98% GPU Utilization Achieved in 1K GPU-Scale AI Training Using Distributed Cache
In this article, learn how JuiceFS achieved over 98% GPU utilization in 1,000 GPU-scale AI training using distributed cache.
Join the DZone community and get the full member experience.
Join For FreeIn Sept 2023, MLPerf, the authoritative benchmark for AI performance, introduced its Storage Benchmark. This benchmark test allows for large-scale performance testing of storage systems in AI model training scenarios, simulating machine learning I/O workloads without the need for GPUs.
MLPerf supports two types of model training: BERT (natural language model) and UNet3D (3D medical image segmentation). Although it does not support large language models (LLMs) like GPT and LLaMA, BERT and LLMs share the multi-layer transformer structure. LLM users can still obtain valuable insights from the BERT training results.
Leading high-performance storage vendors such as DataDirect Networks (DDN), Nutanix, Weka, and Argonne National Laboratory (ANL) released MLPerf test results as industry references. We also conducted tests using JuiceFS Enterprise Edition, a high-performance distributed file system, to let users know its performance in model training.
The most intuitive metric in testing is GPU utilization. Over 90% indicates a passing grade, which demonstrates that the storage system can meet the performance requirements of training tasks. In tests with a 500-card scale for UNet3D, JuiceFS maintained GPU utilization of over 97%; for BERT at a 1,000-card scale, its GPU utilization remained above 98%.
Test Preparation
JuiceFS Enterprise Edition is a parallel file system based on object storage, offering stronger metadata engines and cache management capabilities compared to the Community Edition. The figure below shows its architecture: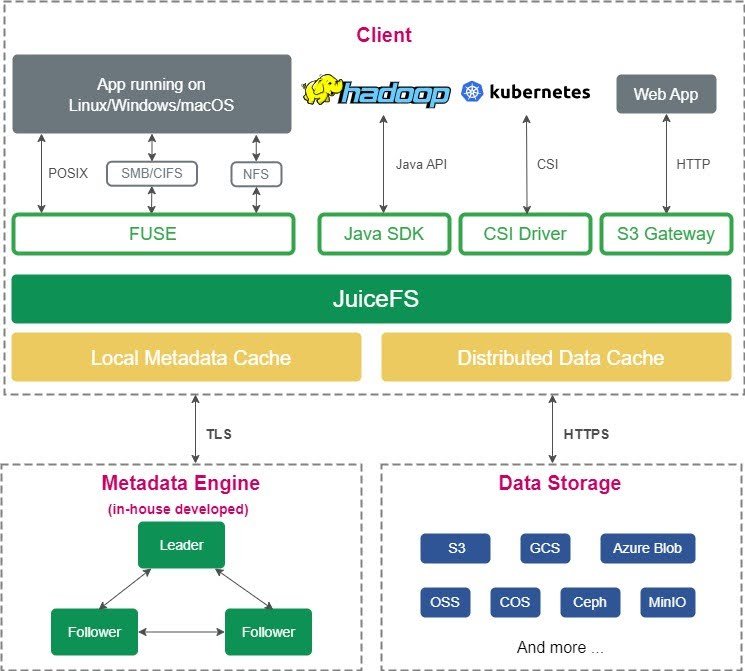
We deployed a JuiceFS Enterprise Edition file system on the cloud. We used object storage as the data persistent layer, with a metadata cluster of three nodes and a distributed cache cluster of multiple nodes. Hardware specifications included:
- Metadata nodes: 8vCPUs | 64 GiB
- Object storage: bandwidth limit 300 Gb/s
- Client nodes: 64vCPUs | 256 GiB | local SSD 2*1, 600 GiB | network bandwidth 25 Gbps (Ethernet)
After we set up the file system, we used mlperf scripts to generate datasets required for subsequent simulated training, with batch size and steps set to default. Currently, only NVIDIA v100 GPU simulation is supported, and all GPUs mentioned later in this post are simulated v100s.
