Anomaly Detection: The Dark Horse of Fraud Detection
Anomaly detection, though less accurate, is a valuable tool for identifying unknown fraud patterns that the supervised models are not trained to detect.
Join the DZone community and get the full member experience.
Join For FreeToday, machine learning-based fraud prediction has become a mainstay in most organizations. The two common types of machine learning are supervised and unsupervised machine learning. Out of the two, supervised learning is the most desired choice for fraud prediction for apparent reasons. Supervised learning that learns the patterns from known fraud cases yields more accurate predictions. On the other hand, unsupervised learning can be leveraged even when we don’t have confirmed cases of fraud. The drawback is that it has a lower level of prediction accuracy compared to supervised learning.
Supervised ML Models Won’t Know What We Don’t Know
Organizations today typically only implement supervised models. A common reason for this is the belief that if a supervised model can deliver the best performance, there is no need to have an unsupervised model. This school of thought could prove dangerous in some domains, fraud detection being one of them. Supervised models only learn what they are taught. They can’t evolve on their own to capture the new fraud patterns. Fraudsters, conversely, are highly creative entities constantly attempting to figure out new ways of evading detection.
This domain’s adversarial nature means we must be ready to fight new fraud patterns now and then. When we ourselves haven’t had enough time to register the new fraud patterns, supervised models won’t learn them. Consider the hypothetical case shown in the charts below. The first chart shows how the supervised model (red observations) classified fraudulent and legitimate transactions at the time of training. When applied to actual data, this model detected the fraudulent transactions that fell within the realm of its learning (region shaded in light blue). However, once fraudsters understood the model well, they began evading detection by adopting new patterns (yellow observations) that the model had not encountered during training.
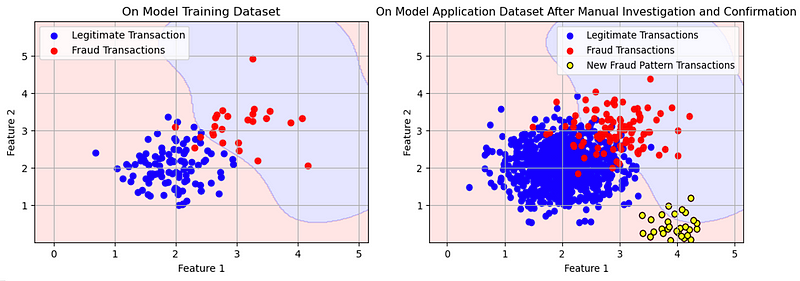
We can mitigate this limitation of supervised learning models by reducing their downtime in learning new patterns. We can set up automated model retraining to make these models learn continuously and fast. How fast? That’s subjective! In many cases, even we won’t be able to register the new fraud patterns until it’s too late, for example, we might only know about a new fraud variation when multiple customers complain about it. By this time, we might have incurred huge losses already.
So, what solution can flag suspicious patterns without us explicitly telling the model? It’s anomaly detection! If not a standalone solution for accuracy reasons, it at least deserves to be applied in combination with the supervised models. Taking the same example as before, we can see in the chart below how an anomaly detection model would have captured the new fraud patterns that the supervised model missed.
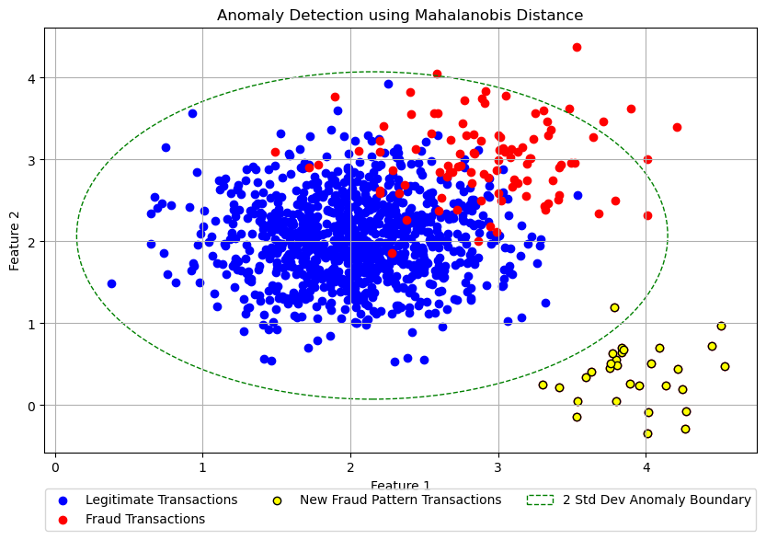
The chart above shows how an anomaly detection model would have detected the new fraud pattern transactions that the supervised model missed, as per the previous chart.
Commonly Used ML-Based Types of Anomaly Detection
Various machine learning-based anomaly detection types are used in the industry today. It’s important to note that no single method outperforms the others in every scenario To choose an appropriate kind of anomaly detection, we must understand the distribution of their data, the kinds of anomalies we might encounter, and the principles behind these detection types. This will help us decide what detection type is the best for our specific scenario.
1. Statistical Methods
These methods detect anomalies based on deviations from some central measures.
- Example: mean + 3 standard deviations
These methods can be applied to data with multiple features as well, for example, Mahalanobis distance. They often assume that the data follows a known distribution like Gaussian. There are non-parametric statistical methods, too: they don’t assume any data distribution and often rely on percentile values to identify anomalies.
- Pros: They are simple to implement and interpret.
- Cons: This can lead to poor performance if the data does not follow the assumed distribution.
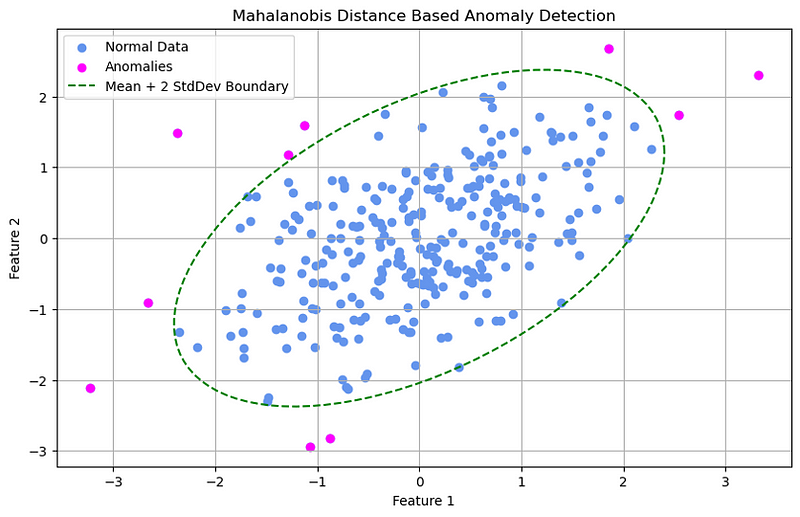
The chart above shows Mahalanobis distance-based anomaly detection.
2. Distance-Based Methods
These methods identify anomalies based on the distance between observations. Observations that are at a large distance from their neighboring observations are considered anomalies.
- Example: The k-nearest-neighbors method looks at the distance of an observation from its k-neighboring observations.
- Pros: They do not require data to follow any particular distribution.
- Cons: They are computationally expensive, especially with large datasets. They are susceptible to the “curse of dimensionality” (more on this in the later section) as the number of features increases.
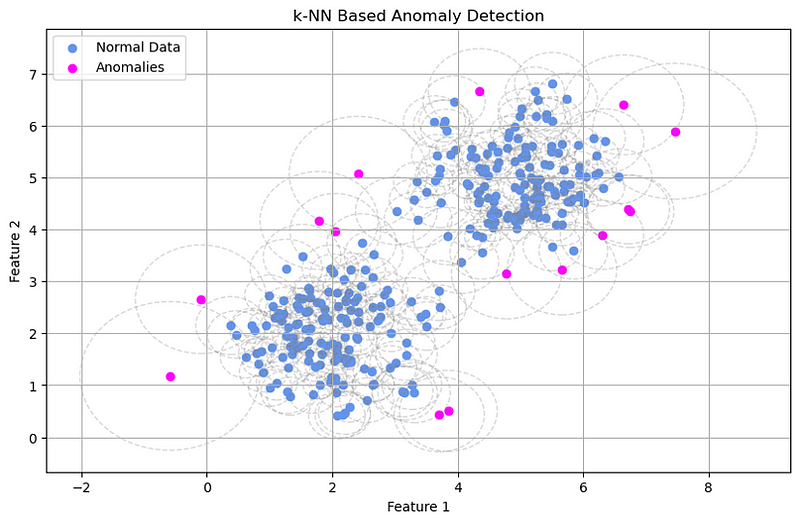
The chart above shows kNN-based anomaly detection. The circles around observations represent the average Euclidean distance to their k neighbors.
