A New Approach to Solve I/O Challenges in the Machine Learning Pipeline
This blog in our machine learning series compares the traditional solutions with Alluxio's in solving I/O challenges in the machine learning pipeline.
Join the DZone community and get the full member experience.
Join For FreeBackground
The drive for training accuracy leads companies to develop complicated training algorithms and collect a large amount of training data with which single-machine training takes an intolerable long time. Distributed training seems promising in meeting the training speed requirements but faces the challenges of data accessibility, performance, and storage system stability in dealing with I/O in the machine learning pipeline.
Solutions
The above challenges can be addressed in different ways. Traditionally, two solutions are commonly used to help resolve data access challenges in distributed training. Beyond that, Alluxio provides a different approach.
Solution 1: Duplicating Data in Local Storage (S3 CLI)
This first traditional approach replicates the entire dataset from the remote storage to the local storage of each server for training. The copy process is easy with tools available online. This approach yields the highest I/O throughput as all data is local, maximizing the chance to keep all GPUs busy.
However, it requires that the full dataset size fits local storage capacity. When the size of the input dataset grows, the data copy process becomes long and error-prone, taking a non-trivial amount of time while leaving the expensive GPU resources idle.
Solution 2: Direct Accessing Remote Storage (S3 FUSE)
The second traditional solution is to skip data copying but connect the training with the target dataset on remote storage directly. Compared with the previous solution, this approach overcomes the constraints of dataset size.
However, it faces a new set of challenges. The I/O throughput is bounded by the network. In addition, all the training nodes need to access the same dataset from the same remote storage concurrently, creating a huge pressure on the storage system when the training scale is large. When the network is slow or the storage is congested due to highly concurrent access, GPU utilization becomes low. Besides, training scripts need to be modified to be strongly coupled with the target remote storage. Changing storage can be a headache.
To overcome the disadvantages of this approach, storage FUSE applications with local cache are developed. First data access will go throughput the network and is served by the remote storage directly. The following data access throughput at the same FUSE mount point will be served by metadata and data caching locally to improve warm read performance and reduce storage system pressure. With the benefits provided by FUSE, training scripts can access remote storage like the local directory without the need to modify training scripts.
This approach suits the workloads that training nodes or multiple training tasks do not need to share the same dataset since the storage FUSE application provides a single node caching solution. In addition, it suits the training that is relatively quick and simple without the need for advanced data management tools like data preloading and data pining.
Solution 3: Alluxio’s Solution
Alluxio is an open-source data orchestration platform for analytics and machine learning applications. Alluxio not only provides a distributed caching layer between training jobs and underlying storage but also is responsible for connecting to the under storage, fetching data proactively or on-demand, caching data based on user-specified policy, and feeding data to the training frameworks.
Alluxio enables training connecting to remote storages via FUSE API and provides caching ability similar to storage FUSE applications. On top of that, Alluxio provides distributed caching for tasks or nodes to share cached data. Advanced data management policies like distributed data preloading, data pining can further improve data access performance.
Alluxio provides the following benefits for the training pipeline:
- Metadata caching to provide low latency metadata performance.
- Distributed data caching to achieve higher data throughput and performance.
- Transparent cache management to evict old data and cache new data automatically.
- Support multiple APIs and frameworks, suitable for using big data frameworks (Presto/Spark) to preprocess data for training.
- Advanced data management to preload, pin, sync, and remove data based on user needs.
Solution Comparison
This subsection compares Alluxio with S3 CLI (duplicating data in local storage) and s3fs-fuse (direct accessing remote storage), which are the two alternative solutions to get data ready for your cloud distributed training in terms of functionality and performance.
Functionality Comparison
The following table compares S3 CLI, S3 FUSE, and Alluxio:
| S3 CLI | S3 FUSE (s3fs-fuse) | Alluxio | |
| Access to remote data | ✓ | ✓ | ✓ |
| Cache data locally | ✓ | ✓ | ✓ |
| No limitation on data size | ✓ | ✓ | |
| No need to copy the full dataset before training | ✓ | ✓ | |
| Assures data consistency | ✓ | ✓ | |
| Support distributed caching | ✓ | ||
| Support advanced data management | ✓ |
S3 CLI vs Alluxio
S3 CLI works for reading smaller datasets when each machine can host the full dataset and the training dataset is isolated and certain, and when there is no disk management needed. However, Alluxio is advantages as it provides the following benefits comparatively:
- No limitation on data size: When your dataset is larger than single machine storage. Alluxio can cache the whole dataset throughout the whole cluster.
- Little preparation needed: Copying the full dataset from s3 to one instance is time-consuming and GPU idle time is unacceptable. Alluxio can use multiple worker nodes to cache the whole dataset distributedly and can cache the required working set only which may largely reduce the data loading time from S3 to the training cluster.
- Assures data consistency. When using S3 CLI, all data syncing needs to be done manually. Using Alluxio, data syncing is done automatically. Files added or deleted on the training cluster dataset will be eventually reflected in the underlying s3 bucket, and vice versa.
S3fs-fuse vs Alluxio
S3fs-fuse is similar to Alluxio in terms of caching ability. However, Alluxio is a distributed solution, thus overcoming the limitations bounded by single-node solutions like s3fs-fuse.
Comparatively, Alluxio is a better option when:
- Training data is large (>= 10TB), especially when training data includes a large number of small files/images
- Training nodes or multiple training tasks share the same dataset. As a distributed cache, all the data cached by Alluxio can be shared for training inside and outside the cluster. Whereas with S3fs-fuse, each node caches the working set used by itself and cannot be shared across nodes.
- Advanced data management is desired. On top of loading and caching data like S3fs-fuse, Alluxio also supports auto eviction, data preload, pin hot data, TTL, and other advanced data management tools.
Performance Comparison
The previous section compared the functionalities of the two popular solutions vs. Alluxio. This section provides the initial read performance analysis between three data access solutions. We focus on the first epoch performance which is more sensitive to data access approaches. Note that a more detailed benchmark to compare the actual performance of different S3 data access solutions under high concurrent and data-intensive training can be found here.
Solution 1: S3 CLI
![Solution 1: S3 CLI]()

Training needs to wait for data to be fully loaded from object storage to the training cluster. Training performance is likely to be the best under this approach since training scripts directly load data from local directories.
Solution 2: S3 FUSE (s3fs-fuse)

Using this approach, all the operations including listing and reading files need to go through the network between object storage and training cluster. If metadata latency is large and data throughput is low, GPU resources of the training cluster may not be fully utilized and are waiting for data to be ready for training.
Solution 3-1: Alluxio (Without Data Preloading)

Without preloading data, Alluxio is expected to have a similar performance as s3fs-fuse, all operations need to go through the network to obtain necessary metadata and data.
Solution 3-2: Alluxio (With data preloading)
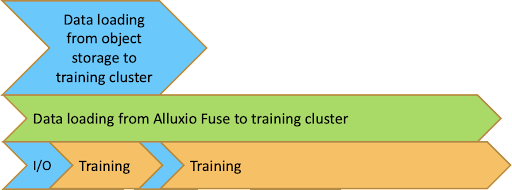
Alluxio can load data from object storage into the training cluster with one click using multiple threads in multiple nodes concurrently. Unlike S3 CLI, training can start before data is fully loaded into the cluster. In the beginning, there will be some I/O wait similar to s3fs-fuse and Alluxio without data preloading, but the I/O wait time will become shorter and shorter because data may be loaded into the Alluxio cache already.
By using this approach, data loading from object storage to training cluster, data caching, data loading from local Alluxio mount point into training, and training can be done parallelly and overlapped to largely speed up the full process.
Interested in Learning More?
In this blog, we’ve demonstrated the advantages of Alluxio’s solution over traditional ones. With the above comparison, we suggest adopting Alluxio when:
- You need distributed training
- You have a large amount of training data (>= 10 TB), especially when training data includes a large number of small files/images
- The Network I/O is not sufficient to keep your GPU resources busy
- Your pipeline involves multiple data sources and multiple training/compute frameworks
- You want to keep your underlying storage stable while being able to serve additional training requests.
- Multiple training nodes or tasks share the same dataset.
That's all for today! If you have any suggestions, feel free to leave a comment below.
Published at DZone with permission of Bin Fan, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments