A Quick Guide to Microservices With the Micronaut Framework
If you love Java and microservices, read on to learn how to use the Micronaut framework and why it's becoming a great alternative to Spring Boot.
Join the DZone community and get the full member experience.
Join For FreeThe Micronaut framework was introduced as an alternative to Spring Boot for building microservice applications. At first glance, it is very similar to Spring. It also implements patterns like dependency injection and inversion of control based on annotations, however, it uses JSR-330 (java.inject) to do it. It has been designed specifically for building serverless functions, Android applications, and low memory-footprint microservices. This means that it should have a faster startup time, lower memory usage, and be easier to unit test than competing frameworks. However, today I don't want to focus on those characteristics of Micronaut. I'm going to show you how to build a simple microservices-based system using this framework. You can easily compare it with Spring Boot and Spring Cloud by reading my previous article about the same subject Quick Guide to Microservices with Spring Boot 2.0, Eureka and Spring Cloud. Does Micronaut have a chance to gain the same popularity as Spring Boot? Let's find out.
Our sample system consists of three independent microservices that communicate with each other. All of them integrate with Consul in order to fetch shared configurations. After startup, every single service will register itself in Consul. The applications organization-service and department-service call endpoints exposed by other microservices using the Micronaut declarative HTTP client. The traces from communication are sent to Zipkin. The source code of the sample applications is available on GitHub in the sample-micronaut-microservices repository.

Step 1. Creating an Application
We need to start by including some dependencies to our Maven pom.xmlfile. First, let's define BOM with the newest stable Micronaut version.
<properties>
<exec.mainClass>pl.piomin.services.employee.EmployeeApplication</exec.mainClass>
<micronaut.version>1.0.3</micronaut.version>
<jdk.version>1.8</jdk.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-bom</artifactId>
<version>${micronaut.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>The list of required dependencies isn't very long. Also, not all of them are required, but they will be useful in our demo. For example, micronaut-management needs to be included in case we want to expose some built-in management and monitoring endpoints.
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-http-server-netty</artifactId>
</dependency>
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-inject</artifactId>
</dependency>
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-runtime</artifactId>
</dependency>
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-management</artifactId>
</dependency>
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-inject-java</artifactId>
<scope>provided</scope>
</dependency>To build the application's uber-jar we need the configure plugin responsible for packaging the JAR file with dependencies. For example, maven-shade-plugin. When building a new application, it is also worth exposing basic information about it under the /info endpoint. As I have already mentioned, Micronaut adds support for monitoring your app via HTTP endpoints after including the micronaut-managementartifact. The management endpoints are integrated with the Micronaut security module, which means that you need to authenticate yourself to be able to access them. To simplify, we can disable authentication for the /info endpoint.
endpoints:
info:
enabled: true
sensitive: falseWe can customize the/info endpoint by adding some supported information sources. This mechanism is very similar to the Spring Boot Actuator approach. If the git.properties file is available on the classpath, all the values inside file will be exposed by the /info endpoint. The same situation applies to thebuild-info.properties file that needs to be placed inside the META-INF directory. However, in comparison with Spring Boot, we need to provide more configuration in thepom.xml file to generate and package those to the application's JAR. The following Maven plugins are responsible for generating the required property files.
<plugin>
<groupId>pl.project13.maven</groupId>
<artifactId>git-commit-id-plugin</artifactId>
<version>2.2.6</version>
<executions>
<execution>
<id>get-the-git-infos</id>
<goals>
<goal>revision</goal>
</goals>
</execution>
</executions>
<configuration>
<verbose>true</verbose>
<dotGitDirectory>${project.basedir}/.git</dotGitDirectory>
<dateFormat>MM-dd-yyyy '@' HH:mm:ss Z</dateFormat>
<generateGitPropertiesFile>true</generateGitPropertiesFile>
<generateGitPropertiesFilename>src/main/resources/git.properties</generateGitPropertiesFilename>
<failOnNoGitDirectory>true</failOnNoGitDirectory>
</configuration>
</plugin>
<plugin>
<groupId>com.rodiontsev.maven.plugins</groupId>
<artifactId>build-info-maven-plugin</artifactId>
<version>1.2</version>
<configuration>
<filename>classes/META-INF/build-info.properties</filename>
<projectProperties>
<projectProperty>project.groupId</projectProperty>
<projectProperty>project.artifactId</projectProperty>
<projectProperty>project.version</projectProperty>
</projectProperties>
</configuration>
<executions>
<execution>
<phase>prepare-package</phase>
<goals>
<goal>extract</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>Now, our /info endpoint is able to print the most important information about our app, including the Maven artifact name, version, and the last Git commit id.

Step 2. Exposing HTTP Endpoints
Micronaut provides their own annotations for pointing out HTTP endpoints and methods. As I mentioned in the preface, this also us to use JSR-330 ( java.inject) for dependency injection. Our controller class should be annotated with @Controller. We also have annotations for every HTTP method type. The path parameter is automatically mapped to the class method parameter by its name, what is a nice simplification in comparison to Spring MVC where we need to use the @PathVariable annotation. The repository bean used for CRUD operations is injected into the controller using the@Inject annotation.
@Controller("/employees")
public class EmployeeController {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeController.class);
@Inject
EmployeeRepository repository;
@Post
public Employee add(@Body Employee employee) {
LOGGER.info("Employee add: {}", employee);
return repository.add(employee);
}
@Get("/{id}")
public Employee findById(Long id) {
LOGGER.info("Employee find: id={}", id);
return repository.findById(id);
}
@Get
public List<Employee> findAll() {
LOGGER.info("Employees find");
return repository.findAll();
}
@Get("/department/{departmentId}")
@ContinueSpan
public List<Employee> findByDepartment(@SpanTag("departmentId") Long departmentId) {
LOGGER.info("Employees find: departmentId={}", departmentId);
return repository.findByDepartment(departmentId);
}
@Get("/organization/{organizationId}")
@ContinueSpan
public List<Employee> findByOrganization(@SpanTag("organizationId") Long organizationId) {
LOGGER.info("Employees find: organizationId={}", organizationId);
return repository.findByOrganization(organizationId);
}
}Our repository bean is pretty simple. It just provides an in-memory store for Employee instances. We will mark it with the @Singleton annotation.
@Singleton
public class EmployeeRepository {
private List<Employee> employees = new ArrayList<>();
public Employee add(Employee employee) {
employee.setId((long) (employees.size()+1));
employees.add(employee);
return employee;
}
public Employee findById(Long id) {
Optional<Employee> employee = employees.stream().filter(a -> a.getId().equals(id)).findFirst();
if (employee.isPresent())
return employee.get();
else
return null;
}
public List<Employee> findAll() {
return employees;
}
public List<Employee> findByDepartment(Long departmentId) {
return employees.stream().filter(a -> a.getDepartmentId().equals(departmentId)).collect(Collectors.toList());
}
public List<Employee> findByOrganization(Long organizationId) {
return employees.stream().filter(a -> a.getOrganizationId().equals(organizationId)).collect(Collectors.toList());
}
}Micronaut is able to automatically generate Swagger YAML definitions from our controller and methods based on these annotations. To achieve this, we first need to include the following dependency to our pom.xmlfile.
<dependency>
<groupId>io.swagger.core.v3</groupId>
<artifactId>swagger-annotations</artifactId>
</dependency>Then we should annotate the application's main class with @OpenAPIDefinition and provide some basic information like the title or version number. Here's the employee application's main class.
@OpenAPIDefinition(
info = @Info(
title = "Employees Management",
version = "1.0",
description = "Employee API",
contact = @Contact(url = "https://piotrminkowski.wordpress.com", name = "Piotr Mińkowski", email = "piotr.minkowski@gmail.com")
)
)
public class EmployeeApplication {
public static void main(String[] args) {
Micronaut.run(EmployeeApplication.class);
}
}Micronaut generatesa Swagger file based on thetitle and version fields inside the@Info annotation. In that case, our YAML definition file is available under the name employees-management-1.0.yml, and will be generated to the META-INF/swagger directory. We can expose it outside the application using an HTTP endpoint. Here's the appropriate configuration provided inside theapplication.yml file.
micronaut:
router:
static-resources:
swagger:
paths: classpath:META-INF/swagger
mapping: /swagger/**Now, our file is available under the path http://localhost:8080/swagger/employees-management-1.0.yml if we run it on the default 8080 port (we won't do that, and I'll explain why in the next part of this article). In comparison to Spring Boot, we don't have projects like Swagger SpringFox for Micronaut, so we need to copy the content to an online editor in order to see the graphical representation of our Swagger YAML. Here it is:
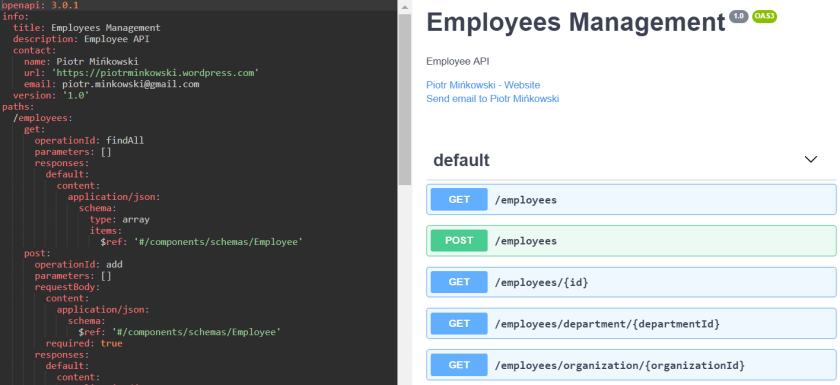
Since we have finished the implementation of a single microservice we may proceed to the cloud-native features provided by Micronaut.
Step 3. Distributed Configuration
Micronaut comes with built-in APIs for doing distributed configuration. In fact, the only available solution, for now, is a distributed configuration based on HashiCorp's Consul. Micronaut features for externalizing and adapting configuration to the environment are very similar to the Spring Boot approach. We also have application.yml and bootstrap.yml files, which can be used for application environment configuration. When using a distributed configuration, we first need to provide a bootstrap.yml file on the classpath. It should contain an address for the remote configuration server and a preferred configuration store format. Of course, we first need to enable a distributed configuration client by setting the micronaut.config-client.enabled property to true. Here's the bootstrap.yml file for department-service.
micronaut:
application:
name: department-service
config-client:
enabled: true
consul:
client:
defaultZone: "192.168.99.100:8500"
config:
format: YAMLWe can choose between properties, JSON, YAML, and FILES (git2consul) configuration formats. I decided to use YAML. To apply this configuration on Consul, we first need to start it locally in development mode. Because I'm using Docker Toolbox, the default address of Consul is 192.168.99.100. The following Docker command will start single-node Consul instance and expose it on port 8500.
$ docker run -d --name consul -p 8500:8500 consulNow, you can navigate to the tab Key/Value in Consul's web console and create a new file in YAML format,/config/application.yml, as shown below. Besides the configuration for Swagger and /info management endpoints, it also enables dynamic HTTP generation on startup by setting themicronaut.server.port property to -1. Because the name of the file is application.yml it is, by default, shared between all the microservices that use the Consul config client.

Step 4. Service Discovery
Micronaut gives you more options when configuring service discovery than it does for working with distributed configurations. You can use Eureka, Consul, Kubernetes, or just manually configure a list of available services. However, I have observed that using the Eureka discovery client together with the Consul config client causes some errors on startup. In this example, we will use Consul discovery. Because the Consul address has already been provided in bootstrap.yml for every microservice, we just need to enable service discovery by adding the following lines to application.yml stored in Consul KV.
consul:
client:
registration:
enabled: trueWe should also include the following dependency to Maven pom.xml of every single application.
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-discovery-client</artifactId>
</dependency>Finally, you can just run every microservice (you may run more than one instance locally, since the HTTP port is generated dynamically). Here's my list of running services registered in Consul.
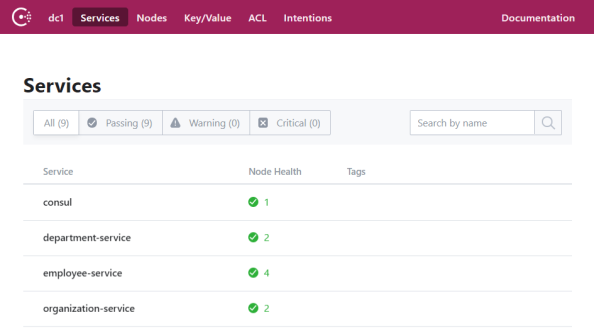
I have run two instances of employee-service, as shown below.

Step 5. Interservice Communication
Micronaut uses a built-in HTTP client for load balancing between multiple instances of a single microservice. By default, it leverages the Round Robin algorithm. We may choose between a low-level HTTP client and a declarative HTTP client with @Client. Micronaut's declarative HTTP client concept is very similar to Spring Cloud's OpenFeign. To use built-in client we first need to include the following dependency to the pom.xml portion of the project:
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-http-client</artifactId>
</dependency>The declarative client automatically integrates with a discovery client. It tries to find the service registered in Consul under the same name, as the value provided inside the id field.
@Client(id = "employee-service", path = "/employees")
public interface EmployeeClient {
@Get("/department/{departmentId}")
List<Employee> findByDepartment(Long departmentId);
}Now, the client bean needs to be injected into the controller.
@Controller("/departments")
public class DepartmentController {
private static final Logger LOGGER = LoggerFactory.getLogger(DepartmentController.class);
@Inject
DepartmentRepository repository;
@Inject
EmployeeClient employeeClient;
@Post
public Department add(@Body Department department) {
LOGGER.info("Department add: {}", department);
return repository.add(department);
}
@Get("/{id}")
public Department findById(Long id) {
LOGGER.info("Department find: id={}", id);
return repository.findById(id);
}
@Get
public List<Department> findAll() {
LOGGER.info("Department find");
return repository.findAll();
}
@Get("/organization/{organizationId}")
@ContinueSpan
public List<Department> findByOrganization(@SpanTag("organizationId") Long organizationId) {
LOGGER.info("Department find: organizationId={}", organizationId);
return repository.findByOrganization(organizationId);
}
@Get("/organization/{organizationId}/with-employees")
@ContinueSpan
public List<Department> findByOrganizationWithEmployees(@SpanTag("organizationId") Long organizationId) {
LOGGER.info("Department find: organizationId={}", organizationId);
List<Department> departments = repository.findByOrganization(organizationId);
departments.forEach(d -> d.setEmployees(employeeClient.findByDepartment(d.getId())));
return departments;
}
}Step 6. Distributed Tracing
Micronaut applications can be easily integrated with Zipkin to send traces with HTTP traffic automatically. To enable this feature, we first need to include the following dependencies to pom.xml.
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-tracing</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-http</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.opentracing.brave</groupId>
<artifactId>brave-opentracing</artifactId>
</dependency>Then, we have to provide some configuration settings inside application.yml, including Zipkin URL and sampler options. By setting the tracing.zipkin.sampler.probability property to 1, we are forcing micronaut to send traces for every single request. Here's our final configuration.

During the tests of my application, I have observed that using distributed configurations together with Zipkin tracing results in problems in communication between microservices and Zipkin. The traces just do not appear in Zipkin. So, if you would like to test this feature, you must provide the application.yml file in the classpath and disable Consul's distributed configuration for all your applications.
We can add some tags to the spans by using the @ContinueSpan or @NewSpan annotations on methods.
After making some test calls to GET methods exposed by organization-service and department-service, we may take a look on Zipkin web console, available under the address http://192.168.99.100:9411. The following picture shows the list of all the traces sent to Zipkin by our microservices in one hour.
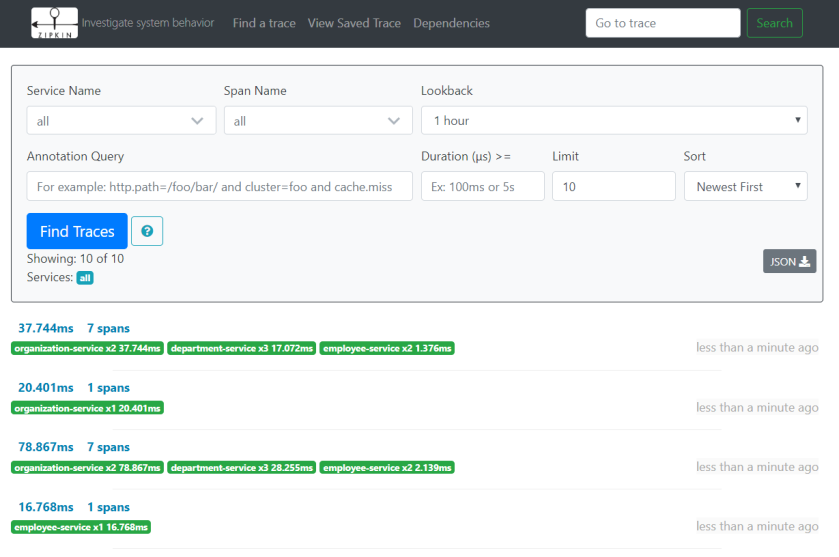
We can check out the details of every trace by clicking on the element from the list. The following picture illustrates the timeline for HTTP method exposed by organization-serviceGET /organizations/{id}/with-departments-and-employees. This method finds the organization in the in-memory repository, and then calls the HTTP method exposed by department-serviceGET /departments/organization/{organizationId}/with-employees. This method is responsible for finding all departments assigned to the given organization. It also needs to return employees within the department, so it calls the GET /employees/department/{departmentId} method from employee-service.

We can also take a look on the details of every single call from the timeline.

Conclusion
In comparison to Spring Boot, Micronaut is still in the early stages of development. For example, I was not able to implement any applications that could act as an API gateway to our system, which can easily be achieved with Spring using Spring Cloud Gateway or Spring Cloud Netflix Zuul. There are still some bugs that needs to be fixed. But above all that, Micronaut is now probably the most interesting micro-framework on the market. It implements the most popular microservice patterns, provides integration with several third-party solutions like Consul, Eureka, Zipkin, or Swagger, consumes less memory and starts faster than similar Spring Boot apps. I will definitely follow the progress in Micronaut development closely.
Published at DZone with permission of Piotr Mińkowski, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments