Turbocharge Ab Initio ETL Pipelines: Simple Tweaks for Maximum Performance Boost
Best practices and design considerations for Ab Initio graphs, along with performance enhancement tips and code snippet(s).
Join the DZone community and get the full member experience.
Join For FreeAb Initio is a powerful data integration and processing platform that enables the design and development of data integration applications. The software consists of two core components:
- GDE — Graphical Development Environment: The Graphical Development Environment (GDE) is the primary development tool in Ab Initio. It provides a graphical interface for designing, developing, and managing data integration applications, referred to as graphs. The GDE allows developers to construct graphs by connecting various components together, providing a visual representation of the data flow.
- Co>Operating System: The Co>Operating System (Co>Op) is a critical component of Ab Initio's data integration platform. It serves as the underlying operating system that facilitates the execution of Ab Initio graphs and manages the necessary resources for data processing. Designed for distributed computing environments, the Co>Op enables parallel execution of Ab Initio applications.
While Ab Initio offers impressive performance by default, there are several performance tweaks that can significantly enhance the data processing applications. Performance tuning in Ab Initio is crucial to optimize the execution of your applications and ensure efficient data processing. By implementing these tweaks, you can further boost performance and improve overall efficiency.
Tweak #1: Reduce/Remove Unwanted Fields/Records As-Early-As in the Graph
When reading data from a source system, select only the necessary fields that are required for downstream processing. Avoid reading unnecessary columns or data that won't be used in subsequent transformations. This reduces the amount of data transferred and processed throughout the graph. Use the Reformat/Join component to select only required fields and use the Filter by Expression component to select records based on filter conditions so that one can eliminate unwanted records at the early stage of processing. Use Dedup sorted or Rollup components to eliminate duplicate records in case source data has redundant data.
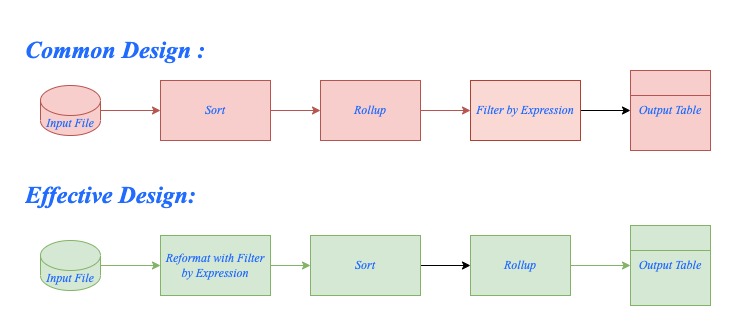
Tweak#2: Try To Reduce Components That Breaks Pipeline Parallelism
Ab Initio is designed to harness parallelism in three distinct ways: pipeline parallelism, data parallelism, and component parallelism. However, the use of certain components, such as Sort, can disrupt pipeline parallelism. Sort components require the entire record set to be available before producing output, causing downstream components to wait for the completion of the Sort component. To optimize performance, it is advisable to minimize the use of such components and consider utilizing in-memory options whenever feasible instead of relying on the Sort component.
Furthermore, even when using Sort components, the order or placement of these components within the graph significantly impacts performance. In Fig-1, the first design sorts the data first and then filters or removes extra fields. However, in the Correct Design, the unwanted fields or records are removed before sorting, resulting in enhanced graph performance.
Tweak#3: Use In-Memory Transformation if Feasible Rather Than Sort Followed by Transformations
There is a common misconception that suggests using Sort before performing roll-up, scan, or join operations when dealing with a large volume of data, such as 10-50 billion records. However, this belief is incorrect. Even if the data volume is substantial, such as 50 billion records, if the distinct key value is finite and can be held in memory, it is more efficient to use in-memory operations rather than resorting to sorting followed by roll-up, scan, or join operations, refer Fig-2 below.
Use Case
For instance, consider a scenario where a file contains 5 billion sales transaction records from 50 different states in the US, and the objective is to calculate the total sales on a state-by-state basis.
record
string(“,”) state_code;
decimal(“,”) sale_amount;
date(“\n”) sale_date;
end;
type temporary_type = record
decimal(“,”) sale_total;
end ;
typetype temporary_type = record
decimal(“,”) sale_total;
end ;
temp:: rollup(temp,in) =
begin
temp.sale_total :: in.sale_amount + temp.sale_total ;
end ;
out:: finalize (temp,in) =
begin
out.state_code :: in.state_code;
out.sale_amount :: temp.sale_total ;
end ;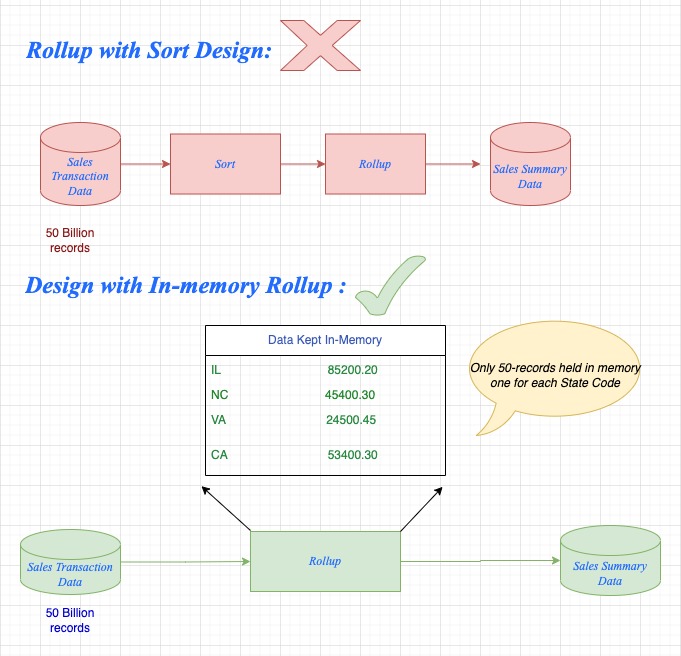
Tweak#4: Use Multi-File-System and Layout Wherever Possible
Ab Initio's main strength is its parallel processing using a multi-file system, going parallel as soon as possible in processing. If aggregation is not happening based on any specific keys, use a round-robin partition and run further processing multiple file layouts.
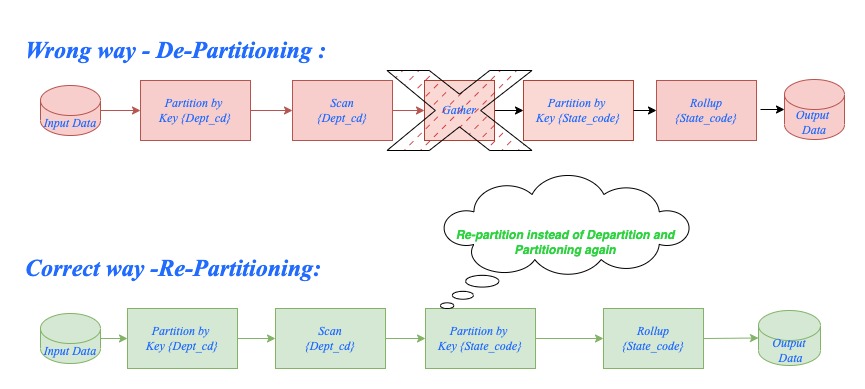
Try to run in multi-file layout/parallel layout, in case it is necessary to change the partition keys, then go for re-partition rather than de-partition and then do partitioning again as in Fig:3
Data skew is an important factor to consider when you implement data parallelism. Choosing the wrong key may result in data skew, which may overuse certain partitions/nodes and underutilize remaining nodes resulting in performance degradation; hence it is very critical to choose appropriate keys while partitioning data.
Tweak#5: Reduce Read/Write to Disk I/O
Disk I/O is always a costly operation; hence, try to avoid landing files on disk and reading them again for further processing unless it is absolutely necessary. Instead, use Ab Initio Phasing and checkpointing mechanisms so that we can reuse them later in the graph if there is a dependency on some other flow within the same graph.
Effective usage of buffers can significantly improve graph performance. Use appropriate buffer sizes or set the max-core value for data flows to minimize data spillage to disk, thus reducing disk I/O and network latency. Buffer data at critical points in the flow to reduce the number of disk reads and writes.
To compress data in a graph, use the Deflate component and use INFLATE to decompress data. Although this adds some overhead to the compression/decompression operation, it reduces the number of bytes transferred during I/O and over the network.
Tweak#6: Avoid Parameters That Invoke Shell
Always try to use Ab Initio functions (in-built/Parameter Definition Language) instead of using shell commands or other third-party programs. This is because using external programs written in third-party languages hinders Ab Initio's built-in performance optimization mechanism, as it cannot optimize those programs.
Tweak#7: Choose the Correct Lookup Type Based on the Use Case
A simple (serial) lookup is appropriate if the data is less than 1 GB, as it can be easily kept in memory. However, if the graph is running in parallel, using a simple serial lookup will result in copying the lookup data to each partition. This leads to 8X or 16X data in memory, depending on the multi-file layout of the environment. In such cases, if it is suitable, use a multi-file lookup instead of a serial lookup file.
If a lookup file is used in a generic graph that runs multiple times, consider using a lookup with an index. This reduces the need to build the index each time, thereby improving the graph's performance
If lookup data is going to grow very large, then it is better to use ICFF (Index Compressed Flat files). It consists of two files:
A data file — This file contains records that are first compressed and indexed as blocks and are then organized into generations.
An index file — The index is loaded into memory and searched for matching records. The lookup data file remains on disk while selected blocks are retrieved and uncompressed as they are needed. This enables ICFF to grow very large — much larger than available physical memory.
Tweak#8: Use Component Folding and Micro Graphs
Component folding is a powerful feature that can significantly enhance performance by reducing the number of processes created by graphs. When enabled, it combines multiple graph components into a single group during runtime. Each partition within this group runs as a unified process, effectively conserving memory and streamlining execution.
The Run Micrograph component provides the capability to consolidate processes associated with independent service graphs or subgraphs into a single long-running child process. Compared to batch graphs, micrographs greatly reduce graph startup and shutdown times. When compared to continuous graphs, micrographs effectively manage the number of processes and the memory consumption of service-oriented applications.
Conclusion
In this article, we have explored several design considerations and performance tweaks for Ab Initio. By implementing these optimizations, the application's performance experiences exponential improvement. Not only do these optimizations enhance performance, but they also effectively reduce resource requirements, including memory and CPU usage. As a result, the overall Ab Initio environment operates more efficiently, delivering significant benefits.
Opinions expressed by DZone contributors are their own.
Comments