Anatomy of a High Availability Kubernetes Cluster
How to put together an unstoppable K8s cluster using node redundancy, a fronting load balancer, an ingress controller and an internal load balancer.
Join the DZone community and get the full member experience.
Join For FreeIn my previous article, I hinted at explaining how Ansible can be used to expose applications running inside a high availability K8s cluster to the outside world. This post will show how this can be achieved using a K8s ingress controller and load balancer.
This example uses the same setup as last time around: virtual machines running under the default Windows Hypervisor (Hyper-V). To make room for the addition of a proxy each VM had to give up some RAM. With the exception of the initial master and the Ansible runner, each of the remaining nodes received an allocation of 2000MB.
A new version of the sample project is available at GitHub with a new playbook called k8s_boot.yml. This yaml boots up the entire cluster instead of having to run multiple playbooks one after the other. It configures the cluster according to the specification of the inventory file. The flow of execution can be better, but I changed the underlying copybooks as little as possible so readers of previous posts can still find their way.
Since the architecture of this post might seem complex at first encounter, an architectural diagram is included towards the very bottom to clarify the landscape.
Master and Commanders
In the previous article I alluded to the fact that a high availability cluster requires multiple co-masters to provide backup should the current master act up. We will start off by investigating how this redundancy is used to establish high availability.
The moment a co-master loses comms with the master, it nominates itself to become the next master. Each of the remaining masters then has to acknowledge its claim upon receiving news of its candidacy. However, another co-master can also notice the absence of the current master before receiving word of a candidacy and nominating itself. Should 50% of the vote be the requirement to assume control, it is possible for two control planes to each attract 50% and think itself the master. Such a cluster will go split-brained with two masters orchestrating a bunch of very confused worker nodes. For this reason, K8s implements the raft protocol from, which follows the typical requirement that a candidate should receive a quorum of 50%+1 before it gains the respect to boss all and sundry. Consequently, a high availability K8s cluster should always comprise of an unequal number of masters. For the project, this means that the inventory should always contain an equal number of co-masters, with the initial master then assuring the inequality.
The bootup playbook imports the older k8s_comasters.yml playbook into its execution to prepare and execute the well-known "kubeadm join" command on each of the co-masters:
kubeadm join k8scp:6443 --token 9ei28c.b496t8c4vbjea94h --discovery-token-ca-cert-hash sha256:3ae7abefa454d33e9339050bb26dcf3a31dc82f84ab91b2b40e3649cbf244076 --control-plane --certificate-key 5d89284dee1717d0eff2b987f090421fb6b077c07cf21691089a369781038c7b
Joining workers nodes to the cluster uses a similar join command but omits the --control-plane switch, as can be seen in k8s_workers.yml, also imported during bootup.
After running the bootup playbook, the cluster will comprise both control-plane and worker nodes:

Control At All Times
At this point in time, all nodes refer to the original master by hostname, as can be seen from the "kube init" command that starts the first master:
kubeadm init --pod-network-cidr 10.244.0.0/16 --control-plane-endpoint k8scp:6443 --upload-certsClearly, this node is currently the single point of failure of the cluster. Should it fall away, the cluster's nodes will lose contact with each other. The Ansible scripts mitigate for this by installing the kube config to all masters so kubectl commands can be run from any master by such designated user. Changing the DNS entry to map k8scp to one of the other control planes will hence restore service. While this is easy to do using the host file, additional complexities can arise when using proper DNS servers. Kubernetes orthodoxy, consequently, has that a load balancer should be put in front of the cluster to spread traffic across each of the master nodes. A control plane that falls out will be removed from the duty roster by the proxy. None will be the wiser.
HAProxy fulfills this role perfectly. The Ansible tasks that make this happen are:
- name: Install HAProxy
become: true
ansible.builtin.apt:
name: haproxy=2.0.31-0ubuntu0.2
state: present
- name: Replace line in haproxy.cfg1.
become: true
lineinfile:
dest: /etc/haproxy/haproxy.cfg
regexp: 'httplog'
line: " option tcplog"
- name: Replace line in haproxy.cfg2.
become: true
lineinfile:
dest: /etc/haproxy/haproxy.cfg
regexp: 'mode'
line: " mode tcp"
- name: Add block to haproxy.cfg1
become: true
ansible.builtin.blockinfile:
backup: false
path: /etc/haproxy/haproxy.cfg
block: |-
frontend proxynode
bind *:80
bind *:6443
stats uri /proxystats
default_backend k8sServers
backend k8sServers
balance roundrobin
server cp {{ hostvars['host1']['ansible_host'] }}:6443 check
{% for item in comaster_names -%}
server {{ item }} {{ hostvars[ item ]['ansible_host'] }}:6443 check
{% endfor -%}
listen stats
bind :9999
mode http
stats enable
stats hide-version
stats uri /stats
- name: (Re)Start HAProxy service
become: true
ansible.builtin.service:
name: haproxy
enabled: true
state: restartedThe execution of this series of tasks is triggered by the addition of a dedicated server to host HAProxy to the inventory file. Apart from installing and registering HAProxy as a system daemon, this snippet ensures that all control-plane endpoints are added to the duty roster. Not shown here is that the DNS name (k8scp) used in the "kubeadm join" command above is mapped to the IP address of the HAProxy during bootup.
Availability and Accessibility
Up to this point, everything we have seen constitutes the overhead required for high-availability orchestration. All that remains is to do a business Deployment and expose a K8s service to track its pods on whichever node they may be scheduled on:
kubectl create deployment demo --image=httpd --port=80
kubectl expose deployment demoLet us scale this deployment to two pods, each running an instance of the Apache web server:
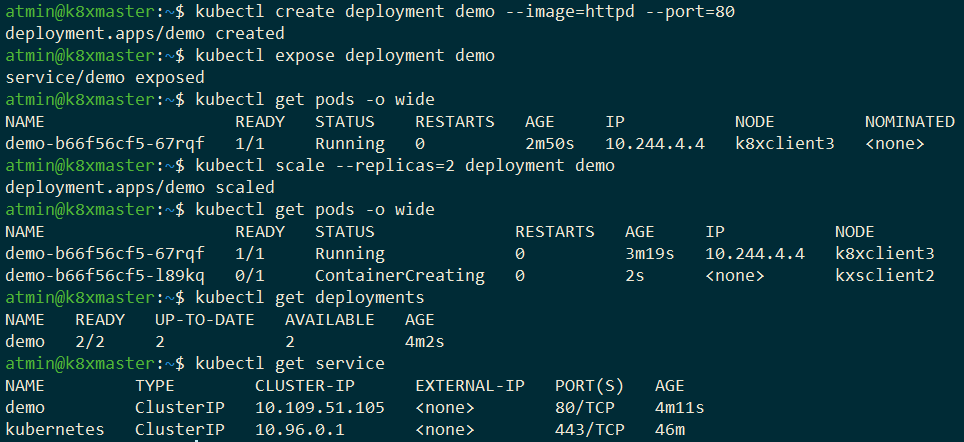
This two-pod deployment is fronted by the demo Service. The other Service (kubernetes) is automatically created and allows access to the API server of the control plane. In a previous DZone article, I explained how this API can be used for service discovery.
Both services are of type ClusterIP. This is a type of load balancer, but its backing httpd pods will only be accessible from within the cluster, as can be seen from the absence of an external ip. Kubernetes provides various other service types, such as NodePort and LoadBalancer, to open up pods and containers for outside access. A NodePort opens up access to the service on each Node. Although it is possible for clients to juggle IP addresses should a node fall out, the better way is to use a LoadBalancer. Unfortunately, Kubernetes does not provide an instance as it is typically provided by cloud providers. Similarly, an on-premise or bare-metal cluster has to find and run its own one. Alternatively, its clients have to make do as best they can by using NodePorts or implementing its own discovery mechanism. We will follow the first approach by using MetalLB to slot K8s load balancing into our high availability cluster.
This is a good solution, but it is not the best solution. Since every K8s deployment will be exposed behind its own LoadBalancer/Service, clients calling multiple services within the same cluster will have to register the details of multiple load balancers. Kubernetes provides the Ingress API type to counter this. It enables clients to request service using the HTTP(S) routing rules of the Ingress, much the way a proxy does it.
Enough theory! It is time to see how Ansible can declare the presence of an Ingress Controller and LoadBalancer:
- hosts: masters
gather_facts: yes
connection: ssh
vars_prompt:
- name: "metal_lb_range"
prompt: "Enter the IP range from which the load balancer IP can be assigned?"
private: no
default: 192.168.68.200-192.168.69.210
tasks:
- name: Installing Nginx Ingress Controller
become_user: "{{ ansible_user }}"
become_method: sudo
# become: yes
command: kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.0.5/deploy/static/provider/cloud/deploy.yaml
run_once: true
- name: Delete ValidatingWebhookConfiguration
become_user: "{{ ansible_user }}"
become_method: sudo
# become: yes
command: kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission
run_once: true
- name: Install Metallb1.
become_user: "{{ ansible_user }}"
become_method: sudo
become: yes
shell: 'kubectl -n kube-system get configmap kube-proxy -o yaml > /home/{{ ansible_user }}/kube-proxy.yml'
- name: Install Metallb2.
become_user: "{{ ansible_user }}"
become_method: sudo
become: yes
command: kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.11/config/manifests/metallb-native.yaml
- name: Prepare L2Advertisement.
become_user: "{{ ansible_user }}"
become_method: sudo
copy:
dest: "~/l2advertisement.yml"
content: |
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
- name: Prepare address pool.
become_user: "{{ ansible_user }}"
become_method: sudo
copy:
dest: "~/address-pool.yml"
content: |
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- {{ metal_lb_range }}
- pause: seconds=30
- name: Load address pool
become_user: "{{ ansible_user }}"
become_method: sudo
command: kubectl apply -f ~/address-pool.yml
- name: Load L2Advertisement
become_user: "{{ ansible_user }}"
become_method: sudo
command: kubectl apply -f ~/l2advertisement.yml
...First off, it asks for a range of IP addresses that are available for use by the LoadBalancers. It subsequently installs the Nginx Ingress Controller and, lastly, MetallLB to load balance behind the Ingress.
MetalLB uses either the ARP (IPv4)/NDP(IPv6) or the BGP to announce the MAC address of the network adaptor. Its pods attract traffic to the network. BGP is probably better as it has multiple MetalLB speaker pods announcing. This might make for a more stable cluster should a node fall out. ARP/NDP only has one speaker attracting traffic. This causes a slight unresponsiveness should the master speaker fail and another speaker has to be elected. ARP is configured above because I do not have access to a router with a known ASN that can be tied into BGP.
Next, we prepare to boot the cluster by designating co-masters and an HAProxy instance in the inventory. Lastly, booting with the k8s_boot.yml playbook ensures the cluster topology as declared in the inventory file is enacted:

Each node in the cluster has one MetalLB speaker pod responsible for attracting traffic. As stated above, only one will associate one of the available IP addresses with its Mac address when using ARP. The identity of this live wire can be seen at the very bottom of the Ingress Controller service description:

Availability in Action
We can now test cluster stability. The first thing to do is to install an Ingress:
kubectl create ingress demo --class=nginx --rule="www.demo.io/*=demo:80"Browse the URL, and you should see one of the Apache instances returning a page stating: "It works!":

This IP address spoofing is pure magic. It routes www.demo.io to the Apache web server without it being defined using a DNS entry outside the cluster.
The Ingress can be interrogated from kubectl:
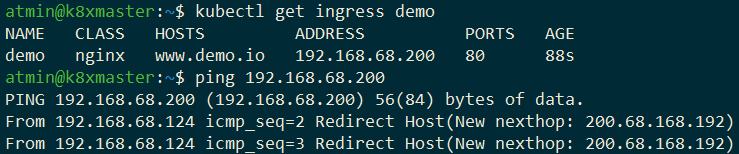
One sees that it can be accessed on one of the IP addresses entered during bootup. The same can also be confirmed using wget, the developer tools of any browser worth its salt, or by inspecting the ingress controller:

Should the external IP remain in the pending state, Kubernetes could not provision the load balancers. The MetalLB site has a section that explains how to troubleshoot this.
We confirmed that the happy case works, but does the web server regain responsiveness in case of failure?
We start off by testing whether the IngressController is a single point of failure by switching the node where it ran:
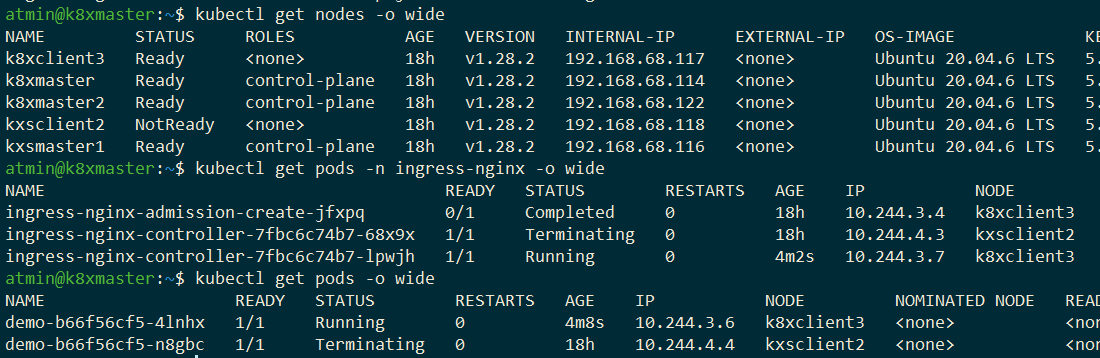
Kubernetes realized that the node was no longer in the cluster, terminated all the pods running on that cluster, and rescheduled them on the remaining worker node. This included the IngressController. The website went down for a while, but Kubernetes eventually recovered service. In other words, orchestration in action!
Next up, we remove the MetalLB speaker by taking down the cluster where it runs:

Another speaker will step up to the task!
What about HAProxy? It runs outside the cluster. Surely, this is the single point of failure. Well... Yes and no.
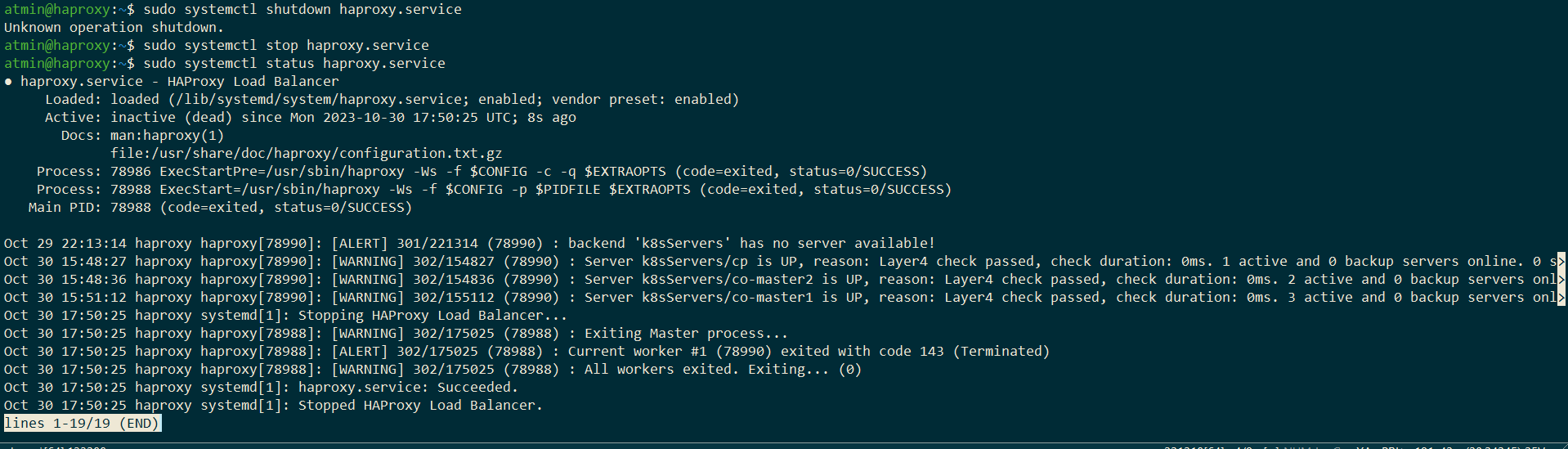
Yes, because one loses connection to the control planes:

No, because all that is required is to map the IP address of k8scp from that of the HAProxy to that of one of the masters. The project has an admin playbook to do this. Run it and wait for the nodes to stabilize into a ready state. Ingress still routes, MetalLB still attracts, and httpd still serves:

Due to the HAProxy being IAC, it is also no trouble to boot a new proxy and slot out the faulty/crashed one. The playbook used above to temporarily switch traffic to a master can also be used during such a proxy replacement. Unfortunately, this requires human interaction, but at least the human knows what to monitor with the utmost care and how to quickly recover the cluster.
Final Architecture
The final architecture is as follows:

Note that all the MetalLB speakers work as a team to provide LoadBalancing for the Kubernetes Services and its Deployments.
Conclusion
There probably are other ways to install a high availability K8s cluster, but I like this double load balancer approach:
- HAProxy abstracts and encapsulates the redundancy of an unequal number of control planes, e.g., it ensures 99.9999% availability for cluster controlling commands coming from kubectl;
- MetalLB and Nginx Ingress Controller working together to track the scheduling of business pods. Keep in mind that the master can move a pod with its container(s) to any worker node depending on failure and resource availability. In other words, the MetalLB LoadBalancer ensures continuity of business logic in case of catastrophic node failure.
In our sample, the etcd key-value store is located as part of the control-planes. This is called the stacked approach. The etcd store can also be removed from the control-planes and hosted inside its own nodes for increased stability. More on this here.
Our K8s as Ansible project is shaping nicely for use as a local or play cloud. However, a few things are outstanding that one would expect in a cluster of industrial strength:
- Role based access control (RBAC);
- Service mesh to move security, observability, and reliability from the application into the platform;
- Availability zones in different locations, each with its one set of HAProxy, control-planes, and workers separated from each other using a service mesh;
- Secret management;
- Ansible lint needs to be run against the Ansible playbooks to identify bad and insecure practices requiring rectification;
- Choking incoming traffic when a high load of failure is experienced to allow business pods to continue service or recover gracefully.
It should be noted, though, that nothing prevents one to add these to one's own cluster.
Opinions expressed by DZone contributors are their own.
Comments