":0}],
"statsLastRefreshed":"03:05:01 UTC"}
}
}This API call provides a ton of information on Java memory usage and free space. You can parse this JSON with NiFi and watch for thresholds and shut things down or send alerts.
GET /nifi-api/flow/status
{"controllerStatus":
{"activeThreadCount":0,
"queued":"241,658 / 2.99 GB",
"flowFilesQueued":241658,
"bytesQueued":3209622825,
"runningCount":119,
"stoppedCount":429,
"invalidCount":70,
"disabledCount":0,
"activeRemotePortCount":0,
"inactiveRemotePortCount":0
}
}This API call provides some other useful diagnostics on the NiFi server.
GET /nifi-api/flow/about
{"about":
{"title":"NiFi",
"version":"1.0.0.2.0.0.0-579",
"uri":"http://timisawesome.com:8090/nifi-api/",
"contentViewerUrl":"/nifi-content-viewer/",
"timezone":"UTC"
}
}This is useful to get your exact version #, URI, and timezone.
GET /nifi-api/flow/bulletin-board
{"bulletinBoard":
{"bulletins":[],"generated":"19:22:05 UTC"}}This lists any bulletins from the NiFi server and notifications.
GET /nifi-api/flow/cluster/summary
{"clusterSummary":
{"connectedNodeCount":0,"totalNodeCount":0,
"clustered":false,"connectedToCluster":false}}This call gives you a list of the nodes in the summary and if it is part of a cluster. Mine is not as you can see.
GET /nifi-api/flow/templates
{"templates":[{"id":"7d3bba1d-f3f2-4679-a5be-71e3d6b3e313",
"permissions":{"canRead":true,"canWrite":true},
"template":{"uri":
"http://tspann:8090/nifi-api/templates/7d3bba1d-f3f2-4679-a5be-71e3d6b3e313",
"id":"7d3bba1d-f3f2-4679-a5be-71e3d6b3e313",
"groupId":"433b0d2c-0157-1000-ab25-4179322143ec",
"name":"Sentiment","description":"save 3\nnov 7 2016\n",
"timestamp":"11/07/2016 21:55:55 UTC","encoding-version":"1.0"}},
...This call will return a lot of information if you have a lot of templates. There are a lot of details per template. I have hundreds of templates so this JSON will be giant.
References
Opinions expressed by DZone contributors are their own.
Comments