3. Density-Based Methods
Methods like Local Outlier Factor (LOF) and Density-Based Spatial Clustering of Applications with Noise (DBSCAN) identify anomalies based on the concentration of observations (density) in the neighborhood of a given observation. Observations below a certain density threshold are considered anomalies. Some of these methods, like LOF, use different local density thresholds, while some, like DBSCAN, use a single overall density threshold to detect anomalies.
Although similar to distance-based methods, they have their differences. For example, consider a group of 10 observations that are near each other but are separated from thousands of other observations. In this case, if k <=10, kNN may not identify them as anomalous since the distance between them is small. However, since they are in a much sparser region than the other observations, DBSCAN may detect them as anomalous.
Another difference is that with the density-based methods, we don’t have to specify the value ‘k’ (number of clusters), which is often difficult to decide when dealing with real-world datasets.
- Pros: They can detect a group of anomalous observations as long as the group is reasonably small. LOF is effective on datasets with complex structures with varying densities.
- Cons: We need to identify and use appropriate density parameters to get good results. They are also susceptible to the curse of dimensionality.
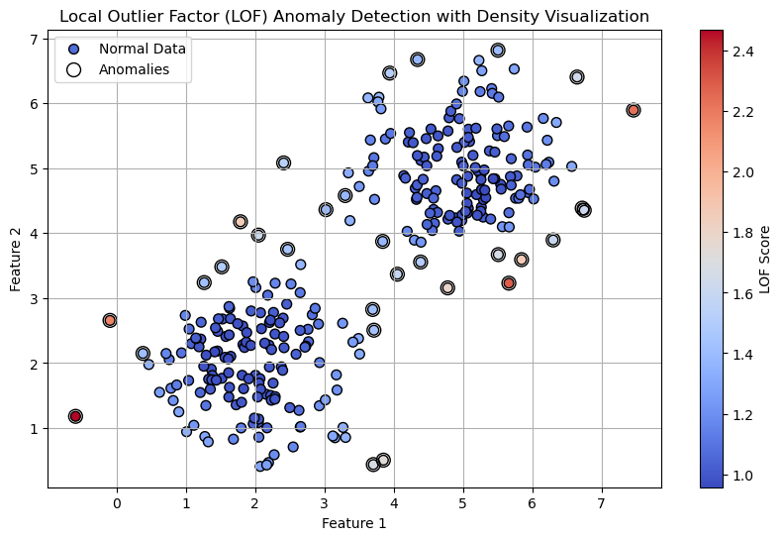
The chart above shows LOF-based anomaly detection. The color of the observations represents the local density for that observation. The higher the LOF score, the more anomalous the observation is.
4. Isolation-Based Methods
Isolation Forest is a popular method that isolates observations by partitioning data. The underlying idea is that anomalous observations can be isolated in a low number of partitions. For partitioning, features are selected randomly, and values for the split are also chosen at random within the range (min and max) of the features. An anomaly score is assigned based on how many partitions it took to isolate a given observation.
- Pros: These methods do not rely on distance or density calculations and are more robust to the curse of dimensionality, although not entirely.
- Cons: They may not perform well on smaller datasets. They may not be able to detect anomalies that have a subtle deviation from normal data.
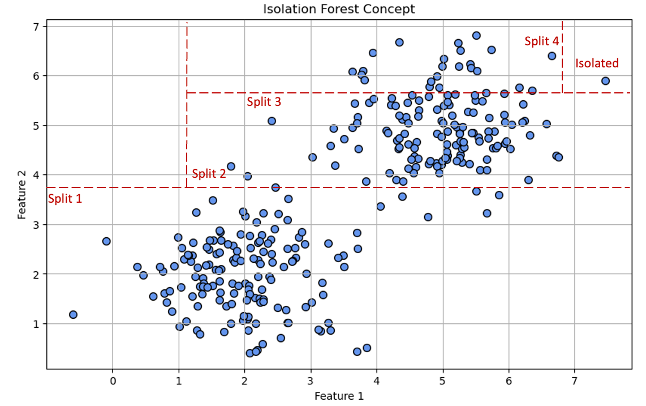
The chart above illustrates the concept of Isolation Forest. We can see that an obviously anomalous observation is isolated in merely 4 splits.
Effective Anomaly Detection Needs High Quality and a Low Number of Features
Unlike supervised models, anomaly detection models do not know how important a given feature is for fraud detection. While this helps keep detection open to new possibilities, it could also lead to poor performance. Imagine using the credit card owner’s height as a feature to detect suspicious credit card transactions. This feature will influence the detection to catch transactions coming from abnormally tall or short individuals. Thus, it’s essential to use only relevant features in the context of fraud detection. Adding meaningless features will only pollute the inputs and make the detection more difficult.
Another issue, especially with distance-based detection, is the curse of dimensionality. As the number of features increases, the distance between the two observations becomes meaningless. Thus, we must ensure that we use only a few features, even if they appear helpful. If the dataset has many potentially relevant features, we can leverage techniques like principal component analysis (PCA) to reduce their number. PCA creates new features such that the first few features capture most of the information from the old features. We can then keep only the top few features and discard the remaining ones.
Well-Designed, Simpler Anomaly Detection Frameworks Can Be Just as Good or Even Better
The key to developing a practically helpful anomaly detection is to identify the fewest number of most important features and choose the simplest, most suitable method. For example, if we want to identify a credit card compromise, we can create a single feature that captures most risk information. We can define a feature named PercentOfRiskyAttributes that gives us the percentage of risky transaction attributes. These attributes could be: is merchant risky, is transaction location new, is transaction devise new, is transaction amount suspicious, and so on. Now, knowing the average value for the feature from the overall data and using a simple binomial probability calculator, we can compute the probability of a given transaction to be a legitimate transaction. If this probability is low enough, we have detected an anomaly!
Note that incorporating relevant features the supervised model does not utilize can enhance anomaly detection and provide protection against fraud which the supervised model may miss.
Practical Considerations
False Positives
Anomaly detection is generally based on deviations from the average behavior. However, deviations are natural to any measurement and don’t always indicate a concern. To avoid false positives due to such benign deviations, we can resort to a less strict detection threshold. But this may cause us to miss the actual cases of fraud. So, it’s vital that we carefully evaluate the tradeoff between the two.
A workaround to reduce false positives is to trigger an alarm only when we have observed a certain number of anomalous events. If we are implementing anomaly detection for new fraud pattern detection, this approach works well, as we need multiple observations to confirm an evolving fraud pattern.
Operational Costs
Anomaly detection may increase operational costs. Most anomaly detection systems don’t provide the precision required for automated actions like denying a transaction. The outcome of anomaly detection is typically a human investigation. This increased operational cost of investigation could be a deterrent for many organizations. However, considering the cost versus benefits in the long term, investing resources in an anomaly detection system could still be a financially rewarding decision in many scenarios concerning fraud detection.
Conclusion
Anomaly detection methods are overlooked due to the level of accuracy they provide in comparison with the supervised models. However, they are an essential tool in fraud detection. A well-designed anomaly detection system can complement a supervised model and protect organizations against new and evolving fraud patterns. In the absence of labeled data to train supervised models, anomaly detection can expedite the data collection. It can identify high-risk instances with greater precision, making it easier to collect fraud samples.
Note: Unless otherwise noted, all images are by the author.
Published at DZone with permission of Sumit Makashir. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments