Apache Doris Storage Layer Design and Storage Structure
A review of Apache Doris's storage capabilities, including a deep dive into save file formats, indexing, and its BloomFilter.
Join the DZone community and get the full member experience.
Join For FreeDoris is an interactive SQL data warehouse based on MPP architecture, mainly used to solve near real-time reporting and multidimensional analysis. Doris's efficient import and query are inseparable from the sophisticated design of its storage structure.
This article mainly analyzes the implementation principle of the storage layer of the Doris BE module by reading the code of the Doris BE module, and expounds and decrypts the core technology behind the efficient writing and query capabilities of Doris. It includes Doris column storage design, index design, data read and write process, compaction process, version management of Tablet and Rowset, data backup, and other functions.
This article introduces the storage layer structure of the Segment V2 version, including rich functions such as ordered storage, sparse index, prefix index, bitmap index, BloomFilter, etc., which can provide extremely fast query capabilities for various complex scenarios.
Design Goals
Bulk import, few updates
the vast majority of read requests
Wide table scenario, read a lot of rows, few columns
Non-transactional scenarios
good scalability
Save File Format
Storage Directory Structure
The storage layer's management of storage data is configured through the storage_root_path path, which can be multiple. The next layer of the storage directory is organized according to buckets. Specific tablets are stored in the bucket directory, and subdirectories are named according to tablet_id.
Segment files are stored in the tablet_id directory and managed according to SchemaHash. There can be multiple Segment files, generally divided according to size, the default is 256MB. Among them, the segment v2 file naming rule is: ${rowset_id}_${segment_id}.dat.
The specific storage directory storage format is shown in the following figure:

Segment v2 File Structure
The overall file format of Segment is divided into three parts: data area, index area, and footer, as shown in the following figure:

Data Region: used to store the data information of each column, the data here is loaded in pages as needed
Index Region: Doris stores the index data of each column uniformly in the Index Region. The data here will be loaded according to the column granularity, so it is stored separately from the column data information.
Footer information
SegmentFooterPB: Define the metadata information of the file
4 bytes checksum of FooterPB content
4 bytes of FileFooterPB message length for reading FileFooterPB
The following distribution introduces the design of the storage format of each part.
Footer Information
The Footer information segment is at the end of the file, which stores the overall structure of the file, including the location of the data field, the location of the index field, and other information, including SegmentFooterPB, CheckSum, Length, MAGIC CODE 4 parts.
SegmentFooterPB data structure is as follows:

SegmentFooterPB uses the PB format for storage, which mainly includes the meta information of the column, the meta information of the index, the short key index information of the segment, and the total number of rows.
Column Meta Information
- ColumnId: the serial number of the current column in the schema
- UniqueId: globally unique id
- Type: the type information of the column
- Length: the length information of the column
- Encoding: encoding format
- Compression: Compression format
- Dict PagePointer: Dictionary information
Meta Information of Column Index
OrdinalIndex: Stores the sparse index meta information of the column.
ZoneMapIndex: Stores the meta information of the ZoneMap index, including the maximum value, the minimum value, whether there is a null value, and whether there is no non-null value. SegmentZoneMap stores the global ZoneMap information, and PageZoneMaps stores the statistical information of each page.
BitMapIndex: Stores the meta information of BitMap index, including BitMap type, dictionary data BitMap data.
BloomFilterIndex: Stores the BloomFilter index information.
In order to prevent the data volume of the index itself from being too large, ZoneMapIndex, BitMapIndex, and BloomFilterIndex adopt two-level Page management. Corresponding to the structure of IndexColumnMeta, when a Page can be put down, the current Page directly stores the index data, that is, a level 1 structure is adopted; when a Page cannot be put down, the index data is written into a new Page, and the Root Page stores the address information of the data page.
Ordinal Index
The Ordinal Index index provides the physical address of the Column Data Page by row number. An ordinal Index can align column-stored data by row, which can be understood as a first-level index. When looking for data in other indexes, the Ordinal Index is used to find the location of the data Page. Therefore, the Ordinal Index index is introduced here first.
In a segment, data is always stored in the sorted order of keys (AGGREGATE KEY, UNIQ KEY, and DUPLICATE KEY), that is, the sorting of keys determines the physical structure of data storage. The physical structure order of the column data is determined. When writing data, the Column Data Page is managed by the Ordinal index. The Ordinal index records the position offset, size, and row number information of the first data item of each Column Data Page. Namely Ordinal. In this way, each column has the ability to quickly scan by row information. The sparse index structure adopted by the Ordinal index is like a book directory, recording the page number corresponding to each chapter.
