Apache Airflow Configuration and Tuning
Apache Airflow is essential for data pipeline automation. Dive deep into its advanced configurations for optimization. Proper setup ensures robustness in workflows.
Join the DZone community and get the full member experience.
Join For FreeApache Airflow is a widely-used open-source tool for automating data pipelines. Airflow is well-received by data engineers for its flexible workflow control, dependency handling, scalability, and strong community support. To leverage Airflow’s capability, users need to understand the advanced configurations so that we can establish a smoother data pipeline workflow.
In this article, we'll explore tips and advanced configurations we can use to enhance the experience and effectiveness when using Apache Airflow.
Exploring the airflow.cfg File
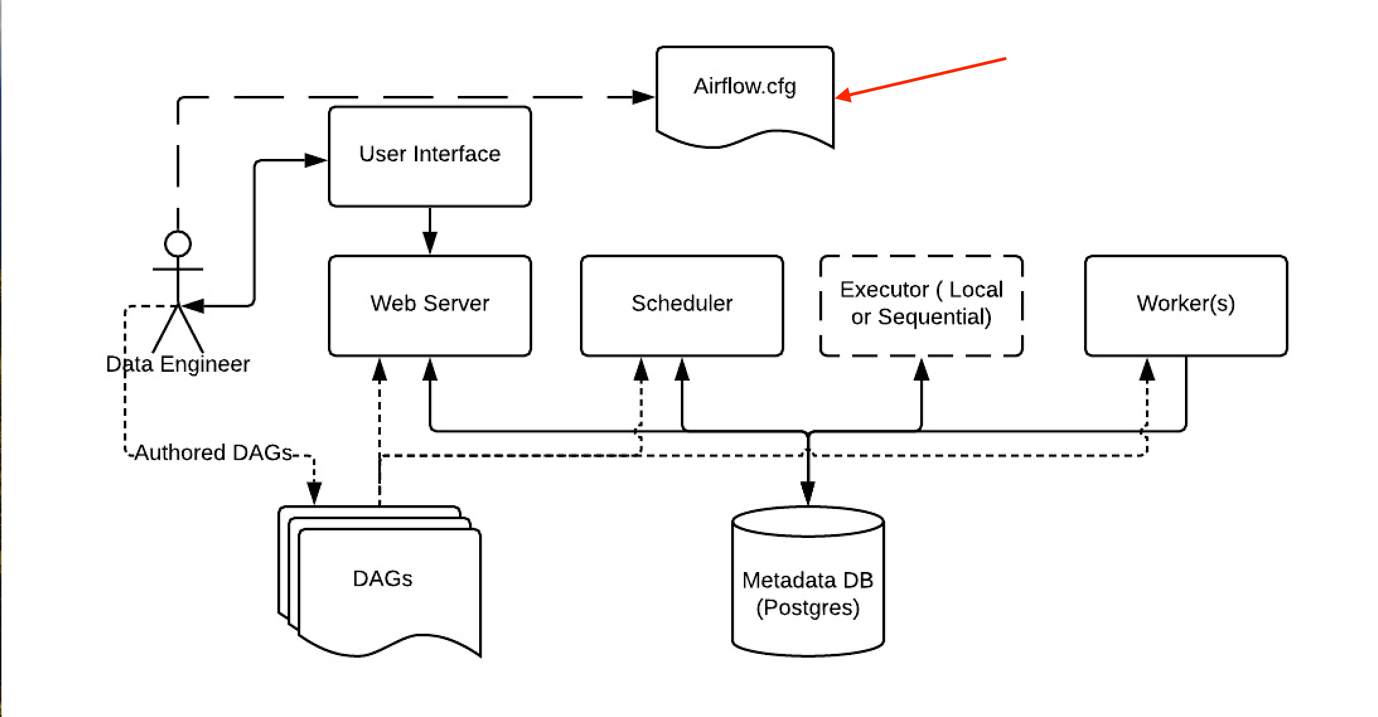
airflow.cfg file is a critical configuration file in Apache Airflow. It contains all the settings and parameters that govern the behavior and performance of Apache Airflow deployment. In this section, we will explore the airflow.cfg file, including its key sections and parameters, and explaining how we can customize these configurations.
Parameters of the airflow.cfg File
The airflow.cfg file is structured into various sections, each responsible for a specific aspect of Airflow's behavior. Below are some of the important sections and their associated parameters:
“[core]” Section
- executor: This parameter specifies the executor used for task execution (e.g., LocalExecutor, CeleryExecutor).
- dags_folder: This defines the directory where DAG files are stored.
- load_examples: This parameter determines whether to load example DAGs during initialization.
- sql_alchemy_conn: This parameter configures the database connection URL.
- parallelism: This sets the maximum number of task instances that can run concurrently.
“[scheduler]” Section
- job_heartbeat_sec: Controls the frequency at which the scheduler heartbeats to the database.
- scheduler_heartbeat_sec: Configures the heartbeat frequency between the scheduler and workers.
“[webserver]” Section
- web_server_port: Specifies the port for the Airflow web UI.
- web_server_host: Defines the host on which the web UI is served.
- web_server_worker_timeout: Sets the timeout for web server workers.
“[celery]” Section (If Using CeleryExecutor)
Parameters related to the Celery message broker and worker configuration.
“[email]” Section
- Configurations for sending email notifications.
“[ldap]” Section (if using LDAP for authentication):
- LDAP server connection settings.
Customizing Configurations

Configuration changes significantly based on the task, which is why customizing the airflow.cfg file is essential to tailor Airflow to your specific needs. Here's how you can do it:
- Edit the configuration file: To get started, you need to first locate the airflow.cfg file in your Airflow installation directory (typically /etc/airflow/ or $AIRFLOW_HOME). You will need to use a text editor to open the file. Depending on your system's permissions, you might also need administrative privileges.
- Modify parameters: Within the file, find the section and parameter you want to customize. Edit the parameter's value according to your requirements. For instance, if you want to make changes to the executor to CeleryExecutor, modify the executor parameter under the [core] section.
- Save the changes: After making your desired changes, save the airflow.cfg file.
- Restart airflow services and verify the changes made: To apply the new configurations, you will have to restart the Airflow webserver, scheduler, and worker processes. You can check if your changes took effect by visiting the Airflow web UI, inspecting logs, or running Airflow commands.
When making customizations, it's important to document any custom configurations and their purpose, as well as to maintain version control over your airflow.cfg file to track changes. This is even crucial if you’re working as a team, which is normally the case for many data engineers and developers.
Database Optimization

Here are some of the steps users need to take when optimizing the database for Apache Airflow.
Choosing the Right Database Backend
First of all, we need to choose the right database for your backend. This is because the choice of a backend database for Apache Airflow's metadata impacts its performance and reliability. Here are some considerations when making a choice;
- Database Options: Airflow supports various database backend databases, including PostgreSQL, MySQL, SQLite, and more. The choice depends on your organization's preferences and expertise. In production, PostgreSQL is a popular choice due to its robustness and scalability. SQLite is the database Apache Airflow supports by default, but this should only be used for development purposes.
- Scaling: Consider the scalability requirements of your Airflow instance. PostgreSQL and MySQL are known for their ability to handle large datasets and concurrent connections. As stated earlier, SQLite is only suitable for development and small deployments but is not recommended for production use due to its limitations.
- High Availability: For mission-critical applications, implementing high availability (HA) is crucial. This often involves setting up a database cluster or using a cloud-managed database service with built-in HA features.
Configuring Database Connection Pooling
Database connection pooling is essential for optimizing Airflow's performance, especially when dealing with a large number of task instances. Here are the steps we can follow to configure database connection pooling;
- Connection pool: Configure the maximum number of connections in the database connection pool using parameters like pool_size and max_overflow in the [core] section of the airflow.cfg file. Setting appropriate values prevents overloading the database server while ensuring there are enough connections for concurrent tasks.
- Use of connection pool: Ensure that your DAGs utilize the database connections efficiently. Avoid opening and closing database connections for every task. Instead, use context managers or decorators like @db_utils to manage connections.
- Monitoring: Keep an eye on database performance metrics to detect potential issues with connection pooling. Tools like database query logs, database performance monitoring software, or Airflow's built-in metrics can be helpful.
Database Maintenance Best Practices
To maintain the health and performance of the Airflow database, here are some of the best practices that we need to follow;
- Regular backups: Implement regular database backups to prevent data loss in case of failures.
- Database cleanup: Regularly clean up old records from the metadata database to prevent it from becoming too large. You can use Airflow's Retries and Trigger Rules settings to manage how long task execution history is retained.
- Database indexing: Properly index the database tables used by Airflow to speed up queries and ensure efficient data retrieval.
- Database upgrades: Stay updated with Airflow releases and perform necessary database schema upgrades when migrating to newer versions.
- Monitoring and alerting: Implement monitoring solutions to detect database performance issues and set up alerts for critical database-related events.
- Database maintenance window: Plan regular maintenance windows for database maintenance tasks like vacuuming, reindexing, and software updates.
Parallelism and Concurrency
Parallelism in Apache Airflow refers to the ability to execute multiple tasks or processes concurrently. It's essential for optimizing workflow execution. Airflow manages parallelism through worker processes, which are responsible for executing tasks in parallel. Parallelism ensures that tasks within a DAG can run concurrently when their dependencies are satisfied, improving overall workflow performance.
Configuring the Number of Worker Processes
You can configure the number of worker processes in the “[core]” section of the airflow.cfg file using the parallelism parameter. Increasing the number of worker processes allows more tasks to run in parallel, which can improve throughput but also requires more system resources. When configuring the worker processes, you need to first consider your hardware resources and the complexity of your workflows.
Fine-Tuning the Number of Task Instances
Task instances are individual executions of tasks within a workflow. To fine-tune the number of task instances, we can set the “max_active_runs” parameter in the “[core]” section of the airflow.cfg file. Adjusting this parameter can control how many times a specific task can run concurrently, allowing us to balance concurrency based on the hardware resources of systems.
Managing Task Execution Concurrency
Managing task execution concurrency involves ensuring that dependencies are respected while optimizing workflow execution. Airflow uses task-level concurrency controls, such as task priority, task dependencies, and pool management, to manage task execution. For instance, we can set task-specific parameters like “priority_weight” to influence the order in which tasks are executed and manage concurrency effectively.
Executor Selection
Apache Airflow offers different executors for task execution, each with its advantages. Let’s explore the best use cases for each of these executors.
- LocalExecutor: Suitable for small to medium-sized deployments where tasks run in separate processes on the same machine.
- CeleryExecutor: Recommended for larger deployments, as it distributes task execution across a Celery cluster.
- KubernetesExecutor: Designed for running Airflow tasks on Kubernetes clusters, providing scalability and isolation.
Choosing the Right Executor for Your Workload
When selecting the appropriate executor, we need to consider factors like the size of deployment, scalability needs, and the infrastructure you're using. It is crucial to consider factors like the number of tasks, resource availability, and fault tolerance requirements when making your choice.
Configuring Executors for Optimal Performance
After selecting the right executor for your workload, you also need to fine-tune its configuration in the airflow.cfg file. Parameters related to the executor, such as “celery_config_options” for CeleryExecutor or “kube_config” for KubernetesExecutor, can be adjusted to optimize performance. Monitoring and profiling can help identify bottlenecks and optimize executor settings for your specific use case.
Scaling Airflow
One of the major benefits of Apache Airflow is its ability to scale, depending on the needs of your business. Scaling Apache Airflow can be achieved through horizontal or vertical scaling. Let’s explore the differences between the two.
- Horizontal scaling: This involves adding more worker nodes to distribute task execution across multiple machines (bare metal servers or virtual machines).
- Vertical scaling: Increasing the resources (CPU, RAM) of individual worker nodes to handle more concurrent tasks.
When choosing between these two scaling methods, you must consider your infrastructure and workload.
Load Balancing Considerations
When scaling horizontally, load balancing is crucial to distribute tasks evenly among worker nodes. Load balancers like HAProxy or software-defined load balancers can be used to distribute tasks to ensure all servers are well utilized without overloading a few. Session affinity can be employed to maintain task dependencies.
Monitoring and Scaling Based on Metrics
We should also consider implementing monitoring tools to track Airflow's performance, resource utilization, and task execution metrics. Use collected metrics to make informed decisions about scaling, such as adding more workers when the system is consistently under heavy load.
Task Optimization

Task Optimization involves profiling and monitoring tasks to identify those that consume significant resources or take longer to execute. Resource-intensive tasks may need optimization, including code improvements, parallelization, or resource allocation adjustments. Here are steps you can take to optimize tasks
- Using task-specific configurations: We need to customize task configurations based on specific requirements. Parameters like retries, retry_delay, and priority_weight can be set individually for tasks to manage retries, handle failures, and prioritize execution.
- Task-level concurrency control: Adjust task concurrency settings to control how many instances of a particular task can run concurrently. This can prevent resource contention and optimize task execution.
Logging and Monitoring
We need to configure Airflow to generate detailed logs for tasks and workflow execution.
Customize log formatting, destinations, and levels to suit your debugging and monitoring needs. it is also crucial to implement external monitoring solutions like Prometheus and Grafana to collect and visualize Airflow metrics.
We should also consider using custom dashboards to gain insights into the health and performance of your Airflow deployment. Finally, developers need to set up alerting mechanisms to notify administrators of critical issues or workflow failures. Tools like Slack, email, or dedicated alerting platforms can be integrated to provide timely notifications to your relevant team members.
Security Considerations

With the rise of cyberattacks in the last couple of years, security should be one of your top priorities when using Apache Airflow. Some of the security measures you can take include the following;
- Role-Based Access Control (RBAC): Implement RBAC to control user access to Airflow components and tasks. This will involve defining roles and permissions to restrict access based on user roles.
- Secure sensitive information: Protect sensitive information like passwords and API keys using secure storage solutions or encryption. Avoid storing secrets in plaintext in configuration files or environment variables.
- Encryption and network security: Enable encryption for data in transit (SSL/TLS) and data at rest (database encryption) to enhance security — secure network configurations to prevent unauthorized access to Airflow components.
Final Thoughts
This article has delved deep into Apache Airflow, exploring some advanced techniques and configuration insights you can use to enhance your experience with this tool. In summary, these techniques include understanding configuration files, optimizing databases, managing parallelism and concurrency, and making informed choices about executors and scaling.
With this knowledge, you're well-equipped to maximize the potential of Apache Airflow while ensuring performance, reliability, and data security in your workflow automation.
Opinions expressed by DZone contributors are their own.
Comments