BERT Model
When MLPerf generates datasets for the BERT model, each dataset file contains 313,532 samples, with each sample size at 2.5 KB. During training, each simulated v100 GPU can process 50 samples per second. This means that each GPU’s I/O throughput requirement is 125 KB/s. Most storage systems can easily meet the model training needs, including JuiceFS, which can support training needs at a 1,000-card scale.
In the figure below, we gathered MLPerf's public results, including those from ANL, DDN, and Weka, and added JuiceFS' results from our tests.
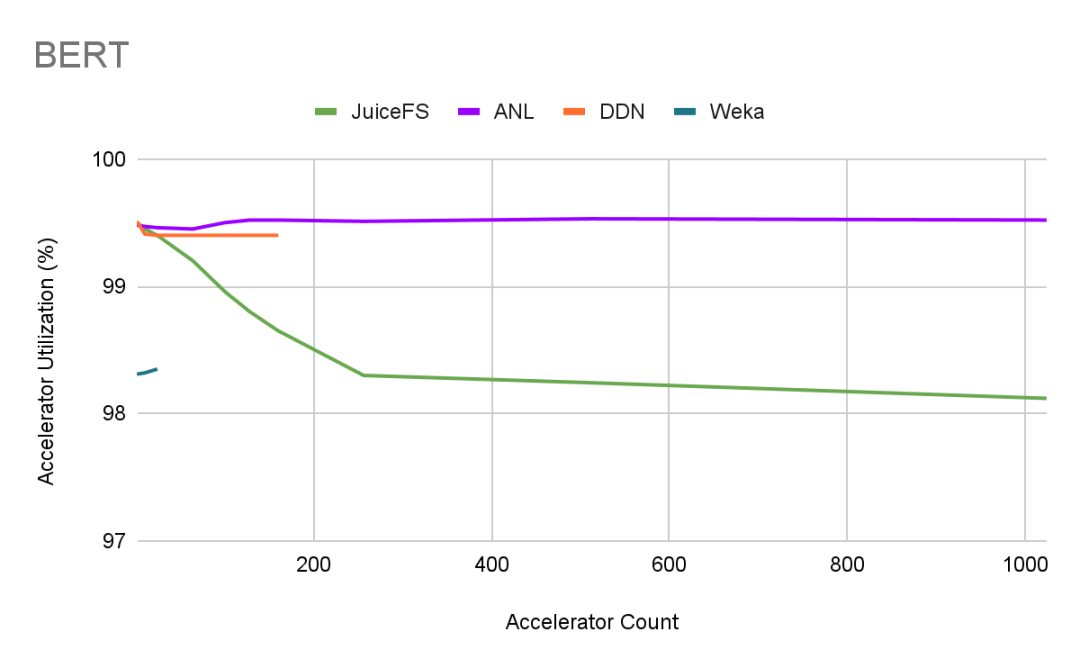
From the figure, we can see that:
- JuiceFS maintained GPU utilization above 98% at the 1,000 GPU scale.
- ANL's results were outstanding. Considering their high-bandwidth, low-latency Slingshot network conditions, achieving such results was expected.
UNet3D Model
UNet3D model training requires higher bandwidth than the BERT model.
Test With No Cache
Initially, we tested UNet3D model training without any cache, including distributed and local caches. In this setup, the JuiceFS client directly reads data from object storage.
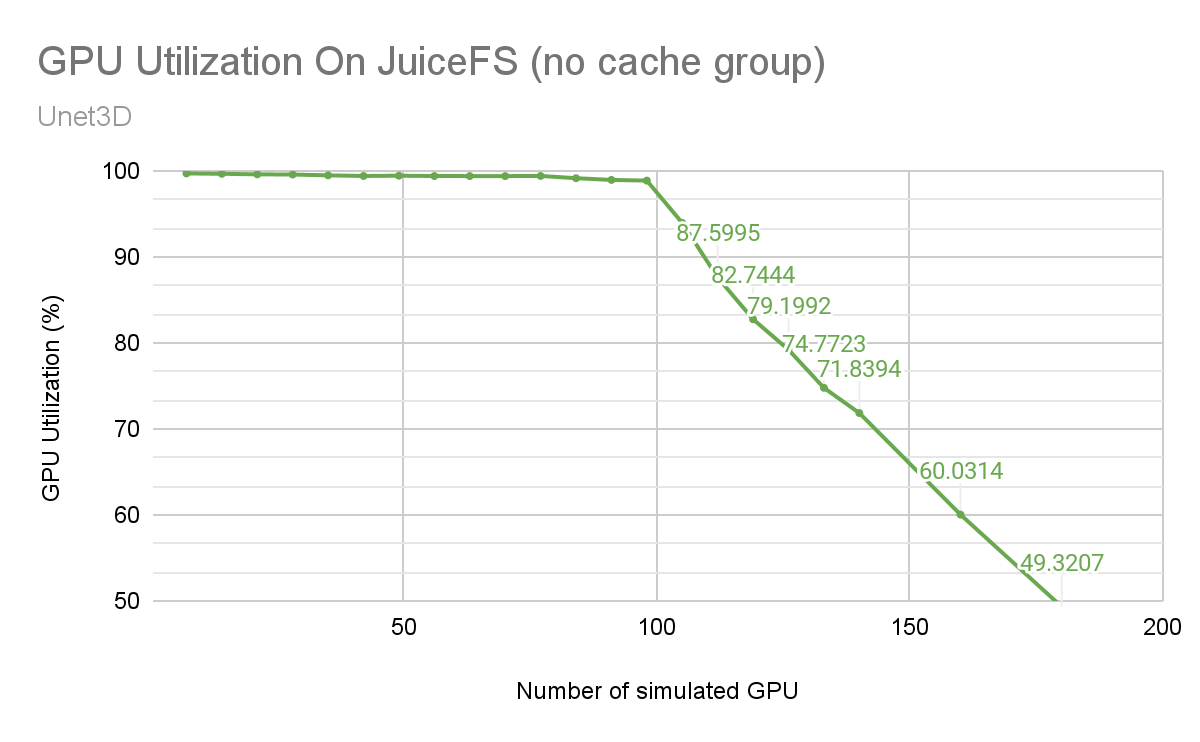
As shown below, GPU utilization (represented by the green line) slowly declined as the number of nodes increased. At 98 cards, there was a noticeable inflection point, followed by a sharp decrease in GPU utilization with an increase in nodes.
The following figure is based on OBS monitoring data and MLPerf results:
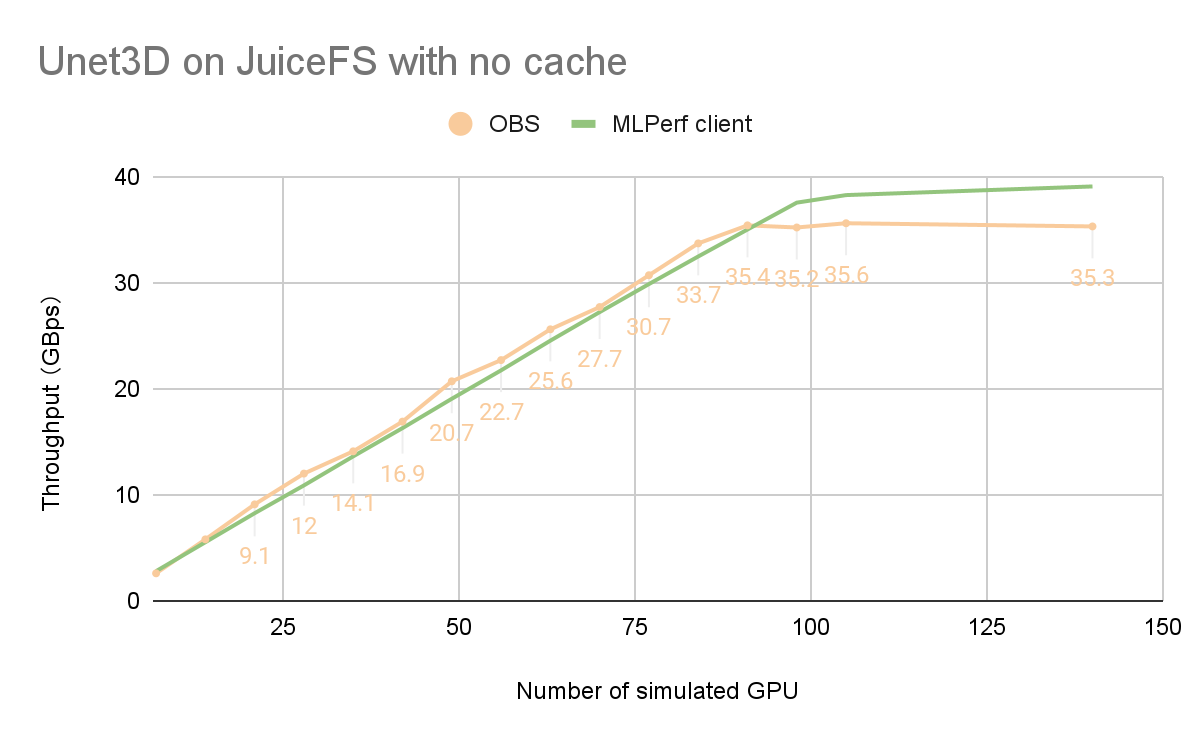
We can see that OBS bandwidth did not increase beyond 98 cards and larger-scale training, becoming a performance bottleneck.
Therefore, without cache, OBS' 300 Gb/s bandwidth was already fully loaded at 98 cards for simultaneous training. According to MLPerf's 90% pass-through standard, it could support training up to 110 cards simultaneously for UNet3D models.
When conducting multi-server multi-card training on large datasets, a standalone cache can only cache a small portion of the dataset due to space limitations. In addition, due to the randomness of data access during training, cache hit rates are low. Therefore, in this scenario, the contribution of a standalone cache to overall I/O performance is limited. As the green line in the figure above shows, the standalone kernel cache could improve the read bandwidth; although the kernel cache space was up to 200 GB, the improvement effect was limited. Thus, we did not conduct tests targeted for the standalone cache.
Test With Distributed Cache Enabled
JuiceFS’ Distributed Cache Architecture
Compared to the local cache, the distributed cache can provide larger cache capacities to support larger training sets and higher cache hit rates. This can enhance the read bandwidth of the entire JuiceFS cluster.
The figure below shows JuiceFS' distributed cache architecture:
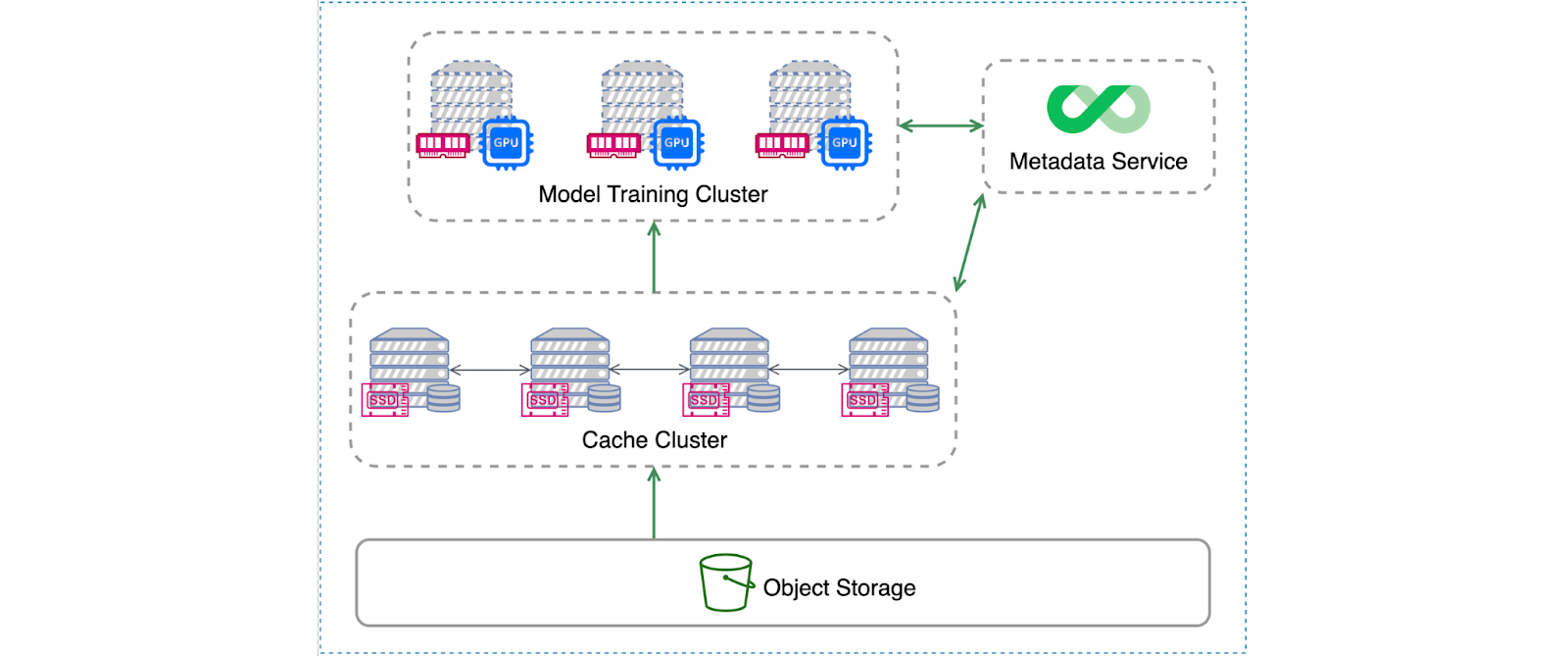
This architecture allows machine learning training clusters and cache clusters to be two independent sets of machines connected via a high-speed network. Both clusters mount JuiceFS clients. The training task accesses data through JuiceFS at the local mount point. When the local mount point needs data, it first requests data from the cache cluster. If the cache cluster does not have the required data, the system retrieves the data from object storage and updates it to the cache. If GPU nodes in the training cluster are equipped with sufficient SSD storage, they can be used directly as JuiceFS cache disks, forming a cache cluster without the need for a separate cache cluster.
This configuration effectively merges the functionalities of the training and cache clusters. In this test, we adopted this mixed deployment method.
Distributed Cache and Its Impact on GPU Utilization
Previous tests showed that without cache, GPU utilization was below 90% at 110 cards. To visually demonstrate the impact of distributed cache on performance, we conducted further tests on JuiceFS. We chose a cluster with 180 GPUs for testing to evaluate the relationship between cache hit rate and GPU utilization.
In the figure below, the horizontal axis represents the ratio of cache space to dataset size, while the vertical axis represents cache hit rate and GPU utilization.
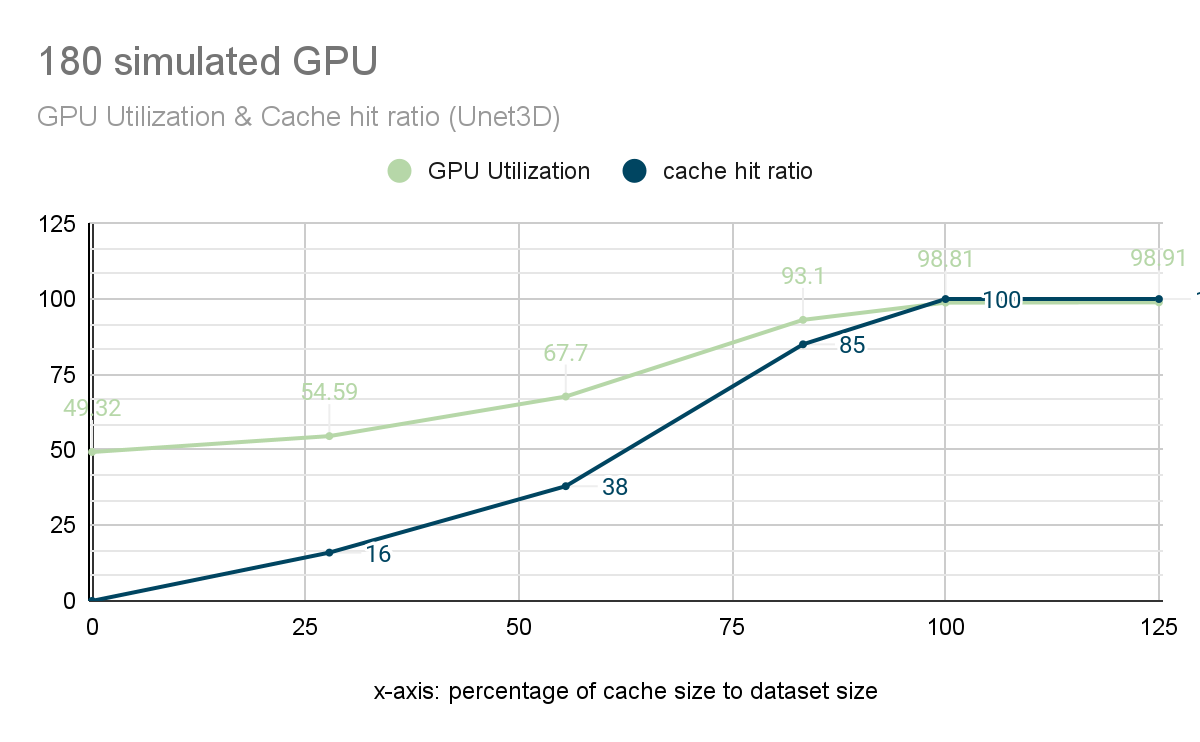
The figure shows that:
- When there was no cache, GPU utilization was only 49%.
- As the cache space ratio increased, cache hit rates (blue line) gradually rose, subsequently driving up GPU utilization (green line).
- When the cache hit rate reached 85%, GPU utilization reached 93.1%, satisfying the needs of training with 180 cards.
- When the cache hit rate reached 100%, GPU utilization reached a peak of 98.8%, almost fully loaded.
To verify the scalability of JuiceFS' cache system, we adjusted the capacity of the cache cluster according to the size of the dataset, ensuring a cache hit rate of 100%. In this way, all data required for training can be directly read from the cache without the need to read from slower object storage. In this configuration, we tested up to approximately 500 card-scale training tasks. As the test scale increased, the changes in GPU utilization were shown in the following figure:
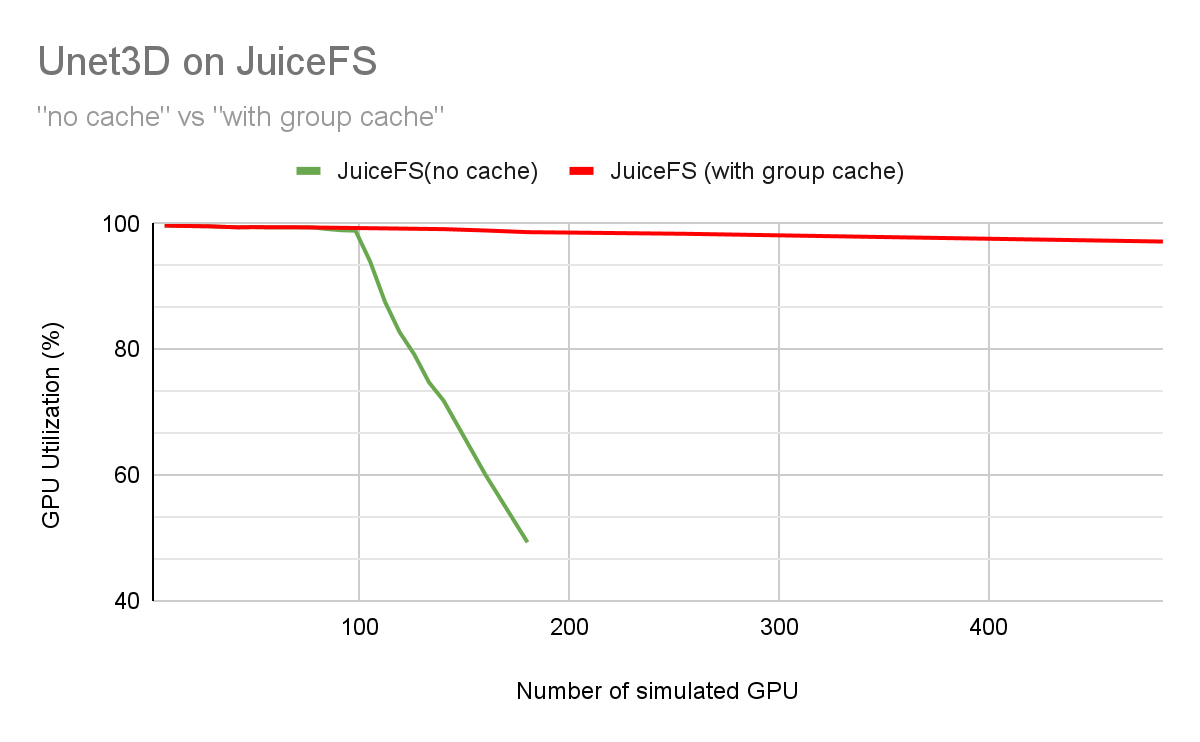
The largest total number of simulated GPUs in the data published by DDN and Weka was less than 200.
ANL maintained no significant degradation at the 512-card scale, achieving a GPU utilization of 99.5%. ANL's read/write bandwidth was 650 GBps, theoretically supporting up to 1,500 card training for UNet3D. Its outstanding performance was closely related to sufficient hardware configuration. For details, see ANL's article.
JuiceFS' GPU utilization slowly declined linearly as the cluster size became larger, maintaining over 97% utilization at a 500-card scale. JuiceFS performance bottleneck mainly came from the network bandwidth of cache nodes. With limited cache node models and network bandwidth, the maximum scale reached in this test was 483 cards. At this scale, the JuiceFS cluster's aggregate bandwidth was 1.7 Tb, while the ANL cluster's bandwidth was 5.2 Tb.
Conclusion
Our test results include the following highlights:
- In BERT testing, JuiceFS maintained over 98% GPU utilization in 1,000 GPU-scale training.
- In UNet3D testing, as the cluster scale increased, JuiceFS maintained over 97% GPU utilization in training approaching 500 GPUs. If cloud service providers can provide higher network bandwidth or more servers, this scale can be further increased.
- The distributed cache’s advantage is its strong scalability. It can use SSD storage on more nodes to aggregate a larger cache space to improve the overall storage system's read bandwidth. Of course, it also introduces some CPU overhead, but in AI training scenarios, using idle CPU resources to improve system bandwidth is valuable, even necessary.
- During machine learning training in the cloud, high-performance GPU models typically have high-performance SSDs and high-bandwidth network cards, which can also serve as distributed cache nodes. Therefore, compared to dedicated high-performance storage products, using JuiceFS is more cost-effective and easier to scale.
Large-scale AI training scenarios usually require dedicated high-performance storage or a parallel file system based on all-flash architecture and kernel mode to meet performance requirements. However, as the computing load increases and the cluster grows, the high cost of all-flash and the operation and maintenance complexity of the kernel client will become a major challenge for users. As a fully user-mode cloud-native distributed file system, JuiceFS uses a distributed cache to greatly improve the system's I/O throughput. It uses inexpensive object storage for data storage. This is more suitable for the overall needs of large-scale AI applications.
About MLPerf
MLPerf is a benchmark suite for evaluating machine learning training and inference performance on both local and cloud platforms. It provides an independent and objective performance evaluation standard for software frameworks, hardware platforms, and machine learning cloud platforms. The suite includes tests to measure the time required for machine learning model training to target accuracy and the speed of neural networks executing inference tasks on new data. This suite was created by over 30 organizations related to AI. For details, see MLPerf: An Industry Standard Benchmark Suite for Machine Learning Performance.
Published at DZone with permission of Edric Mo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments