9 Ways To Improve How You Ship Software
Seven principles and nine tactics for improving engineering culture and shipping velocity. These are all practical things you can start implementing at work.
Join the DZone community and get the full member experience.
Join For Free10x developers are real, and there’s more than one way to be a 10x developer.
The most approachable is to make ten other people 10% more productive.
In this article, I cover things to improve your individual and team productivity. This is valuable to your company and will likely help level up your career.
First, we’ll cover seven principles and then nine tactics.
7 Principles for Shipping Software
1. Speed
Let’s face it. As developers, we are speed junkies. If we find a tool that’s 10 ms faster, we’re inclined to immediately rewrite our entire application.
But when it comes to how often we deploy our code, we tend to be much more cautious. We’d rather deploy tomorrow or next week so we don’t have to stay late today to fix whatever problems might happen.
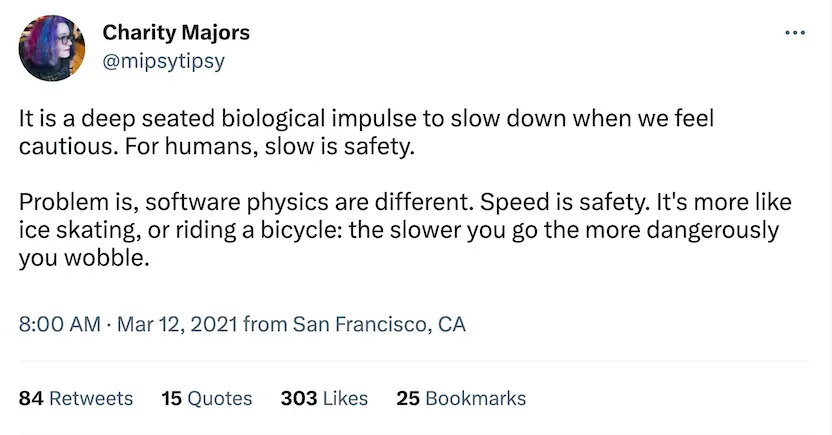
Like Charity says, it is a deep-seated biological impulse to slow down when we feel cautious. For humans, slowness is safety.
But software physics is different. It's more like riding a bicycle. The slower you go, the more dangerously you wobble.
Speed is safety. Small is speed.
When it comes to deployment, speed is safety, and small is speed.
The speed of shipping has massive compounding effects. If your deployment takes hours, you’re going to want to ensure there are no bugs because if you find a critical bug right after a deployment goes live, you have to wait another couple of hours for your fix to go live.
We must aim for speed in every part of the software lifecycle.
- Fast feedback loops
- Fast builds
- Fast tests
- Fast deploys
- Fast fixes
- Fast rollbacks
2. Reliability
The second principle is reliability. Our systems must be dependable.
Flaky CI/CD issues have to be one of the worst possible things in the universe.
We must avoid flakiness at all costs.
3. Reproducibility
In order to build and maintain complex systems, we need to know that if we do X, we get Y every time. If one time you do X, you get Y, but another time you get Z, you will lose confidence in your systems.
We want to use scripts and code to control everything we do instead of manually clicking, manually commanding, etc.
4. Calm On-Call Rotations
Somewhat self-explanatory, no one wants to dread on-call rotations. If they are hectic, it will degrade morale and cause all sorts of issues. So, it’s something we should explicitly prioritize. It can serve as a backstop of sorts to make sure what we’re doing is truly working well.
5. Easy To Debug
Everyone causes bugs. Even seniors. Even when you have tests. Even when you have 100% test coverage. You will ship bugs to production.
So, you must be prepared to fix production bugs. This is an area where speed is important. And as part of that, it must be easy to debug.
If it’s hard to debug and slow to deploy fixes, it’s going to slow you down because you are going to add lengthy QA processes, and before you know it, you’ll be deploying code only once every few weeks.
But even with lots of QA, you’ll still have production bugs. Production is the only tried-and-true way to find all the bugs.
Our systems must be easy to debug.
6. Self-Serve Infrastructure and Deployments
In the old way of doing infrastructure and code deployments, you had two separate teams. Devs and Ops. If devs needed a new database, they filed a ticket with ops. If they need a new service, file a ticket with ops. Need to deploy your code? File a ticket with ops.
