Accelerate Innovation by Shifting Left FinOps: Part 6
In this final installment, we will discuss a worked-out example of how to apply cost optimization FinOps techniques early in the solution lifecycle.
Join the DZone community and get the full member experience.
Join For FreeIn the first two parts of this series, we understood the importance of cost models and how to create and refine cost models. In the subsequent parts, we learned how to optimize our workload components across infrastructure, applications, and data. In this final part, we will present the impact and results related to applying the cost optimization and ShiftLeft FinOps techniques for a cloud-native application. We will use the sample application or workload introduced in the initial post.
Reference (Part 1 of this series): The Workload
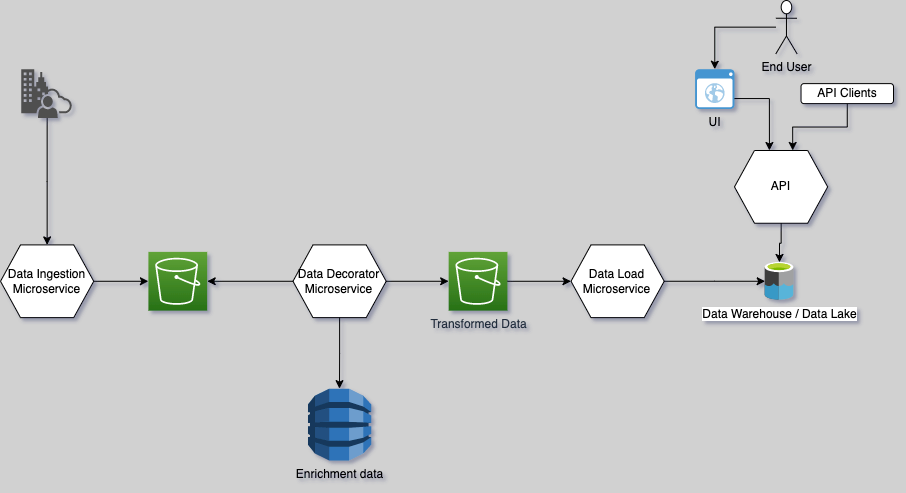
Candidate Architecture for the representative Cloud Native Application
This candidate workload consists of components in the multiple layers of the architecture. The cloud-native application performs data ingestion processing to enrich and analyze the data and then outputs the data along with reports and insights for a user. We will utilize a cloud-agnostic approach and break the workload and optimization techniques across infrastructure, application, and data components. Subsequent sections illustrate the gains and impact of applying these techniques across various layers.
Building and Refining the Cost Model
Reference (Part 2 of this series): Creating and refining the FinOps Cost Model
We looked at elaborating the requirement to find a balance between model complexity and the granularity of performance levels expected from the solution. The models were refined based on the requirements. The following table, for example, helps you determine your compute requirements based on the data ingestion timelines for the workload.
| MONTHLY SOURCE DATA SIZE IN GIB | DATA PROCESSING TIME IN HOURS (APPROX) | NUMBER OF INSTANCES (PROCESSING HOURS/24) | COMPUTE INSTANCE TYPE | STORAGE SIZE IN GIB |
|---|---|---|---|---|
| >= 300 | 196 | 9 | CPU: 4, RAM: 32 GB |
50 |
| 200-<300 | 42 | 2 | CPU: 4, RAM: 32 GB |
30 |
| 100- <200 | 20 | 1 | CPU: 4, RAM: 32 GB |
20 |
| 50- <100 | 17 | 1 | CPU: 4, RAM: 32 GB |
10 |
| 20 - <50 | 10 | 1 | CPU: 4, RAM: 32 GB |
5 |
| 5 - <20 | 6 | 1 | CPU: 4, RAM: 32 GB |
2 |
| < 5 | 2 | 1 | CPU: 4, RAM: 32 GB |
0.5 |
Similarly, based on the monthly source data and the response time needed for the queries, the databases are sized.
| QUERY TYPE | ELAPSED TIME | SLOTS CONSUMED | SLOT TIME CONSUMED |
|---|---|---|---|
| Query for line items | 19s | 81.95 | 25 min 57 sec |
| Query for aggregated records | 15s | 90.47 | 22min 37 sec |
A workload planning capability, as provided by Cloudability, is recommended to create the cost model as well as track, monitor, and analyze your spending through development, deployment, and operations.
Cost Optimization Techniques for Infrastructure
Reference (Part 3 of this series): Cost optimization techniques for infrastructure
The table below lists the potential optimization and techniques for the infrastructure layer applied to the example workload.
# |
Optimisation Objective |
Area To Optimise |
Approx Cost Saving |
Techniques / CONSIDERATIONS |
|---|---|---|---|---|
| 1 | Implement a controller to scale in/out the ec2 instances (required to run the application) dynamically | Compute | ~10% of compute cost |
There is an additional cost incurred to maintain the job statistics, but the overall compute cost is reduced. **Note: For a single data domain, this optimization may look costly because of the additional cost explained above, but if the workload is huge, then it will be cost-beneficial. |
| 2 | Split the data processing jobs to run the data processing part with spot instances | Compute | ~60% of compute cost |
Spot instances can bring lots of savings, but splitting the jobs should not overflow the number of jobs. |
| 3 | Implement S3 and Cloud storage clean-up policy | Storage | ~50% of storage cost | After certain period of time (based on the business requirement) add data archival rule is cost beneficial for longer run of the application. |
Cost Optimization Techniques for Applications
Reference (Part 4 of this series): Cost optimization techniques for applications
Indicative figures and potential optimizations with impact and savings applying the techniques discussed related to application components optimization to the example workload are given below.
Optimisation objective |
Area To Optimise |
Approx Cost Saving |
TEChniques / Considerations |
|
|---|---|---|---|---|
| 1 | Implement EMR to do the data instead of using EC2 instances | Application | ~50% of compute cost |
EMR processes the data very fast with a higher configuration. So the uptime/running time of the cluster is lesser and hence, the cost is lesser than asg based compute infra. **Note: For the single customers, this optimization may look a bit costly because of the additional cost at the cluster level, but if the workload is high, then it will be cost-beneficial. |
| 2 | Review of Job slicing and Job scheduling | Application | ~40% of compute cost | Categorize jobs as T-shirt sizes - big, medium, and small and allocate compute accordingly. Introduce a parallel process by splitting the incoming file into smaller chunks and adjusting the job size and schedule to leverage the use of spot instances with optimal duration and availability. Use of spot instances in place of on-demand instances to lower overall cost. |
Cost Optimization Techniques for Data
Reference (Part 5 of this series): Cost optimization techniques for data
Indicative figures and potential optimizations with impact and savings applying the techniques discussed related to data components optimization to the example workload are given below.
# |
Optimisation objective |
Area To Optimise |
Approx Cost Saving |
TECHNIQUES / CONSIDERATIONS |
|---|---|---|---|---|
| 1 | Read from file storage instead of dynamodb | Data / Read API Calls |
~30% of data cost |
Make enrichment data available in files in S3 compared to DynamoDB. File storage does not need additional RCU(Read Capacity Unit) cost as compared to the Dynamodb. Hence, this is helpful to fetch multiple records from a data store at a time. |
| 2 | Use a single partition instead of two partitions to fetch the data | Data / Schema changes |
~80% of data cost | Implement filters to limit the fetch of data across a single partition only. |
| 3 | Optimize BigQuery slot usage and requirement | Data/query Optimization | 15% of data cost | Estimate the number of max slots needed for a given period. This can be estimated from existing functionality or other projects using similar functionality like GCP BigQuery. Based on past experience and the current requirement for the example cloud-native application, the goal should be to buy optimal slots for a longer period. Optimizing the queries, as well as reducing the columns, helps to reduce the number of slots consumed. |
Conclusion
In this final part of the series, we shared a worked-out example to illustrate the cost optimization techniques for the functional components and the related impact. The objective of this series is to articulate the value of shifting left FinOps earlier in the application solution design phase itself. I look forward to sharing the details on how to apply this methodology to non-functional components to reduce the cost of security, observability, and availability.
Opinions expressed by DZone contributors are their own.
Comments