Storage Structure
Ordinal index meta information is stored in OrdinalIndexMeta for each column in SegmentFooterPB. The specific structure is shown in the following figure:

The root page address corresponding to the index data is stored in OrdinalIndexMeta. Some optimizations are made here. When the data has only one page, the address here can directly point to the only data page; when a page cannot be placed, it points to the second page of the Ordinal Index type Hierarchical structure index page, each data item in the index data corresponds to the Column Data Page offset position, size, and ordinal row number information. The Ordinal Index granularity is the same as the page granularity, and the default is 64*1024 bytes.
Column Data Store
Data Page Storage Structure
DataPage is mainly divided into two parts: the Data part and Page Footer.
The Data section stores the data of the columns of the current Page. When the Null value is allowed, the Bitmap of the Null value is stored separately for the null value, and the row number of the Null value is recorded by the RLE format encoding through the bool type.

Page Footer contains Page type Type, UncompressedSize uncompressed data size, FirstOrdinal RowId of the first row of the current Page, NumValues is the number of rows of the current Page, NullMapSize corresponds to the size of NullBitmap.
Data Compression
Different encodings are used for different field types. By default, the correspondences adopted for different types are as follows:
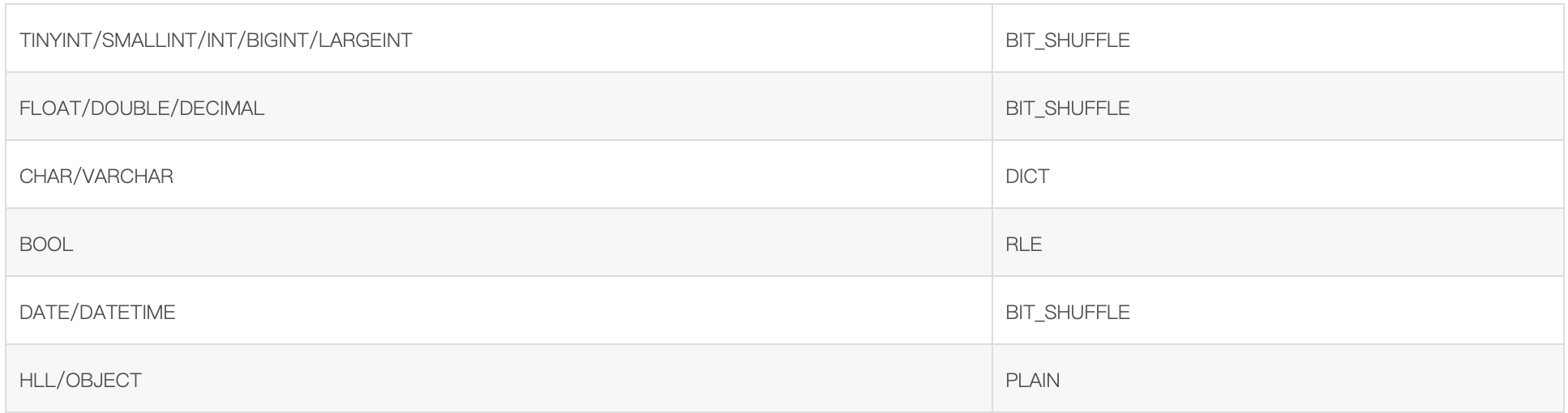
The data is compressed in LZ4F format by default.
Short Key Index
Storage Structure
Short Key Index prefix index is an index method to quickly query data according to a given prefix column based on the sorting of keys (AGGREGATE KEY, UNIQ KEY, and DUPLICATE KEY). Here, the Short Key Index index also adopts a sparse index structure. During the data writing process, an index item will be generated every certain number of rows. The number of rows is 1024 rows by default for the index granularity, which can be configured. The process is shown in the following diagram:

Among them, KeyBytes stores the index item data, and OffsetBytes stores the offset of the index item in KeyBytes.
Index Generation Rules
The Short Key Index uses the first 36 bytes as the prefix index for this row of data. Prefix indexes are simply truncated when a VARCHAR type is encountered.
Application Cases
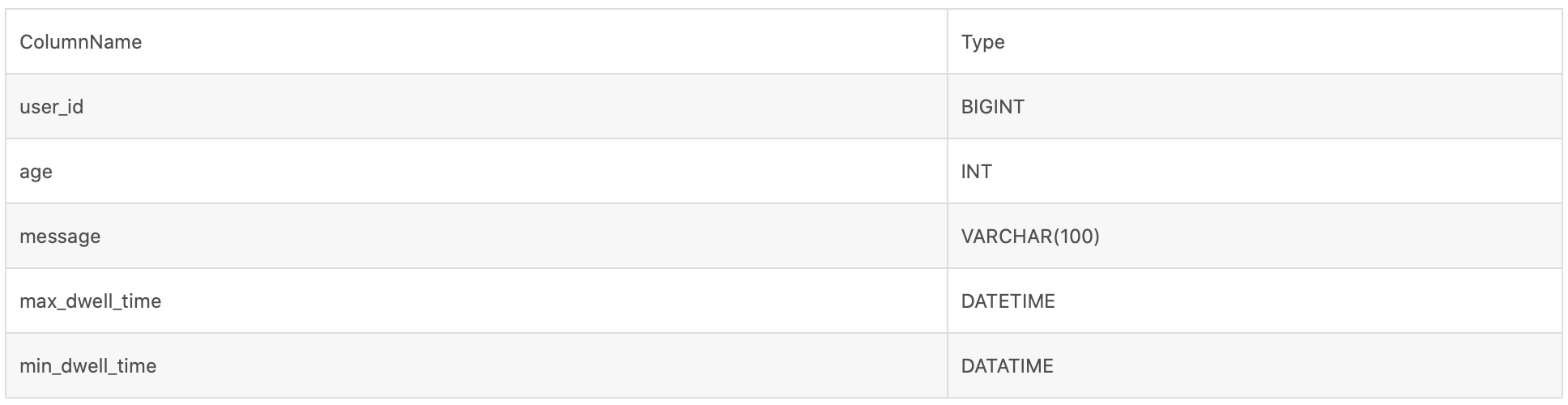
(1) The prefix index of the following table structure is user_id(8Byte) + age(4Bytes) + message(prefix 24 Bytes).
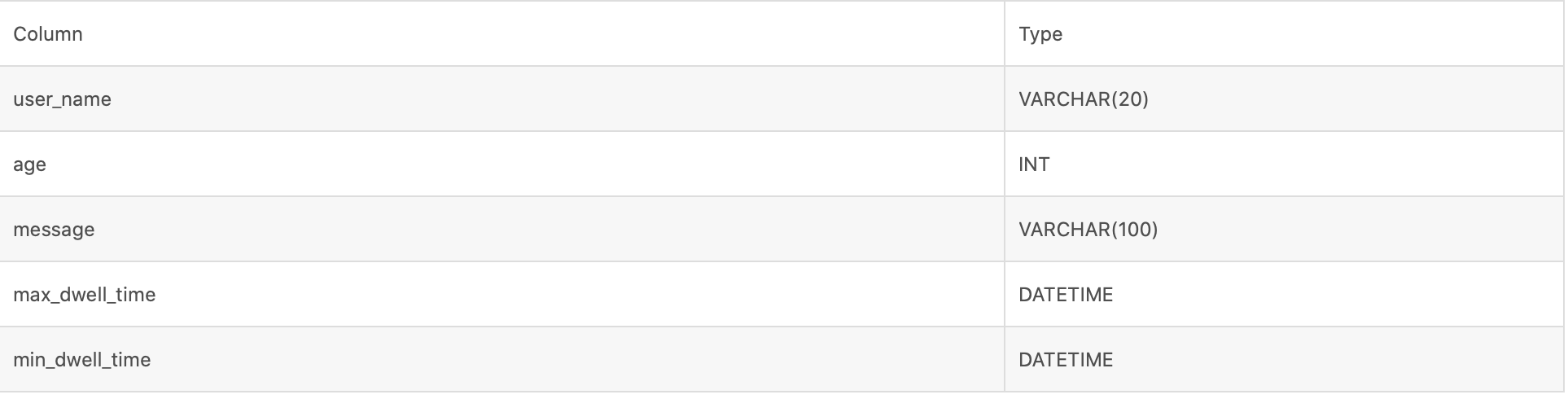
(2) The prefix index of the following table structure is user_name (20 Bytes). Even if it does not reach 36 bytes, because VARCHAR is encountered, it is directly truncated and will not continue further.
When our query condition is the prefix of the prefix index, the query speed can be greatly accelerated. For example, in the first example, we execute the following query:
SELECT * FROM table WHERE user_id=1829239 and age=20;This query will be much more efficient than the following query:
SELECT * FROM table WHERE age=20;Therefore, when building a table, choosing the correct column order can greatly improve query efficiency.
ZoneMap Index
The ZoneMap index stores the statistics of the Segment and each column corresponding to each Page. These statistics can help speed up the query and reduce the amount of scanned data. The statistics include the maximum value of Min, the minimum value of Max, HashNull null value, and HasNotNull not all null information.
Storage Structure
The index storage structure of ZoneMap is shown in the following figure:
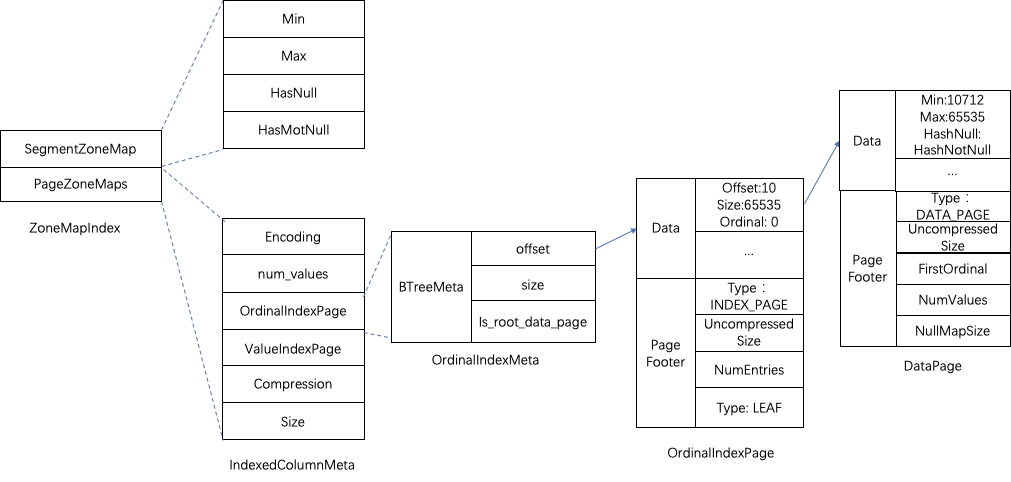
In the SegmentFootPB structure, each column of index metadata ColumnIndexMeta stores the ZoneMapIndex index data information of the current column. ZoneMapIndex has two parts, SegmentZoneMap and PageZoneMaps. SegmentZoneMap stores the global ZoneMap index information of the current Segment, and PageZoneMaps stores the ZoneMap index information of each Data Page.
PageZoneMaps corresponds to the IndexedColumnMeta structure of the Page information stored in the index data. Currently, there is no compression in the implementation, and the encoding method is also Plain. The OrdinalIndexPage in IndexedColumnMeta points to the offset and size of the root page of the index data. The second-level Page optimization is also done here. When there is only one DataPage, OrdinalIndexMeta directly points to this DataPage; when there are multiple DataPages, OrdinalIndexMeta points to OrdinalIndexPage first, OrdinalIndexPage It is a secondary Page structure, and the data items in it are the address offset, Size and ordinal information of the index data DataPage.
Index Generation Rules
Doris opens the ZoneMap index for the key column by default; when the model of the table is DUPULCATE, the ZoneMap index is enabled for all fields. When the column data is written to the Page, the data is automatically compared, and the index information of the ZoneMap of the current Segment and the ZoneMap of the current Page is continuously maintained.
Application Cases
During data query, the fields that will be filtered according to the range conditions will select the scanned data range according to the ZoneMap statistics. For example, in case 1, filter on the age field. The query statement is as follows:
SELECT * FROM table WHERE age > 20 and age < 1000If the Short Key Index is not hit, it will use the ZoneMap index to find the ordinary range of data that should be scanned according to the query conditions of age in the conditional statement, reducing the number of pages to be scanned.
BloomFilter
Doris provides a BloomFilter index when some fields cannot use Short Key Index and the field has a high degree of discrimination.
Storage Structure
The storage structure of BloomFilter is shown in the following figure::
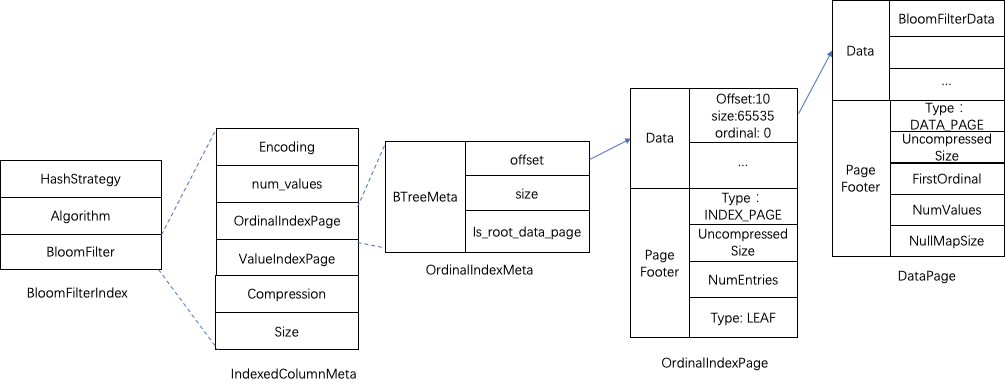
The BloomFilterIndex information stores the produced Hash strategy, Hash algorithm, and the corresponding data Page information of BloomFilter. The hash algorithm adopts HASH_MURMUR3, the Hash strategy adopts BlockSplitBloomFilter block implementation strategy, and the expected false positive rate fpp is configured to be 0.05 by default.
The storage of data pages corresponding to BloomFilter index data is similar to that of ZoneMapIndex, and the optimization of secondary pages has been done, which will not be described in detail here.
Index Generation Rules
BloomFilter is generated by Page granularity. When data is written to a complete Page, Doris will generate the BloomFilter index data of this Page at the same time according to the Hash strategy. Currently, the filter does not support tinyint/hll/float/double types, other types are already supported. When using, you need to specify bloom_filter_columns in PROPERTIES The fields to be indexed by BloomFilter.
Application Cases
When querying data, the query conditions are filtered in the field with the bloom filter set. When the bloom filter is not hit, it means that there is no such data on the page, which can reduce the number of pages to be scanned.
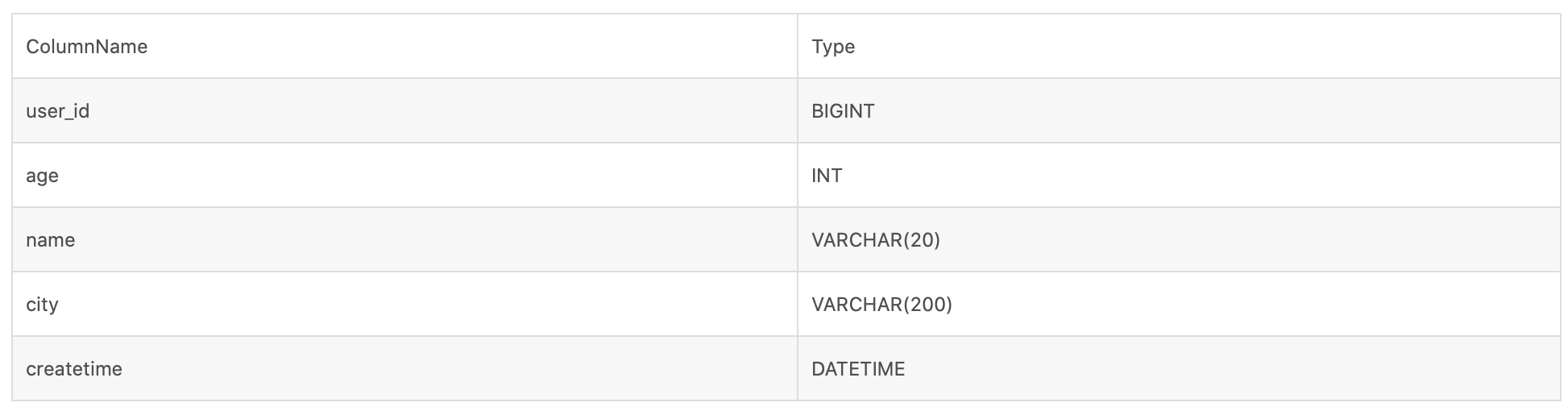
Case: The schema of the table is as follows:

The SQL here is as follows:
SELECT * FROM table WHERE name = 'Zhang San'Due to the high degree of discrimination of names, in order to improve the query performance of SQL, a BloomFilter index, PROPERTIES ( "bloom_filter_columns" = "name" ), is added to the name data. At query time, the BloomFilter index can filter out a large number of Pages.
Bitmap Index index
Doris also provides BitmapIndex to speed up data queries.
Storage structure
The bitmap storage format is as follows:

The meta information of BitmapIndex is also stored in SegmentFootPB. BitmapIndex includes three parts, BitMap type, dictionary information DictColumn, and bitmap index data information BitMapColumn. Among them, DictColumn and BitMapColumn correspond to the IndexedColumnData structure, and store the Page address offset and size of dictionary data and index data respectively. The optimization of the secondary page is also done here, and will not be explained in detail.
The difference between this and other index storage structures is that the DictColumn dictionary data is LZ4F compressed, and the first value in the Data Page is stored when the secondary Page offset is recorded.
Index Generation Rules
When creating a BitMap, it needs to be created through CREATE INDEX. The index of the Bitmap is the index of the Column field in the entire Segment, rather than generating a separate copy for each Page. When writing data, a map structure is maintained to record the row number corresponding to each key value, and the Roaring bitmap is used to encode the rowid. The main structure is as follows:

When generating index data, the dictionary data is first written, and the key value of the map structure is written into the DictColumn. Then, the key corresponds to the Roaring-encoded rowid to write data into BitMapColumn in bytes.
Application Cases
When querying data, bitmap indexes can be used to optimize data columns with small degrees of differentiation and small column cardinality. For example, gender, marriage, geographic information, etc.
Case: The schema of the table is as follows:
The SQL here is as follows:
SELECT * FROM table WHERE city in ("Beijing", "Shanghai")Since the value of city is relatively small, after the data dictionary and bitmap are established, matching rows can be quickly found by scanning the bitmap. And after bitmap compression, the amount of data itself is small, and the entire column can be accurately matched by scanning less data.
Index Query Process
When querying data in a Segment, according to the query conditions executed, the data will be filtered first according to the field indexing. Then read the data, the overall query process is as follows:
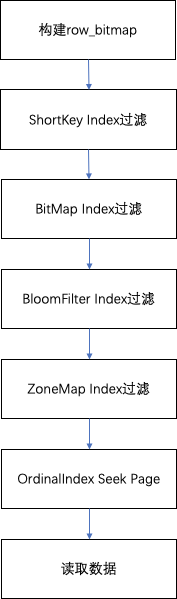
First, a row_bitmap will be constructed according to the number of rows in the Segment, indicating that the data needs to be read to record. If no index is used, all data needs to be read.
When the key is used in the query condition according to the prefix index rule, the ShortKey Index will be filtered first, and the ordinal row number range matched in the ShortKey Index can be merged into the row_bitmap.
When there is a BitMap Index index in the column field in the query condition, the ordinal row number that meets the conditions will be directly found according to the BitMap index, and the intersection filter with row_bitmap will be obtained. The filtering here is accurate, and after removing the query condition, this field will not be filtered by the subsequent index.
When there is a BloomFilter index in the column field in the query condition and the condition is equal (eq, in, is), it will be filtered by the BloomFilter index, here will go through all the indexes, filter the BloomFilter of each Page, and find out the query condition can be All Pages hit. Intersect the ordinal row number range in the index information with row_bitmap.
When there is a ZoneMap index in the column field in the query condition, it will be filtered by the ZoneMap index. Here, all the indexes will also be traversed to find all the pages that the query condition can intersect with the ZoneMap. Intersect the ordinal row number range in the index information with row_bitmap.
After the row_bitmap is generated, find the specific Data Page in batches through the OrdinalIndex of each Column.
Batch read the data of the Column Data Page of each column. When reading, for a page with a null value, judge whether the current row is null according to the null value bitmap. If it is null, it can be filled directly.
Summary
Doris currently adopts a complete column storage structure and provides rich indexes to deal with different query scenarios, laying a solid foundation for Doris's efficient writing and query performance. The Doris storage layer is designed to be flexible, and functions such as new indexes and enhanced data deletion can be further added in the future.
Opinions expressed by DZone contributors are their own.
Comments