Naturally, this has several problems:
- Devs are often blocked, waiting on ops to get to some ticket.
- Devs aren’t monitoring infrastructure and likely won’t get feedback on whether their code is fast or slow, efficient or inefficient.
- The whole organization is slowed down.
As an industry, we figured out it’s much better for devs to deploy and run their own code. This is more efficient, with fewer blockages and less communication overhead, and devs get more feedback from the real world on how their code is performing.
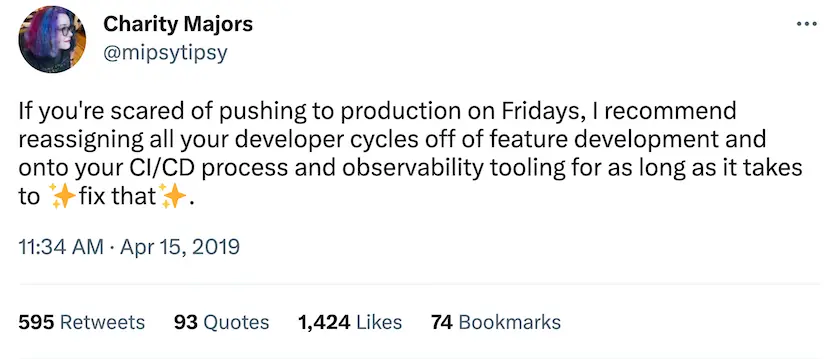
7. Ship on Fridays

Healthy engineering organizations deploy multiple times per day, including on Friday!
If you are afraid to deploy on Friday, it’s likely from one or more of the following:
- You don’t have reliable deploys.
- You have slow deploys.
- You don’t have good monitoring and alerting.
- Your app is hard to debug.
- You don’t have tests.
Those are all things you must fix.
9 Tactics To Improve How You Ship Software
With the above principles in place, let’s look at nine specific tactics to implement them in practice.
1. Decouple Deploys From Releases
Deploying software is a terrible, horrible, no good, very bad way to go about the process of changing user-facing code.
Charity Majors
Fundamentally, there are two possible actions for changing code in production: deploys and releases.
- Releasing refers to the process of changing the user experience in a meaningful way.
- Deploying refers to the process of building, testing, and rolling out changes to your production software.
The traditional process is that you change the code on a branch, and when it’s ready, you merge and deploy it. Once it’s deployed, users will see the new code.
But today’s modern engineering organizations use feature flags.
What is a feature flag?
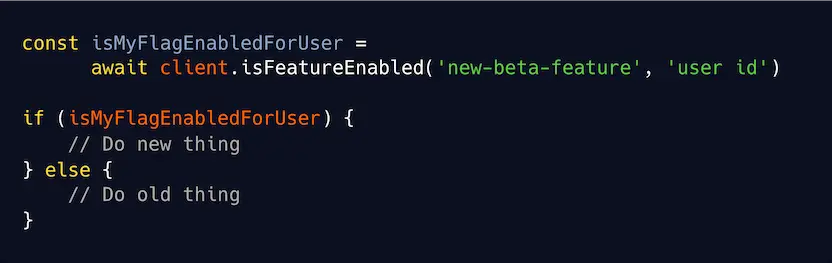
It allows you to write new code alongside the old code, and then, based on a runtime feature flag, your app decides whether to run the old or new code.
This is huge! Remember how speed is one of the key principles? Separating deploys from releases speeds up both. It speeds up deploys because engineers can deploy their code as soon as it’s ready without waiting for product management to be ready to release it. And it speeds up releases because now you can release a feature instantly. And roll back a feature instantly without needing a deployment. Product managers can do releases on their schedule.
Furthermore, it unlocks advanced methods like progressive rollout, where you enable the feature flag for a percentage of your users. You could start out with 5% of users. If everything is working, then increase to 10%, 20%, etc. This is the best way to roll out changes at scale because if there are problems, only a subset of your users will experience them instead of all.
And feature flags are superior to long-lived feature branches for development flow. You have fewer merge conflicts, less stale code, more team momentum, better team morale, and more flexibility for testing things with real users.
I encourage you to introduce this idea at work. And next time someone has a long-lived feature branch instead of a feature flag, use this:

2. Continuous Deployment (CD)
Deployments are the heartbeat of your engineering organization. And like a human heart, you want a steady rhythm of simple heartbeats. And with this steady rhythm of deployments, you get momentum. And momentum is life for organizations.
Along with momentum, you get efficiency, being able to deliver code to production as quickly as possible after it’s written.
You want to deploy as often as possible, like multiple times per day. Every commit should be deployed. Small, understandable changes mean you have debuggable and understandable deploys. The engineer who writes the code should merge their own PR and then monitor production for any unexpected issues.
Feature flags are basically a prerequisite for this because they allow your team to ship small changes continuously instead of having long-lived feature branches.
3. Set Up Alerts
Make sure you set up alert notifications for the following anomalies:
- Failed builds
- Failed deploys
- Service downtime
- Unhealthy servers
- Unexpected errors
- Unusual amount of traffic
- Statuses of third-party services (many have a status page that you can subscribe to in Slack)
The benefit is relatively obvious, but it does take at least a bit of effort to set them up, so this is something many teams can do as a quick win.
And if you already have alerts, you should audit them:
- Are they useful?
- Are you getting too many false alerts so that you ignore them?
- Are there things you should add new alerts for?
4. Optimize Deploy Speed — 15 Minutes or Bust
Your target for a happy team is 15-minute deploys or less. Of course, we want them to be as fast as possible, but the neighborhood of 15 minutes is the baseline target. Significantly longer than this is significantly painful. But significantly faster than this could take more work than it’s worth, depending on your circumstances.
There are a number of ways to improve your speed of deploys.
- Track and measure your current deploy times. You want to understand your starting point and which parts of the process are taking a long time. That’s where you want to focus initially.
- Speed up dependency installation. Dependency installation is often time consuming so that it can be a good first step.
- Switch to a faster package manager. If using javascript, switch to pnpm. It’s a drop-in replacement for npm and yarn that has significant performance and caching improvements.
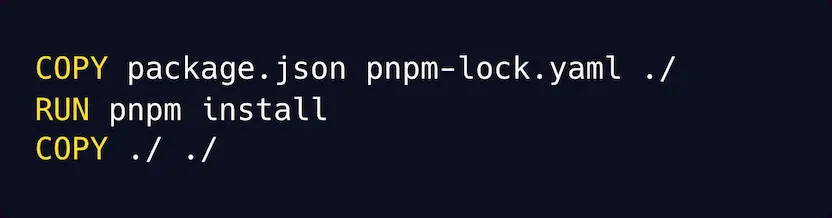
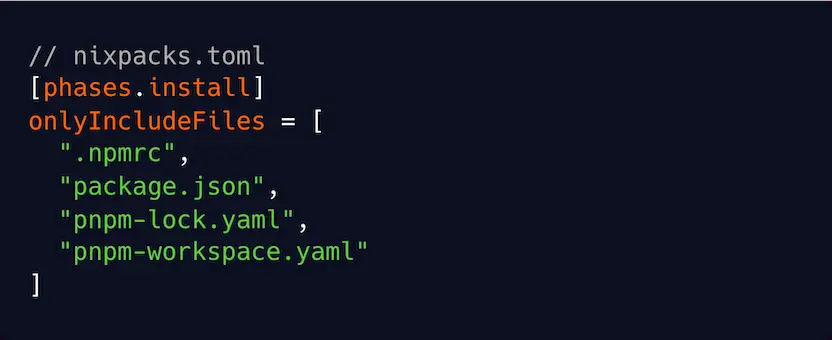
- Cache the entire install step. Use your build system to cache this entire step, so this step doesn’t even run if your dependencies haven’t changed.
Example with Docker:
Example with Nixpacks:
- Improve your build speed. The main way to improve your build speed is to switch to a faster bundler.
- For example, if you are using create-react-app, which uses webpack, you can switch to Vite, which is way faster.
- If using Next.js, upgrade to the latest and ensure you don’t have a .babelrc file; this will use SWC instead of Babel, which is much faster.
- If you like living on the edge, you can try Turbopack by passing the
--turboflag to thenextcommands, but it’s still experimental and doesn’t work for all setups.
- Set up build caching. If you are using Docker, there are several ways to improve caching:
- Optimize your build layers.
- Use multi-stage builds.
- Set up remote caching.
When building locally, Docker caches by default and is fast, but in CI, you usually don't have a permanent machine. You have to manually set up remote caching. Refer to the Docker documentation for more information.
- Globally cache everything. If you want to really live with your hair on fire, in a good or maybe bad way, there is another style of caching that can give you big wins as long as you have a JavaScript project.
This caching style works by having a single shared cache between your entire team and also CI.
This means if you build a commit locally and then push that commit to CI, the CI build will download the previous cached build from your local machine and be done in mere seconds. Or if someone else on your team already built a commit, and then you run the build locally, it will again download the cache and be done in mere seconds instead of building from scratch again.
You might be thinking, “ok, Brandon, that’s cool and all, but usually, we’re changing code so it won’t be cached.” But the trick is that this caching works on a package level, so assuming you have a monorepo, you are likely only working in one package at a time. So this enables you to iterate faster and not have to build things you aren’t working on.
There are two tools that do this: NX and Turborepo.
There is a gotcha. You must be careful with how you handle environment variables. I’ve seen numerous people have production issues because a dev ran the production build locally but with dev or staging environment variables. And then CI uses the cached build with incorrect environment variables. Make sure you set up different commands for dev, staging, and production.
5. Replace Staging With Preview Environments
Preview environments are temporary environments tied to the lifecycle of a pull request. When you open a pull request, infrastructure can be automatically provisioned for that PR.
This enables stakeholders to see the changes in a production-like environment before it’s merged. And then, when the pull request is merged or closed, its environment will be automatically cleaned up.
Preview environments are a better replacement for long-lived staging environments. Because staging is running all the time, whether it needs to or not. And you have to merge a PR before anyone can verify the change.
Preview environments are a companion to feature flags. Larger changes should use feature flags and will have many PRs for that feature. But small changes are easier to review in a preview environment instead of going through the hassle of managing a feature flag for them.
6. Infrastructure-as-Code
Hopefully, you have automated deployments, but you might not have automated infrastructure. Without infrastructure-as-code (IaC), you typically define your infrastructure config by clicking through a dashboard.
Bringing automation to your infrastructure config in the form of infrastructure-as-code has a huge number of benefits, including:
- Repeatability or reproducibility
- Consistency and standardization
- Predictability
- Version controlled
- Collaboration and review
IaC can take many forms. If using AWS, it can be low level like CloudFormation or Terraform. Or it can be at a higher level of abstraction, designed for product developers. Examples are Flightcontrol’s flightcontrol.json or Render’s render.yaml.
7. Platform Engineering
Platform engineering might be a new term for you, so let me give you the back story that got us to this point.
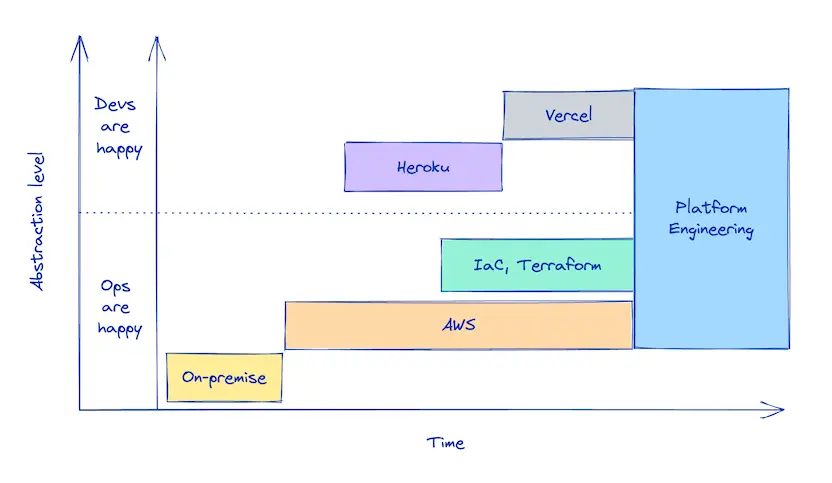
Back in the old days, you had to rack your own servers in a data center. The abstraction level of infrastructure was extremely low. Then came AWS, which introduced the cloud and raised the abstraction level. But it was still too low for the average developer.
This led to the creation of Heroku, to the glee of developers all around the world. But that excitement was not to last because ops were not happy. It turns out abstractions like Heroku do not scale for large companies. So ops take over and create a new abstraction over AWS, infrastructure as code, and Terraform. This works well, but it’s still too tedious for developers.
Additionally, company leadership wants to increase operational efficiency, and one way to do that is to provide devs with self-serve infrastructure, so we, as an industry, started creating internal platforms that provide a better developer experience. Through this, we found a way for both ops and devs to be mostly happy. This has come to be known as platform engineering.
Now, many larger companies are building an internal platform, sometimes known as an internal developer platform. This platform can look more like an internal Heroku or more like plain Terraform.
Either way, the three key concepts are:
- Deploy to your own AWS/GCP account
- Self-serve infrastructure with good developer experience
- Ops can dictate and customize the underlying primitives.
There are many tools in the space, one of which is Flightcontrol.
8. Work as a Team
Back in the beginning of Flightcontrol, it was only my cofounder and me. We had a clear separation of duties aligned with our skillsets. He did all the backend/infra stuff, and I did all the web app and frontend things. It worked great!
But then we started hiring more engineers. We initially kept the same work model where each person was off working on their own project or feature.
It started to feel like something wasn’t right.
We weren’t benefiting from collaboration. Since each person was working mostly alone, we weren’t benefiting from others’ expertise on everything from architecture design to code quality.
We would review each other’s code, but since no one else had the full context of the project, they were only able to give superficial reviews. LGTM!
Then, somewhere during this time, I ran across a few blog posts by Swizec Teller, talking about how most teams don’t actually work as a team, and if you actually work as a team, you can be way more effective.
When we first started working as a team instead of a group of soloists, every story felt like a million gerbils running through my brain.
Swizec
We moved faster. We got more done. We kept everyone in the loop. Shared more ideas. Found more edge cases. Created fewer bugs. And heard more opinions.
I read this, and my heart was saying, YES YES, but my mind was saying, I don’t understand!
As a team, we decided to shift how we worked fundamentally. We’d no longer have multiple projects in progress at the same time. Instead, we’d have one project, and the entire team would work on it together from start to finish.
Initially, it was scary and awkward and felt like it wouldn’t work smoothly. And it was rough for a couple of months until we got things ironed out. But now it’s many months later, and we can’t imagine working any other way.
We can emphatically say that teams should work as a team. Everything has improved. We ship better features, have fewer bugs, and cover more edge cases. Job satisfaction and team morale increased. Because now they get true collaboration, not a “hi” as you pass them in the Slack channel.
How does this work?
- Small team (2-6 people, four is ideal)
- Entire team works on one project at a time, together.
- Kickoff meeting (deep discussions on how to build)
- Break the project into small tasks (usually in kickoff)
- Work on subtasks in parallel.
- Small PRs, at least one per day.
- Quick reviews. I.e., don’t be a blocker.
- Unblock yourself; merge your own safe PR if no one is available to review and you are blocked.
9. Trunk Based Development
The next level of team productivity is to get rid of pull requests and commit straight to the main branch.
I’m serious.
It’s called trunk-based development. If this is a new concept to you, I know you’re thinking this is impossible; there is no way this can work. Even if you’ve heard of this concept before, you are probably thinking, “I have no idea how this could work.”
Think of it like a cafeteria. Your tray is the main branch. When the burger is done, it goes on the tray. When the fries are ready, they go on the tray. When the milkshake is poured, it goes on the tray. Once the tray is full, you’re done.
That's how trunk-based development works. Every feature goes straight to the main when it's ready. Whether subtasks or an entire project, it doesn’t matter because they're all working, independent, and deployable.
If committing straight to the main is too radical for you, then do the next best thing, which is short-lived branches.
And by short-lived branches, I mean short-lived branches.
You want to be as close as possible to pure trunk-based development as possible.
PRs shouldn’t last more than about a day. For a project, you should have many short PRs that are quick for others to review and easy to merge.
That’s how you get momentum.
Conclusion
We’ve covered seven principles and nine tactics for improving how you ship software.
What do you think of these? Have things to add or take away?
Published at DZone with permission of Brandon Bayer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments